

一. nodejs背景
先来说说nodejs最常被提到的几个关键词,“单线程”,“非阻塞异步IO”,“事件循环”。接下来主要来通过这几个关键字总结一下nodejs的内在原理,以及引申出的一些问题。
二. nodejs是单线程吗?
如果说nodejs是单线程语言,可以想象一下,一个单实例的nodejs的服务器同时接受100个用户请求时,第100个用户的请求要等前面99的用户处理完成才能得到处理,如果每个用户的请求要0.3秒,第100个用户需要30秒的等待,这显然和我们的实际情况并不符合,所以说,nodejs并不是单纯的单线程。
那为什么说nodejs是单线程语言呢?而是因为nodejs中javascript代码的执行是单线程,怎么理解这句话,看下面代码。
console.log('javascript start');
setTimeout(()=>{
console.log('javascript setTimeout');
}, 2000);
const now = Date.now();
while(Date.now() < now + 4000) {}
console.log('javascript end');
执行结果:
$ node index.js
javascript start
javascript end
javascript setTimeout
上面的代码中,setTimeout的回调代码在while执行4秒期间,计时器已经是过了两秒的,而'javascript setTimeout'这一句打印却在'javascript end'之后,即使计时器在两秒后回调代码应该被执行时,因为javascript的线程处于非空闲状态,而不能输出'javascript setTimeout',javascript代码是单线程这样理解。
