

激活函数专题
可以直接参考维基百科的表
为什么需要激活函数
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层节点的输入都是上层输出的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了,那么网络的逼近能力就相当有限。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络表达能力就更加强大(不再是输入的线性组合,而是几乎可以逼近任意函数)。
Sigmoid函数
数学形式:
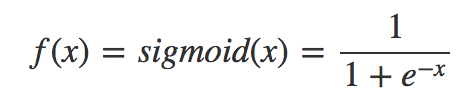
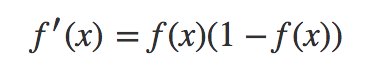
导数形式:
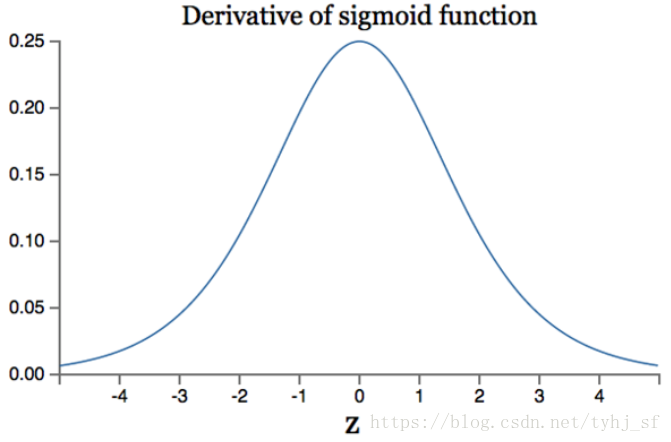
特点:
- 它能够把输入的连续实值变换为0和1之间的输出,特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1.
- 导数比较好求
- 导数最大值是0.25
缺点:
- 在深度神经网络中梯度反向传递时导致梯度爆炸和梯度消失,其中梯度爆炸发生的概率非常小,而梯度消失发生的概率比较大。
- Sigmoid 的output 不是0均值(即zero-centered)。
- 其解析式中含有幂运算,计算机求解时相对来讲比较耗时。
tanh函数
tanh函数解析式:
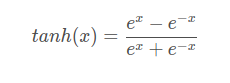
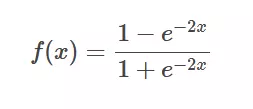
导数形式:
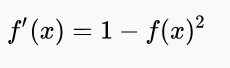
tanh函数及其导数的几何图像如下图:
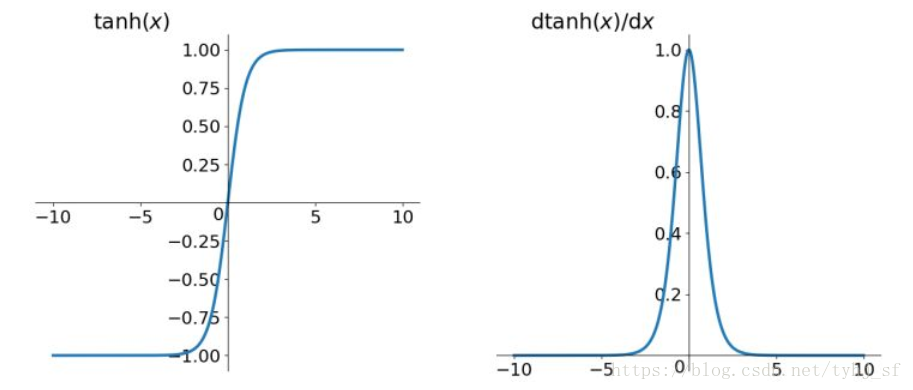
它解决了Sigmoid函数的不是zero-centered输出问题,其收敛速度要比sigmoid快,然而,梯度消失(gradient vanishing)的问题和幂运算的问题仍然存在。
