spark任务提交有三种方式
1:通过local方式提交
2:通过spark-submit脚本提交到集群
3:通过spark提交的API SparkLauncher提交到集群,这种方式可以将提交过程集成到我们的spring工程中,更加灵活
先来看一下spark架构,可以帮助理解任务的提交
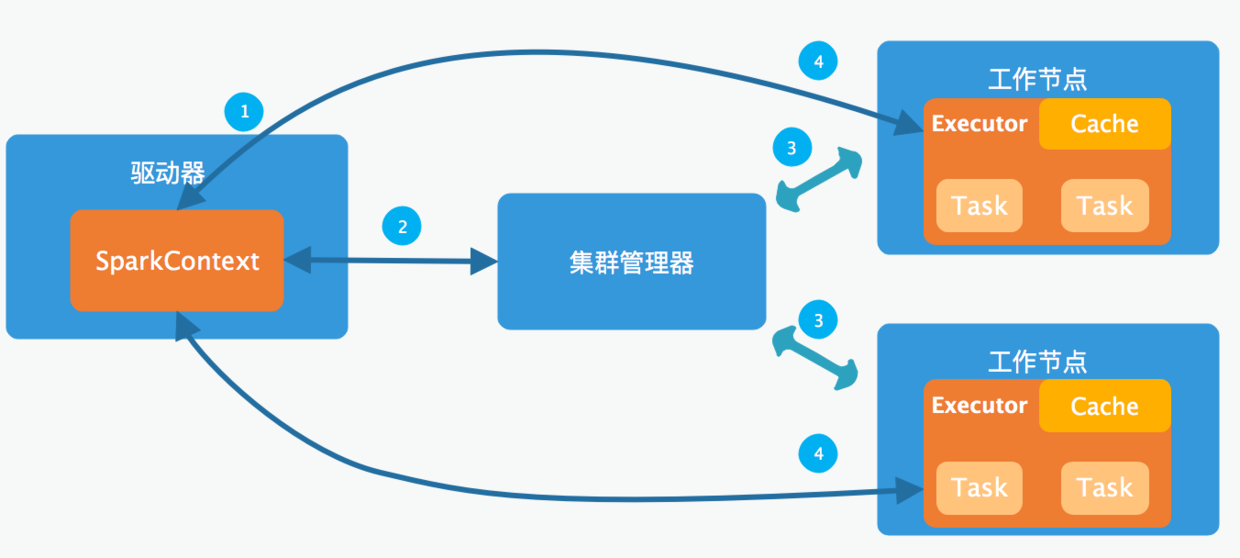
驱动程序:执行应用程序main方法的进程
集群管理器:启动执行器节点,有Mesos、YARN(Hadoop)、独立集群管理器(spark自带的集群管理器),在standalone模式中即为Master主节点。
执行器节点:工作进程,负责在spark作业中运行任务
过程大概如下
①:执行器节点(工作节点)在启动时会向驱动器注册自己
②:用户提交任务,驱动器调用main方法,驱动器与集群管理器通信申请执行器资源
③:集群管理器为驱动器程序启动执行器节点
④:驱动器程序执行应用程序,将任务发送到工作节点
⑤:工作节点进行计算并保存结果
⑥:驱动器main方法退出,通过集群管理器释放资源
注意:在客户端模式下,spark-submit 会将驱动器程序运行 在 spark-submit 被调用的这台机器上。在集群模式下,驱动器程序会被传输并执行 于集群的一个工作节点上
一、本地方式提交
//该代码是对企业架构下的不同级别的海量告警信息进行离线统计,按部门、日期、级别进行分组统计
public static void main(String[] args) {
logger.info("开始执行spark任务");
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd");
SparkConf conf = new SparkConf()
.setAppName("离线统计")
//.setMaster("spark://" + SparkConfig.SPARK_MASTER_HOST + ":" + SparkConfig.SPARK_MASTER_PORT)
.setMaster("local")
.set("spark.mongodb.input.uri", MongoConfig.SPARK_MONGODB_URL_PREFIX + BaseConstant.ALARM_SOURCE_TABLE)
.set("spark.mongodb.output.uri", MongoConfig.SPARK_MONGODB_URL_PREFIX + BaseConstant
.ALARM_TARGET_TABLE);
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaMongoRDD<Document> lines = MongoSpark.load(jsc).withPipeline(
singletonList(
getCondition()
)
);
//按部门时间分组计算
JavaPairRDD<String, AlarmStatisticBean> pairs =
lines.filter((Function<Document, Boolean>) line -> {
//代码略掉
//过滤函数,true:不过滤,false:过滤
return true;
}).mapToPair(
//对RDD中的每个元素调用指定函数,并返回<String, AlarmStatisticBean>类型的对象
//键值对, key: orgId_day value: level[] 例:1_20190101, [0,1,0]
(PairFunction<Document, String, AlarmStatisticBean>) line -> {
Long orgId = line.getLong("orgId");
