

残差网络
残差网络(Residual Network简称ResNet)是在2015年继Alexnet Googlenet VGG三个经典的CNN网络之后提出的,并在ImageNet比赛classification任务上拔得头筹,ResNet因其简单又实用的优点,现已在检测,分割,识别等领域被广泛的应用。
ResNet可以说是过去几年中计算机视觉和深度学习领域最具开创性的工作,有效的解决了随着网络的加深,出现了训练集准确率下降的问题,如下图所示:
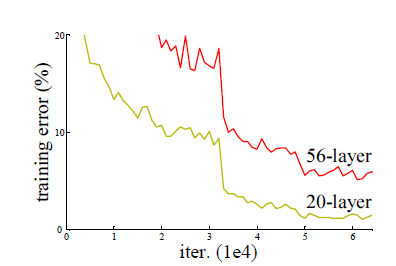
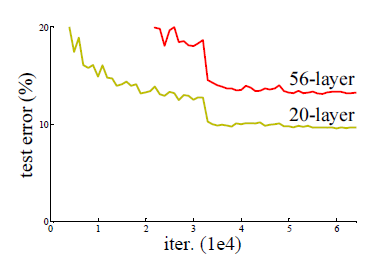
Fig. 1
图中56层的普通神经网络在训练集上的表现明显的比20层的差很多,从而导致在测试集上的表现也相对较差。
做过深度学习的同学应该都知道,随着网络层数的增加而导致训练效果变差的一个原因是梯度弥散和梯度爆炸问题(vanishing/exploding gradients),这个问题抑制了浅层网络参数的收敛。但是这个问题已经通过一些参数初始化的技术较好的解决了,有兴趣的同学可以看下以下几篇文章[2][3][4][5][6]。
但是即便如此,在网络深度较高的时候(例如图中的56层网络)任然会出现效果变差的问题,我们在先前的Alexnet Googlenet VGG三个模型中可以看出,网络的深度在图片的识别中有着至关重要的作用,深度越深能自动学习到的不同层次的特征可能就越多,那到底是什么原因导致了效果变差呢?
ResNet的提出者做出了这样的假设:如果一个深层的网络在训练的时候能够训练成一个浅层的网络加上一堆恒等映射的网络,那这样的得到的深层网络在训练的误差上是不会比这个浅层的网络还要高的,所以问题的根源可能在于当网络深度较深的时候,多层的非线性的网络在拟合恒等映射的时候遇到了困难,于是就提出了一种“短路”(shortcut connections)的模型来帮助神经网络的拟合,如下图所示:
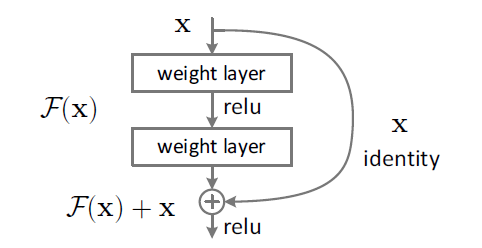
Fig. 2
假设
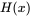
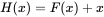
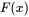
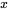
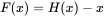
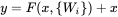
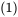
这里的
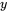
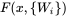
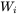
是第

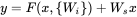
