

关于Java并发的书籍和文章已经有很多了,但是就我自己的学习下来的感受来说,有一些看似简单的知识点,以至于大神们和文章的作者们都直接忽略了,但是这些知识点却很重要,如果不搞清楚,很难“彻底理解、融会贯通”,这种似懂非懂的感觉让我很难受,所以我总结了这篇文章,可能不会有什么牛X的技术,高深的理论,但是这些思考曾经让我对Java并发的认知更进了一步,送给你们。
先提几个曾经困扰过我的问题啊,看似很简单,而且可能还有很多同学还存在误解,我们来一起看一下。
- 问题一:经常听说“主内存“,”工作内存“,那它们到底指什么? 或者说它们以何种形式存在?
- 问题二:我们还经常听说“可见性”,到底什么是可见性?为什么会出现“不可见”的情况?
- 问题三:你肯定还听说过“原子性”,那什么是原子性?哪些操作可以认为是原子的?
- 问题四:”有序性“,代码真的按我们写的先后顺序执行吗?背后有什么玄机?
如果这些问题也曾困扰过你,那这篇文章最合适你不过了,接下来我们一起进入Java的世界扒一扒并发。
什么是主内存,工作内存
这2个概念是Java内存模型(Java Memory Model)中提出的,关于内存模型的详细介绍猛戳这里,我们目前只需要知道内存模型是帮我们屏蔽底层硬件细节的,程序员只需要按照它的规则来写代码,写的程序就可以实现跨平台运行,很巧妙的设计。
了解了内存模型,我们回到主题,我们知道JVM将内存划分了以下几大块
- 堆 (进程内所有线程共享)
- 方法区 (进程内所有线程共享)
- 虚拟机栈 (每个线程独立)
- native本地方法栈 (每个线程独立)
- pc计数器 (每个线程独立)
那主内存,工作内存跟它们的对应关系是怎么样的呢? 这里直接给出结论。
- 主内存就是堆 + 方法区
- 工作内存就是虚拟机栈 + native本地方法栈 + pc计数器
这个知识点看似不起眼,但是却很重要,因为只有有了这个结论,才能与我们后面的实际代码例子结合起来,否则就会感觉理论与实际操作脱节了,没法对应起来。
举个例子
需求是这样的,有一个Counter计数器类,内部有一个count成员变量int类型,记录当前的总数,具体定义如下。
public class Counter {
private int count;
public void increment() {
this.count++;
}
public int getCount() {
return this.count;
}
}
我们现在的任务是调用一亿次increment方法,然后打印count的数量,那么显然正确的输出应该是一亿。
public static void main(String[] args) {
// 单线程代码
Counter counter = new Counter();
int loopCount = 100000000;
long startTime = System.currentTimeMillis();
for (int i = 0; i < loopCount; i++) {
counter.increment();
}
System.out.println("count:" + counter.getCount());
System.out.println("take time:" + (System.currentTimeMillis() - startTime) + "ms");
}
// 输出结果
count:100000000
take time:577ms
so easy!这样的代码我们太熟悉了,但是这次我想从代码在虚拟机栈中的具体执行过程来加深理解程序是怎么运作的。先通过Javac和Javap命令查看Counter类的increment方法的字节码实现。
javac Counter.java
javap -verbose Counter.class
// Counter类 increment方法的字节码
public void increment();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=3, locals=1, args_size=1
0: aload_0
1: dup
2: getfield #2 // Field count:I
5: iconst_1
6: iadd
7: putfield #2 // Field count:I
10: return
我们知道Java中方法的调用是基于栈帧实现的,每个栈帧中主要包含操作数栈+用到类的运行时常量池引用+本地变量表。我画了一张示意图帮助大家理解整个执行过程,并且将其中一次count++操作的字节码在操作数栈中的执行步骤分解了(以count=10为例),这里要注意,下面这张图的运行是在工作内存中(main方法所在线程的虚拟机栈中)。
