

项目里面的一个分表用到了sharding-jdbc
当时纠结过是用mycat还是用sharding-jdbc的, 但是最终还是用了sharding-jdbc, 原因如下:
1. mycat比较重, 相对于sharding-jdbc只需导入jar包就行, mycat还需要部署维护一个中间件服务.由于我们只有一个表需要分表, 直接用轻量级的sharding-jdbc即可.
2. mycat作为一个中间代理服务, 难免有性能损耗
3. 其他组用mycat的时候出现过生产BUG
然而sharding-jdbc也同样是坑坑洼洼不断的, 我们从2.x版本改成4.x版本, 又从4.x版本降到了3.x版本,每一个版本都踩到了坑(有些是sharding-jdbc的, 有些是由于我们项目依赖的), 最终不得已改动了一下源码才趟过去(其实就是注释了一行代码).
今天就来聊一下其中的一个坑--分表分页
问题描述
背景
CREATE TABLE `order_00` (
`id` bigint(18) NOT NULL AUTO_INCREMENT COMMENT '逻辑主键',
`orderId` varchar(32) NOT NULL COMMENT '订单ID',
`CREATE_TM` datetime DEFAULT NULL COMMENT '订单创建时间',
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `IDX_ORDER_POSTID` (`orderId`) USING BTREE,
KEY `IDX_ORDER_CREATE_TM` (`CREATE_TM`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=COMPACT COMMENT='订单表';
CREATE TABLE `order_01` (
`id` bigint(18) NOT NULL AUTO_INCREMENT COMMENT '逻辑主键',
`orderId` varchar(32) NOT NULL COMMENT '订单ID',
`CREATE_TM` datetime DEFAULT NULL COMMENT '订单创建时间',
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `IDX_ORDER_POSTID` (`orderId`) USING BTREE,
KEY `IDX_ORDER_CREATE_TM` (`CREATE_TM`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=COMPACT COMMENT='订单表';
CREATE TABLE `order_02` (
`id` bigint(18) NOT NULL AUTO_INCREMENT COMMENT '逻辑主键',
`orderId` varchar(32) NOT NULL COMMENT '订单ID',
`CREATE_TM` datetime DEFAULT NULL COMMENT '订单创建时间',
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `IDX_ORDER_POSTID` (`orderId`) USING BTREE,