String statisticDate = sdf.format(line.getLong("createTimestamp") * 1000);
AlarmStatisticBean bean = new AlarmStatisticBean();
Long level = line.getLong("levelDictId");
if (level == AlarmTypeEnum.LEVEL1.getType()) {
bean.setLevel1Count(1);
}
if (level == AlarmTypeEnum.LEVEL2.getType()) {
bean.setLevel2Count(1);
}
if (level == AlarmTypeEnum.LEVEL3.getType()) {
bean.setLevel3Count(1);
}
bean.setOrgId(orgId.intValue());
bean.setDay(statisticDate);
String code = orgId + "_" + statisticDate;
return new Tuple2<>(code, bean);
}
//分组多列求和 1_20190101, [x,y,z]
).reduceByKey((Function2<AlarmStatisticBean, AlarmStatisticBean, AlarmStatisticBean>) (v1, v2) -> {
//reduceByKey的作用是合并具有相同键的值
v1.setLevel1Count(v1.getLevel1Count() + v2.getLevel1Count());
v1.setLevel2Count(v1.getLevel2Count() + v2.getLevel2Count());
v1.setLevel3Count(v1.getLevel3Count() + v2.getLevel3Count());
return v1;
});
logger.info("------------------------->>>>>" + pairs.count());
List<Document> documents = new ArrayList<>();
//类型转换,以便持久化到DB(mongo或mysql)
for (Tuple2<String, AlarmStatisticBean> tuple2 : pairs.collect()) {
Document document = new Document("day", tuple2._2.getDay())
.append("level1Count", tuple2._2.getLevel1Count())
.append("level2Count", tuple2._2.getLevel2Count())
.append("level3Count", tuple2._2.getLevel3Count())
.append("orgId", tuple2._2.getOrgId());
documents.add(document);
}
MongoManager.saveToMongo(documents, BaseConstant.ALARM_TARGET_TABLE);
}
直接运行上述main方法会将AlarmStatisticBean对象保存到MongoDB中
二、spark-submit脚本
提交到集群时,需要注释掉local
SparkConf conf = new SparkConf()
.setAppName("离线统计")
.setMaster("spark://" + SparkConfig.SPARK_MASTER_HOST + ":" + SparkConfig.SPARK_MASTER_PORT)
//.setMaster("local")
...
