

OpenGL 介绍
OpenGL是一种图形硬件的软件接口。它被设计成一种可以运行在多种不同硬件平台上与硬件无关的接口。OpenGL程序也可以跨过网络工作(客户-服务器的形式),即使客户机和服务器是不同的机器类型。OpenGL中的客户机是OpenGL程序真正执行的机器,而服务器是实现渲染的机器。
OpenGL在OpenGL核心的命令前使用了前缀gl,在OpenGL工具类中的命令前使用了前缀glu。相似地,OpenGL常量都是以GL_开始的并且全部都是大写字母。OpenGL也使用后缀来指定函数的函数数目和类型。
glColor3f(1, 0, 0); // 使用3个浮点型的数字设置渲染颜色为红色
glColor4d(0, 1, 0, 0.2); // 使用双精度浮点型设置渲染颜色为绿色,不透明度为20%
glVertex3fv(vertex); // 使用向量设置x,y,z的坐标
状态机
OpenGL是一个状态机。属性和模式将保持作用效果直到它们被改变为止。大多数状态变量能使用glEnable()函数和glDisable()函数来启用和禁用。你也可以使用glIsEnabled()函数来检查一个状态现在是否被启用。你能使用glPushAttrib()函数和glPopAttrib()函数来将很多状态变量保存在一个存放属性变量的栈中或从这个栈中恢复出来。GL_ALL_ATTRIB_BITS参数能被用来保存或恢复所有的状态。栈的数目在标准OpenGL中至少有16个(使用glinfo函数检查栈最多能容纳的元素个数)。
glPushAttrib(GL_LIGHTING_BIT); // 改变状态的最佳方式,这样后面你能使用glPopAttrib()函数恢复到现在的状
glDisable(GL_LIGHTING); //态,第一行代码将GL_LIGHTING_BIT状态入栈,这样接下来可以对这个状态进行
glEnable(GL_COLOR_MATERIAL); // 修改,并且某一时刻可以恢复到入栈时的状态
glPushAttrib(GL_COLOR_BUFFER_BIT);
glDisable(GL_DITHER);
glEnable(GL_BLEND);
... // do something
glPopAttrib(); // 第一次调用将恢复最后入栈时的状态,即GL_COLOR_BUFFER_BIT
glPopAttrib(); // 第二次调用将恢复倒数第二次调用时的状态,即GL_LIGHTING_BIT
glBegin()和glEnd()函数
为了在OpenGL中绘制几何图元(点,线,三角形等),你可以在glBegin()和glEnd()函数之间指定一系列顶点数据。这种方法叫做立即模式。(你也可以使用其他方法绘制几何图元,如顶点数组)
glBegin(GL_TRIANGLES);
glColor3f(1, 0, 0); // 设置顶点的颜色为红色
glVertex3fv(v1); // 使用v1,v2,v3这3个顶点绘制三角形
glVertex3fv(v2);
glVertex3fv(v3);
glEnd();
OpenGL中有10种图元类型:GL_POINTS, GL_LINES, GL_LINE_STRIP, GL_LINE_LOOP, GL_TRIANGLES, GL_TRIANGLE_STRIP, GL_TRIANGLE_FAN, GL_QUADS, GL_QUAD_STRIP, 和 GL_POLYGON.
注意并不是所有的OpenGL命令都可以放置在glBegin()和glEnd()之间的。只有一部分命令可以放置在这两个函数之间,如glVertex*(),glColor*(),glNormal*(),glTexCoord*(),glMaterial*(),glCallList()等。
glFlush()和glFinish()函数
和计算机中的IO缓冲区比较类似,OpenGL命令并不是立即执行的。所有的命令首先被存储在缓冲区中,包括网络中的缓冲区和图形加速器自身,直到缓冲区满了才开始执行。例如,如果一个应用程序需要通过网络来执行,那么一次发送一系列的命令显然比一次只发生一个命令更加高效。
glFlush()清空这个缓冲区中的所有命令并且强迫这个命令立即执行而不需要等待缓冲区塞满。因此glFlush保证了所有OpenGL命令在调用glFlush()之后在有限的时间内会被全部执行。并且glFlush函数不会等待之间的命令执行完且有可能立即返回到你的程序中。因此,你可以很自由地发送更多的命令即使之间的命令没有被执行完。
glFinish()像glFlush函数一样刷新缓冲区并强迫命令开始执行。但是glFinish函数块会阻塞其他的OpenGL命令直到glFinish函数块中的所有命令被执行完。因此,glFinish()函数直到所有的OpenGL命令都被执行完了才会返回到你的程序中。它可能被用来同步任务或者测量某个OpenGL命令的准确的执行时间。
OpenGL渲染管线
OpenGL渲染管线包含一系列有序地处理数据的阶段。两种图形数据即基于顶点的数据和基于像素的数据,在渲染管线中处理并统一输出到帧缓冲区。注意,OpenGL可以将处理后的数据重新发送到你的程序中(注意下图中的灰色线条)。
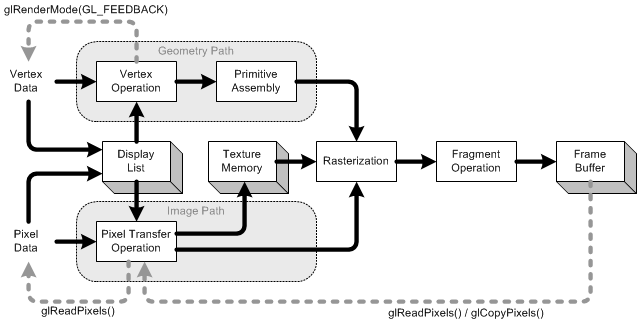
显示列表(Display List)
OpenGL在即时模式(Immediate Mode)下绘图时,程序中每条语句产生的图形对象被直接送进绘图流水线,在显示终端立即绘制出来。当需要在程序中多次绘制同一个复杂的图像对象时,这种即时模式会消耗大量的系统资源,降低程序的运行效率,为此,OpenGL提供了一种更有效组织OpenGL语句的形式——显示列表。
显示列表是一组被存储或编译的用来以后执行的OpenGL命令的集合。当一个显示列表被创建以后,所有的顶点数据和像素数据被复制到位于服务器端的显示列表内存中。这个过程只进行一次。当显示列表准备好(被编译完成)后,你可以重复使用它而不需要在每帧中重复地传输这些数据。显示列表是最快的一种绘制静态数据的方式,因为顶点数据和OpenGL命令被缓冲在服务器端的显示列表中,这样减少了从客户端到服务器段的数据传输。这意味着减少了执行实际的数据传输的CPU周期。
显示列表另一个重要的功能是显示列表可以被多个客户端所共享,因为它是服务器端的状态。
为了最佳的性能,将矩阵变换,光照,材质计算尽可能地放在显示列表中,这样OpenGL将只会在显示列表创建时执行一次这些高昂开销的计算,并将最终的结果存储在显示列表中。
然而,显示列表有一个缺点。当一个显示列表被编译后,它不能被改变。如果你需要频繁地改变数据或需要动态的数据,使用顶点数组或顶点缓冲区对象。顶点缓冲区对象可以同时处理静态和动态的数据。
注意并不是所有的OpenGL命令都可以存储在显示列表中。由于显示列表是服务器端的状态,所有与客户端状态相关的命令不能被放置在显示列表中。例如:glFlush(),glFinish(),glRenderMode(),glEnableClientState(),glVertexPointer()等这些函数不能放在显示列表中。并且有返回值的OpenGL命令也不能放在显示列表中,因为这些返回值需要被返回到客户端,而不是显示列表中,例如:glIsEnabled(),geGet*(),glReadPixels(),glFeedbackBuffer()等。如果这些命令存储在显示列表中,它们将会被立即执行。