KEY `IDX_ORDER_CREATE_TM` (`CREATE_TM`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=COMPACT COMMENT='订单表';
假设有以上三个分表, 分表逻辑用orderId取模, 即orderId=0的写到order_00,orderId=1的写到order_01,orderId=2的写到order_02.
备注: 这里为啥不用时间分表而用orderId做hash, 当时也是颇有争议的. 理论上订单表更适合使用时间做分表, 这样一来时间越老的数据访问的频率越小, 旧的分表逐渐就会成为冷表, 不再被访问到. 当时负责人的说法是, 由于这个表读写频率都高(而且场景中经常需要读主库), 用orderId分表可以均衡写负载和读负载. 虽然是有点牵强, 但也有一定道理, 就先这么实现了
业务上需要根据orderId或CREATE_TM进行分页查询, 即查询sql的mybatis写法大概如下:
<select id="queryPage" parameterType="xxx" resultMap="BaseResultMap">
select
<include refid="Base_Column_List"/>
from ORDER
<if test="orderId !=null and orderId !='' ">
AND orderId=#{orderId , jdbcType=VARCHAR}
</if>
<if test="createTmStartStr!=null and createTmStartStr!='' ">
AND create_tm >= concat(#{createTmStartStr, jdbcType=VARCHAR},' 00:00:00')
</if>
<if test="createTmEndStr!=null and createTmEndStr!='' ">
AND create_tm <= concat(#{createTmEndStr, jdbcType=VARCHAR},' 23:59:59')
</if>
limit #{page.begin}, #{page.pageSize}
</select>
用过sharding-jdbc的都知道, sharding-jdbc一共有5种分片策略,如下图所示. 没用过的可以参考官网
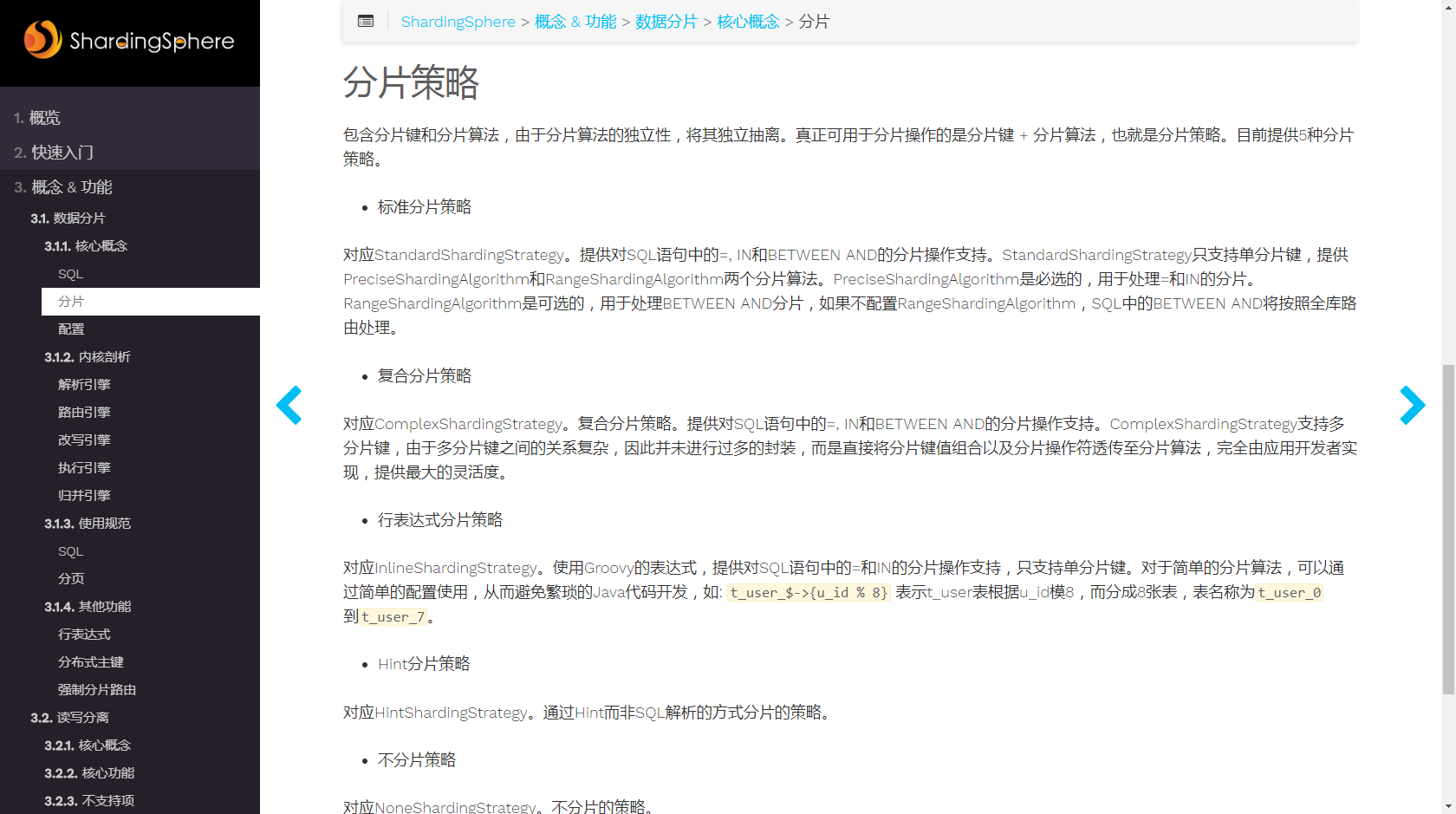
除了Hint分片策略, 其他的分片策略都要求sql的where条件需要包含分片列(在我们的表中是orderId), 很明显我们的业务场景中不能保证sql的where条件中一定会包含有orderId, 所以我们只能使用HintShardingStrategy,将页面的查询条件传递给分片策略算法中, 再判断查询哪个表, 大概代码如下
public class OrderHintShardingAlgorithm implements HintShardingAlgorithm {
public static final String ORDER_TABLE = "ORDER";
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ShardingValue shardingValue) {
