

本文同步发表在:豆米的博客
前言
趋于好奇心去尝试了下LeetCode,果不其然,蛮有意思的,随便选了一道题目做,一开始觉得还是蛮容易的,最后提交答案的时候,果然还是有坑,竟然还考察程序运行时间,这么一整,更有意思了。下面以这道题目来讲讲涉及的几个知识点以及解法的不断演进,仅供参考。
题目来源在这里:传送门
完整的题目文本是:
我们对 0 到 255 之间的整数进行采样,并将结果存储在数组 count 中:count[k] 就是整数 k 的采样个数。
我们以 浮点数 数组的形式,分别返回样本的最小值、最大值、平均值、中位数和众数。其中,众数是保证唯一的。
我们先来回顾一下中位数的知识:
如果样本中的元素有序,并且元素数量为奇数时,中位数为最中间的那个元素;
如果样本中的元素有序,并且元素数量为偶数时,中位数为中间的两个元素的平均值。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/statistics-from-a-large-sample
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
提示:
count.length == 256
1 <= sum(count) <= 10^9
计数表示的众数是唯一的
答案与真实值误差在 10^-5 以内就会被视为正确答案
最初的解法
一开始,看着题目觉得很容易嘛,拿个数组整理一下这些样本值不就行了。于是有了第一种解法:
var sampleStats = function(count) {
let samples = []
let mode = 0 // 众数
let maxModeCount = 0 // 某个数字出现的最多次数0
count.forEach((item, index) => {
if (item) {
const arr = new Array(item).fill(index)
samples = [...samples, ...arr]
if (item > maxModeCount) {
mode = index
maxModeCount = item
}
}
})
const aver = samples.reduce((sum, index) => sum += index, 0) / samples.length
let middle = 0
if (samples.length % 2 === 0) {
middle = (samples[samples.length / 2] + samples[samples.length / 2 - 1]) / 2
} else {
middle = samples[Math.floor(samples.length / 2)]
}
samples.sort()
const min = samples[0]
const max = samples[samples.length - 1]
return [min.toFixed(5), max.toFixed(5), aver.toFixed(5), middle.toFixed(5), uniqueIndex.toFixed(5)]
};
就这样执行这段代码,以下面这个输入值来做测试的时候,完美通过:
[0,1,3,4,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
咦,这么简单吗?于是果断提交了答案。眼尖基础好的童鞋们是不是看出有什么不对的吗?(倒数3秒)
1
2
3
然后,等着远程服务器跑他们的测试用例的时候给我返回了错误“执行时间超时”。哇?这是什么提示?LeetCode还友好地提示为啥会有“执行时间超时”的错误提示,并且将执行到那个单元测试用例一并展示出来,不得不说这产品做得很不错呀。
当时错误的测试用例是这个:
[264,912,1416,1903,2515,3080,3598,4099,4757,5270,5748,6451,7074,7367,7847,8653,9318,9601,10481,10787,11563,11869,12278,12939,13737,13909,14621,15264,15833,16562,17135,17491,17982,18731,19127,19579,20524,20941,21347,21800,22342,21567,21063,20683,20204,19818,19351,18971,18496,17974,17677,17034,16701,16223,15671,15167,14718,14552,14061,13448,13199,12539,12265,11912,10931,10947,10516,10177,9582,9102,8699,8091,7864,7330,6915,6492,6013,5513,5140,4701,4111,3725,3321,2947,2357,1988,1535,1124,664,206,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
于是我在自己浏览器上跑了下,并加进去执行时间的打印,我去,执行时间达到6秒多!!!难怪要报错。看着这段输入样本,就知道这个采样数据很大一个,难怪叫做“大样本统计”,轻敌轻敌了~
于是想到forEach循环的内容可能是耗时的最大原因,大家知道哪几个函数是耗时的最大因素吗?(倒计时3秒)
1
2
3
继续优化
一开始我就想,这样写貌似有点浪费循环了,好多值在循环的时候其实已经可以得到的,没必要使用reduce或sort之类的函数啦,于是改写成这样:
var sampleStats = function(count) {
let samples = []
let mode = 0 // 众数
let maxModeCount = 0 // 某个数字出现的最多次数
let isFirstFoundMin = false // 第一次找到最小值
let min = 0
let max = 0
let sum = 0
count.forEach((item, index) => {
if (!item) { return }
const arr = new Array(item).fill(index)
samples = [...samples, ...arr]
if (item > maxModeCount) {
mode = index
maxModeCount = item
}
if (index > max) {
max = index
}
if (!isFirstFoundMin) {
min = index
isFirstFoundMin = true
}
sum += item * index
})
const length = samples.length
let middle = 0
if (length % 2 === 0) {
middle = (samples[length / 2] + samples[length / 2 - 1]) / 2
} else {
middle = samples[Math.floor(length / 2)]
}
return [min.toFixed(5), max.toFixed(5), sum/length.toFixed(5), middle.toFixed(5), mode.toFixed(5)]
};
少了几个函数的调用,但是,耗时时间没有减少多少?于是我将视线瞄准到了forEach循环体。forEach循环的最大次数是256次,也不算太多次,但是每次循环耗时时间却很久,因为我们使用了new Array和解构赋值。
为什么new Array和解构赋值很耗时?