建立显示列表
分配显示列表编号
OpenGL中用正整数来区分不同的显示列表,为防止重复定义已经存在的显示列表号,使用glGenLists函数来自动分配一个没有被使用过的显示列表编号。
glGenLists函数原型:
GLuint glGenLists (GLsizei range);
参数range指定要分配几个显示列表。
返回值是被分配的显示列表中的最小编号,若返回0表示分配失败。
创建显示列表
创建显示列表声明了把哪些OpenGL语句装入到当前显示列表中。使用glNewList开始装入,使用glEndList结束装入。
glNewList的函数原型如下:
void glNewList (GLuint list, GLenum mode);
第一个参数标示当前正在操作的显示列表号
第二个参数有两种取值--GL COMPILE和GL COMPILE AND EXECUTE,前者声明当前显示列表只是装入相应OpenGL语句,不执行;后者表示在装入的同时,执行一遍当前显示列表。
并不是所有的OpenGL函数都可以装入到显示列表中,一般来说,用于传递参数或具有返回数值的函数语句不能存入显示列表。
调用显示表
调用显示列表只需要在需要调用的地方插入glCallList(id)即可,入参id表示了要调用的显示列表的编号。另外也可以使用glCallLists一次性调用一组显示列表。
删除显示表
在退出程序前要将所建立的显示表删除,释放显示列表占用的资源。
glDeleteLists(GLuint list,GLsizei range)
用来删除用户建立的显示列表。
参数list表示要删除的第一个显示列表的数字编号;参数range表示从指定的第一个显示表开始要删除的连续的显示表个数。
显示列表的适用场合
并不是所有场合下显示列表都可以优化程序性能,这是因为调用显示列表本身时程序也会产生一些开销,若一个显示列表太小,这个开销将超过显示列表的所带来的效率提升。以下是一些非常适合使用显示列表的场景:
矩阵操作:大部分矩阵操作需要OpenGL计算逆矩阵,矩阵及其逆矩阵都可以保存在显示列表中。
光栅位图和图像:程序定义的光栅数据不一定是适合硬件处理的理想格式。当编译组织一个显示列表时,OpenGL可能把数据转换成硬件能够接受的数据,这可能有效地提高画位的速度。
光、材质和光照模型:当用一个比较复杂的光照环境绘制场景时,可以为场景中的每个物体改变材质。但是材质计算较多,因此设置材质可能比较慢。若把材质定义放在显示列表中,则每次改换材质时就不必重新计算了。因为计算结果存储在表中,因此能更快地绘制光照场景。
纹理:因为硬件的纹理格式可能与OpenGL格式不一致,若把纹理定义放在显示列表中,则在编译显示列表时就能对格式进行转换,而不是执行中进行,这样就能大大提高效率。
多边形的图案填充模式:可将定义的图案放在显示列表中。
顶点操作(Vertex Operation)
每个顶点和法向量坐标需要经过GL_MODELVIEW(模型视图矩阵,从物体坐标系到人眼坐标系)矩阵变换。同样地,如果光照状态开启,作用在每个顶点上的光照计算是使用变换后的顶点和法向量数据。光照计算会更新每个顶点的颜色。
图元装配(Primitive Assembly)
顶点操作之后,图元(点,线,三角形)再次经过投影变换,然后经过裁剪平面裁剪,从人眼坐标系变换到裁剪坐标系。经过上述操作之后,再次经过透视除法和视口变换从而将三维的场景映射到窗口的区域坐标中。图元装配中最后要做的一件事就是如果裁剪状态开启则进行裁剪测试。
像素转换操作(Pixel Transfer Operation)
将像素数据从客户端内存中读取进来以后,数据会经过缩放,映射等一系列操作。这些操作叫做像素转换操作。转换后的数据被存储在纹理中或直接光栅化到片元中。
纹理内存(Texture Memory)
纹理图片被加载到纹理内存中以便应用到几何对象上。
光栅化(Raterization)
光栅化将几何数据和像素数据转换到片元中。片元是一种可以包含颜色,深度值,线宽,点大小和抗锯齿计算(GL_POINT_SMOOTH, GL_LINE_SMOOTH, GL_POLYGON_SMOOTH)的矩形数组。如果明暗模式是GL_FILL,那么多边形内部的像素将会在这个阶段被填充。每一个片元对于帧缓冲区中的一个像素。
片元操作(Fragment Operation)
这是将片元转换成要传输到帧缓冲区中的像素的最后一步。首先进行纹素生成;纹理元素通过纹理内存生成并且被应用到每一个片元。然后进行雾计算。接下来是一系列有序的片元测试操作:裁剪测试->alpha测试->模板测试->深度测试。
最后,经过混合,抖动,逻辑操作,遮挡这些操作实际的纹理数据被存储到帧缓冲区中。
反馈(Feedback)
OpenGL能通过glGet*()和glIsEnabled()命令返回大多数当前的状态和信息。除此之外,可以使用glReadPixels()函数从帧缓冲区中读取一个长方形区域的像素数据,使用glRenderMode(GL_FEEDBACK)函数得到变换后的顶点数据。glCopyPixels不会返回像素数据到指定的系统内存中,而是将他们复制到另一个缓冲区中,如将前台缓冲区中的像素数据复制到后台的缓冲区中。
OpenGL变换
在OpenGL渲染管线中几何数据(顶点位置和法向量)在光栅化处理之前会先经过顶点操作和图元装配。

物体坐标系(Object Coordinates)
这是物体的局部坐标系,并且表示物体未经过任何变换前的初始位置和朝向。为了变换物体,使用glRotatef(),glTranslatef(),glScalef()等函数。
人眼坐标系(Eye Coordinates)
这是将GL_MODELVIEW(模型视图矩阵)与物体坐标相乘产生的。在OpenGL中物体从物体自身的坐标变换到人眼坐标使用GL_MODELVIEW矩阵。GL_MODELVIEW矩阵是将模型矩阵和视图矩阵相乘的结果()。模型变换是将物体坐标变换到世界坐标,视图变换是将世界坐标变换到人眼坐标。
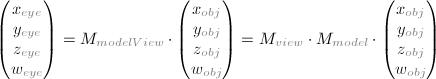
注意在OpenGL中没有单独的照相机(视图)矩阵。因此,为了模仿视图变换,场景(三维物体和光照)必须使用视图变换的反转进行变换。换句话说,OpenGL定义的照相机在人眼坐标系中一直在(0,0,0)位置并且指向Z轴的负半轴,并且不能进行变换。
模型视图矩阵
定义了3个矩阵对象:matrxModel,matrixView和matrixModelView。每个矩阵存储了前乘的变换并使用glLoadMatrix()函数将矩阵中的元素传递到OpenGL中。
...
glPushMatrix();
// 为视图变换设置视图矩阵
glLoadMatrixf(matrixView.getTranspose());
// 在模型变换之前绘制最原始的网格
drawGrid();
// 为模型变换和视图变换设置模型视图矩阵
// 从物体坐标系变换到人眼坐标系
glLoadMatrixf(matrixModelView.getTranspose());
// 模型视图变换之后绘制一个茶壶
drawTeapot();
glPopMatrix();
...