//带*的是公司名或项目名称,不影响阅读
spark-submit --class com.*.*.meter.alarm.AlarmStatisticService --master spark://master:7077 /opt/middleware/*-alarm-task-1.0-jar-with-dependencies.ja
--master spark:// 表示会使用独立模式,也就是使用spark自带的独立集群管理器。提交时使用的主机名和端口精确匹配用户页面中的URL,这里建议直接从http://172.*.*.6:8080页面上复制URL,避免不必要的麻烦。
三、SparkLauncher提交
SparkLauncher也提供了两种方式提交任务
3.1、launch
SparkLauncher实际上是根据JDK自带的ProcessBuilder构造了一个UNIXProcess子进程提交任务,提交的形式跟spark-submit一样。这个子进程会以阻塞的方式等待程序的运行结果。简单来看就是拼接spark-submit命令,并以子进程的方式启动。
代码中的process.getInputStream()实际上对应linux进程的标准输出stdout
process.getErrorStream()实际上对应linux进程的错误信息stderr
process.getOutputStream()实际上对应linux进程的输入信息stdin
@Scheduled(fixedRate = 5000 * 60)
public void alarmStatistic() {
logger.info("=====>>>>>离线统计定时任务!", System.currentTimeMillis());
try {
HashMap env = new HashMap();
//这两个属性必须设置
env.put("HADOOP_CONF_DIR", CommonConfig.HADOOP_CONF_DIR);
env.put("JAVA_HOME", CommonConfig.JAVA_HOME);
SparkLauncher handle = new SparkLauncher(env)
.setSparkHome(SparkConfig.SPARK_HOME)
.setAppResource(CommonConfig.ALARM_JAR_PATH)
.setMainClass(CommonConfig.ALARM_JAR_MAIN_CLASS)
.setMaster("spark://" + SparkConfig.SPARK_MASTER_HOST + ":" + SparkConfig.SPARK_MASTER_PORT)
.setDeployMode(SparkConfig.SPARK_DEPLOY_MODE)
.setVerbose(SparkConfig.SPARK_VERBOSE)
