

一、数据湖概念的提出
数据湖这一概念,最早是在2011年由CITO Research网站的CTO和作家Dan Woods首次提出。其比喻是:如果我们把数据比作大自然的水,那么各个江川河流的水未经加工,源源不断地汇聚到数据湖中。业界便对数据湖一直有着广泛而不同的理解和定义。“数据湖是一个集中化存储海量的、多个来源,多种类型数据,并可以对数据进行快速加工,分析的平台,本质上是一套先进的企业数据架构。”
"数据湖"的核心价值在于为企业提供了数据平台化运营机制。随着DT时代的到来,企业急需变革,需要利用信息化、数字化、新技术的利器形成平台化系统,赋能公司的人员和业务,快速应对挑战。而这一切的数据基础,正是数据湖所能提供的。
二、数据湖特点
数据湖本身,具备以下几个特点:
1)原始数据
海量原始数据集中存储,无需加工。数据湖通常是企业所有数据的单一存储,包括源系统数据的原始副本,以及用于报告、可视化、分析和机器学习等任务的转换数据。数据湖可以包括来自关系数据库(行和列)的结构化数据,半结构化数据(CSV,日志, XML, JSON),非结构化数据(电子邮件,文档, PDF)和二进制数据(图像,音频,视频)。也就是数据湖将不同种类的数据汇聚到一起。
2)按需计算
使用者按需处理,不需要移动数据即可计算。数据库通常提供了多种数据计算引擎供用户来选择。常见的包括批量、实时查询、流式处理、机器学习等。
3)延迟绑定
数据湖提供灵活的,面向任务的数据编订,不需要提前定义数据模型。
三、数据湖优缺点
任何事物都有两面性,数据湖有优点也同样存在些缺点。
优点包括:
- 数据湖中的数据最接近原生的。这对于数据探索类需求,带来很大便利,可以直接得到原始数据。
- 数据湖统一企业内部各个业务系统数据,解决信息孤岛问题。为横跨多个系统的数据应用,提供一种可能。
- 数据湖提供了全局的、统一的企业级数据概览视图,这对于数据质量、数据安全..直到整体的数据治理,甚至提高到数据资产层面都大有裨益。
- 数据湖改变了原有工作模式,鼓励人人了解、分析数据;而不是依赖于专门的数据团队的”供给”方式,可以提升数据运营效率、改善客户互动、鼓励数据创新。
缺点主要体现在:
- 对数据的归集处理程度明显缺失,对于试图直接使用数据的用户来说显得有些过于“原材料”化,且数据太过冗余。应对这一问题,可通过”数据接入+数据加工+数据建模”的方式来解决。
- 对数据湖基础层的性能有较高要求,必须依托高性能的服务器进行数据处理过程。这主要是来自于海量数据、异构多样化数据、延迟绑定模式等带来的问题。
- 数据处理技能要求高。这也主要是因为数据过于原始带来的问题。
四、数据湖与关联概念
4.1 数据湖 vs 数据仓库
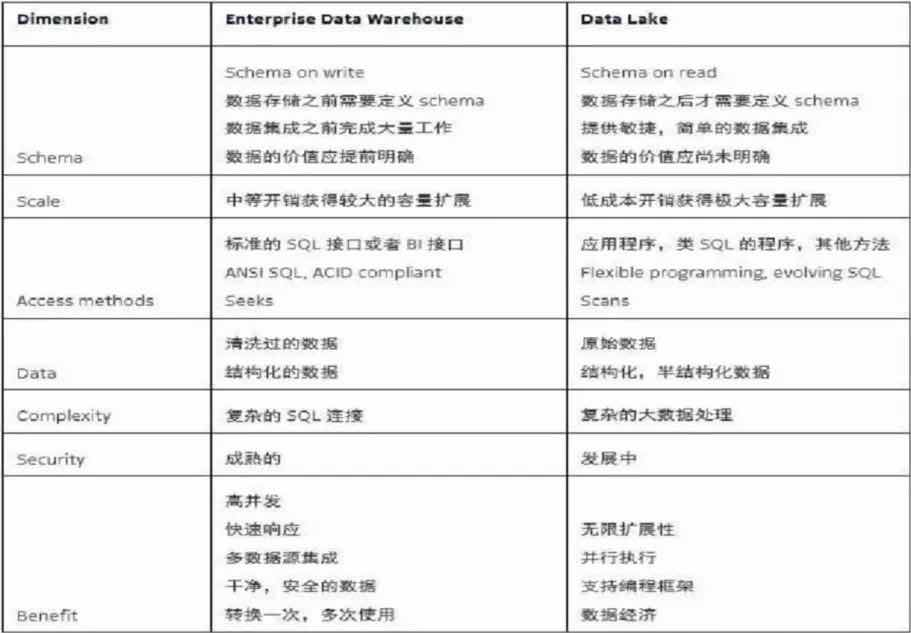