相同的功能使用OpenGL默认的矩阵操作函数如下:
...
glPushMatrix();
// 将模型视图矩阵归一化
glLoadIdentity();
// 首先,将视图从物体坐标系变换到人眼坐标系
// 注意所有的值都是负数,因为我们是使用视图矩阵的逆来移动整个场景
glRotatef(-cameraAngle[2], 0, 0, 1); // roll
glRotatef(-cameraAngle[1], 0, 1, 0); // heading
glRotatef(-cameraAngle[0], 1, 0, 0); // pitch
glTranslatef(-cameraPosition[0], -cameraPosition[1], -cameraPosition[2]);
// 在模型变换之前绘制最原始的网格
drawGrid();
// 模型变换
// GL_MODELVIEW矩阵的结果如下:
// ModelView_M = View_M * Model_M
glTranslatef(modelPosition[0], modelPosition[1], modelPosition[2]);
glRotatef(modelAngle[0], 1, 0, 0);
glRotatef(modelAngle[1], 0, 1, 0);
glRotatef(modelAngle[2], 0, 0, 1);
// 模型视图变换之后绘制一个茶壶
drawTeapot();
glPopMatrix();
...
法向量为了后续的光照计算也会从物体坐标系变换到人眼坐标系。注意法向量和顶点变换的不同方式。它是将GL_MODELVIEW的逆矩阵的转置矩阵乘以法向量。

裁剪坐标(Clip Coordinates)
将GL_PROJECTTION与人眼坐标相乘就得到了裁剪坐标。GL_PROJECTION(投影矩阵)定义了视景体;几何数据怎么被投影到屏幕中(透视投影或正投影)。它被称为裁剪坐标是因为变换后的顶点坐标(x,y,z)经过了裁剪(通过与-w和+w的比较)。

投影变换
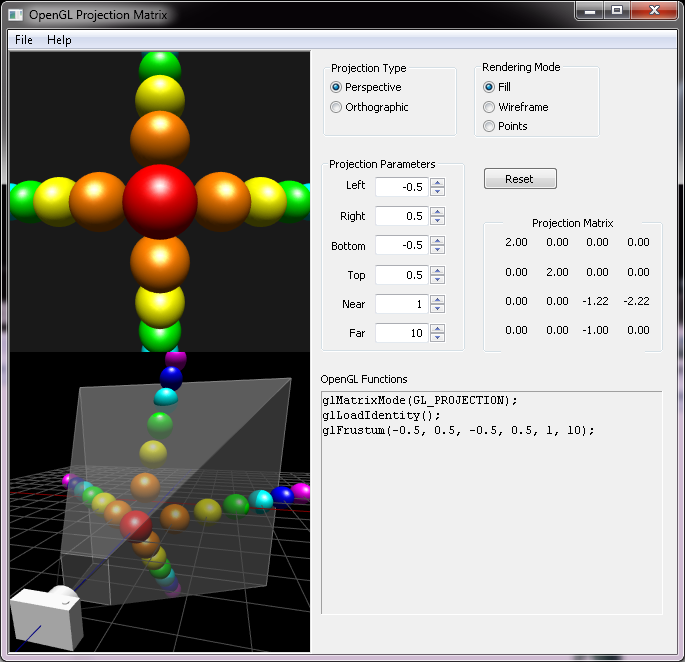
ModelGL类有一个自定义的矩阵对象,matrixProjection,和两个成员函数,setFrustum()和setOrthoFrustum(),这两个函数等价于glFrustum()和glOrtho()。
///////////////////////////////////////////////////////////////////////////////
// 使用6个参数像glFrustum()函数一样设置一个透视的视景体
// (left, right, bottom, top, near, far)
// 注意:这是以行为主的标记方式,OpenGL需要先将其转置
///////////////////////////////////////////////////////////////////////////////
void ModelGL::setFrustum(float l, float r, float b, float t, float n, float f)
{
matrixProjection.identity();
matrixProjection[0] = 2 * n / (r - l);
matrixProjection[2] = (r + l) / (r - l);
matrixProjection[5] = 2 * n / (t - b);
matrixProjection[6] = (t + b) / (t - b);
matrixProjection[10] = -(f + n) / (f - n);
matrixProjection[11] = -(2 * f * n) / (f - n);
matrixProjection[14] = -1;
matrixProjection[15] = 0;
}
///////////////////////////////////////////////////////////////////////////////
// 使用6个参数像glOrtho()函数一样设置一个正投影的视景体
// (left, right, bottom, top, near, far)
// 注意:这是以行为主的标记方式,OpenGL需要先将其转置
///////////////////////////////////////////////////////////////////////////////
void ModelGL::setOrthoFrustum(float l, float r, float b, float t, float n,
float f)
{
matrixProjection.identity();
matrixProjection[0] = 2 / (r - l);
matrixProjection[3] = -(r + l) / (r - l);
matrixProjection[5] = 2 / (t - b);
matrixProjection[7] = -(t + b) / (t - b);
matrixProjection[10] = -2 / (f - n);
matrixProjection[11] = -(f + n) / (f - n);
}
...
// 将投影矩阵传递给OpenGL
glMatrixMode(GL_PROJECTION);
glLoadMatrixf(matrixProjection.getTranspose());
...
归一化的设备坐标(Normalized Device Coordinates(NDC))
将裁剪坐标与w相除就得到归一化的设备坐标。它被称为透视除法。它更像窗口坐标,但是还没有被平移和缩放到匹配窗口。现在3个坐标轴上变量的取值被归一化到-1到1之间。
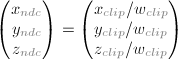
窗口坐标(Window Coordinates(Screen Coordinates)) 这是将归一化的设备坐标应用到视口变换而产生的。归一化的设备坐标经过缩放了平移以匹配窗口。窗口坐标最后被传递给OpenGL渲染管线中光栅化程序生成片元。glViewport()命令被用来定义最后渲染出来的图像将要映射到的长方形区域。glDepthRange()命令被用来定义窗口坐标的z值的范围。窗口坐标是经过下面这两个函数变换得到的
glViewport(x,y,w,h);
glDepthRange(n,f);
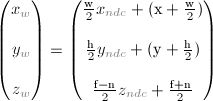
视口变换公式是一个从NDC到窗口坐标的简单的线性变换。
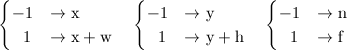
OpenGL变换矩阵
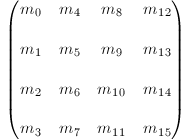
OpenGL使用一个4*4的矩阵来表示变换。注意矩阵中的16个元素是按列的顺序存储在一个一维数组中。如果你需要将他转换成标准型,即按行存储,则需要将这个矩阵转置。 OpenGL有4中不同类型的矩阵:GL_MODELVIEW(模型视图矩阵),GL_PROJCETION(投影矩阵),GL_TEXTURE(纹理矩阵),GL_COLOR(颜色矩阵)。你可以通过使用glMatrixMode()函数改变当前的矩阵类型。例如,为了选中GL_MODELVIEW矩阵,使用glMatrixMode(GL_MODELVIEW).