Relu函数
Relu函数的解析式:
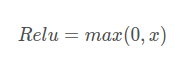
Relu函数及其导数的图像如下图所示:
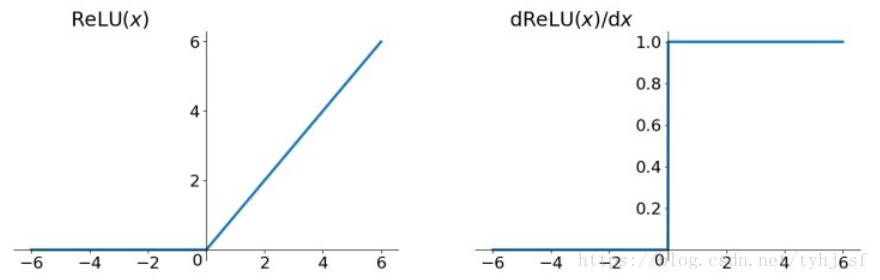
优点:
- 解决了gradient vanishing问题 (在正区间)
- 计算速度非常快,只需要判断输入是否大于0
- 收敛速度远快于sigmoid和tanh
缺点:
- ReLU的输出不是zero-centered
- Dead ReLU Problem,指的是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。
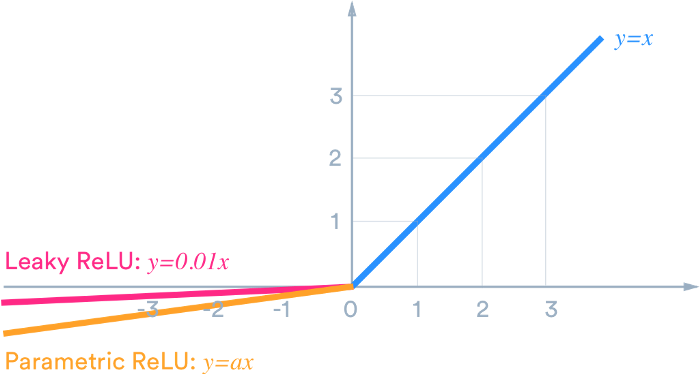
Leaky ReLU
函数表达式:
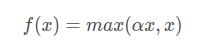
为了避免ReLU在x<0时的神经元死亡现象,添加了一个参数。
ELU函数
函数表达式:
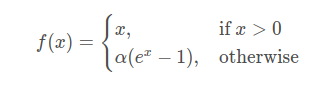
函数及其导数的图像如下图所示:
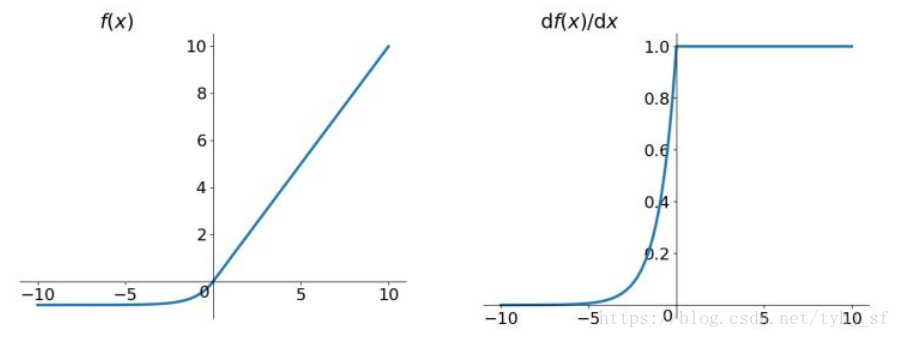
它结合了sigmoid和ReLU函数,左侧软饱和,右侧无饱和。右侧线性部分使得ELU能缓解梯度消失,而左侧软饱和能让对ELU对输入变化或噪声更鲁棒。ELU的输出均值接近于0,所以收敛速度更快。
MaxOut

选择合适的激活函数
- 选择输出具有zero-centered特点的激活函数以加快模型的收敛速度
- 如果使用 ReLU,那么一定要小心设置 learning rate,而且要注意不要让网络出现很多 “dead” 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU 或者 Maxout.
- 最好不要用 sigmoid,可以试试 tanh,不过可以预期它的效果会比不上 ReLU 和 Maxout.