下图是解构赋值在上述输入样本的时候,每次循环的耗时(当前电脑配置是Mac Pro: 2.2 GHz Intel Core i7)
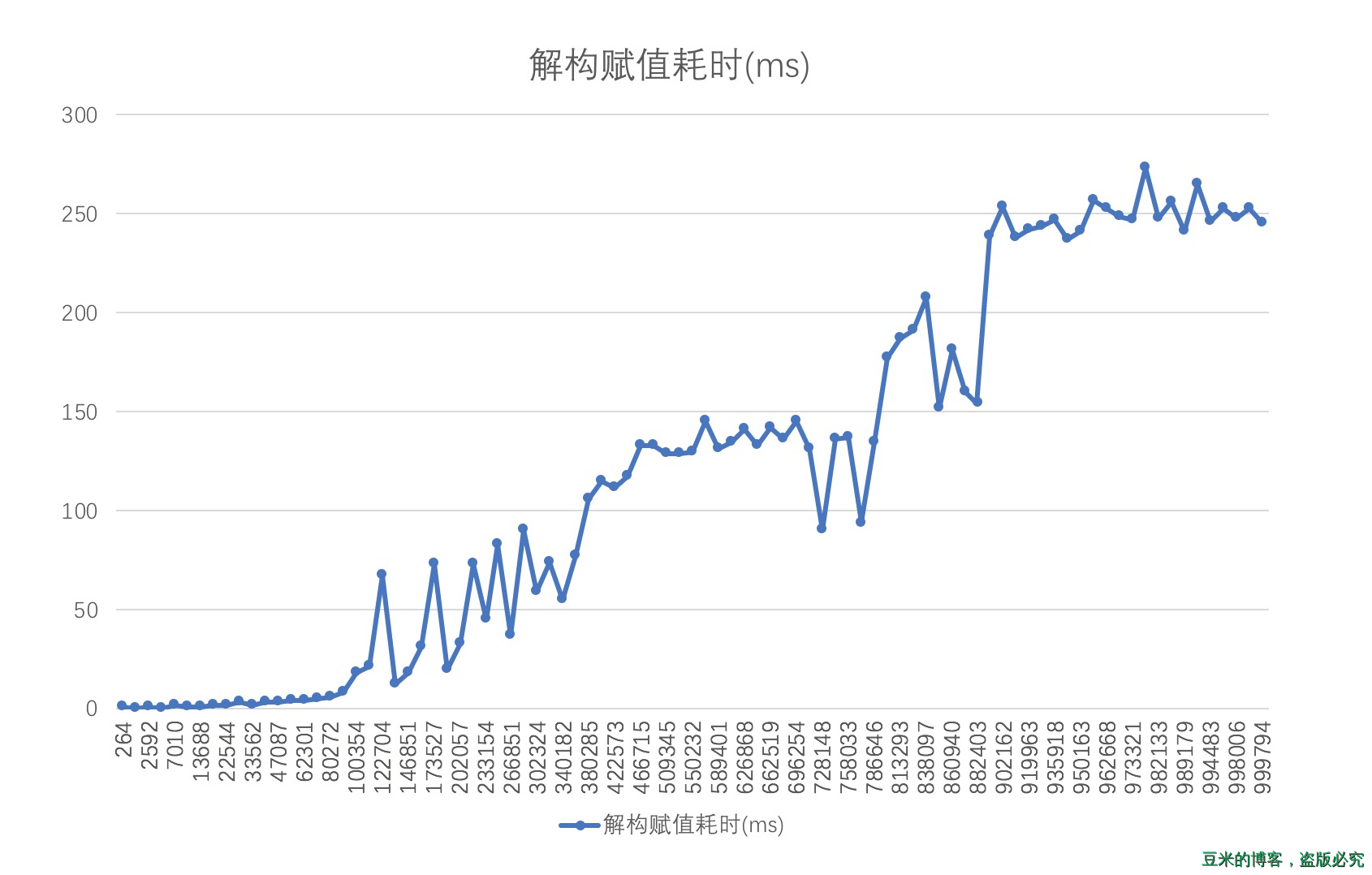
可以看出随着数组的长度不断变大,每次解构赋值耗时越来越长。此时因为初始化数组的最大长度22342,所以new Array的耗时没有明显的起伏,但是在稍后提到的一个更大型的样本中,这个函数的瓶颈就凸显的非常明显。
那为什么会这样呢?原因就是二者的底层实现没有那么纯粹。我们先来看解构赋值的大致底层实现:(真正实现参考v8源码)
function(arr) {
const result = [];
const iterator = arr[Symbol.iterator]();
const next = iterator.next;
for ( ; ; ) {
const iteratorResult = next.call(iterator);
if (iteratorResult.done) break;
result.push(iteratorResult.value);
}
return result;
}
通过这个函数可以看出,解构赋值为了考虑到所有的情况,也为了遵循迭代器的规则,不得不使用了下面三个造成速度变慢的流程:
- 需要创建
iterator - 每次循环的时候需要创建并查询
iteratorResult对象 - 在每次循环的时候不断变大
result数组的长度,这样就会导致不断重复地重分配辅助存储器。
而new Array也是类似的,需要校验参数的个数,如果只有一个参数的话,还需要校验参数的类型,一系列的动作下来会导致该方法比直接使用[]或者for来得慢,在大数据量的时候。
因此我们改进写法。
继续优化2
接下去我们不使用上面,转而这样实现:
var sampleStats = function(count) {
let samples = []
let mode = 0 // 众数
let maxModeCount = 0 // 某个数字出现的最多次数
let isFirstFoundMin = false // 第一次找到最小
let min = 0
let max = 0
let sum = 0
count.forEach((item, index) => {
if (!item) { return }
for (var i = 0; i < item; i++) {
samples.push(index)
}
if (item > maxModeCount) {
mode = index
maxModeCount = item
}
if (index > max) {
max = index
}
if (!isFirstFoundMin) {
min = index
isFirstFoundMin = true
}
sum += item * index
})
const length = samples.length
let middle = 0
if (length % 2 === 0) {
middle = (samples[length / 2] + samples[length / 2 - 1]) / 2
} else {
middle = samples[Math.floor(length / 2)]
}
return [min.toFixed(5), max.toFixed(5), sum/length.toFixed(5), middle.toFixed(5), mode.toFixed(5)]
};
执行时间一下子缩短到了几十毫秒了。于是自信地以为这下子提交答案应该可以通过了吧。没想到LeetCode的测试用例竟然还没完。提交没多久,页面又展示错误了,这下子发现测试样本改成这样子:
[2725123,2529890,2612115,3807943,3002363,3107290,2767526,981092,896521,2576757,2808163,3315813,2004022,2516900,607052,1203189,2907162,1849193,1486120,743035,3621726,3366475,639843,3836904,462733,2614577,1881392,85099,709390,3534613,360309,404975,715871,2258745,1682843,3725079,564127,1893839,2793387,2236577,522108,1183512,859756,3431566,907265,1272267,2261055,2234764,1901434,3023329,863353,2140290,2221702,623198,955635,304443,282157,3133971,1985993,1113476,2092502,2896781,1245030,2681380,2286852,3423914,3549428,2720176,2832468,3608887,174642,1437770,1545228,650920,2357584,3037465,3674038,2450617,578392,622803,3206006,3685232,2687252,1001246,3865843,2755767,184888,2543886,2567950,1755006,249516,3241670,1422728,809805,955992,415481,26094,2757283,995334,3713918,2772540,2719728,1204666,1590541,2962447,779517,1322374,1675147,3146304,2412486,902468,259007,3161334,1735554,2623893,1863961,520352,167827,3654335,3492218,1449347,1460253,983079,1135,208617,969433,2669769,284741,1002734,3694338,2567646,3042965,3186843,906766,2755956,2075889,1241484,3790012,2037406,2776032,1123633,2537866,3028339,3375304,1621954,2299012,1518828,1380554,2083623,3521053,1291275,180303,1344232,2122185,2519290,832389,1711223,2828198,2747583,789884,2116590,2294299,1038729,1996529,600580,184130,3044375,261274,3041086,3473202,2318793,2967147,2506188,127448,290011,3868450,1659949,3662189,1720152,25266,1126602,1015878,2635566,619797,2898869,3470795,2226675,2348104,2914940,1907109,604482,2574752,1841777,880254,616721,3786049,2278898,3797514,1328854,1881493,1802018,3034791,3615171,400080,2277949,221689,1021253,544372,3101480,1155691,3730276,1827138,3621214,2348383,2305429,313820,36481,2581470,2794393,902504,2589859,740480,2387