ListShardingValue<String> listShardingValue = (ListShardingValue<String>) shardingValue;
List<String> list = Lists.newArrayList(listShardingValue.getValues());
List<String> actualTable = Lists.newArrayList();
// 页面上的查询条件会以json的方式传到shardingValue变量中
String json = list.get(0);
OrderQueryCondition req = JSON.parseObject(json, OrderQueryCondition.class);
String orderId = req.getOrderId();
// 查询条件没有orderId, 要查所有的分表
if(StringUtils.isEmpty(orderId)){
// 所有的分表
for(int i = 0 ; i< 3; i++){
actualTable.add(ORDER_TABLE + "_0" + i);
}
}else{
// 如果指定了orderId, 只查orderId所在的分表即可
long tableSuffix = ShardingUtils.getHashInteger(orderId);
actualTable.add(ORDER_TABLE + "_0" + tableSuffix);
}
// actualTable中包含sharding-jdbc实际会查询的表
return actualTable;
}
}
这样子, 如果我们根据orderId来查询的话, sharding-jdbc最终执行的sql就是(假设每页10条):
select * from ORDER_XX where orderId = ? limit 0 ,10
如果查询条件没有orderId, 那么最终执行的sql就是3条(假设每页10条):
select * from ORDER_00 where create_tm >= ? and create_tm <= ? limit 0 ,10 ;
select * from ORDER_01 where create_tm >= ? and create_tm <= ? limit 0 ,10 ;
select * from ORDER_02 where create_tm >= ? and create_tm <= ? limit 0 ,10 ;
注意在有多个分表的情况下, 每个表都取前10条数据出来(一共30条), 然后再排序取前10条, 这样的逻辑是不对的. sharding-jdbc给了个例子, 如果下图:
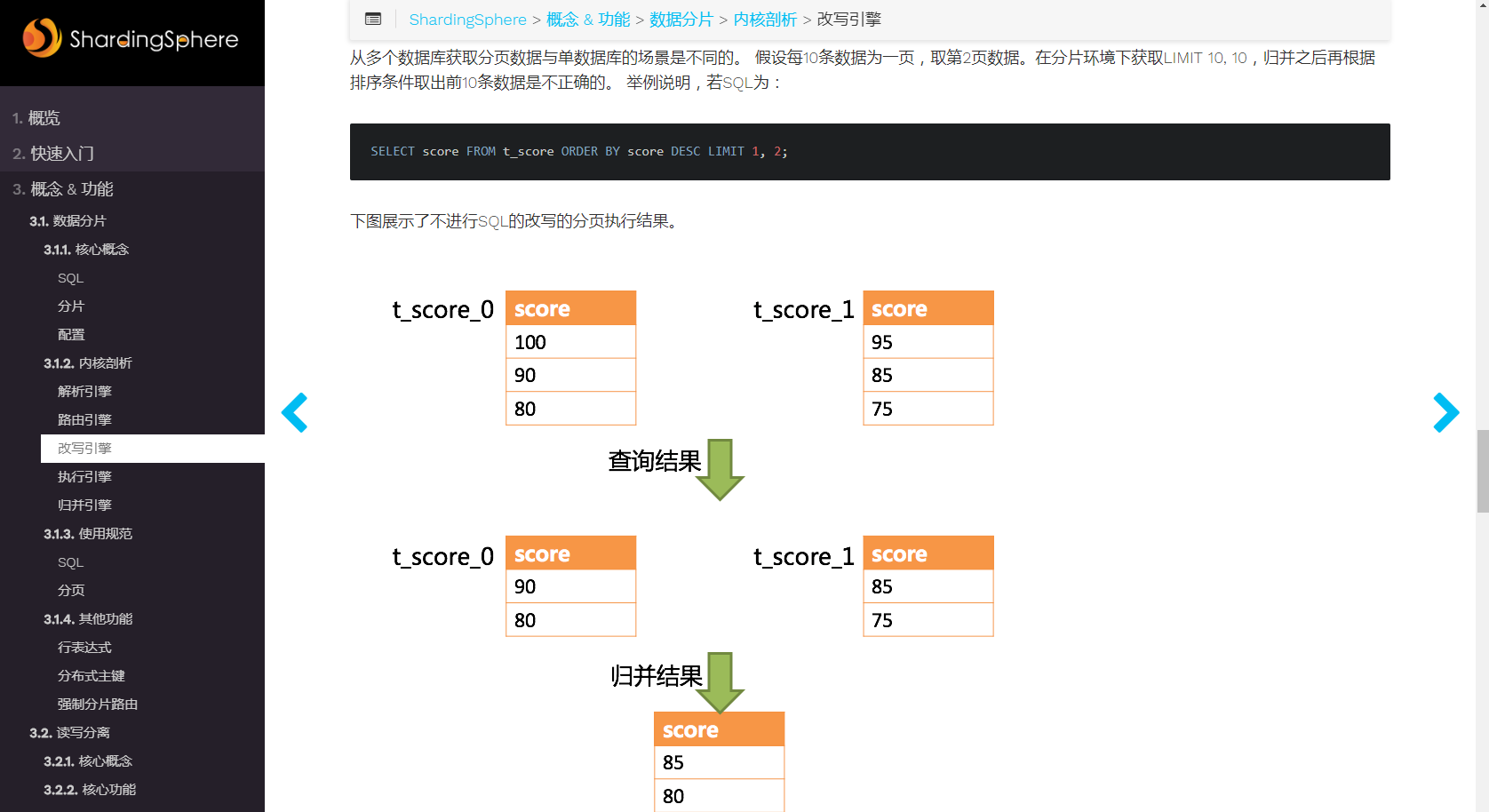
图中的例子中,想要取得两个表中共同的按照分数排序的第2条和第3条数据,应该是95和90。 由于执行的SQL只能从每个表中获取第2条和第3条数据,即从t_score_0表中获取的是90和80;从t_score_0表中获取的是85和75。 因此进行结果归并时,只能从获取的90,80,85和75之中进行归并,那么结果归并无论怎么实现,都不可能获得正确的结果.