优化器专题
词嵌入专题
可以将Word Embedding理解为一种映射,其过程是:将文本空间中的某个Word,通过一定的方法,映射或者说嵌入(Embedding)到另一个数值向量空间。
Word Embedding的类型
- 基于频率的Word Embedding(Frequency based embedding)
- 基于预测的Word Embedding(Prediction based embedding)
基于频率的Word Embedding又可细分为如下几种:
Count Vector TF-IDF Vector Co-Occurence Vector 其本质都是基于One-Hot表示法的,以频率为主旨的加权方法改进。
fasttext
FastText是Facebook开发的一款快速文本分类器。关于fastText具体实现原理,Facebook发表了两篇相关论文
- Bag of Tricks for Efficient Text Classification(高效文本分类技巧)
- Enriching Word Vectors with Subword Information(使用子字信息丰富词汇向量)
模型结构
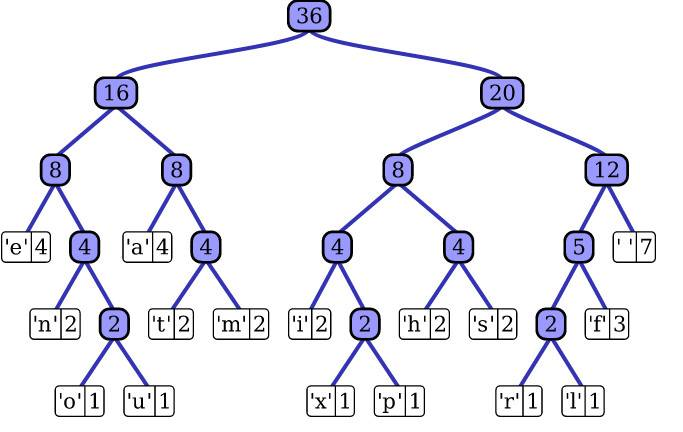
