

原创作者,公众号【程序员读书】,欢迎关注公众号,转载文章请注明出处哦。
相信很多做开发的小伙伴对Elasticsearch应该都听过或有一定的了解吧,毕竟Elasticsearch是时下最火的开源全文搜索引擎。
除了搜索功能之外,Elasticsearch也是一款大数据分析引擎,可以用于大数据实时分析,比如用于日志分析、指标监控、信息安全等方面,而要完成这些功能,则还需要与其他组件配合,这便是我们现在要讲的Elastic Stack。
什么是Elastic Stack?
Elastic Stack是一套构建在开源基础之上,可以让我们安全可靠地采集任何来源、任何格式的数据,并且实时地对数据进行搜索、分析和可视化工具链。
从上面这段定义可以看出Elastic Stack的几个特点:采集、转换、搜索、分析、可视化,这些功能分别由ElasticSearch、Kibana、Beats、Logstash这几个组件来实现。
Elasticsearch
Elasticsearch是Elastic Static的核心,可以用Elasticsearch来存储我们的文档数据,利用Elasticsearch强大的搜索和分析功能为我们的网站提供支持,ElasticSearch是分布式搜索引擎和大数据实时分析引擎,可以实时分析计算数据并得出结果,还可以通过Kibana的各种图表将分析结果可视化。
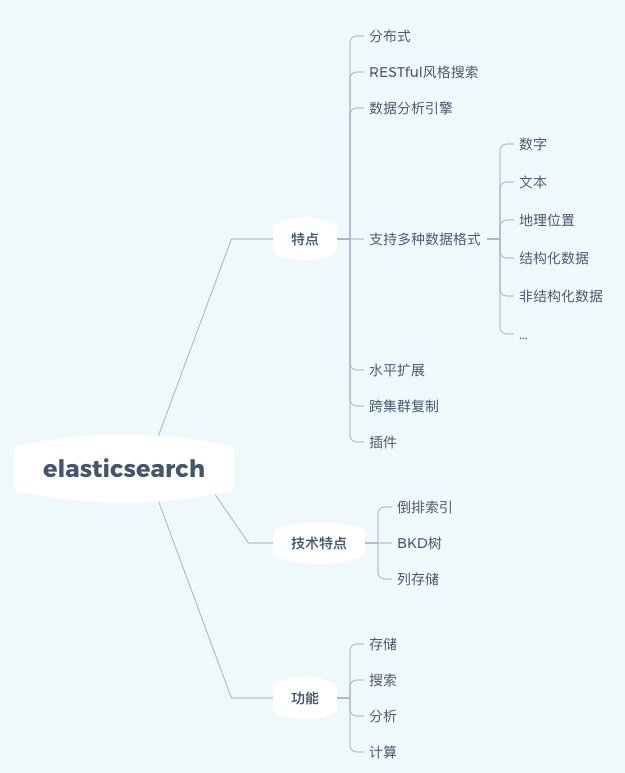
下面的思维导图,是我学习Elasticsearch的一点简单的梳理:
Kibana
一图胜万言,Kibana是Elastic Stack产品中的一款可视化工具,支持柱状图、线状图、饼图、旭日图等多种图形,还可以使用Vega 语法来设计独属于我们自己的可视化图形。
通过Kibana可以实时呈现Elastichsearch聚合分析的数据,看到数据的趋势,为决策提供依据。
Beats
Beats是一个轻量型采集器的平台,集合了多种轻量级的、单一的数据采集器,几乎可以兼容所有的数据类型,这些采集器可以从成千上万的系统中采集数据并向Logstash和Elasticsearch发送数据。
下面是Beats支持的采集器列表:
- Filebeat:文件文件
- Metricbeat:指标数据
- Packetbeat:网络数据
- Winlogbeat:Windows事件日志
- Auditbea:审计数据
- Heartbeat:运行时间监控
- Functionbeat:无需服务器的采集器

当然,如果上面提供的采集器无法满足我们的需求,Beats也支持自定义采集器。