那怎么办呢?
sharding-jdbc的做法就改写我们的sql, 先查出来所有的数据, 再做归并排序
例如查询第2页时
原sql是:
select * from ORDER_00 where create_tm >= ? and create_tm <= ? limit 10 ,10 ;
select * from ORDER_01 where create_tm >= ? and create_tm <= ? limit 10 ,10 ;
select * from ORDER_02 where create_tm >= ? and create_tm <= ? limit 10 ,10 ;
会被改写成:
select * from ORDER_00 where create_tm >= ? and create_tm <= ? limit 0 ,20 ;
select * from ORDER_01 where create_tm >= ? and create_tm <= ? limit 0 ,20 ;
select * from ORDER_02 where create_tm >= ? and create_tm <= ? limit 0 ,20 ;
查询第3页时
原sql是:
select * from ORDER_00 where create_tm >= ? and create_tm <= ? limit 20 ,10 ;
select * from ORDER_01 where create_tm >= ? and create_tm <= ? limit 20 ,10 ;
select * from ORDER_02 where create_tm >= ? and create_tm <= ? limit 20 ,10 ;
会被改写成:
select * from ORDER_00 where create_tm >= ? and create_tm <= ? limit 0 ,30 ;
select * from ORDER_01 where create_tm >= ? and create_tm <= ? limit 0 ,30 ;
select * from ORDER_02 where create_tm >= ? and create_tm <= ? limit 0 ,30 ;
当然, 大家肯定会觉得这样处理性能会很差, 其实事实上也的确是, 不过sharing-jdbc是在这个基础上做了优化的,就是上面提到的"归并", 具体归并过程可以戳这里查看官网的说明.篇幅比较长, 我这里就不再贴出来了
大概的逻辑就是先查出所有页的数据, 然后通过流式处理跳过前面的页,只取最终需要的页,最终达到分页的目的
踩坑
既然sharding-jdbc都已经优化好了, 那么我们踩到的坑到底是什么呢?