fastText 也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法建立用于表征类别的树形结构。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。
word2vec
glove
循环神经网络专题
RNN
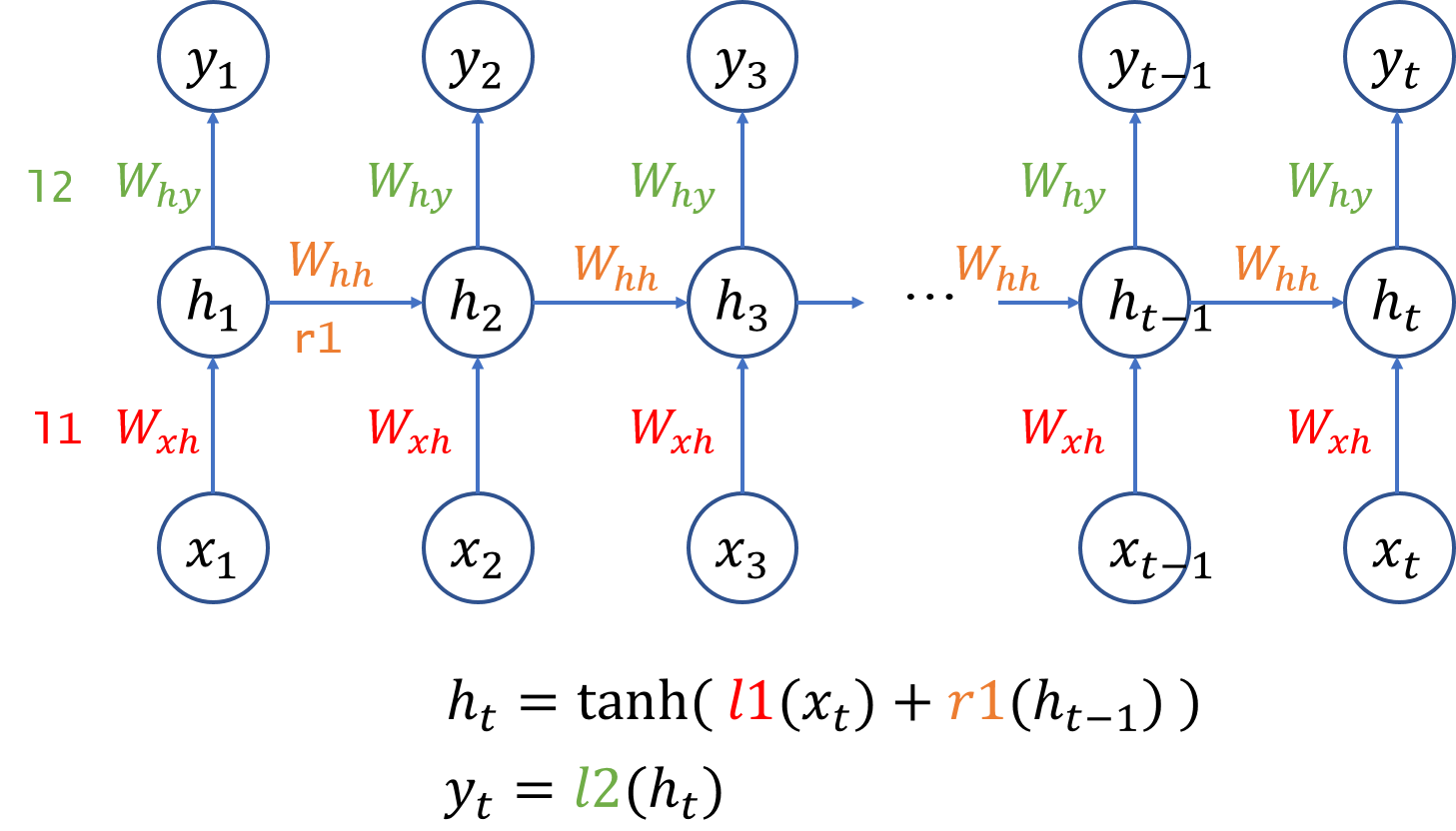
BPTT
梯度裁剪
循环神经网络中较容易出现梯度衰减或梯度爆炸。为了应对梯度爆炸,我们可以裁剪梯度(clip gradient)。假设我们把所有模型参数梯度的元素拼接成一个向量 g ,并设裁剪的阈值是 θ 。裁剪后的梯度:
的 L2 范数不超过 θ 。
LSTM
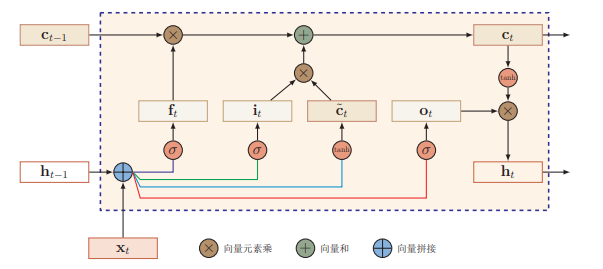
式 (1)∼(4) 的输入都一样,因而可以合并:
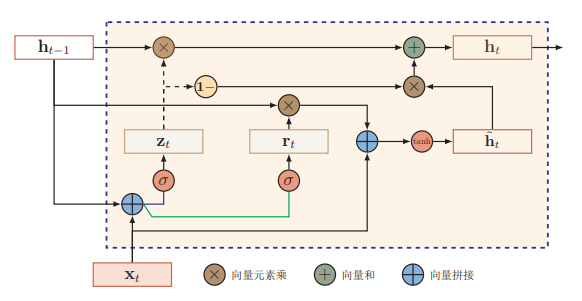
GRU
过拟合和正则化
BatchNormalization的作用
神经网络在训练的时候随着网络层数的加深,激活函数的输入值的整体分布逐渐往激活函数的取值区间上下限靠近,从而导致在反向传播时低层的神经网络的梯度消失。而BatchNormalization的作用是通过规范化的手段,将越来越偏的分布拉回到标准化的分布,使得激活函数的输入值落在激活函数对输入比较敏感的区域,从而使梯度变大,加快学习收敛速度,避免梯度消失的问题。