数据湖建设思路从本质上颠覆了传统数据仓库建设方法论。传统的企业数据仓库则强调的是整合、面向主题、分层次等思路。其两者并不是对等的概念,更多是包含;即数据仓库作为数据湖的一类“数据应用”存在。两者可从以下维度进行对比:
1)存储数据类型
- 数据仓库是存储清洗加工过的,可信任的、结构良好的数据;
- 数据湖则是存储大量原始数据,包括结构化的、半结构化的和非结构化的数据。在我们世界中,主要是由原始的、混乱的、非结构化的数据组成。随着“混乱数据”的不断升级,人们对它的兴趣也不断增长,想要更好的理解它、从其中获取价值、并根据它做出决策。这就得需要一个灵活、敏捷、经济且相对轻松的解决方案,然而这些都不是数据仓库的强项。而且当有新的需求提出时,传统数据仓库又难以快速随之变化。
2)处理数据方式
- 如果需要加载到数据仓库中的数据,我们首先需要定义好它,这叫做写时模式(Schema-On-Write)。
- 而对于数据湖,您只需加载原始数据,然后,当您准备使用数据时,就给它一个定义,这叫做读时模式(Schema-On-Read)。
这是两种截然不同的数据处理方法。因为数据湖是在数据到使用时再定义模型结构,因此提高了数据模型定义的灵活性,可满足更多不同上层业务的高效率分析诉求。
3)工作合作方式
- 传统的数据仓库的工作方式是集中式的,业务人员给需求到数据团队,数据团队根据要求加工、开发成维度表,供业务团队通过BI报表工具查询。
- 数据湖更多是开放、自助式的(self-service),开放数据给所有人使用,数据团队更多是提供工具、环境供各业务团队使用(不过集中式的维度表建设还是需要的),业务团队进行开发、分析。
4)其他
还有很多方面,我们通过下图简要对比。
4.2 数据湖 vs 大数据
数据湖的技术实现,与大数据技术紧密结合。
- 通过Hadoop存储成本低的特点,将海量的原始数据、本地数据、转换数据等保存在Hadoop中。这样所有数据都在一个地方存储,能给后续的管理、再处理、分析提供基础。
- 通过Hive、Spark等低成本处理能力(相较于RDBMS),将数据交给大数据库平台剂型处理。此外,还可通过Storm、Flink等支持流式处理等特殊计算方式。
- 由于Hadoop的可扩展性,可以很方便地实现全量数据存储。结合数据生命周期管理,可做到全时间跨度的数据管控。
4.3 数据湖 vs 云计算
云计算采用虚拟化、多租户等技术满足业务对服务器、网络、存储等基础资源的最大化利用,降低企业对IT基础设施的成本,为企业带来了巨大的经济性;同时云计算技术实现了主机、存储等资源快速申请、使用,则同样为企业带来了更多的管理便捷性。在构建数据湖的基础设施时,云计算技术可以发挥很大作用。此外,像AWS、MicroSoft、EMC等均提供了云端的数据湖服务。
4.4 数据湖 vs 人工智能