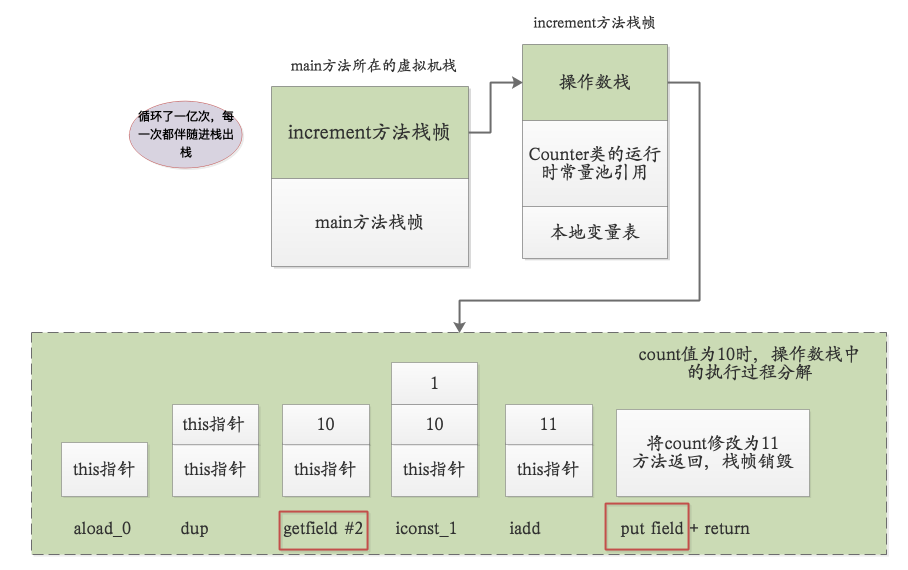
- 循环从0到一亿,是严格按顺序执行的(有序性)
- 循环过程中,前一次对count的修改对后面可见(可见性)
- 因为是严格按顺序执行的,所以count++操作中间不会交叉执行,所以其实在单线程环境中,可以认为满足原子性 (原子性)
上面的条件只要有一个被打破,执行的结果就可能不正确,这也就是为什么Java多线程环境下容易出现并发问题,原因就是没有同时满足这三个条件。
多线程为什么会出现并发问题?
上面已经提到,我们上面的Count类的实例中,需同时满足 有序性,可见性,原子性,其中有序性和原子性,我们比较容易想到因为多个线程交叉执行,如果不加同步控制,有序性和原子性肯定没法保证,但是这里比较难理解的是可见性,骨头先捡难啃的啃,所以接下来我们先谈谈可见性。
什么是可见性?为什么会出现”不可见“
还是以我们上面的示例来说明。 我们已经知道
counter.increment();
编译成字节码为
getfield #2
iconst_1
iadd
putfield #2
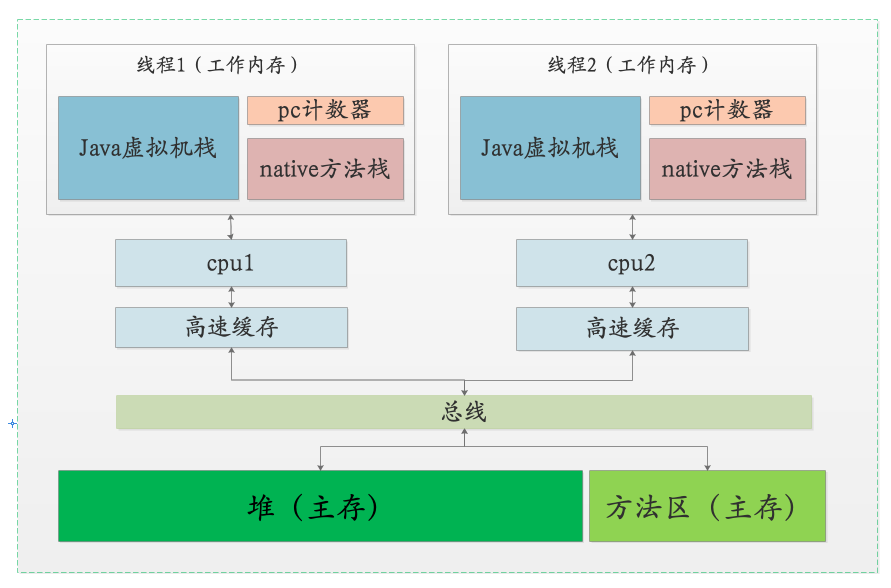
前面已经说过,这里的字节码的执行过程是在工作内存中,但是getField和putField这二条指令其实是跟主内存有交互的,这里还是以Counter类的increment方法为例。
- getField指令会从主存中读取count的值,但是并不是每次都从主存中读,因为CPU高速cache的存在,我们count值有可能会从cache中读,导致读的并不是最新的
- putField指令会将count新的值写入主内存,但是也不是立即生效,别的CPU的高速cache中的count不会立即更新,CPU会使用缓存一致性协议来做同步,这个对我们是透明的。
正是因为CPU高速cache的存在,在多核环境中会有可见性的问题。这里额外提一句 ,之所以有高速cache存在,是为提高运行效率,现代CPU的速度比我们的内存快很多,如果每次都锁总线写主存,会导致执行速度下降很多,这是不可以接受的,木桶理论我们都能理解哈。这里我也画了一张图,来帮助大家理解。
volatile
volatile修饰的变量有下面的特性
- 在写volatile的时候,有monitor release的语义,会刷新各个cpu中该变量的cache,存入最新的值
- 在读volatile的时候,有monitor acquire的语义,会使当前cpu的cache中该变量的cache失效,从主存中读取最新的值
- volatile拥有禁止指令重排序的语义
其中monitor可以理解为锁,moniter release就是释放锁,monitor acquire就是获取锁,这样就是volatile变量的读写都是直接对主存操作的,相当于牺牲一部分性能来换取可见性,这一部分牺牲的性能一般是可以忽略不计的,只需要知道有这么回事就行。
volatile实现原理
给count加上volatile修饰符后,查看编译后的字节码后会发现,字节码层面唯一的变化是给count添加了ACC_VOLATILE标识flag,在运行时会根据这个flag会自动插入内存屏障,保证volatile可见性语义,内存屏障一共有四种,分别是:
- LoadLoad
- LoadStore
- StoreStore
- StoreLoad
这里有个文档,比较权威详细的说明了内存屏障的知识,这一块知识大家可以自己继续深入。这里给出文档中的一个实例,比较形象的说明了内存屏障是怎么插入的。

再回到上面的例子,我们给count添加上volatile修饰符之后,是不是就能在多线程中得到正确的累加结果呢?我们试验一下,简单起见,我们只开2个线程,每个线程分配一半的计算量。
// Counter.java
private volatile int count;
// main 方法
Counter counter = new Counter();
int loopCount = 100000000;
int halfCount = loopCount / 2;
Thread thread1 = new Thread(() -> {
for (int i = 0; i < halfCount; i++) {
counter.increment();
}
});
Thread thread2 = new Thread(() -> {
for (int i = halfCount; i < loopCount; i++) {
counter.increment();
}
});
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("count:" + counter.getCount());