三. nodejs的异步IO
再拿上面的例子来看,当100个用户请求同时被接受到时,当需要IO(网络IO/文件IO)操作时,单线程的javascript并不会停下来等待IO操作完成,而是“事件驱动”开始介入,javascript执行线程继续执行未完的javascript代码,当执行完成后该线程处于空闲状态,可以看下面这一段代码示例。
// http.js
const http = require('http');
const fs = require('fs');
let num = 0;
http.createServer((req, res) => {
console.log('request id: %d, time:', num++, Date.now());
fs.readFile('./test.txt', ()=> {
res.end('response');
});
}).listen(9007, ()=>{
console.log('server start, 127.0.0.1:9007');
});
// req.js
const http = require('http');
for(let i=0; i<100; i++) {
http.get('http://127.0.0.1:9007', (res)=>{
res.on("data",(data)=>{
console.log('response time:', Date.now())
// console.log('data', data.toString())
})
}).on('error', (err)=>{
console.log('error', err);
})
}
node http.js // 启动服务器

node req.js // 发起100个请求
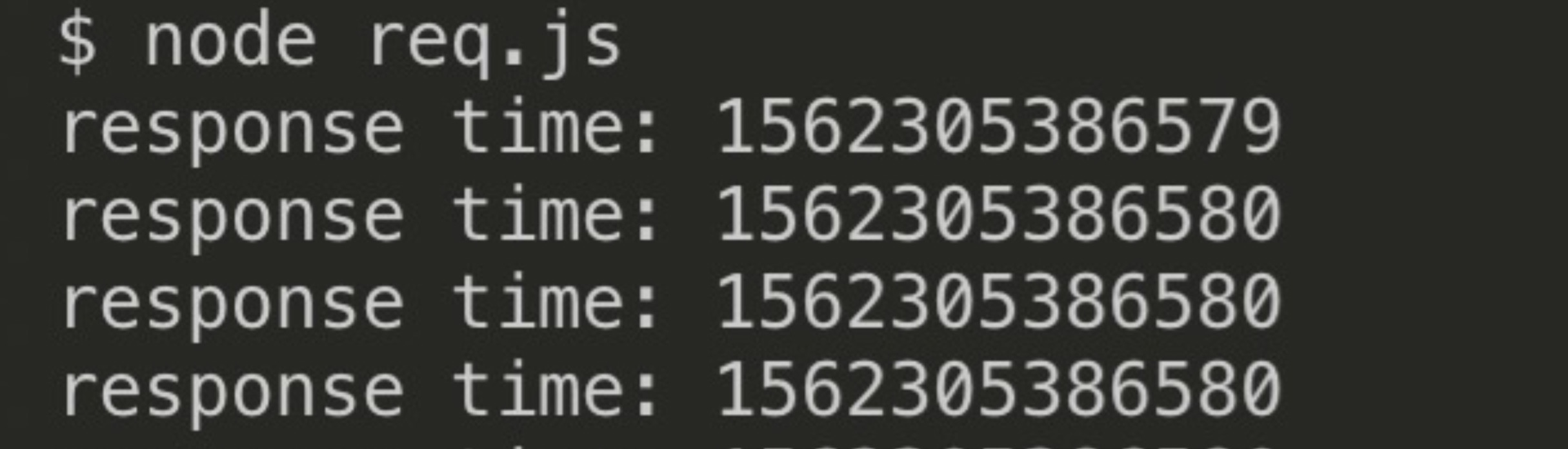
可以看出100个请求均是在请求返回之前非常短的时间都被得到了处理,而返回则均在请求之后,并非请求按接收顺序依次等待各个IO得到处理后依次返回。
四. 事件循环
说到事件循环,在上面的请求中,100个请求的都在非常短的时间得到了处理,而后请求又各自得到了回复,可以思考一下,javascript已经执行到了第100个请求,而第1个请求才得到回复,而第一个请求的栈信息没有丢失,说明第一个请求的请求栈信息被记录了,这一过程便是注册IO事件。
从上面注册事件后,事件循环得到激活,对于上面代码中fs.readFile这个读文件IO则开始真正执行,而这时候IO的执行跟javascript代码的执行便没有关系了,由nodejs底层libuv提供的线程池接收该文件IO执行工作,该线程池默认大小为4,可以通过环境变量process.env.UV_THREADPOOL_SIZE在启动的时候进行调整,但是最大不能超过1024个,有兴趣的可以查看线程池源码;由上可以看出nodejs内部实际是多进程并行工作的,而是利用事件循环做了封口处理。
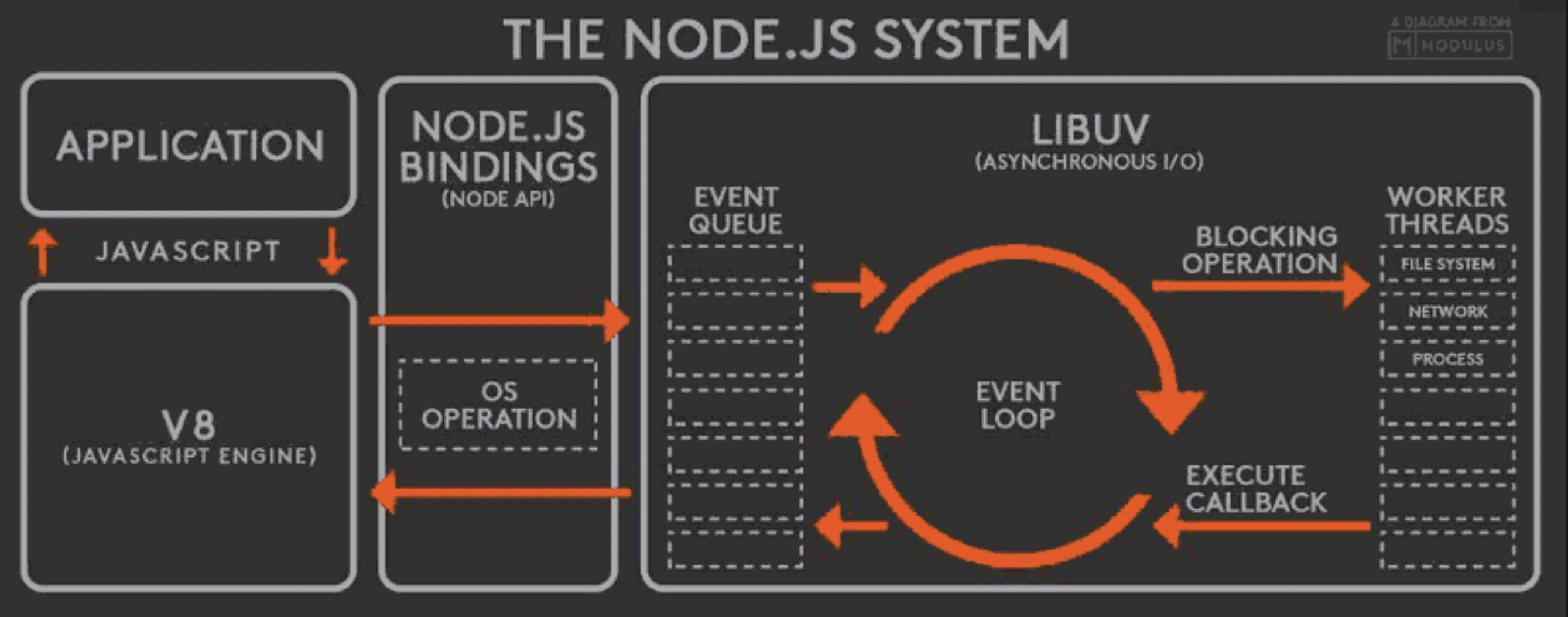