模型-视图 矩阵(GL_MODELVIEW)
GL_MODEVIEW矩阵联合和视图矩阵和模型矩阵到一个矩阵中。为了变换视图(相机),你需要将整个场景按照视图矩阵的逆进行移动。gluLookAt()函数是用来设置视图变换的。
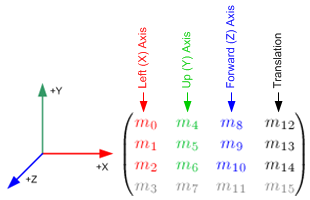
上图中(m12,m13,m14)表示glTranslatef()函数进行的平移变换。m15是齐次坐标,主要用来进行投影变换。 3个元素集,(m0,m1,m2), (m4,m5,m6)和(m8,m9,m10)是用来表示欧氏变化,如旋转(glRoattef()),和缩放(glScalef())。注意这3个集合实际上表示的是3个正交的轴。
(m0,m1,m2):+X轴,指向右边的向量,默认为(1,0,0)
(m4,m5,m6):+Y轴,指向上边的向量,默认为(0,1,0)
(m8,m9,m10):+Z轴,指向前边的向量,默认为(0,0,1)
我们可以使用角度或观察点直接构造GL_MODELVIEW矩阵而不使用OpenGL的变换函数。下面是一些构造GL_MODELVIEW矩阵的有用的代码:
角度到坐标轴
观察点到坐标轴
矩阵类
注意如果多个变换应用到顶点中时OpenGL是按照相反的顺序执行的。例如,如果一个顶点首先经过矩阵MA变换,然后经过矩阵MB变换,然后OpenGL在将矩阵与顶点相乘之前会首先执行MBxMA操作。因此,最后的变换会首先被应用,最早的变换会最后被应用。
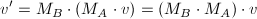
// 注意对象首先被平移,然后被旋转
glRotatef(angle, 1, 0, 0); // 将对象绕x轴旋转angle角度
glTranslatef(x, y, z); // 移动对象到(x,y,z)处
drawObject();
投影矩阵(GL_PROJECTION)
GL_PROJECTION矩阵被用来定义截头锥。这个截头锥决定了哪些物体或物体的哪些部分会被裁剪掉。它也定义了三维场景将会如何被映射到屏幕上。(更多细节参考如果构造投影矩阵) OpenGL为GL_PROJCETION变换提供了两个函数。glFrustum()用来产生一个透视投影,glOrtho()用来产生一个正投影。两个函数都需要6个参数来指定6个裁剪面:左面,右面,上面,近面,远面。截头锥的8个顶点如下图:
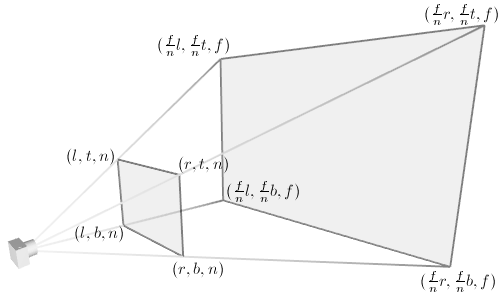
近(远)面的坐标计算可以通过相似三角形计算得到,如左面的计算方法:
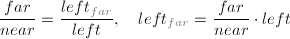
对正投影而言,相似三角形的比例是1,因此远平面的左,右,上,下点的坐标和近平面是一样的。如下图:
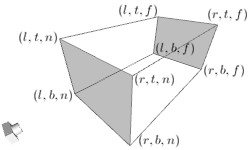
你也可以传递更少的参数给gluPerspective()函数和gluOrtho2D()函数。gluPerspective()函数只需要4个参数;视线的垂直夹角,面的宽高比,视点距近裁剪面和远裁剪面的距离。4个参数与6个参数之间的相互转换的代码如下:
// 这创建了一个对称的截头锥
// 它将给定的4个参数(fovy, aspect, near, far)转换
// 成glFrustum()所需的6个参数:(l, r, b, t, n, f)
void makeFrustum(double fovY, double aspectRatio, double front, double back)
{
const double DEG2RAD = 3.14159265 / 180;
double tangent = tan(fovY/2 * DEG2RAD); // fovY的一半的正切,fovY是视线的夹角
double height = front * tangent; // 近裁剪面的高度的一半
double width = height * aspectRatio; // 近裁剪面的宽度的一半
// params: left, right, bottom, top, near, far
glFrustum(-width, width, -height, height, front, back);
}
然而,如果你需要创建一个不对称的视景体那么必须直接使用glFrustum()函数。例如,如果你需要渲染一个宽屏场景到两个邻接的屏幕中,你可以将视景体划分成两个不对称的视景体(左边和右边),然后将场景分别渲染到两个视景体中,如下图:
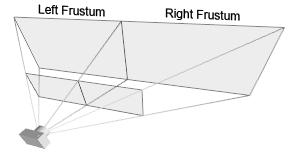
纹理矩阵(GL_TEXTURE)
纹理坐标(s,t,r,q)在纹理映射之前会和GL_TEXTURE(纹理矩阵)相乘。默认情况下它是归一化的,所以纹理将会准确映射物体上你指定的纹理坐标处。通过修改GL_TEXTURE,你可以移动,旋转,拉伸,收缩纹理。
// 将纹理绕x轴旋转
glMatrixMode(GL_TEXTURE);
glRotatef(angle, 1, 0, 0);
颜色矩阵(GL_COLOR)
颜色值(r,g,b,a)会和矩阵GL_COLOR相乘。它可以被用来交换颜色空间和颜色值。GL_COLOR矩阵不会被普遍使用因为它需要GL_ARB_imaging扩展支持。
其他一些矩阵操作
glPushMatrix():将当前矩阵压入当然矩阵栈中
glPopMatrix():从当前矩阵栈中弹出一个元素
glLoadIdentify():将当前矩阵设置为单位矩阵(归一化)
glLoadMatrix{fd}(m):将当前矩阵替换成矩阵m
glLoadTransposeMatrix{fd}(m):将当前矩阵替换成以行为主的矩阵m
glMultMatrix{fd}(m):m乘以当前矩阵,并将结果设置为当前矩阵
glMultTransposeMatrix{fd}(m):将以行为主的矩阵乘以当前矩阵,并将结果设置为当前矩阵
glGetFloatv(GL_MODELVIEW_MATRIX,m):返回模型视图矩阵到矩阵m
OpenGL矩阵类
OpenGL为渲染管线准备了4种不同类型的矩阵(GL_MODELVIEW,GL_PROJECTION, GL_TEXTURE and GL_COLOR)并且为这些矩阵提供了变换的操作:glLoadIdentity(),glTranslatef(),glRotatef(),glScalef(),glMultMatrixf(),glFrustum()和glOrtho().