Logstash
Logstash是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的存储库中,一般就是发送到Elasticsearch当中。
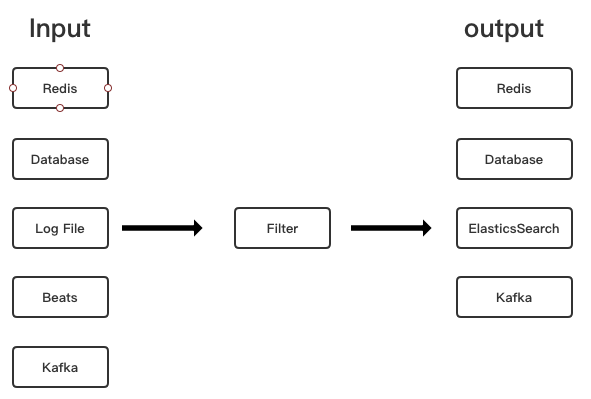
从上面的定义中,我们可以看出,Logstash与Beats有类似的功能,而实际上,Logstash的功能比Beats更强大,Logstash支持丰富的过滤器,可以通过过滤器将非常结构化的数据转换成结构化的数据,如下图所示:
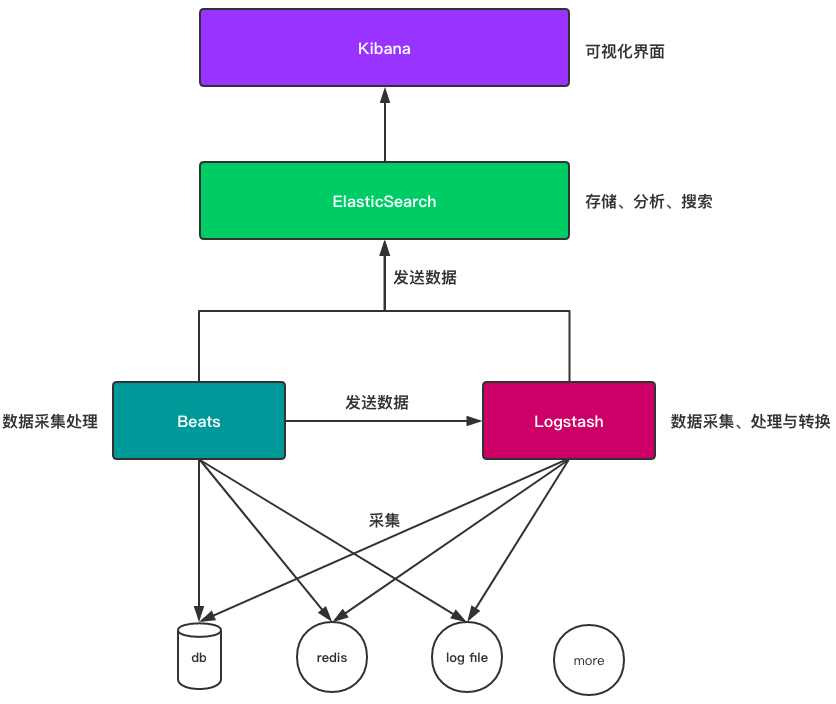
通过上面的介绍,我们应该对Elastich Stack中各个组件的功能有所了解,下面我们通过示图意了解一下各组件之间的关系:
安装
Elastic Stack支持多种不同的操作系统,不同的操作系统也支持多种不同的安装方式,我们只是介绍在Linux操作系统的安装过程,使用的版本是最新的7.2。
ElasticSearch安装
在7.0之前的版本,安装Elasticsearch之前需要先安装Java SDK,在7.0之后,在Elasticsearch的安装中包含了Java SDK
下载安装
ElasticSearch支持多种操作系统,下面的示例是在Linux上的安装过程:
# 下载压缩安装包
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.2.0-linux-x86_64.tar.gz
# 解压
$ tar -zxvf elasticsearch-7.2.0-linux-x86_64.tar.gz
# 修改安装目录名称,不改也可以的
$ mv elasticsearch-7.2.0-linux-x86_64 /usr/local/elasticsearch
安装的过程非常简单,直接解压便可以了。
启动ElasticSearch
# 进入到elasticsearch安装目录
$ cd /usr/local/elasticsearch
# 在elasticsearch安装目录运行以下命令
$ bin/elasticsearch
在Docker上运行
除了自己下载安装外,可以elasticsearch的docker镜像进行安装,这种方式也很方便。
# 拉取elasticsearch的docker镜像
$ docker pull docker.elastic.co/elasticsearch/elasticsearch:7.2.0