再来说说事件循环,上面示例中fs.readFile读文件时,如何知道这个读操作完成了呢?可以思考一下,读操作是线程池来控制执行的,在该线程执行前,先在注册事件的内存中初始化一个状态是“执行中”,并且事件循环也已经被激活,开始轮询等待执行结果,当执行IO的线程在执行完之后,再通过底层的异步IO接口(epoll_wait/IOCP)进行通知到初始注册的任务队列内存进行变更状态,事件循环轮询到状态变成“已完成”,这时候在IO事件注册时注入的回调函数得到执行权,javascript线程开始工作,整个异步过程完毕。
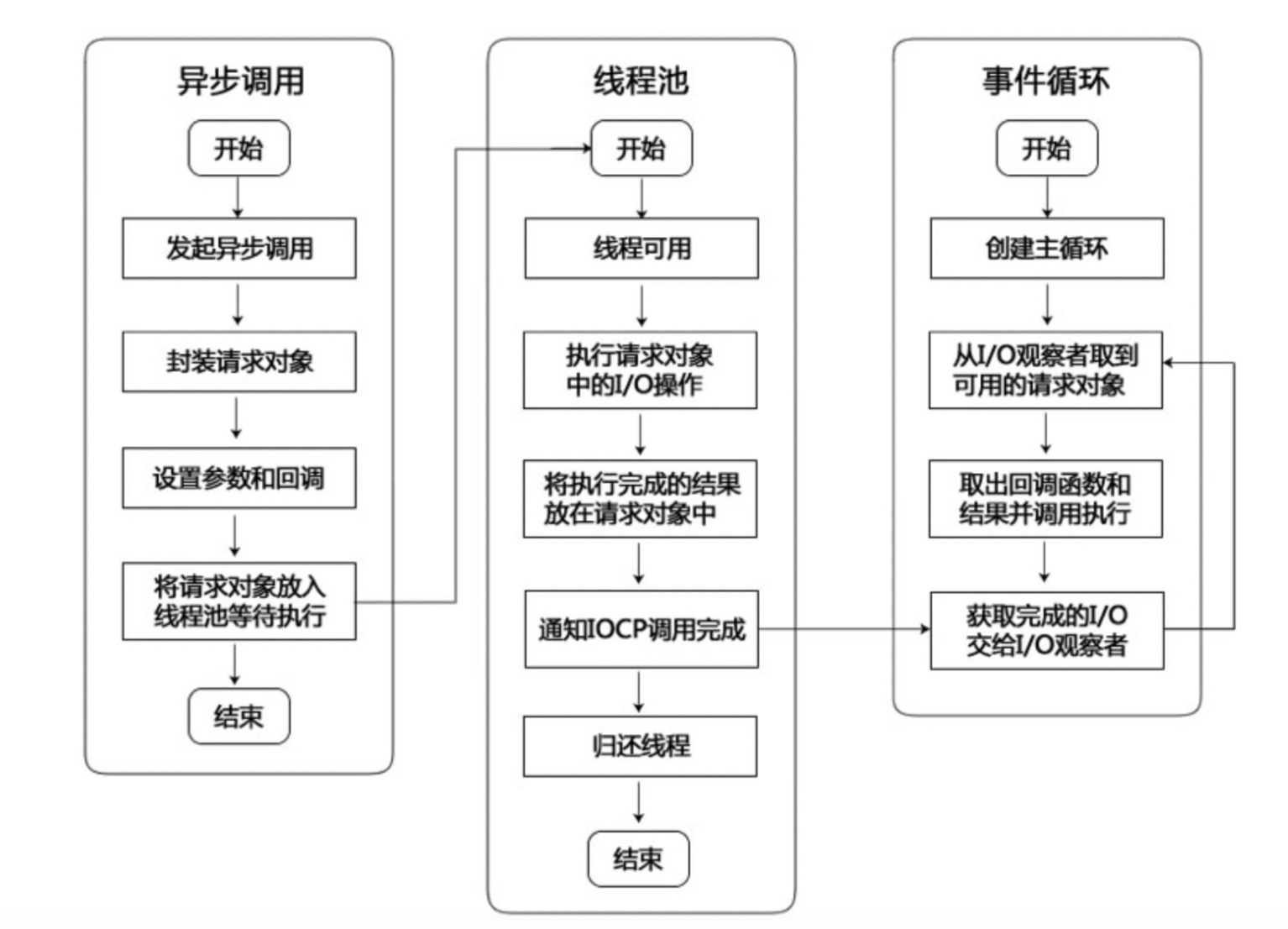
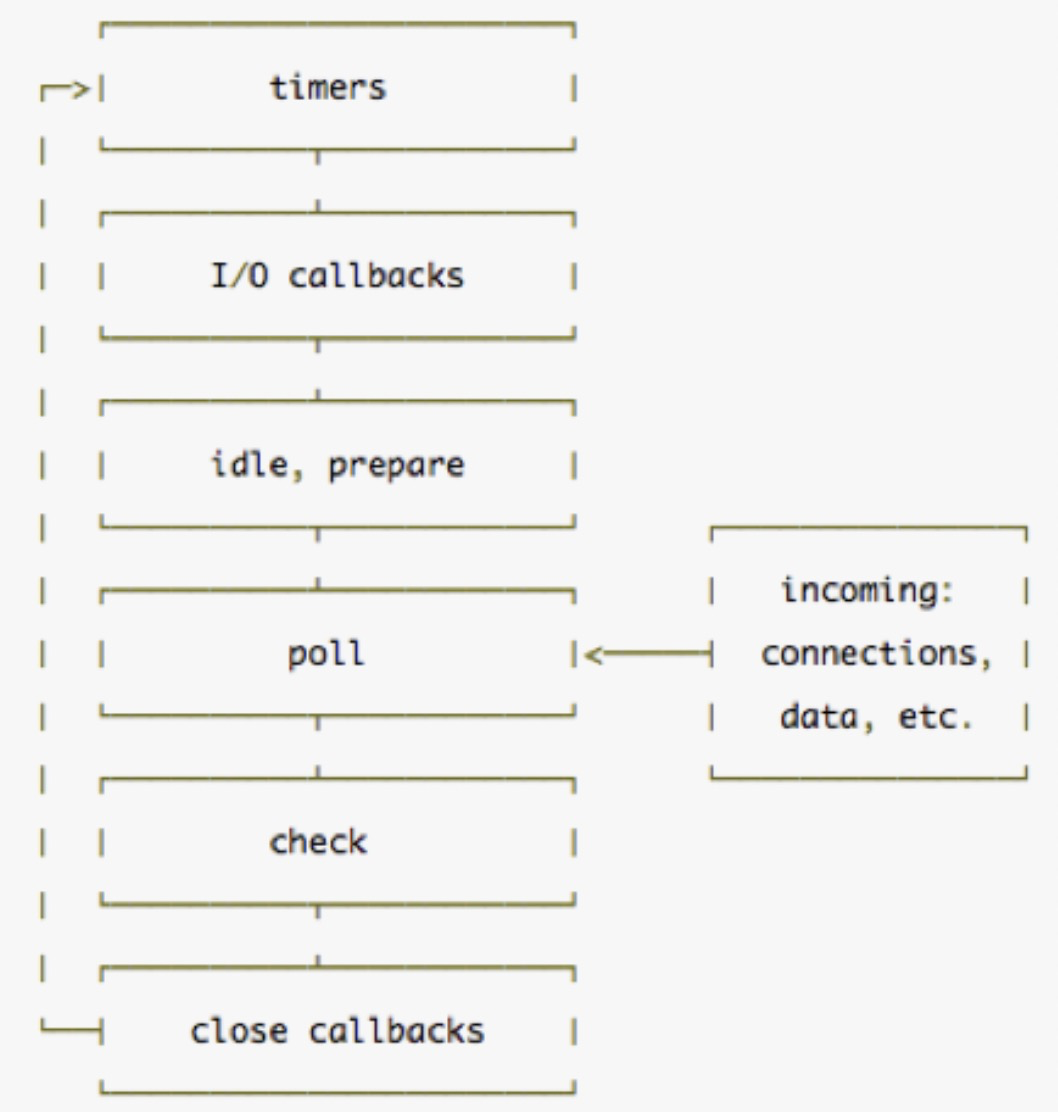
可以看一下英文原版的解释,事件循环解释

翻译过来:
**阶段概览**
timers:这个阶段执行setTimeout() 和 setInterval()中到期的回调函数
I/O callbacks:执行所有除了setTimeout() ,setInterval(),close事件,setImmediate的其他回调函数
idle, prepare:仅内部使用
poll:获取新的I/O 事件,在适当的条件下nodejs会阻塞在这个阶段
check:setImmediate的回调函数在这里被调用
close callbacks:像socket.on("close",func)这一类执行close事件的回调
如上内容均为自己总结,难免会有错误或者认识偏差,如有问题,希望大家留言指正,以免误人,若有什么问题请留言,会尽力回答之。如果对你有帮助不要忘了分享给你的朋友哦!也可以关注作者,查看历史文章并且关注最新动态,助你早日成为一名全栈工程师!