System.out.println("take time:" + (System.currentTimeMillis() - startTime) + "ms");
// 运行结果
count:51743664
take time:2335ms
结果显然还是不对的,而且程序运行的时间长了好几倍了。这是因为volatile只保证了可见性,却没有原子性语义,比如下面这种情况

那我们不妨设想下,如果在putfield之前,检查下当前栈中存储的count是不是最新的,如果不是最新的重新读取count,然后重试,如果是最新的,直接写入更新值,似乎这样就能解决我们上面出现的错误写入的问题。看起来似乎是一个不错的想法,但是一定要注意,整个检查过程要保证原子性,否则仍然会有并发问题。事实上JDK中Unsafe包里面的CAS方法就是这个思路,不断循环尝试,这个过程就是自旋,它的底层实现依赖cmpxchgl 和 cmpxchgq这二个汇编指令,不同平台的cpu有不同的实现,但是代码大同小异,我在这里以opekjdk8为例扒一扒CAS的源码,源码比较多我只会贴出关键代码块。
// Unsafe.class中的三个CAS方法,都是native的
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
它对应的native实现在hotspot/src/share/vm/prims/unsafe.cpp
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
篇幅关系,这里只贴上compareAndSwapInt的实现,可以看到又调用了Atomic::cmpxchg方法,继续跟进去
unsigned Atomic::cmpxchg(unsigned int exchange_value,
volatile unsigned int* dest, unsigned int compare_value) {
assert(sizeof(unsigned int) == sizeof(jint), "more work to do");
return (unsigned int)Atomic::cmpxchg((jint)exchange_value, (volatile jint*)dest,
(jint)compare_value);
}
jbyte Atomic::cmpxchg(jbyte exchange_value, volatile jbyte* dest, jbyte compare_value) {
assert(sizeof(jbyte) == 1, "assumption.");
uintptr_t dest_addr = (uintptr_t)dest;
uintptr_t offset = dest_addr % sizeof(jint);
volatile jint* dest_int = (volatile jint*)(dest_addr - offset);
jint cur = *dest_int;
jbyte* cur_as_bytes = (jbyte*)(&cur);
jint new_val = cur;
jbyte* new_val_as_bytes = (jbyte*)(&new_val);
new_val_as_bytes[offset] = exchange_value;
while (cur_as_bytes[offset] == compare_value) {
jint res = cmpxchg(new_val, dest_int, cur);
if (res == cur) break;
cur = res;
new_val = cur;
new_val_as_bytes[offset] = exchange_value;
}
return cur_as_bytes[offset];
}
我们跟踪到了调用了cmpxchg这个方法,这个方法不是在atomic.cpp中定义的,查看atomic.hpp,看到了cmpxchg对应的内联函数的定义
inline static jint cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value);
// See comment above about using jlong atomics on 32-bit platforms
inline static jlong cmpxchg (jlong exchange_value, volatile jlong* dest, jlong compare_value);