# 运行镜像,创建容器
$ docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.2.0
测试是否安装成功
在浏览器输入地址http://localhost:9200,或使用在命令行中使用curl工具,输入以下语句:
$ curl http://localhost:9200
如果在浏览器或命令中输出如下Elasticsearch的状态信息,则说明已经安装成功。
{
"name" : "localhost.localdomain",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IcfpUJx8TOOU9udd2fXWkw",
"version" : {
"number" : "7.2.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "508c38a",
"build_date" : "2019-06-20T15:54:18.811730Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
在安装成功后,便可以调用Elasticsearch提供的restful api,往Elasticsearch创建索引和文档,开始Elasticsearch的学习了。
Kibana安装
下载安装
# 使用wget命令获取安装包
$ wget https://artifacts.elastic.co/downloads/kibana/kibana-7.2.0-linux-x86_64.tar.gz
#解压
$ tar -zxvf kibana-7.2.0-linux-x86_64.tar.gz
# 修改安装目录名称,不改也可以的
$ mv kibana-7.2.0-linux-x86_64 /usr/local/kibana
上面简单两条命令便已经安装好了kibana。
启动kibana
安装成功后,可以使用以下命令启动kibana。
# 进入kibana安装目录
$ cd /usr/local/kibana
# 运行命令启动
$ bin/kibana
测试是否安装成功
安装成功后,Kibana默认运行在5601端口,因此在浏览器中输入http://localhost:5601,如果安装成功,则会进入如下界面:
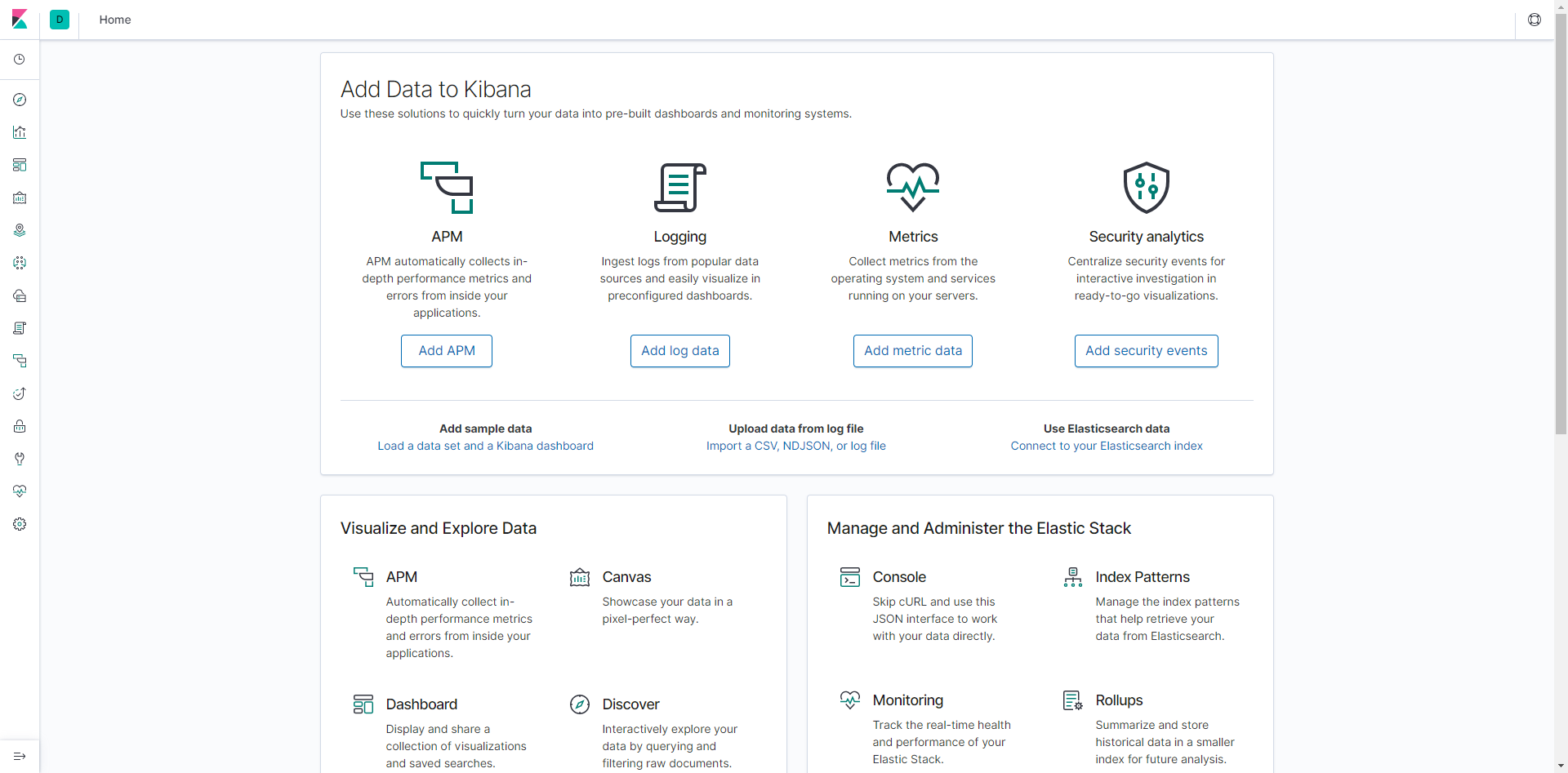
Beats安装