.setConf("spark.app.id", CommonConfig.ALARM_APP_ID)
.setConf("spark.driver.memory", SparkConfig.SPARK_DRIVER_MEMORY)
.setConf("spark.rpc.message.maxSize", SparkConfig.SPARK_RPC_MESSAGE_MAXSIZE)
.setConf("spark.executor.memory", SparkConfig.SPARK_EXECUTOR_MEMORY)
.setConf("spark.executor.instances", SparkConfig.SPARK_EXECUTOR_INSTANCES)
.setConf("spark.executor.cores", SparkConfig.SPARK_EXECUTOR_CORES)
.setConf("spark.default.parallelism", SparkConfig.SPARK_DEFAULT_PARALLELISM)
.setConf("spark.driver.allowMultipleContexts", SparkConfig.SPARK_DRIVER_ALLOWMULTIPLECONTEXTS)
.setVerbose(true);
Process process = handle.launch();
InputStreamRunnable inputStream = new InputStreamRunnable(process.getInputStream(), "alarm task input");
ExecutorUtils.getExecutorService().submit(inputStream);
InputStreamRunnable errorStream = new InputStreamRunnable(process.getErrorStream(), "alarm task error");
ExecutorUtils.getExecutorService().submit(errorStream);
logger.info("Waiting for finish...");
int exitCode = process.waitFor();
logger.info("Finished! Exit code:" + exitCode);
} catch (Exception e) {
logger.error("submit spark task error", e);
}
}
运行过程示意图
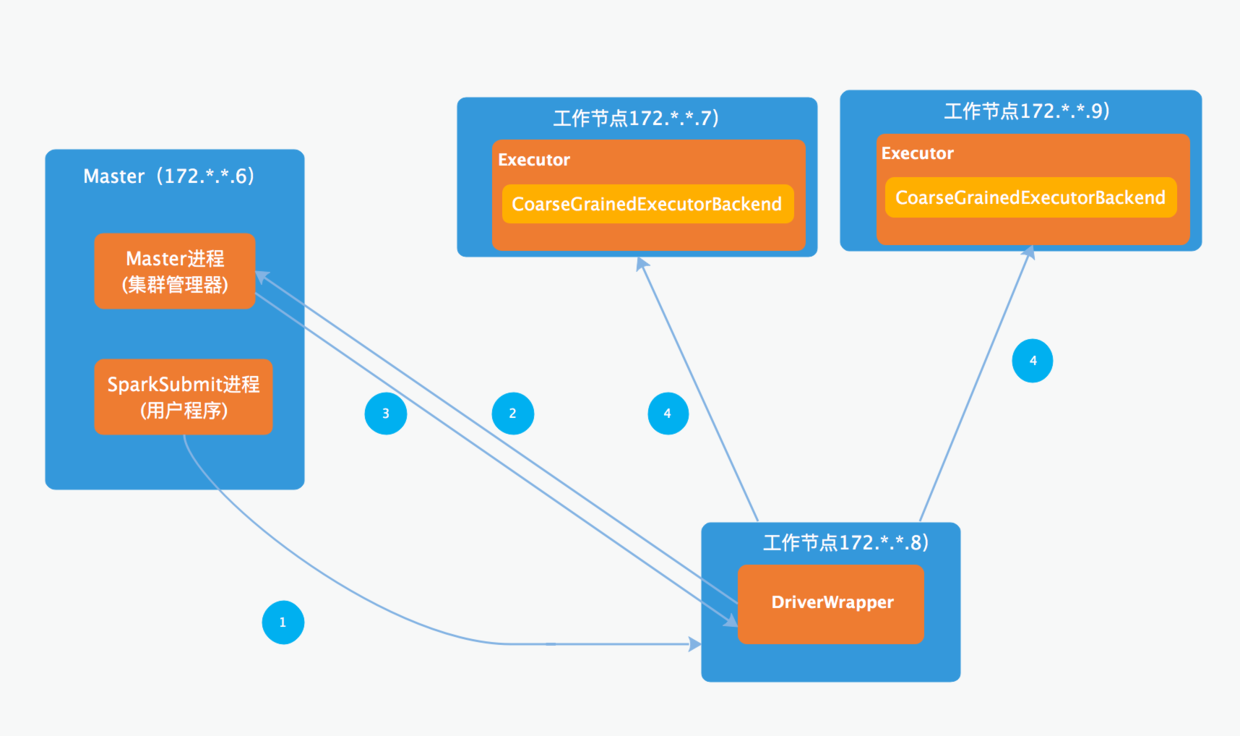
1:用户程序启动(SparkLauncher,非驱动程序)时会在当前节点上启动一个SparkSubmit进程,并将驱动程序(即spark任务)发送到任意一个工作节点上,在工作节点上启动DriverWrapper进程
