

卷积神经网络 AlexNet
1.介绍
LeNet 是最早推动深度学习领域发展的卷积神经网络之一。这项由 Yann LeCun 完成的开创性工作自 1988 年以来多次成功迭代之后被命名为 LeNet5。AlexNet 是 Alex Krizhevsky 等人在 2012 年发表的《ImageNet Classification with Deep Convolutional Neural Networks》论文中提出的,并夺得了 2012 年 ImageNet LSVRC 的冠军,引起了很大的轰动。AlexNet 可以说是具有历史意义的一个网络结构,在此之前,深度学习已经沉寂了很长时间,自 2012 年 AlexNet 诞生之后,后面的 ImageNet 冠军都是用卷积神经网络(CNN)来做的,并且层次越来越深,使得CNN成为在图像识别分类的核心算法模型,带来了深度学习的大爆发。本文将详细讲解 AlexNet 模型及其使用 Keras 实现过程。开始之前,先介绍一下卷积神经网络。
2. 卷积神经网络
2.1 卷积层
卷积是一种数学运算,它采用某种方式将一个函数“应用”到另一个函数,结果可以理解为两个函数的“混合体”。不过,这对检测图像中的目标有何帮助?事实证明,卷积非常擅长检测图像中的简单结构,然后结合这些简单特征来构造更复杂的特征。在卷积网络中,会在一系列的层上发生此过程,每层对前一层的输出执行一次卷积。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
那么,您会在计算机视觉中使用哪种卷积呢?要理解这一点,首先了解图像到底是什么。图像是一种二阶或三阶字节数组,二阶数组包含宽度和高度 2 个维度,三阶数组有 3 个维度,包括宽度、高度和通道,所以灰阶图是二阶的,而 RGB 图是三阶的(包含 3 个通道)。字节的值被简单解释为整数值,描述了必须在相应像素上使用的特定通道数量。所以基本上讲,在处理计算机视觉时,可以将一个图像想象为一个 2D 数字数组(对于 RGB 或 RGBA 图像,可以将它们想象为 3 个或 4 个 2D 数字数组的相互重叠)。
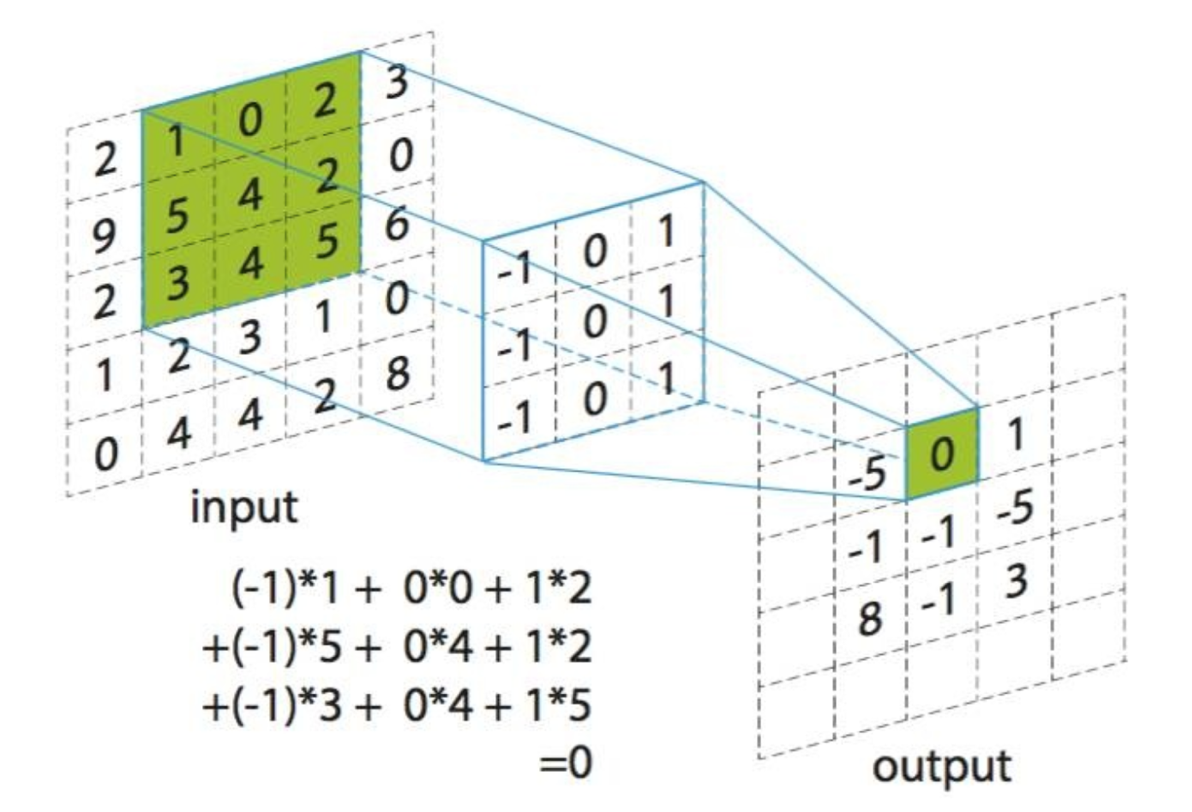
图1:卷积运算示意图(左输入,中过滤器,右输出)点我看计算演示
应该注意的是,步幅和过滤器大小是超参数,这意味着模型不会学习它们。所以您必须应用科学思维来确定这些数量中的哪些值最适合您的模型。对于卷积,您需要理解的最后一个概念是填充。如果您的图像无法在整数次内与过滤器拟合(将步幅考虑在内),那么您必须填充图像。可通过两种方式实现此操作:VALID 填充和 SAME 填充。基本上讲,VALID 填充丢弃了图像边缘的所有剩余值。也就是说,如果过滤器为 2 x 2,步幅为 2,图像的宽度为 3,那么 VALID 填充会忽略来自图像的第三列值。SAME 填充向图像边缘添加值(通常为 0)来增加它的维数,直到过滤器能够拟合整数次。这种填充通常以对称方式进行的(也就是说,会尝试在图像的每一边添加相同数量的列/行)。
2.2 激活层
激活层主要是激活函数的作用,那么什么是激活函数呢?在神经网络中,当输入激励达到一定强度,神经元就会被激活,产生输出信号。模拟这一细胞激活过程的函数,就叫激活函数。将神经元的输出 f,作为其输入 x 的函数,对其建模的标准方法是用