这里我们以solaris_x86平台为例,cmpxchg对应的内涵函数定义在hotspot/src/os_cpu/solaris_x86/vm/atomic_solaris_x86.inline.hpp
#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
inline jint _Atomic_cmpxchg(jint exchange_value, volatile jint* dest, jint compare_value, int mp) {
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
这个是内嵌汇编代码,实话说,汇编这一块的知识我也还给老师了。根据LOCK_IF_MP这个宏定义判断是不是多核心,如果是多核心需要加锁,但是这个锁是cpu总线锁,它的代价比我们应用层中用的Lock代价小得多。同时我们看到cmpxchgl这个关键的指令。追到这一层,我想对于应用开发工程师已经足够了。了解了底层实现,我们来现学现卖实战一波。
使用CAS改造我们的加法器Counter,使其是线程安全的
要使用CAS,肯定要使用Unsafe类,我们还是通过反射来获取Unsafe对象,先看UnsafeUtil类的实现
// UnsafeUtil.java
public static Unsafe getUnsafeObject() {
Class clazz = AtomicInteger.class;
try {
Field uFiled = clazz.getDeclaredField("unsafe");
uFiled.setAccessible(true);
return (Unsafe) uFiled.get(null);
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public static long getVariableOffset(Object target, String variableName) {
Object unsafeObject = getUnsafeObject();
if (unsafeObject != null) {
try {
Method method = unsafeObject.getClass().getDeclaredMethod("objectFieldOffset", Field.class);
method.setAccessible(true);
Field targetFiled = target.getClass().getDeclaredField(variableName);
return (long) method.invoke(unsafeObject, targetFiled);
} catch (Exception e) {
e.printStackTrace();
}
}
return -1;
}
再来看Counter类的实现
public class Counter {
private volatile int count;
private Unsafe mUnsafe;
private long countOffset;
public Counter() {
mUnsafe = UnsafeUtil.getUnsafeObject();
countOffset = UnsafeUtil.getVariableOffset(this, "count");
}
public void increment() {
int cur = getCount();
while (!mUnsafe.compareAndSwapInt(this, countOffset, cur, cur+1)) {
cur = getCount();
}
}
public int getCount() {
return this.count;
}
}
再次开启二个线程,执行我们的累加程序
// 输出结果
count:100000000
take time:5781ms
可以看到我们得到正确的累加结果,但是运行时长更长了,但是还好,时间复杂度还是在一个数量级上的。这里要注意一点的是,上述示例代码中,我给count变量增加了volatile关键字,其实就算不加volatile关键字,在这里CAS也是能够正确工作的,但是效率会低一点,我测试下来差不多性能会低5%左右,大家可以思考下为什么不加volatile效率会低?
volatile关键字还有一个禁止指令重排序的语义,一个经典的应用就是DCL单例模式,大家应该都很熟了,就不赘述了。
到这里,关于可见性我们已经讨论的差不多了,接下来我们来讨论”原子性“
原子性,怎么保证原子性?