2:驱动程序会从集群管理器(standalone模式下是master服务器)申请执行器资源
3:集群管理器反馈执行器资源给驱动器
4:驱动器Driver将任务发送到执行器节点执行
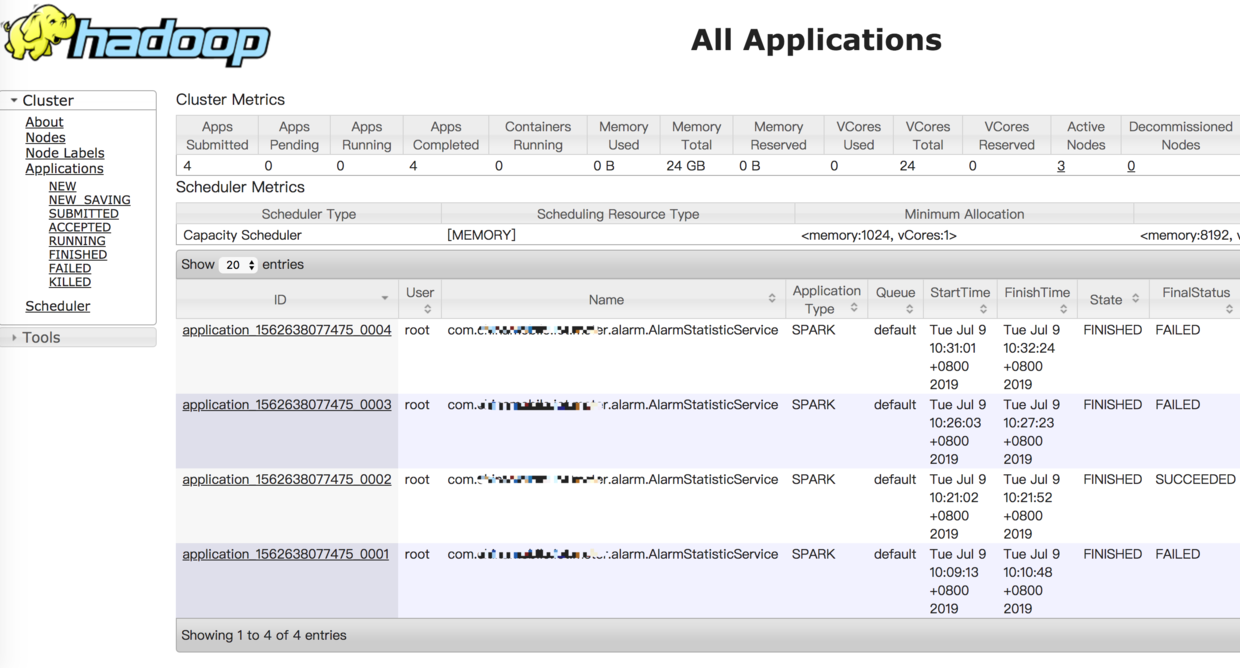
spark首页监控
可以看到启动的Driver
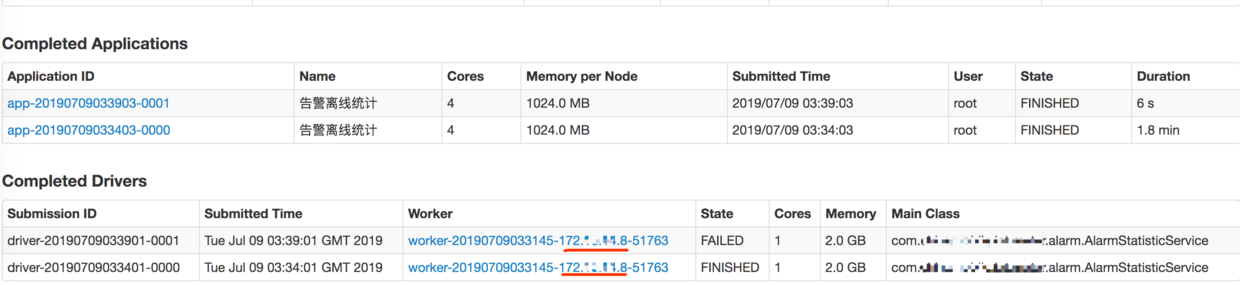

也可通过服务器进程查看各进程之间的关系
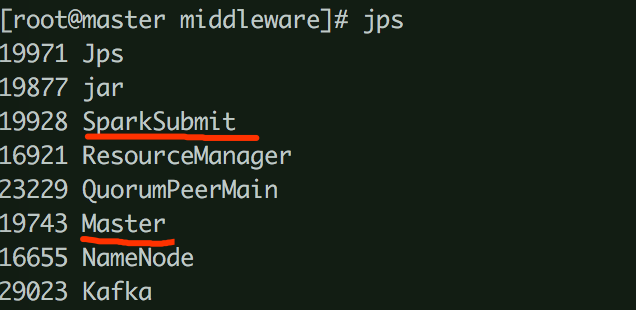
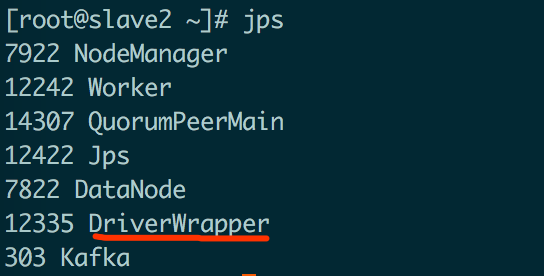
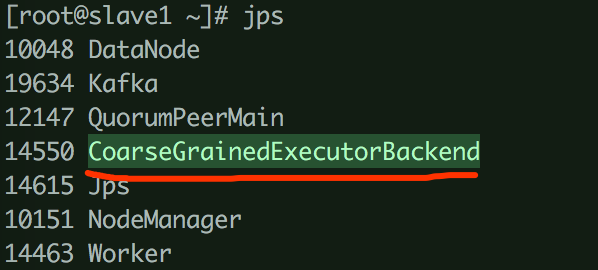
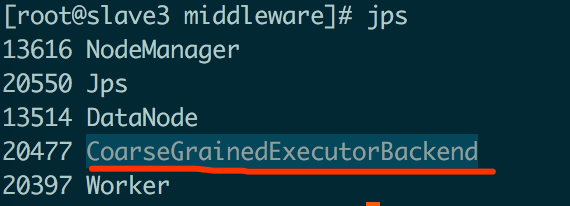
3.2、startApplication()方式
@Scheduled(fixedRate = 5000 * 60)
public void alarmStatistic() {
logger.info("=====>>>>>告警离线统计定时任务!", System.currentTimeMillis());
try {
HashMap env = new HashMap();
//这两个属性必须设置
env.put("HADOOP_CONF_DIR", CommonConfig.HADOOP_CONF_DIR);
env.put("JAVA_HOME", CommonConfig.JAVA_HOME);
CountDownLatch countDownLatch = new CountDownLatch(1);
SparkAppHandle handle = new SparkLauncher(env)
.setSparkHome(SparkConfig.SPARK_HOME)
.setAppResource(CommonConfig.ALARM_JAR_PATH)
.setMainClass(CommonConfig.ALARM_JAR_MAIN_CLASS)
.setMaster("spark://" + SparkConfig.SPARK_MASTER_HOST + ":" + SparkConfig.SPARK_MASTER_PORT)
// .setMaster("yarn")
.setDeployMode(SparkConfig.SPARK_DEPLOY_MODE)
.setVerbose(SparkConfig.SPARK_VERBOSE)
.setConf("spark.app.id", CommonConfig.ALARM_APP_ID)
.setConf("spark.driver.memory", SparkConfig.SPARK_DRIVER_MEMORY)
.setConf("spark.rpc.message.maxSize", SparkConfig.SPARK_RPC_MESSAGE_MAXSIZE)