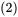
这里
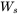
下面我们来看作者设计的34层ResNet的结构与VGG网络结构的对比(参加比赛使用的网络达到了152层):
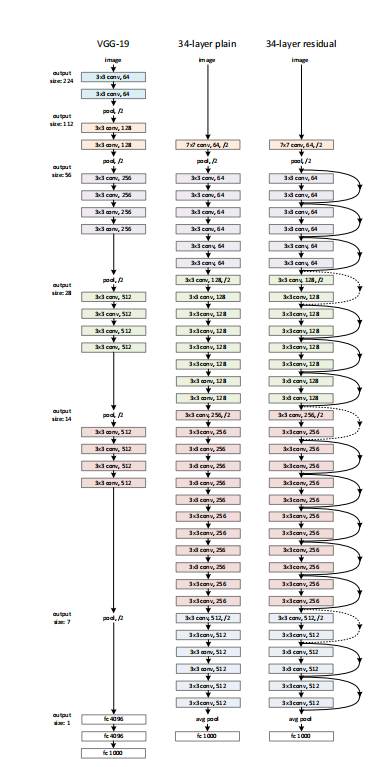
Fig. 3
左侧19层的VGG模型的计算量是 19.6 billion FLOPs 中间是34层的普通卷积网络计算量是3.6 billion FLOPs
右边是34层的ResNet计算量是3.6billion FLOPs,图中实线的箭头是没有维度变化的直接映射,虚线是有维度变化的映射。通过对比可以看出VGG虽然层数不多但是计算量还是很大的,后面我们可以通过实验数据看到34层的ResNet的表现会比19层的更好。
更详细的结构如下图所示(包括一些层数更多的ResNet):
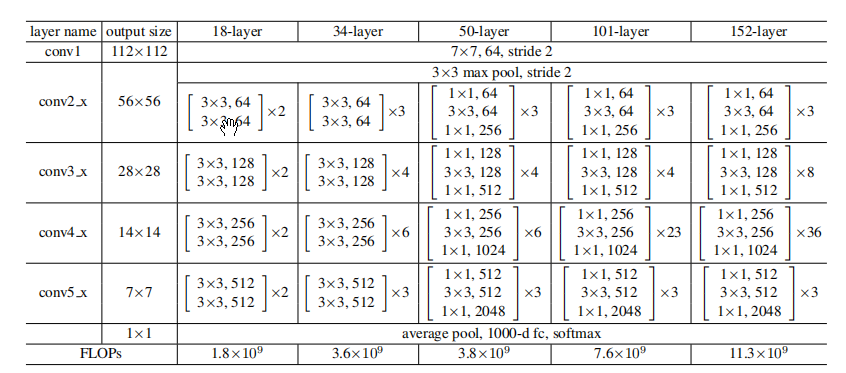
Fig. 4
残差网络虽然在结构和原理上都非常简单,但表现不俗且解决了随着深度增加效果变差的问题,下面是实验数据:
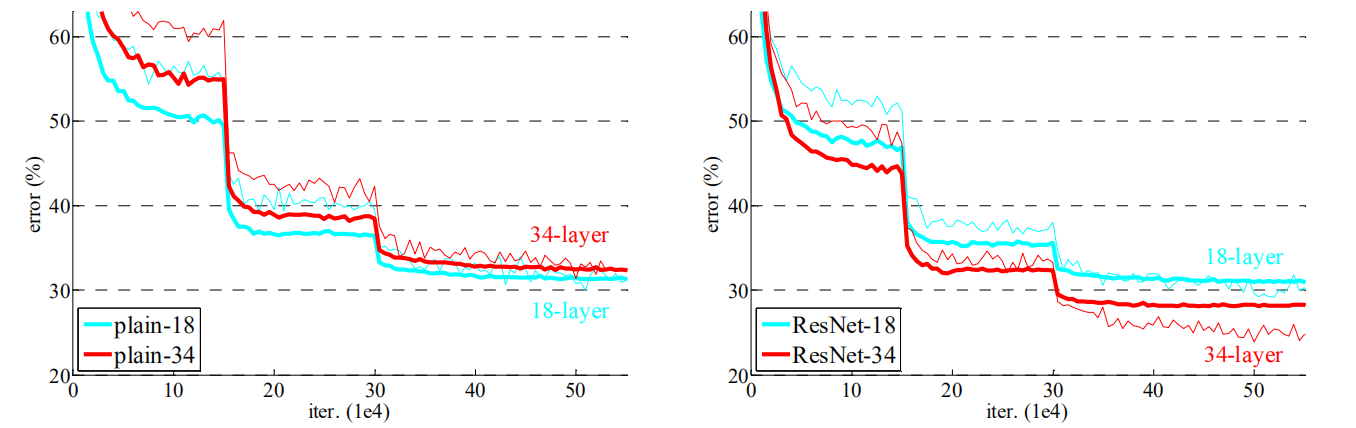
这是普通网络(左)和残差网络(右)的对比,图中细线代表训练误差,粗线代表检验误差,蓝色是18层,红色是34层。从图中可以看出普通网络是存在较深的网络比浅的网络效果差的问题,而残差网络却是层数越高效果越好。
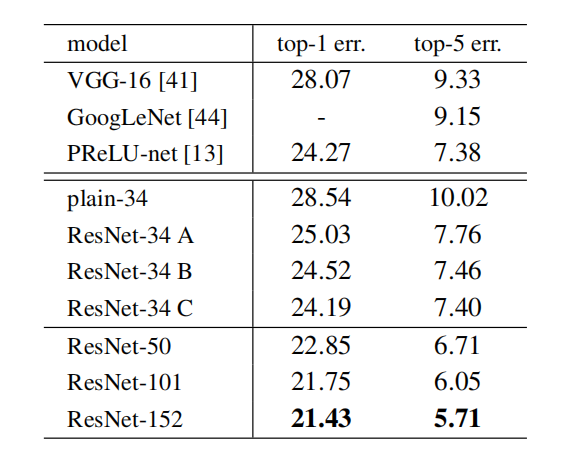
Fig. 6
这是残差网络,VGG和GoogleNet在ImageNet数据集上的测是数据,top-1 err表示1000种类别中分类错误的概率,top-5 err 表示1000种类别中网络得出的最有可能的5种类别中任然没有正确类别的概率。图中34层A,B,C是指上文提到的输入输出维度不一致问题中当卷积层之间维度变高的时候采取的三种方案,A是将所有增加的维度都用0填充。(zero-padding)B 是保持原始输入,增加的维度用线性映射填充。C 是将所有的输入都进行线性映射再加到输出中。
从图中可以看出在效果上,34层的残差网络比VGG和GoogleNet都要好,A,B,C三种方案中C方案效果最好,但是B,C方案在计算量上比A方案要大很多,而效果提升的又很少,所以论文作者建议还是使用A方案较为实用。
下面我们介绍层数在50及以上的残差网络的结构: Deeper Bottleneck Architectures。这种结构是作者为了降低训练时间所设计的,结构对比如下图所示:
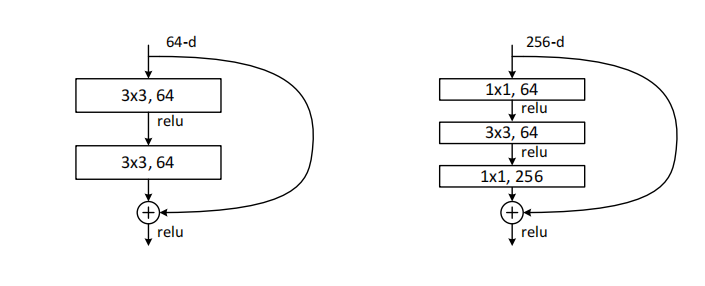
Fig. 7
图中左边是34层ResNet使用的普通的结构,右边是50层及以上的所使用的瓶颈(Bottleneck)结构,
这里的瓶颈结构中有两个1X1但通道数分别为64和256,第一个是将256通道的输入降维到64通道,第二个是将64通道升维到256通道。中间是普通的3X3的卷积网络,最后整体的计算量与左边的相近。这样的结构的好处是在卷积的同时就完成了维度上的适应,输入可以直接加到输出上,这样可以让计算量减少一半之多。在图5中有50层网络的整个结构,总共的计算量为 3.8 billion FLOPs 只比34层的多0.2 个billion。