近些年,人工智能技术再一次飞速发展,训练和推理等需要同时处理超大的,甚至是多个数据集,这些数据集通常是视频、图片、文本等非结构化数据,来源于多个行业、组织、项目,对这些数据的采集、存储、清洗、转换、特征提取等工作是一个系列复杂、漫长的工程。数据湖需要为人工智能程序提供数据快速收集、治理、分析的平台,同时提供极高的带宽、海量小文件存取、多协议互通、数据共享的能力,可以极大加速数据挖掘、深度学习等过程。
4.5 数据湖 vs 数据治理
传统方式下,数据治理工作往往是在数据仓库中。那么在构建企业级数据湖后,对数据治理的需求实际更强了。因为与”预建模”方式的数仓不同,湖中的数据更加分散、无序、不规格化等,需要通过治理工作达到数据”可用”状态,否则数据湖很可能会”腐化”成数据沼泽,浪费大量的IT资源。平台化的数据湖架构能否驱动企业业务发展,数据治理至关重要。这也是对数据湖建设的最大挑战之一。
4.6 数据湖 vs 数据安全
数据湖中存放有大量原始及加工过的数据,这些数据在不受监管的情况下被访问是非常危险的。这里是需要考虑必要的数据安全及隐私保护问题,这些是需要数据湖提供的能力。但换种角度来看,将数据集中在数据湖中,其实是有利于数据安全工作的。这要比数据分散在企业各处要好的多。
五、数据湖架构

5.1 数据接入
在数据接入方面,需提供适配的多源异构数据资源接入方式,为企业数据湖的数据抽取汇聚提供通道。提供如下能力:
- 数据源配置:支持多种数据源,包括但不限于数据库、文件、队列、协议报文等。
- 数据采集:支持对应数据源的采集动作,需完成结构解析、清洗、标准化格式等。
- 数据同步:支持数据同步到其他数据源,包括必要的清洗、加工、转换等。
- 数据分发:支持数据的共享分发,将数据以多种形式(对象、API等)发布出来。
- 任务调度:任务管理、监控、日志、策略等。
- 数据加工:支持对数据的加密、脱敏、规格化、标准化等加工逻辑。
5.2 数据存储
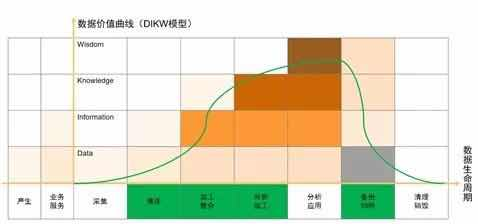
许多企业通常忽略数据积累的价值,数据需要从企业的各个方面持续的收集、存储,才有可能基于这些数据挖掘出价值信息,指导业务决策,驱动公司发展。因此数据湖需要提供的核心能力之一就是存储能力。通过一套数据存储池,可有效解决企业中的数据烟囱问题,提供统一的命名空间,多协议互通访问,实现数据资源的高效共享,减少数据移动。当然数据在湖中也不能无序存放,这里需要有个数据生命周期的概念。需要根据数据的不同阶段,根据其价值、成本因素,设计可行的存储方案。
5.3 数据计算
数据湖需要提供多种数据分析引擎,来满足数据计算需求。需要满足批量、实时、流式等特定计算场景。此外,向下还需要提供海量数据的访问能力,可满足高并发读取需求,提高实时分析效率。
5.4 数据应用
在基本的计算能力之上,数据湖需提供批量报表、即席查询、交互式分析、数据仓库、机器学习等上层应用,还需要提供自助式数据探索能力。
作者:韩锋
首发于公众号《韩锋频道》,欢迎关注。
来源:宜信技术学院