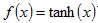
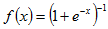
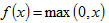
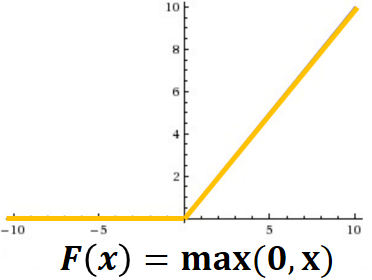
图2: ReLU 函数(输入小于0则输出为0,输入大于0则输出原值)
2.3 池化层
您会在卷积网络中看到的另一种重要的层是池化层。池化层具有多种形式:最大值,平均值,求和等。但最常用的是最大池化,其中输入矩阵被拆分为相同大小的分段,使用每个分段中的最大值来填充输出矩阵的相应元素。池化层可以被认为是由间隔为 s 个像素的池单元网格组成,每个池汇总了以池单元的位置为中心的大小为 z×z 的邻域。如果我们设置 s = z(池化窗口大小与步长相同),我们获得在 CNN 中常用的传统的局部合并。 如果我们设置 s<z(每次移动的步长小于池化的窗口长度),我们就获得重叠池化。在 AlexNet 中首次使用重叠池化来避免过拟合。
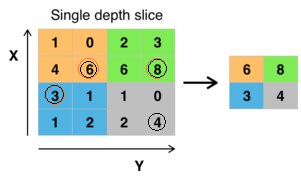
图3:最大池化(左 16X16 大小分成了 4 块,黑子圈中是最大的数字)
2.4 全连接层
全连接层是一个传统的多层感知器,它在输出层使用 softmax 激活函数(也可以使用其他分类器,比如 SVM)。“完全连接”这个术语意味着前一层中的每个神经元都连接到下一层的每个神经元。 这是一种普通的卷积网络层,其中前一层的所有输出被连接到下一层上的所有节点。卷积层转换为全连接层时,总神经元个数不变。
3. AlexNet 模型
3.1 模型介绍
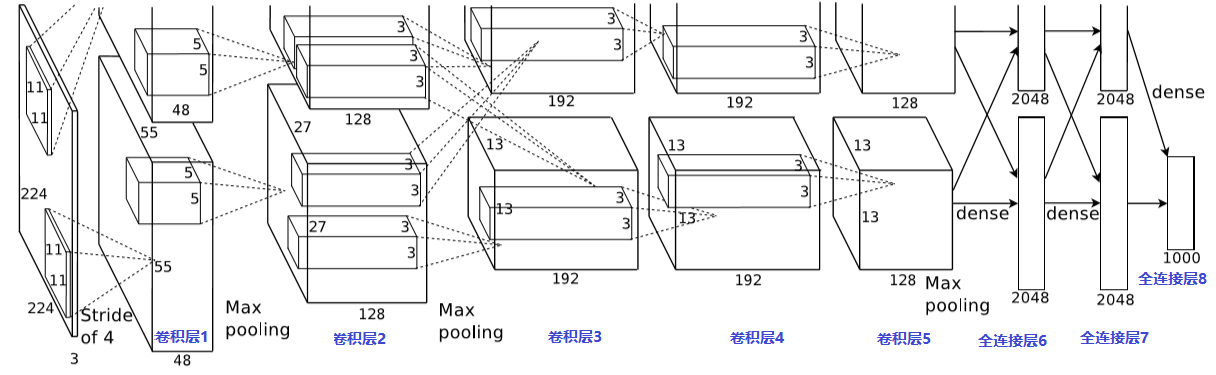
图4:AlexNet 模型( 5 卷积层+ 3 全连接层共 8 层神经网络,使用 2GPU 故分上下两部分)
AlexNet 模型包含 6 千万个参数和 65 万个神经元,包含 5 个卷积层,其中有几层后面跟着最大池化(max-pooling)层,以及 3 个全连接层,最后还有一个 1000 路的 softmax 层。为了加快训练速度,AlexNet 使用了 Relu 非线性激活函数以及一种高效的基于 GPU 的卷积运算方法。为了减少全连接层的过拟合,AlexNet 采用了最新的 “Dropout”防止过拟合方法,该方法被证明非常有效。
3.2 局部归一化(Local Response Normalization,简称LRN)
在神经生物学有一个概念叫做“侧抑制”(lateral inhibitio),指的是被激活的神经元抑制相邻神经元。归一化(normalization)的目的是“抑制”,局部归一化就是借鉴了“侧抑制”的思想来实现局部抑制,尤其当使用 ReLU 时这种“侧抑制”很管用,因为 ReLU 的响应结果是无界的(可以非常大),所以需要归一化。使用局部归一化的方法有助于增加泛化能力。
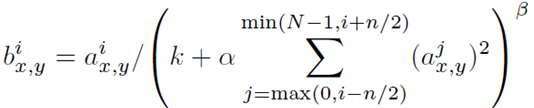
4. AlexNet 过拟合处理
4.1 数据扩充