同样的在图4和图5中可以看出101层和152层的残差网络也用这种结构在计算量上比16层的VGG还要少,而在准确度上比VGG高出许多。
总结:
ResNet通过残差学习解决了深度网络的退化问题,让我们可以训练出更深的网络,这称得上是深度网络的一个历史大突破吧。也许不久会有更好的方式来训练更深的网络,让我们一起期待吧!
目前,您可以在人工智能建模平台 Mo 找到基于tensorflow 的34层的残差网络(ResNet)实现样例,数据集是CIFAR-10 (CIFAR的十分类数据集),这个样例在测试集上的精度为90%,验证集上的精度为98%。主程序在ResNet_Operator.py中,网络的Block结构在ResNet_Block.py中,训练完的模型保存在results文件夹中。
项目源码地址:momodel.cn/explore/5d1…
参考文献:
[1] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. arXiv preprint arXiv:1512.03385,2015.
[2] Y. LeCun, L. Bottou, G. B. Orr, and K.-R.M¨uller. Efficient backprop.In Neural Networks: Tricks of the Trade, pages 9–50. Springer, 1998.
[3] X. Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. In AISTATS, 2010.
[4] A. M. Saxe, J. L. McClelland, and S. Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks.arXiv:1312.6120, 2013.
[5] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers:Surpassing human-level performance on imagenet classification. In ICCV, 2015.
[6] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
关于我们
Mo(网址:momodel.cn)是一个支持 Python 的人工智能在线建模平台,能帮助你快速开发、训练并部署模型。
Mo 人工智能俱乐部 是由网站的研发与产品设计团队发起、致力于降低人工智能开发与使用门槛的俱乐部。团队具备大数据处理分析、可视化与数据建模经验,已承担多领域智能项目,具备从底层到前端的全线设计开发能力。主要研究方向为大数据管理分析与人工智能技术,并以此来促进数据驱动的科学研究。
目前俱乐部每周六在杭州举办以机器学习为主题的线下技术沙龙活动,不定期进行论文分享与学术交流。希望能汇聚来自各行各业对人工智能感兴趣的朋友,不断交流共同成长,推动人工智能民主化、应用普及化。