.setConf("spark.executor.memory", SparkConfig.SPARK_EXECUTOR_MEMORY)
.setConf("spark.executor.instances", SparkConfig.SPARK_EXECUTOR_INSTANCES)
.setConf("spark.executor.cores", SparkConfig.SPARK_EXECUTOR_CORES)
.setConf("spark.default.parallelism", SparkConfig.SPARK_DEFAULT_PARALLELISM)
.setConf("spark.driver.allowMultipleContexts", SparkConfig.SPARK_DRIVER_ALLOWMULTIPLECONTEXTS)
.setVerbose(true).startApplication(new SparkAppHandle.Listener() {
//这里监听任务状态,当任务结束时(不管是什么原因结束),isFinal()方法会返回true,否则返回false
@Override
public void stateChanged(SparkAppHandle sparkAppHandle) {
if (sparkAppHandle.getState().isFinal()) {
countDownLatch.countDown();
}
System.out.println("state:" + sparkAppHandle.getState().toString());
}
@Override
public void infoChanged(SparkAppHandle sparkAppHandle) {
System.out.println("Info:" + sparkAppHandle.getState().toString());
}
});
logger.info("The task is executing, please wait ....");
//线程等待任务结束
countDownLatch.await();
logger.info("The task is finished!");
} catch (Exception e) {
logger.error("submit spark task error", e);
}
}
这种模式下,据本人亲自测试,只有在yarn工作模式下可以提交成功,在standalone模式下总是提交失败,如果有人知道的可以告诉我
yarn模式需要安装hadoop集群,提交任务的流程基本和上面是一样的,不同的是集群管理器不在是spark自带的集群管理器,而是由yarn来管理,这也是官方推荐的提交方式,比较麻烦的就是需要安装hadoop集群,hadoop的安装参加另一篇
Hadoop集群搭建
从监控页面可以看到application的执行情况