其实上面我们已经提及了一些,比如CAS本身就是原子的,那想一想还有哪些是原子的?我这里还是以Counter类的increment方法为例。
0: aload_0
1: dup
2: getfield #2 // Field count:I
5: iconst_1
6: iadd
7: putfield #2 // Field count:I
10: return
这7条字节码指令,都是原子的,没有问题吧,但是我们如果再往深处想的话,还是会有疑问,单个字节码指令都是原子的吗? 如果单条都不是原子的,我想我们前面的所有判断都是错误的,因为我们得出结论的理论基石被打破了。事实是,单条字节码就是原子的,这个原子性由谁来保证呢?由Java内存模型JMM来保证,程序员不需要知道具体的细节。
虽然单条字节码是原子的,但是多条字节码组合起来就不是原子的了。这也是很多并发问题发生的根源。那我们程序员有哪些手段保证原子性呢?大概有以下三种。
- CAS + 自旋
- synchronized关键字
- concurrent包提供的Lock,具体实现类比如ReentrantLock
CAS我们上面已经讨论过,这里不赘述了,我们来看看synchronized
synchronized
synchronized算是我们最常用的同步方式,主要有以下三种使用方式
// 普通类方法同步
synchronized publid void invoke() {}
// 类静态方法同步
synchronized public static void invoke() {}
// 代码块同步
synchronized(object) {
}
这三种方式不同之处在于我们进行同步的对象不同,普通类synchronized同步的就是对象本身,静态方法同步的是类Class本身,代码块同步的是我们在括号内部填入的对象。本质上它们的原理是相同的,都会有一个monitor的对象与我们要进行同步的对象进行关联,当有一个线程持有了monitor的锁后,其他线程必须等待,一直到该线程释放了该monitor才能被别的线程重新获取,hotspot虚拟机中,它在native层对应的实现类是ObjectMonitor.hpp,这个类内部维护了很多同步相关的变量,我们重点关注二个变量
void * volatile _owner; // pointer to owning thread OR BasicLock
ObjectWaiter * volatile _WaitSet; // LL of threads wait()ing on the monitor
_owner代表当前持有锁的线程,—WaitSet代表等待锁的线程队列,通过ObjectWaiter的数据结构可以推断这是一个双向循环链表。
回到我们的实例,这一次我们通过synchronized来实现我们的Counter类。
public void increment() {
synchronized (Counter.class) {
this.count++;
}
}
// 再运行一次,
// 输出结果
count:100000000
take time:4881ms
输出的结果是正确的,而且从我们打印的运行时间结果来看,synchronized加锁后的执行速度比我们上面的CAS还要快,这有一点点反直觉,其实synchronized在Java1.7后引入了偏向锁,轻量级锁后,synchronized性能有了较大提升,所以在使用synchronized的时候不需要有太多的心理负担,一般情况下,对性能不是极度要求高的话,使用synchronized没有问题。