513,2716342,1914543,3219912,1865333,2388350,3525289,3758988,961406,1539328,448809,1326527,1339048,2924378,2715811,376047,3642811,2973602,389167,1026011,3633833,2848596,3353421,1426817,219995,1503946,2311246,2618861,1497325,3758762,2115273,3238053,2419849,2545790]
计算了一下,数组长度达到了504541132,上亿了诶~,前端报错直接是栈溢出了,尴尬了,所以说就不能用sample存储数组,毕竟浪费的内存很多。于是有了下面的这种解法:
继续优化之三
因为不使用sample数组,影响比较大的是计算中位数,我们得根据采样数组的长度得到中间值的index,如果数组长度是偶数的话,需要判断这个中间值是否刚好位于新的一组值的第一个位置,如果是的话,需要获取上一组值,然后相加除以2。举个例子如下:
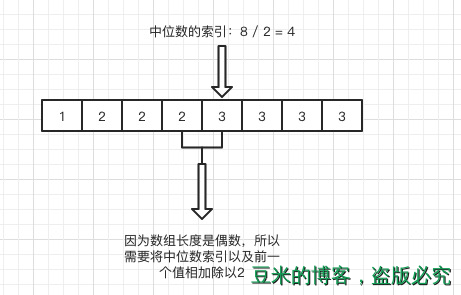
于是我们的改进方法如下:
var sampleStats = function(count) {
const min = count.findIndex(item => item)
let mode = 0 // 众数
let maxModeCount = 0 // 某个数字出现的最多次数
let isFirstFoundMax = false // 第一次找到最大值
let max = 0
let sum = 0
let samplesLength = 0
for(i = count.length - 1; i >= 0; i--) {
if (count[i] && !isFirstFoundMax) {
max = i;
isFirstFoundMax = true
}
if (count[i]) {
sum += i * count[i]
samplesLength += count[i]
}
if (count[i] > maxModeCount) {
mode = i
maxModeCount = count[i]
}
}
const isOdd = samplesLength % 2 === 0
const middleIndex = isOdd ? samplesLength / 2 : Math.floor(samplesLength / 2)
let tempIndex = 0
let middleValue = 0
for (i = 0; i < count.length; i++) {
tempIndex += count[i]
if (tempIndex === middleIndex) {
middleValue = (i + i + 1) / 2
break
} else if (tempIndex > middleIndex) {
middleValue = i
break;
}
}
return [min.toFixed(5), max.toFixed(5), sum/samplesLength.toFixed(5), middleValue.toFixed(5), mode.toFixed(5)]
};
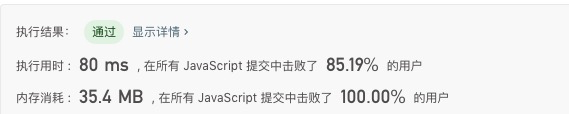
最后提交答案,终于跑过了LeetCode的测试用例,至此这道题目算是通过了。
最后
体验了一把LeetCode有了下面的几个想法:
- 既然是算法题,确实应该好好审题,并且把最大的情况考虑掉
- 执行的时间和空间都要重复考虑
- 仔细审题,尤其是提示
各位看官最后不知道这道题是否还有更优的解法(毕竟还有14.81%的解法比这个解法还快的),欢迎留言相互探讨~