减少图像数据过拟合最简单最常用的方法,是使用标签-保留转换,人为地扩大数据集。AlexNet 模型使用两种不同的形式,这两种形式都允许转换图像用很少的计算量从原始图像中产生,所以转换图像不需要存储在磁盘上。数据扩充的第一种形式由生成图像转化和水平反射组成。数据扩充的第二种形式包含改变训练图像中 RGB 通道的强度。

图5:数据扩充三种方式
4.2 Dropout
对某一层神经元,Dropout 做的就是以 0.5 的概率将每个隐层神经元的输出设置为零。以这种方式 “Dropped out” 的神经元既不用于前向传播,也不参与反向传播。所以每次提出一个输入,该神经网络就尝试一个不同的结构,所有这些结构之间共享权重。因为神经元不能依赖于其他特定神经元而存在,所以这种技术降低了神经元复杂的互适应关系。正因如此,要被迫学习更为鲁棒的特征,这些特征在结合其他神经元的一些不同随机子集时有用。如果没有 Dropout,AlexNet 网络会表现出大量的过拟合。
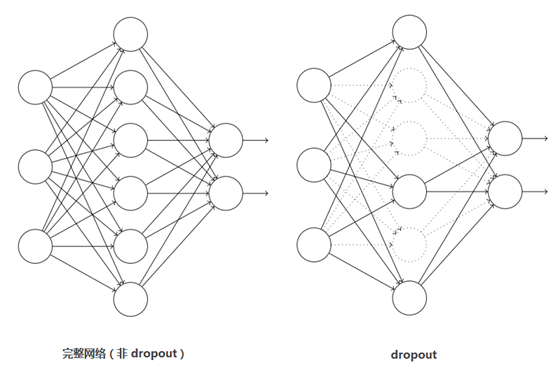
图6:Dropout示意图
5. 源码解读
5.1数据集和导入依赖库
# (1) Importing dependency
import keras
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout, Flatten, Conv2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
import numpy as np
np.random.seed(1000)
# (2) Get Data
import tflearn.datasets.oxflower17 as oxflower17
x, y = oxflower17.load_data(one_hot=True)
# (3) Create a sequential model
model = Sequential()
AlexNet 模型建立在千分类问题上,其算力对计算机要求很高。这里我们为了简单复现,使用了 TensorFlow 的数据集 oxflower17 ,此数据集对花朵进行17 分类,每个分类有 80 张照片。Keras 包含许多常用神经网络构建块的实现,例如层、目标、激活函数、优化器和一系列工具,可以更轻松地处理图像和文本数据。在 Keras 中有两类主要的模型:Sequential 顺序模型和使用函数式 API 的 Model 类模型。这里使用 Sequential 模型。
5.3 第一次卷积+池化
# 1st Convolutional Layer
model.add(Conv2D(filters=96, input_shape=(224,224,3), kernel_size=(11,11), strides=(4,4), padding='valid'))
model.add(Activation('relu'))
# Pooling
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='valid'))
# Batch Normalisation before passing it to the next layer
model.add(BatchNormalization())
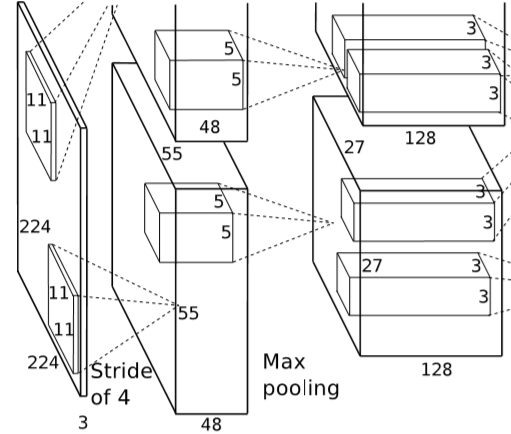