听我慢慢道来
在io.shardingsphere.shardingjdbc.jdbc.core.statement.ShardingPreparedStatement#getResultSet()中有个逻辑,
如果查询的分表数只有一个的话, 就不会做归并的逻辑(然而就算只查一个分表, sql的limit子句也会被改写了), 如图:
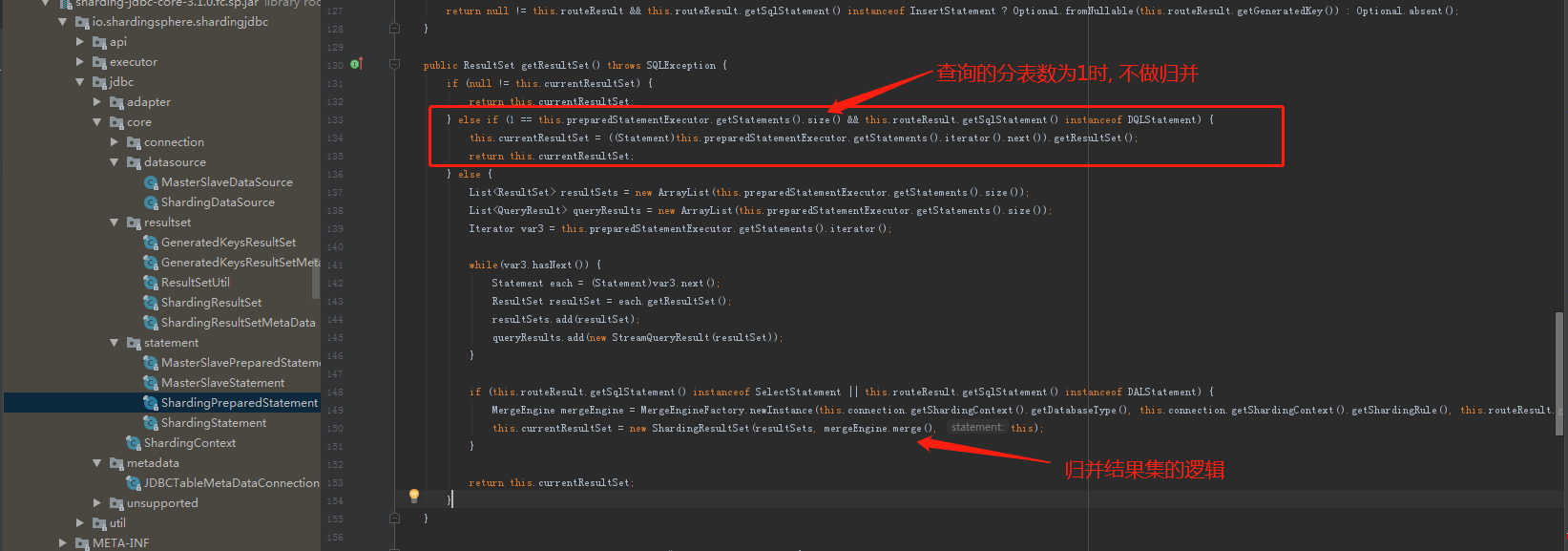
回到我们的业务场景, 如果查询条件包含了orderId的话, 因为可以定位到具体的表, 所以最终需要查询的分表就只有一个.
那么问题就来了, 由于sharding-jdbc把我们的sql的limit子句给改写了, 后面却由于只查一个分表而没有做归并(也就是没有跳过前面的页),所以最终不管是查询第几页,执行的sql都是(假设页大小是10000):
select * from ORDER_XX where orderId = ? limit 0 ,10000
select * from ORDER_XX where orderId = ? limit 0 ,20000
select * from ORDER_XX where orderId = ? limit 0 ,30000
select * from ORDER_XX where orderId = ? limit 0 ,40000
......
这样就导致了一个问题, 不管我传的页码是什么, sharding-jdbc都会给我返回同一条数据. 很明显这样是不对的.
当然, 心细的朋友可能会发现了, 由于orderId是个唯一索引, 所以肯定只有一条数据, 所以永远不会存在查询第二页的情况.
正常来说的确是这样, 然而在我们的代码里面, 还有个老逻辑: 导出查询结果(就是导出所有页的数据)时, 会异步地在后台一页一页地 导出, 直到导出了所有的页或者达到了查询次数上限(假设是查询1万次).
所以在根据orderId导出的时候, 因为每一页都返回相同的数据, 所以判断不了什么时候是"导完了所有的页", 所以正确结果本应该是只有一条数据的, 但是在sharding-jdbc下却执行了一万次, 导出了一万条相同的数据, 你说这个是不是坑呢?
知道问题所在, 那解决就简单了. 但是本文并不是想聊怎么解决这个问题的, 而是想聊聊通过这个问题引起的思考:
在mysql分表环境下, 如何高效地做分页查询?
对mysql分页的思考
limit 优化
在讨论分表环境下的分页性能之前, 我们先来看一下单表环境下应该实现分页.
众所周知, 在mysql里面实现分页只需要使用limit子句即可, 即
select * from order limit (pageNo-1) * pageSize, pageSize
由于在mysql的实现里面, limit offset, size是先扫描跳过前面的offset条数据,再取size条数据. 当pageNo越大的时候, offset也会越大, mysql扫描的数据也越大, 所以性能会急剧下降.
因此, 分页第一个要解决的问题就是当pageNo过大时, 怎么优化性能.