这些内置的矩阵和操作对于开发简单的OpenGL应用程序非常有用并且非常有利于理解矩阵变换。但是当你的应用程序变的复杂的时候,最好是自己为所有需要移动的对象实现你自己的矩阵和操作。除此之外,你也不可以在可编程的管线(GLSL),像OpenGL v3.0+, OpenGL ES v2.0+ 和 WebGL v1.0+中使用这些内置的矩阵和操作。你必须实现你自己的矩阵并且将矩阵中的数据传递到着色器中。
构造&初始化
Matrix4类包含一个16个浮点型元素的数组来存储4*4的矩阵,它有3个构造函数来实例化这个Matrix4类的对象。
以行为主的Matrix4

OpenGL中使用的以列为主的矩阵
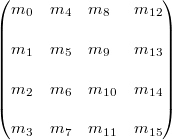
注意这个Matrix4类使用以行为主的标记次序而不是像OpenGL那样使用以列为主的标记次序。然儿,以行为主的次序和以列为主的次序只是两种不同的将多维数组中的数据存储的一维数组中的方式,这对矩阵的算法和矩阵的操作结果是没有影响的。
缺省的构造函数(没有参数)将会创建一个单位矩阵。其他两个构造函数接受16个参数或者包含16个参数的数组。你也可以使用复制构造或赋值操作符(=)来初始化一个Matrix4类的实例。
顺便说一下,复制构造和赋值操作符(=)会由C++编译器自动生成。
下面是一个使用不同方式构造Matrix4对象的例子。首先,需要在使用Matrix4类的文件中包含Matrices.h头文件。
#include "Matrices.h" // 为 Matrix2, Matrix3, Matrix4准备的
...
// 使用缺省的构造函数构造一个单位矩阵
Matrix4 m1;
// 使用16个元素构造一个矩阵
Matrix4 m2(1, 1, 1, 1, // 第一行
1, 1, 1, 1, // 第二行
1, 1, 1, 1, // 第三行
1, 1, 1, 1); // 第四行
// 使用一个数组够造一个矩阵
float a[16] = {2,2,2,2, 2,2,2,2, 2,2,2,2, 2,2,2,2};
Matrix4 m3(a);
//使用复制构造和赋值操作符构造一个矩阵
Matrix4 m4(m3);
Matrix4 m5 = m3;
Matrix4存取操作
Matrix4类提供set()函数来设置所有的16个元素。
Matrix4 m1;
// 使用16个元素来设置矩阵
m1.set(1,1,1,1, 1,1,1,1, 1,1,1,1, 1,1,1,1);
// 使用数组来设置矩阵
float a1[] = {2,2,2,2, 2,2,2,2, 2,2,2,2, 2,2,2,2};
m1.set(a1);
你也可以使用setRow()和setColumn()函数一次来设置一行或一列的值,setRow()和setColumn()函数的第一个参数是一个基于0的索引,第二个参数是指向数组的指针。
Matrix4 m2;
float a2[4] = {2,2,2,2};
// 使用索引和数组设置一行的值
m2.setRow(0, a2); // 1st row
// 使用索引和数组设置一列的值
m2.setColumn(2, a2); // 3rd column
单位矩阵
identify()函数用来生成一个单位矩阵
// 设置一个单位矩阵
Matrix4 m3;
m3.identity();
Matrix4::get()方法返回一个指向拥有16个元素的数组。getTranspose()返回转置后的矩阵元素。它专门用来将矩阵中的数据传递到OpenGL中
// 得到矩阵中的元素并赋值个一个数组
Matrix4 m4;
const float* a = m4.get();
//将矩阵传递给OpenGL
glLoadMatrixf(m4.getTranspose());
访问单个元素
矩阵中的单个元素可以通过[]操作符来访问:
Matrix4 m5;
float f = m5[0]; // 得到第一个元素
m5[1] = 2.0f; // 设置第二个元素
打印Matrix4
Matrix4也提供了一个便利的打印输出函数std::cout<<来方便调试:
Matrix4 m6;
std::cout << m6 << std::endl;
OpenGL矩阵算法
加法和减法
Matrix4 m1, m2, m3;
//相加
m3 = m1 + m2;
m3 += m1; //等价于: m3 = m3 + m1
// subtract
m3 = m1 - m2;
m3 -= m1; // 等价于: m3 = m3 - m1
乘法
Matrix4 m1, m2, m3;
// 矩阵相乘
m3 = m1 * m2;
m3 *= m1; // 等价于: m3 = m3 * m1
// 缩放操作
m3 = 2 * m1; // 将所有元素缩放
// 与向量相乘
Vector3 v1, v2;
v2 = m1 * v1;
v2 = v1 * m1; // 前乘
比较
Matrix4 m1, m2;
//精确比较
if(m1 == m2)
std::cout << "equal" << std::endl;
if(m1 != m2)
std::cout << "not equal" << std::endl;
Matrix4变换函数
OpenGL有几个变换函数:glTranslatef(),glRotatef()和glScalef()。Matrix4也提供了几个相同的函数来进行矩阵变换:translate(),rotate()andscale()。除此之外,Matrix4还提供了invert()函数计算矩阵的转置矩阵。
Matrix4::translate(x,y,z)
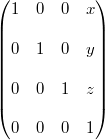
translate()函数产生经过(x,y,z)变换后的矩阵。首先,它创建一个变换矩阵MT,然后乘以当前矩阵来产生最终的矩阵:
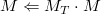
注意这个函数等价于OpenGL中的glTranslatef(),但是OpenGL使用后乘而不是前乘:
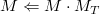
如果你执行多个变换,结果将会不一样因为矩阵相乘不满足交换律。
// M1 = Mt * M1
Matrix4 m1;
m1.translate(1, 2, 3); // 移动到(x, y, z)
Matrix4::rotate(angle,x,y,z)
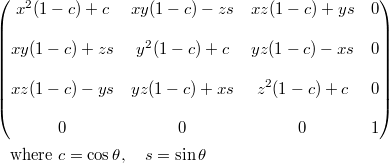
rotate()可以被用来通过指定一个轴(x,y,z)和绕轴旋转的角度来旋转三维模型。这个函数生成一个旋转矩阵MR,然后乘以当前矩阵生成一个最终经过旋转变换后的矩阵:
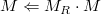
它等价于glRotatef(),但是OpenGL使用后乘操作来生成最终的变换后的矩阵:
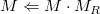
rotate()可以用来绕任意的轴旋转。Matrix4类提供了额外的3个函数绕指定轴旋转rotateX(),rotateY(),rotateZ()。
// M1 = Mr * M1
Matrix4 m1;
m1.rotate(45, 1,0,0); // 绕X轴旋转45度
m1.rotateX(45); // 和rotate(45, 1,0,0)一样
Matrix4::scale(x,y,z)
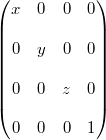
scale()在每一个轴上产生一个不均等的缩放效果的矩阵:
注意:OpenGL中glScalef()执行后乘操作:
Matrix4类也提供了均等的缩放函数。
// M1 = Ms * M1
Matrix4 m1;
m1.scale(1,2,3); // 非均等的缩放
m1.scale(4); // 均等的缩放,在所有轴上是一样的
Matrix::invert()
invert()函数计算当前矩阵的反转矩阵,这个反转矩阵主要用来将法向量从物体坐标系变换到人眼坐标系中。法向量和顶点的变换不一样。法向量变换是使用GL_MODELVIEW的反转乘以法向量:
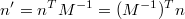
如果矩阵只是欧式变换(旋转和平移),或者放射变换(旋转,平移,缩放,裁剪),反转矩阵的计算会很简单。Matrix4::invert()将会为你决定何时的反转方式,但是如果你明确地调用了一个反转函数:invertEuclidean(),invertAffine(),invertProjective()o或invertGeneral()。
Matrix4 m1;
m1.invert(); // 反转矩阵
例子:模型视图矩阵
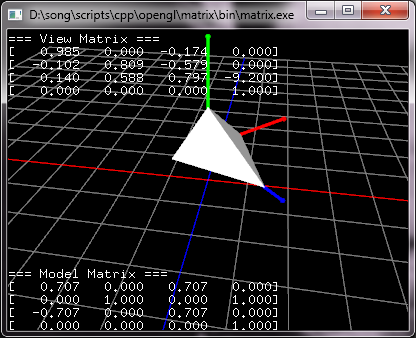
GL_MODELVIEW联合和视图矩阵和模型矩阵,但是我们将它们分开并传递两个矩阵给OpenGL的模型视图矩阵。
Matrix4 matModel, matView, matModelView;
glMatrixMode(GL_MODELVIEW);
...