卷积层 1 大小 224X224X3,卷积核大小 11X11X3,数量 48,步长为 4。
关于卷积层的计算如下:
- 输入数据体尺寸为
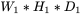
- 4个超参数(模型不会学习优化):
- 滤波器数量
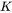
- 滤波器空间尺寸
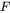
- 卷积运算步长
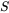
- 零填充数量(SAME 填充)
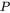
- 滤波器数量
- 输出数据体尺寸为
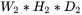
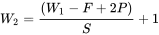
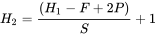
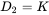
这里 W1=224,H1=224,D1=3,K=48,F=11,S=4,P=1.5。
计算卷积层 2 有 W2=(224-11+3)/4+1=55,同理 H2=55,D2=K*2=96。
经过卷积运算后,输出特征图像大小为 55X55X96。
这里使用了最大池化,步长为 S=2,则 W=(55-3)/2+1=27。
再经过池化后,输出特征图像大小为 27X27X96。
5.4 第二次卷积+池化
# 2nd Convolutional Layer
model.add(Conv2D(filters=256, kernel_size=(11,11), strides=(1,1), padding='valid'))
model.add(Activation('relu'))
# Pooling
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='valid'))
# Batch Normalisation
model.add(BatchNormalization())
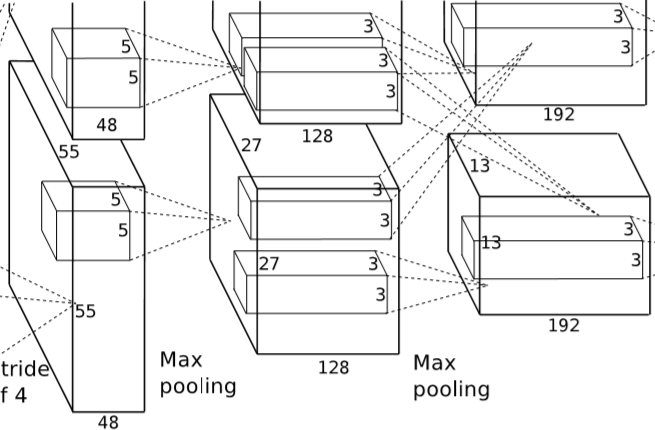
卷积层 2 大小 55X55X96,卷积核大小 5X5,数量为 128 个,步长为 1。
同理,可以计算卷积后得到特征图像大小为 27X27X256。
经过池化,输出特征图像大小为 13X13X256。**
5.5 第三次卷积
# 3rd Convolutional Layer
model.add(Conv2D(filters=384, kernel_size=(3,3), strides=(1,1), padding='valid'))
model.add(Activation('relu'))
# Batch Normalisation
model.add(BatchNormalization())
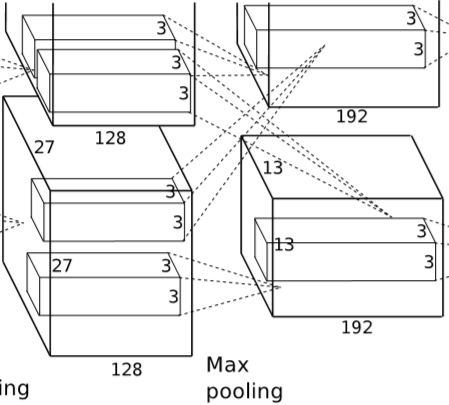
经过卷积后,特征图像大小为 13X13X384。
5.6 第四次卷积