这里还是贴下increment方法加上synchronized同步后的字节码实现。
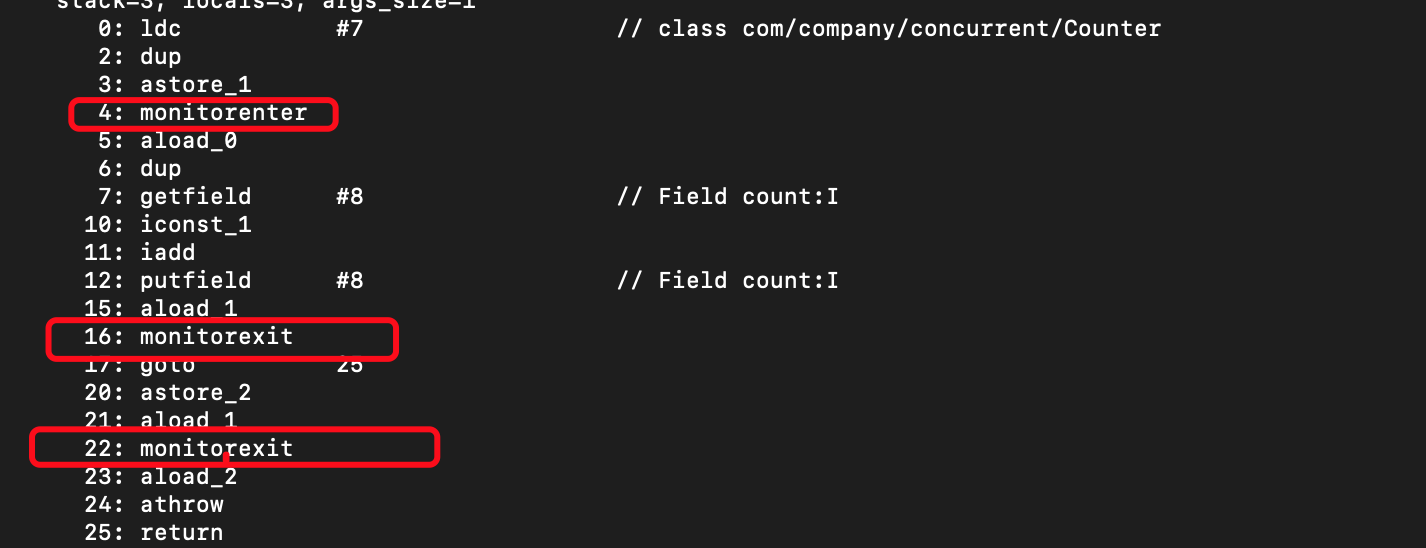
// 我们的实现
synchronized (Counter.class) {
this.count++;
}
// 编译后,相当于下面的伪代码
monitorenter Counter.class;
try {
this.count++;
monitorexit Counter.class;
} finally {
monitorexit Counter.class;
}
除了synchronized关键字之外,还有个比较常用的用来做同步类就是ReentrantLock
ReentrantLock
ReentrantLock的使用大家应该都很熟了,篇幅关系,这里只简单提一下用法,更详细的使用文档大家可以自行查阅相关资料。
// 参数表示 是否是公平锁,公平锁严格按照等待顺序获取锁,但是吞吐率低性能差
// 非公平锁性能高,但是有可能会出现锁等待饥饿
ReentrantLock reentrantLock = new ReentrantLock(false);
// 一个标准的使用方式
reentrantLock.lock();
try {
// do something
} finally {
reentrantLock.unlock();
}
这里要注意的是加锁的lock方法的调用,一定要在try-catch-finally的前面,不能在内部,因为如果在内部调用lock,如果代码在lock之前就出现异常了,就会出现我们没有加锁就执行了finally里面的释放锁,肯定会有问题。
为了对比,我们还是使用ReentrantLock实现一遍上面Counter累加。
Lock lock = new ReentrantLock(false);
Thread thread1 = new Thread(() -> {
for (int i = 0; i < halfCount; i++) {
lock.lock();
try {
counter.increment();
} finally {
lock.unlock();
}
}
});
Thread thread2 = new Thread(() -> {
for (int i = halfCount; i < loopCount; i++) {
lock.lock();
try {
counter.increment();
} finally {
lock.unlock();
}
}
});
// 运行程序,输出结果
count:100000000
take time:12754ms
输出结果也是正确的,但是运行时间却是最长的,差不多是我们用synchronized的三倍。当然我们这里并不是搞性能测试,运行的时间也没什么参考意义,贴出来只是让大家有个直观认识,那就是CAS未必就一定性能高,synchronized未必就一定性能差,要具体问题具体分析,一定要有质疑的意识。
既然说到了Lock,我们还是扒一扒它的实现源码,这里以非公平锁为例。
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
/**
* Performs lock. Try immediate barge, backing up to normal
* acquire on failure.