// 视图变换
matView.identity(); // 变换次序:
matView.rotate(-camAngleY, 0,1,0); // 1: 绕Y轴旋转
matView.rotate(-camAngleX, 1,0,0); // 2: 绕X轴旋转
matView.translate(0, 0, -camDist); // 3: 沿Z轴平移
//模型变换
// 沿Y轴旋转45度,然后向上平移两个单位
matModel.identity();
matModel.rotate(45, 0,1,0); // 第一个变换
matModel.translate(0, 2, 0); // 第二次变换
//构造模型视图矩阵: Mmv = Mv * Mm
matModelView = matView * matModel;
// 将模型视图矩阵传递给OpenGL
// 注意:需要将矩阵转置
glLoadMatrixf(matModelView.getTranspose());
// 绘制
...
等价的OpenGL实现如下:
//注意:变换的次序是相反的
//因为OpenGL使用的是后乘
glMatrixMode(GL_MODELVIEW);
glLoadIdentity();
// 视图变换
glTranslatef(0, 0, -camDist); // 3: 沿Z轴平移
glRotatef(-camAngleX, 1,0,0); // 2: 绕X轴旋转
glRotatef(-camAngleY, 0,1,0); // 1: 绕Y轴旋转
// 模型变换
// 先绕Y轴旋转45度再向上平移2个单位
glTranslatef(0, 2, 0); // 2:平移
glRotatef(45, 0,1,0); // 1: 旋转
// 绘制
...
模型视图矩阵的反转用来将法向量从物体坐标系变换到人眼坐标系中。在可编程的渲染管线中,你需要将它传递给GLSL着色器。
//为法向量构造矩阵: (M^-1)^T
Matrix4 matNormal = matModelView; // 得到模型视图矩阵
matNormal.invert(); // 得到反转矩阵
matNormal.transpose(); // 将矩阵转置
例子:投影矩阵
这个例子显示了如何创建投影矩阵,等价于glFrustum()和glOrtho()。
// 设置投影矩阵并将其传递给OpenGL
Matrix4 matProject = setFrustum(-1, 1, -1, 1, 1, 100);
glMatrixMode(GL_PROJECTION);
glLoadMatrixf(matProject.getTranspose());
...
///////////////////////////////////////////////////////////////////////////////
// glFrustum()
///////////////////////////////////////////////////////////////////////////////
Matrix4 setFrustum(float l, float r, float b, float t, float n, float f)
{
Matrix4 mat;
mat[0] = 2 * n / (r - l);
mat[2] = (r + l) / (r - l);
mat[5] = 2 * n / (t - b);
mat[6] = (t + b) / (t - b);
mat[10] = -(f + n) / (f - n);
mat[11] = -(2 * f * n) / (f - n);
mat[14] = -1;
mat[15] = 0;
return mat;
}
///////////////////////////////////////////////////////////////////////////////
// gluPerspective()
///////////////////////////////////////////////////////////////////////////////
Matrix4 setFrustum(float fovY, float aspect, float front, float back)
{
float tangent = tanf(fovY/2 * DEG2RAD); // 视角一半的切
float height = front * tangent; // 近平面高度的一半
float width = height * aspect; // 近平面宽度的一半
// 参数: left, right, bottom, top, near, far
return setFrustum(-width, width, -height, height, front, back);
}
///////////////////////////////////////////////////////////////////////////////
// glOrtho()
///////////////////////////////////////////////////////////////////////////////
Matrix4 setOrthoFrustum(float l, float r, float b, float t, float n, float f)
{
Matrix4 mat;
mat[0] = 2 / (r - l);
mat[3] = -(r + l) / (r - l);
mat[5] = 2 / (t - b);
mat[7] = -(t + b) / (t - b);
mat[10] = -2 / (f - n);
mat[11] = -(f + n) / (f - n);
return mat;
}
...
OpenGL顶点数组
不像在立即模式(在glBegin()和glEnd()对之间)中指定单独的顶点数据 ,你可以存储顶点数据(顶点坐标,法向量,纹理坐标和颜色信息)在一系列数组中。你也可以利用数组的索引只取数组中的部分元素来绘制几何图元。
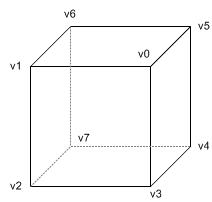
看一下下面的代码中使用立即模式绘制一个立方体的例子。
每一个面需要调用6次glVertex*()来绘制两个三角形,例如,前表面有v0-v1-v2和v2-v3-v0两个三角形。一个立方体有6个面,因此总共需要调用glVertex*()函数36次。如果你同时也指定法向量,纹理坐标和颜色给指定的顶点,也以同样的速度增加函数调用的次数。
你需要注意的另外一件事就是顶点“v0”被3个相邻的面共享:前表面,右表面和上表面。在立即模式中,你必须指定这个共享的顶点6次(每个面需要指定2次)。
glBegin(GL_TRIANGLES); // 使用12个三角形绘制立方体
// front face =================
glVertex3fv(v0); // v0-v1-v2
glVertex3fv(v1);
glVertex3fv(v2);
glVertex3fv(v2); // v2-v3-v0
glVertex3fv(v3);
glVertex3fv(v0);
// right face =================
glVertex3fv(v0); // v0-v3-v4
glVertex3fv(v3);
glVertex3fv(v4);
glVertex3fv(v4); // v4-v5-v0
glVertex3fv(v5);
glVertex3fv(v0);
// top face ===================
glVertex3fv(v0); // v0-v5-v6
glVertex3fv(v5);
glVertex3fv(v6);
glVertex3fv(v6); // v6-v1-v0
glVertex3fv(v1);
glVertex3fv(v0);
... // 绘制另外3个面
glEnd();
使用顶点数组减少了函数调用的次数和共享顶点的冗余使用。因此,你可以提高渲染的性能。现在将解释使用顶点数组的3个不同的OpenGL函数:glDrawArrays(),glDrawElements()和glDrawRangeElements()。虽然更好的方式是使用顶点缓冲区对象(VBO)或显示列表。
初始化
OpenGL提供了glEnableClientState()和glDisableClientState()来激活或禁用6个不同类型的数组,还有6个函来操作这6个数组,因此,OpenGL可以在你的应用程序中访问这6个数组。
glVertexPointer():指向顶点坐标数组
glNormalPointer():指向法向量数组
glColorPointer():指向RGB颜色数组
glIndexPointer():指向索引颜色数组
glTexCoordPointer():指向纹理坐标数组
glEdgeFlagPointer():指向临界标示数组
临界标示数组用来标记顶点是否在边界上。所以唯一一中临界标示为真并且边界可见的情况是glPolygonMode()的值被设置成GL_LINE。
glVertexPointer(GLint size, GLenum type, GLsizei stride, const GLvoid* pointer)
1.size:顶点的维数,2表示2维的点,3表示3维的点。
2.type:GL_FLOAT, GL_SHORT, GL_INT 或 GL_DOUBLE。
3.stride:下一个顶点的偏移量。
4.pointer:指向顶点数组的指针。
glNormalPointer(GLenum type, GLsizei stride, const GLvoid* pointer)
1.type:GL_FLOAT, GL_SHORT, GL_INT 或 GL_DOUBLE。
2.stride:下一个法向量的偏移量。
3.pointer:指向顶点数组的指针。
注意顶点数组位于你的应用程序之中(系统内存),它在客户机这端。位于服务器端的OpenGL访问它们。这是为什么对于顶点数组会有与众不同的访问方式:使用glEnableClientState()和glDisableClientState()而不是使用glEnable()和glDisable()。
glDrawArrays()
glDrawArrays()以连续地无跳跃的方式从顶点数组中读取数据。因为glDrawArrays不允许跳跃地访问顶点数组,你依然需要重复定义顶点。
glDrawArrays()需要三个参数。第一个参数是图元类型,第二个参数是第一个元素在数组中的偏移量,第三个参数是传递给OpenGL渲染的顶点数目。对于上面绘制立方体的例子而言,第一个参数是GL_TRIANGLES,第二个参数是0,表示是从数组中的首个元素开始的,最后一个参数是36:一个立方体有6个面,每个面需要6个顶点来绘制两个三角形,6*6=36。
GLfloat vertices[] = {...}; // 36 个顶点的坐标
...