# 4th Convolutional Layer
model.add(Conv2D(filters=384, kernel_size=(3,3), strides=(1,1), padding='valid'))
model.add(Activation('relu'))
# Batch Normalisation
model.add(BatchNormalization())
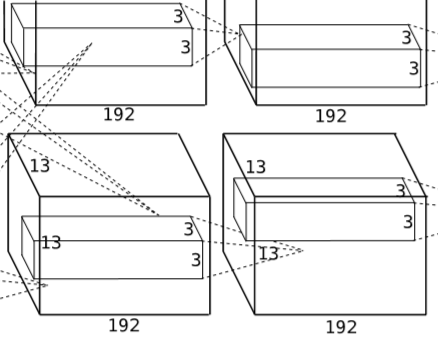
经过卷积后,特征图像大小为 13X13X284。
5.7 第五次卷积+池化
# 5th Convolutional Layer
model.add(Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), padding='valid'))
model.add(Activation('relu'))
# Pooling
model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='valid'))
# Batch Normalisation
model.add(BatchNormalization())
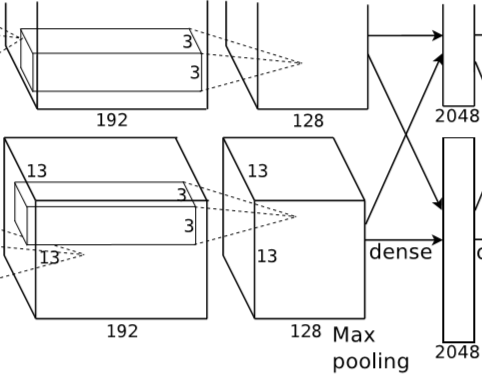
经过卷积后,特征图像大小为 13X13X256。
5.8 全连接层6
# Passing it to a dense layer
model.add(Flatten())
# 1st Dense Layer
model.add(Dense(4096, input_shape=(224*224*3,)))
model.add(Activation('relu'))
# Add Dropout to prevent overfitting
model.add(Dropout(0.4))
# Batch Normalisation
model.add(BatchNormalization())
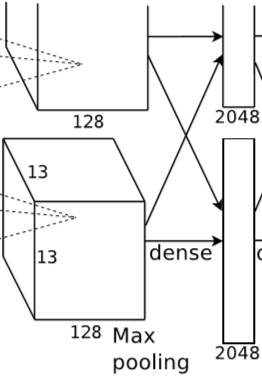
全连接层6大小为 6X6X256,共 4096 个神经元,输出 4096X1 的向量。
5.9 全连接层7
# 2nd Dense Layer
model.add(Dense(4096))
model.add(Activation('relu'))
# Add Dropout
model.add(Dropout(0.4))
# Batch Normalisation
model.add(BatchNormalization())
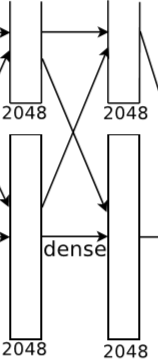
全连接层7大小为 4096X1,共 4096 个神经元,输出 4096X1 的向量。
5.10 全连接层8
# 3rd Dense Layer
model.add(Dense(1000))
model.add(Activation('relu'))
# Add Dropout
model.add(Dropout(0.4))
# Batch Normalisation
model.add(BatchNormalization())
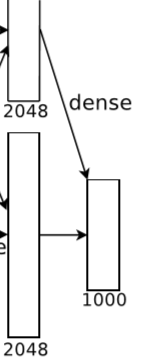