第一个方案是这篇文章介绍的索引覆盖的方案. 总结来说就是把sql改写成这样:
select * from order where id >= (select id from order limit (pageNo-1) * pageSize, 1) limit pageSize
利用索引覆盖的原理, 先直接定位当前页的第一条数据的最小id, 然后再取需要的数据.
这样的确可以提高性能, 但是我认为还是没有彻底解决问题, 因为当pageNo过大的时候, mysql还是会需要扫描很多的行来找到最小的id. 而扫描的那些行都是没有意义.
scroll 游标查询
游标查询是elasticSearch里面的一个术语, 但是我这里并不是指真正的scroll查询, 而是借鉴ES里面的思想来实现mysql的分页查询.
所谓的scroll就是滚动, 一页一页地查. 大概的思想如下:
1. 查询第1页
select * from order limit 0, pageSize;
2. 记录第1页的最大id: maxId
3. 查询第2页
select * from order where id > maxId limit pageSize
4. 把maxId更新为第2页的最大id
... 以此类推
可以看到这种算法对于mysql来说是毫无压力的, 因为每次都只需要扫描pageSize条数据就能达到目的. 相对于上面的索引覆盖的方案, 可以极大地提高查询性能.
当然它也有它的局限性:
1. 性能的提高带来的代价是代码逻辑的复杂度提高. 这个分页逻辑实现起来比较复杂.
2. 这个算法对业务数据是有要求的, 例如id必须是单调递增的,而且查询的结果需要是用Id排序的.
如果查询的结果需要按其他字段(例如createTime)排序, 那就要求createTime也是单调的, 并把算法中的id替换成createTime.
有某些排序的场景下, 这种算法会不适用.
3. 这个算法是需要业务上做妥协的, 你必须说服你的产品经理放弃"跳转到特定页"的功能, 只能通过点击"下一页"来进行翻页.
(这才是scroll的含义, 在手机或平板上,只能通过滚动来翻页,而无法直接跳转到特定页)
分表环境下的分页查询
如上面讨论, 在单表环境下, 想要实现高效的分页, 还是相对比较简单的.
那如果在分表环境下, 分页的实现会有什么不同呢?
正如上面提到的, sharding-jdbc中已经论证过了, 分表环境的分页查询, 如果不把
select * from ORDER_00 where create_tm >= ? and create_tm <= ? limit (pageNo-1) * pageSize ,pageSize ;
select * from ORDER_01 where create_tm >= ? and create_tm <= ? limit (pageNo-1) * pageSize ,pageSize;
select * from ORDER_02 where create_tm >= ? and create_tm <= ? limit (pageNo-1) * pageSize ,pageSize ;
改写成
select * from ORDER_00 where create_tm >= ? and create_tm <= ? limit 0 , (pageNo-1) * pageSize + pageSize ;
select * from ORDER_01 where create_tm >= ? and create_tm <= ? limit 0 , (pageNo-1) * pageSize + pageSize;
select * from ORDER_02 where create_tm >= ? and create_tm <= ? limit 0 , (pageNo-1) * pageSize + pageSize ;
那么最终查出来的数据, 很有可能不是正确的数据. 所以在分表环境下, 上面所说的"索引覆盖法"和"游标查询法"肯定是都不适用了的. 因为必须查出所有节点的数据,再进行归并, 那才是正确的数据.
因此, 要在分表环境下实现分页功能, 基本上是要对limit子句进行改写了的.
先来看sharing-jdbc的解决方案, 改写后的limit 0 , (pageNo-1) * pageSize + pageSize 和原来的limit (pageNo-1) * pageSize, pageSize对比, 数据库端的查询压力都是差不多的, 因为都是要差不多要 扫描(pageNo-1) * pageSize 行才能取得到数据. 不同的是改写sql后, 客户端的内存消耗和网络消耗变大了.
sharding-jdbc巧妙地利用流式处理和优先级队列结合的方式, 消除了客户端内存消耗的压力, 但是网络消耗的影响依然是无法消除.
所以真的没有更好的方案了?
那肯定是有的, 在业界难题-“跨库分页”的四种方案这篇文章中, 作者提到了一种"二次查询法", 就非常巧妙地解决了这个分页查询的难题. 大家可以参考一下.