// 激活顶点数组
glEnableClientState(GL_VERTEX_ARRAY);
glVertexPointer(3, GL_FLOAT, 0, vertices);
// 绘制一个立方体
glDrawArrays(GL_TRIANGLES, 0, 36);
// 绘制完成后禁用顶点数组
glDisableClientState(GL_VERTEX_ARRAY);
通过使用glDrawArrays(),将36次glVertex*()函数调用替换成了一次glDrawArrays()。然而,我们依然需要重复共享顶点,因此顶点数组的大小依然是36而不是8。glDrawElements()函数是减少顶点数组中顶点数目的方法,它能传输更少的数据到OpenGL中。
glDrawElements()
glDrawElements()通过指定相关联的的数组索引在顶点数组中跳跃绘制一系列的图元。它同时减少了函数调用的次数和要传输的顶点数目。除此之外,OpenGL可能缓存最近被处理的顶点并且能重新使用它们而不需要多次将重复的数据发送到OpenGL的渲染管线中。
glDrawElements()需要4个参数。第一个参数指定图元类型,第二个参数指定索引数组的大小,第三个参数指定索引数组的类型,第4个参数指定索引数组。在本文的这个例子中,参数分别是是:GL_TRIANGLES, 36, GL_UNSIGNED_BYTE 和indices。
GLfloat vertices[] = {...}; // 8个顶点坐标
GLubyte indices[] = {0,1,2, 2,3,0, // 索引数组
0,3,4, 4,5,0,
0,5,6, 6,1,0,
1,6,7, 7,2,1,
7,4,3, 3,2,7,
4,7,6, 6,5,4};
...
// 激活顶点数组
glEnableClientState(GL_VERTEX_ARRAY);
glVertexPointer(3, GL_FLOAT, 0, vertices);
// 绘制立方体
glDrawElements(GL_TRIANGLES, 36, GL_UNSIGNED_BYTE, indices);
// 禁用顶点数组
glDisableClientState(GL_VERTEX_ARRAY);
现在顶点数组的大小是8,和立方体中的顶点数目相同。
注意索引数组的类型是GLubyte而不是GLuint或glushort。它应该是能容纳最多顶点数目的占用空间最小的数据类型,否则,由于索引数组的容量将会导致性能下降。由于顶点数组包含8个顶点,GLubyte能容纳所有的索引。
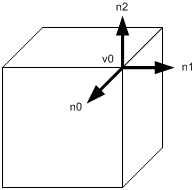
另外一件需要考虑的事情就是共享顶点的法向量。如果共享顶点的法向量在邻接的多边形中不一样,那么法向量需要为每一个面指定一个。
例如,如下图所示,顶点v0被前表面,右表面和上表面共享,但是在v0处的法向量不能被共享。前表面的法向量是n0,右表面的法向量是n1,上表面的法向量是n2。对于这种情况,在共享顶点处的法向量不一样,在顶点数组中的顶点就不能只被定义一次。它必须被定义多次以匹配在法向量数组中的元素个数。一个典型的拥有合适的法向量的立方体需要24个顶点:6个面,每个面4个顶点。
glDrawRangeElements()
和glDrawElements()比较类似,glDrawRangeElements()也可以在数组中跳跃访问。然而,glDrawRangeElements()还有两个额外的参数(开始和结束位置的索引)来指定顶点的范围。通过添加这个范围限制,OpenGL可以只获得访问有限范围的顶点的来优先渲染,这样可能提高性能。
在glDrawRangeElements()中的额外的参数是开始(start)和结束(end)位置的索引,OpenGL预取end-start+1个顶点数据。索引数组中的值必须在start和end之间。注意并不是start和end之间的所有顶点都必须被引用到,但是如果你指定了一个稀疏的范围,那样将会导致为那些不需要使用的顶点进行的没必要的处理。
GLfloat vertices[] = {...}; // 8个顶点坐标
GLubyte indices[] = {0,1,2, 2,3,0, // 前一半 (18 个顶点)
0,3,4, 4,5,0,
0,5,6, 6,1,0,
1,6,7, 7,2,1, // 后一半 (18 个顶点)
7,4,3, 3,2,7,
4,7,6, 6,5,4};
...