Beats是一个多种单一采集器的平台,每一种采集器都需要单独安装,因此我们可以根据自己的需要进行安装,下面以Filebeat安装为例:
# 下载安装包
$ wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.2.0-linux-x86_64.tar.gz
# 解压
$ tar -zxvf filebeat-7.2.0-linux-x86_64.tar.gz
# 修改安装目录名称,不改也可以的
$ mv filebeat-7.2.0-linux-x86_64 /usr/local/filebeat
启动filebeat
# 启动
/usr/local/filebeat/filebeat -e -c filebeat.yml
Logstash安装
下载安装
# 下载
$ wget https://artifacts.elastic.co/downloads/logstash/logstash-7.2.0.tar.gz
#解压
$ tar -zxvf logstash-7.2.0.tar.gz
# 修改安装目录名称,不改也可以的
$ mv logstash-7.2.0 /usr/local/logstash
启动Logstash
启动logstash时,需要指定一个配置文件,配置文件的结构一般是下面的结构,input指定数据来源,filter指定过滤器,output指定输出。
input {
...
}
filter {
...
}
output {
...
}
比如我们使用下面的logstash.conf文件,将一个txt文件的每一行记录导入到elasticsearch中:
input {
file {
path => "/data/users.txt"
start_position => beginning
}
}
filter {
txt {
separator => ","
columns => ["id","username","age"]
}
}
output {
elasticsearch {
hosts => "http://localhost:9200"
index => "user_list"
document_id => "%{id}"
}
stdout {}
}
接下来使用下面的命令,便可以启动logstash了。
# 运行
logstash -f logstash.conf
小结
在这篇文章中,我们只是对Elastic Stack建立一个全面的了解以及如何安装,而对Elastic Stack的使用与开发,则需要在后续中更多地学习。
你的关注,是我写作路上最大的鼓励!