全连接层8输入大小为4096X1,共 4096 个神经元,输出 1000X1 的向量。
5.11 输出层及训练
# Output Layer
model.add(Dense(17))
model.add(Activation('softmax'))
model.summary()
# (4) Compile
model.compile(loss='categorical_crossentropy', optimizer='adam',metrics=['accuracy'])
# (5) Train
model.fit(x, y, batch_size=64, epochs=1, verbose=1, validation_split=0.2, shuffle=True)
最后在全连接层经过softmax激活函数后得到结果。
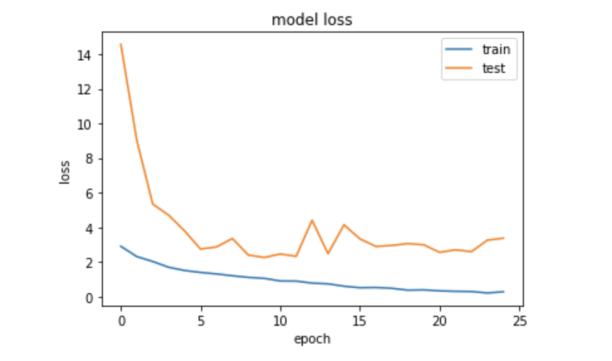
在结果损失函数图中,训练集的损失值在迭代23次时达到最小。由于数据量有限,测试集的损失值无法降到理想位置。(横坐标是迭代次数,纵坐标是损失函数的值)
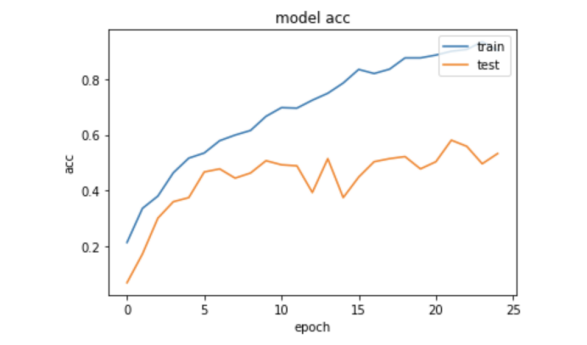
可以看出,在训练集上可以达到近90%的准确率。(横坐标是迭代次数,纵坐标是准确率)
由于数据集太小,测试集的准确率无法达到理想的值。
6. 总结与展望
目前,您可以在 Mo 平台中找到基于 AlexNet 的项目 Flower,此项目对原文的千分类进行整合,最终做成花卉的17分类。您在学习的过程中,遇到困难或者发现我们的错误,可以随时联系我们。
项目源码地址:www.momodel.cn:8899/explore/5cf…
总结一下 AlexNet 的主要贡献:
- 2 路 GPU 实现,加快了训练速度
- Relu 非线性激活函数,减少训练时间,加快训练速度
- 重叠池化,提高精度,不容易产生过拟合
- 为了减少过拟合,使用了数据扩充和 “Dropout”
- 使用局部响应归一化,提高精度
- 5 个卷积层+ 3 个全连接层,结构性能良好
7. 参考
- 论文:papers.nips.cc/paper/4824-…
- 论文翻译版:zhuanlan.zhihu.com/p/35400048
- 数据集:www.robots.ox.ac.uk/~vgg/data/f…
- Keras:keras.io/zh/
- 算法:www.mydatahack.com/building-al…
- 博客:my.oschina.net/u/876354/bl…
- 博客:www.ibm.com/developerwo…
关于我们
Mo(网址:momodel.cn)是一个支持 Python 的人工智能在线建模平台,能帮助你快速开发、训练并部署模型。
Mo 人工智能俱乐部 是由网站的研发与产品设计团队发起、致力于降低人工智能开发与使用门槛的俱乐部。团队具备大数据处理分析、可视化与数据建模经验,已承担多领域智能项目,具备从底层到前端的全线设计开发能力。主要研究方向为大数据管理分析与人工智能技术,并以此来促进数据驱动的科学研究。
目前俱乐部每周六在杭州举办以机器学习为主题的线下技术沙龙活动,不定期进行论文分享与学术交流。希望能汇聚来自各行各业对人工智能感兴趣的朋友,不断交流共同成长,推动人工智能民主化、应用普及化。