但是仔细思考一下, 还是有一定的局限性的:
1. 当分表数为N时, 查一页数据要执行N*2条sql.(这个无解, 只要分表了就必须这样)
2. 当offset很大的时候, 第一次查询中扫描offset行数据依然会非常的慢, 如果只分表不分库的话, 那么一次查询会在一个库中产生N条慢sql
3. 算法实现起来代码逻辑应该不简单, 如果为了一个分页功能写这么复杂的逻辑, 是不是划不来,
而且后期也不好维护
如果算法原作者看到我这里的鸡蛋挑骨头, 会不会有点想鄙视我~~
其实我想表达的意思是, 既然分表环境下的分页查询没有完美的解决方案的话,或者实现起来成本过大的话, 那是不是可以认为: 分表环境下就不应该做分页查询?
离线计算+有损服务
上面说到, 其实分表环境下就不适宜再做分页查询的功能. 但是业务上的需求并不是说去掉就去掉的, 很多情况下分页功能是必须的, 然而分页查询的存在通常也是为了保护数据库, 去掉了分页功能, 数据库的压力反而更大.
所以分表和分页只能二选一?
不, 我全都要, 分表我要, 分页我也要!
但是分页功能不在分表环境里面做, 而是在另外一张汇总表里面做分页查询的功能.
大概的方案就是:
1. 正常的业务读写分表
2. 根据具体的业务需求,例如实时计算/离线计算技术(spark, hadoop,hive, kafka等)生成各分表的一张汇总表
3. 分页查询的接口直接查询汇总表
另外还要注意这个方案对业务来说肯定是有损的, 具体表现为:
1. 不管是离线计算还是实时计算, 都不能保证实时性, 查询结果肯定是有时延的
2. 由于汇总表是不可能包含分表的所有数据的, 所以汇总表肯定是只包含部分数据的,例如只有一个月内的,具体根据业务场景而定
总的来说, 就是报表系统的数据由数据仓库系统来生成, 但只能生成用户非要不可的数据,其他的都去掉.
写这篇总结在找资料的时候, 看到一句话:
其实分表的根本目的是分摊写负载, 而不是分摊读负载
其实是有一定道理的, 如果读负载过高, 我们可以增加缓存, 增加数据节点等很多方法, 而写负载过高的话, 分表基本就是势在必行了.
从这个理论来说, 分页是一个读操作, 根本就没有必要去读取分表, 从其他地方读取(我们这里是数据仓库)即可
不分表(分区 tidb mongoDb ES)
其实大多数mysql的表都没有必要分表的
在mysql5.5之前, 表数量大概在在500W之后就要进行优化, 在mysql5.5之后, 表数量在1KW到2KW左右才需要做优化. 在这个性能拐点之前, 可以认为mysql是完全有能力扛得住的.当然, 具体还要看qps以及读写冲突等的频率的.
到了性能拐点之后呢? 那就要考虑对mysql的表进行拆分了. 表拆分的手段可以是分表分库, 或者就简单的分区.
基本来说, 分区和分表带来的性能提升是一样的, 由于分区实际上就可以认为是mysql底层来帮我们实现分表的逻辑了, 所以相对来说分表会比分区带来更高的编码复杂度(分区就根本不用考虑多表分页查询的问题了). 从这个角度来说, 一般的业务直接分区就可以了.
当然, 选择分区还是分表还是需要做一点权衡的:
1. 表中的数据只有部分热点数据经常访问, 其他的不常访问的话, 适合用分区表
2. 分区表相对容易维护, 可以针对单独一个分区进行检查,优化, 批量删除大量数据时, 分区表会比一般的表更快
3. 分区表可以分布在不同的物理设备上, 从而可以高效地利用多个硬盘
4. 如果查询条件不包含partition key的话, 分区表不一定有分表效率高
5. 如果分区表中绝对的热点数据, 每一条数据都有可能被访问到, 也不太适合分区
6. 如果数据量超大, 由于mysql只能分1024个分区, 如果1024个分区的数据都是千万以上, 那肯定是也不适合分区的了
综上所述, 如果分区表就足够满足我们的话, 那其实就没有必要进行分表了增加编程的复杂度了.
另外, 如果不想将数据表进行拆分, 而表的数据量又的确很大的话, nosql也是一个替代方案. 特别是那些不需要强事务的表操作, 就很适合放在nosql, 从而可以避免编程的复杂度, 同时性能上也没有过多的损耗.
nosql的方案也有很多:
1. mongoDb
2. hbase
3. tidb
4. elasticSearch
当然也可以使用mysql+nosql结合的方式, 例如常规读写操作mysql, 分页查询走ES等等.
今天就先写到这, 有机会再写写mysql和nosql