*/
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}
abstract static class Sync extends AbstractQueuedSynchronizer {
//......
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
}
可以看到,lock方法的实现,首先会用CAS尝试去设置State为1,如果设置成功,将exclusiveOwnerThread设置为当前thread,如果设置不成功调用acquire方法,又调用了tryAcquire,我们可以重写该方法来自定义锁的逻辑,ReentrantLock中的默认实现如下
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
首先尝试获取state状态,如果==0尝试用CAS获取锁,如果!=0,检查是否是当前线程拥有锁,如果是,将state+1,返回true,如果不是返回false。所以这也就是为什么是可重入锁的原因,允许锁的嵌套,如果已经获取了锁,state+1然后返回true。
// 可重入锁,允许嵌套重复获得锁,伪代码如下
lock.lock();
lock.lock();
// do something ...
lock.unlock();
lock.unlock();
总结一下,ReentrantLock的实现是基于队列同步器AbstractQueuedSynchronizer(AQS)的,而AQS内部也是封装了CAS来实现的,深究下去还是有很多内容的,可以说整个concurrent包都是建立在CAS+AQS这二块基石上的,篇幅关系,更多的实现细节我们这里就不讨论了,大家可以自行参考相关的源码分析文章加深理解。
到这里,我们讨论了Java中的”原子性“,以及如果保证”原子性“的三种常规手段,原子性的讨论就结束了。接下来我们进入最后一个问题,Java的”有序性“。
有序性
为了方便说明,我们首先举一个简单的例子
int a = 1; ①
int b = 2; ②
int c = a; ③
按我们的预期,执行的顺序应该是①②③,但是 真实的执行顺序可能是②①③或者①③②,这是因为指令重排序的原因,基本有二种重排序
- CPU级的指令重排序
- 编译器级的指令重排序
重排序的目的是优化我们的程序运行速度,但是优化的前提是不能破坏as-if-serial语义,简单来说,以上面的例子为例,③由于有依赖①的结果,所以它需要永远排在①后面执行。 在单线程有序性还比较容易保证,但是在多线程情况就会变得复杂起来。所以JMM中抽象出了一个happen-before原则,这个原则是JMM给我们开发者的承诺,让我们写代码时对多线程情况下的有序性有一个正确的预期。这个原则有下面5条。
- 同一个线程中,程序中前面的代码happen-before后面的代码
- 对一个monitor的解锁happen-before对这个monitor的加锁
- 对一个volatile变量的写happen-before对这个volatile变量的读
- 线程start方法调用happen-before线程内的所有action
- 在A线程调用了B线程的join,则B线程内的操作happen-before于A线程后续的操作
当然happen-before具有传递性,如果A happen-before B, B happen-before C,则A 也 happen-before C。 需要注意的是,happen-before并不完全等同于时间意义上的先执行,比如上面的例子中,根据第一条happen-before原则,int a = 1; 这条语句 happen-before int b = 2; 这条语句,但是由于二者之间没有依赖关系,可以指令重排,所以可以是 int b = 2;先执行,这是合法的,并不违背happen-before原则。
理解这几条happen-before原则后,很多我们平时经常写的并发代码就有了理论依据,比如第二条,加锁happen-before解锁,所以保证了锁的同步范围内的代码,具有原子性和有序性,同时加锁和解锁都会插入内存屏障,可见性也得到保障,所以加锁后的代码是线程安全的。再比如第三条,volatile的写happen-before于volatile的读,有了这一条,多线程之间volatile修饰的共享变量的可见性得到保证。
另外几条原则比较好理解,大家可以自行结合实际代码加深理解,这里就不赘述了。
总结
Java并发算是一个比较高级的主题,但是这一块的知识又是高级工程师必须掌握的,骨头再难啃也得啃,希望本文的一些总结能帮助到希望深入了解Java并发的同学,哪怕是其中能有一点,能让你在阅读中有豁然开朗的感觉,我的目的就达到了。
最后,来针鸡血,”怕什么真理无穷,进一寸有一寸的欢喜“。
码字不易,如果喜欢点个赞呗!