// 激活顶点数组
glEnableClientState(GL_VERTEX_ARRAY);
glVertexPointer(3, GL_FLOAT, 0, vertices);
// 绘制前面一半的图形 6 - 0 + 1 = 7 个顶点被使用
glDrawRangeElements(GL_TRIANGLES, 0, 6, 18, GL_UNSIGNED_BYTE, indices);
// 绘制后面一半的图形 7 - 1 + 1 = 7 个顶点被使用
glDrawRangeElements(GL_TRIANGLES, 1, 7, 18, GL_UNSIGNED_BYTE, indices+18);
// 禁用顶点数组
glDisableClientState(GL_VERTEX_ARRAY);
通过使用glGetIntegerv()和GL_MAX_ELEMENTS_VERTICES, GL_MAX_ELEMENTS_INDICES你可以找到能预取的最大的顶点数目和最大的索引数目。
注意glDrawRangeElements()只有在OpenGL 1.2版本或更高版本上才可以使用。
例子
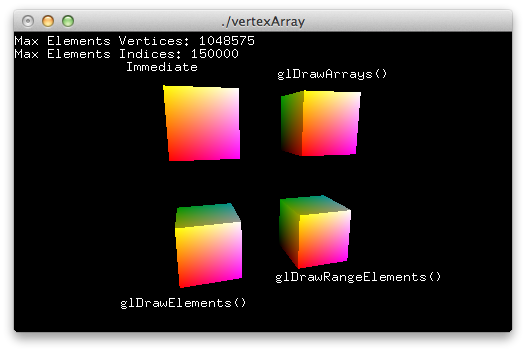
这个例子程序使用4种不同的方式渲染一个立方体:立即模式,glDrawArrays(),glDrawElemennts(),glDrawRangeElements()。
draw1():使用立即模式绘制立方体
draw2():使用glDrawArrays()绘制立方体
draw3():使用glDrawElements()绘制立方体
draw4():使用glDrawRangeElements()绘制立方体
draw5():使用glDrawElements()和交错的顶点数组绘制立方体
OpenGL顶点缓冲区对象(VBO)
GL_ARB_vertex_buffer_object扩展通过提供顶点数组和显示列表的优点并且避免它们的不足提高了OpenGL的性能。顶点缓冲区对象(vertex buffer object,VBO)允许顶点数组存储在位于服务器端的高性能的图形内存中,并且提升了数据传输的效率。如果缓冲区对象用来存储像素数据,那么它叫做像素缓冲区对象(PBO)。
使用顶点数据可以减少函数调用的次数和共享顶点的冗余使用,但是,顶点数组的缺点是顶点数组中的函数位于客户端并且数组中的数据在它每次被引用时都需要发送到服务器端一次。
相反,显示列表位于服务器端,因此它不需要忍受数据传输的开销。但是,当一个显示列表编译后,显示列表里的数据就不能够再修改了。
顶点缓冲区对象(VBO)在服务器端高性能的内存中为顶点属性创造了一个“缓冲区对象”,并且提供了一些函数来引用在顶点数组中使用的数组,如glVertexPointer(),glNormalPointer(),glTexCoordPointer()等。
顶点缓冲区对象(VBO)中的内存管理根据用户定义的"目标(target)"和“用法(usage)”模式,将缓冲区对象放置在内存中最合适的地方。因此,内存管理通过在3中不同的内存(系统内存,AGP,显卡内存)中协调能优化缓冲区。
不像显示列表,通过将缓冲区映射到客户端的内存区域中顶点缓冲区中的数据可以被读取或者更新。
顶点缓冲区对象(VBO)的另外一个优点是缓冲区对象可以被多个客户端共享,像显示列表和纹理。由于顶点缓冲区对象(VBO)位于服务器端,多个客户端使用相关联的标示符可以访问相同的缓冲区。
创建VBO
创建VBO需要3步:
1.使用glGenBuffersARB()生成一个缓冲区对象;
2.使用glBindBufferARB()绑定一个缓冲区对象;
3.使用glBufferDataARB()将顶点数据复制到缓冲区对象中。
glGenBuffersARB()创建一个缓冲区对象并且返回这个缓冲区对象的标示。它需要两个参数:第一个参数指示要创建的缓冲区对象的个数,第二个参数指示存放返回一个或多个缓冲区标示的GLuint类型变量或数组的地址。
void glGenBuffersARB(GLsizei n, GLuint* ids)
glBindBufferARB()当缓冲区对象创建以后,在使用缓冲区对象之前我们需要将缓冲区对象的标示绑定。glBindBufferARB()需要两个参数:target和ID。
void glBindBufferARB(GLenum target, GLuint id)
target是告诉VBO这个缓冲区对象是用来存储顶点数组数据还是用来存储索引数组数据的:GL_ARRAY_BUFFER_ARB或 GL_ELEMENT_ARRAY_BUFFER_ARB 。任何顶点属性,如顶点坐标,纹理坐标,法向量,和颜色信息需要使用GL_ARRAY_BUFFER_ARB作为target。而像glDraw[Range]Elements()函数使用的索引数组则需要与GL_ELEMENT_ARRAY_BUFFER_ARB绑定。注意这个target标示帮助VBO决定顶点缓冲区的最佳位置,例如,有些系统将会将索引数组放置在AGP或系统内存中,而将顶点数组放置在显卡内存中。
当glBindBufferARB()被首次调用的时候,VBO使用大小为0的内存区初始化这个缓冲区并且设置了这个VBO的初始状态,例如usage和访问属性。
glBufferDataARB()当缓冲区初始化以后你可以使用glBufferDataARB()将数组复制到缓冲区对象中。
void glBufferDataARB(GLenum target, GLsizei size, const void* data, GLenum usage)
第一个参数target可能是GL_ARRAY_BUFFER_ARB或GL_ELEMENT_ARRAY_BUFFER_ARB。size是将要传输的数据的字节数。第3个参数是指向数据源的指针,如果这个指针是NULL,那么VBO将会只保留指定大小的存储空间。最后一个参数usage是另一个VBO中的性能参数,指示这个缓冲区会被怎么使用,static(静态的),dynamic(动态的),stream(流),read(读),copy(复制),draw(绘制)。
VBO为usage标示指定了9中枚举的值:
GL_STATIC_DRAW_ARB
GL_STATIC_READ_ARB
GL_STATIC_COPY_ARB
GL_DYNAMIC_DRAW_ARB
GL_DYNAMIC_READ_ARB
GL_DYNAMIC_COPY_ARB
GL_STREAM_DRAW_ARB
GL_STREAM_READ_ARB
GL_STREAM_COPY_ARB
“static”意味着VBO中的数据不能被改变(指定一次使用多次),“dynamic”意味着数据将会频繁地改变(指定多次使用多次),“stream”意味着数据在每一帧中都会被改变(指定一次使用一次)。“draw”意味着数据被传输至GPU渲染(从应用程序到OpenGL),“read”意味着数据被客户端的应用程序所读取(从OpenGL到应用程序),“copy”意味着既可以用来“draw”也可以用来“read”。
注意只有"draw"标示可以被VBO使用,“copy”和“read”标示对像素缓冲区对象(PBO)和帧缓冲区对象(FBO)才有意义。
VBO内存管理会根据usage的值为缓冲区对象选择最合适的内存位置,例如,GL_STATIC_DRAW_ARB 和GL_STREAM_DRAW_ARB将会选择显卡内存,GL_DYNAMIC_DRAW_ARB将会选择AGP内存。任何与_READ_相关的缓冲区既可以使用系统内存也可以是用AGP内存,因为数据应该很容易被访问到。
glBufferSubDataARB()和glBufferDataARB()比较类似,glBufferSubDataARB()用来将数据复制到VBO中,但是它只将部分数据复制到已经存在的缓冲区中,从给定的偏移量开始。(缓冲区的总大小必须在使用glBufferSubDataARB()之前使用glBufferDataARB()设置)
void glBufferSubDataARB(GLenum target, GLint offset, GLsizei size, void* data)
glDeleteBuffersARB()。你可以使用glDeleteBuffersARB()函数来删除一个或多个不再使用的VBO。缓冲区对象被删除掉后,它的内容会丢失掉。
void glDeleteBuffersARB(GLsizei n, const GLuint* ids)
下面的代码是一个为顶点坐标创建一个简单的顶点缓冲区对象(VBO)的例子。注意当你把所有的数据复制到VBO中之后你可以删除在你的应用程序中为顶点数组分配的内存。
GLuint vboId; // VBO的ID
GLfloat* vertices = new GLfloat[vCount*3]; // 创建顶点数组
...
// 生成一个新的顶点缓冲区对象并得到相关联的ID
glGenBuffersARB(1, &vboId);
// 绑定顶点缓冲区对象
glBindBufferARB(GL_ARRAY_BUFFER_ARB, vboId);
// 将数据复制到顶点缓冲区对象中
glBufferDataARB(GL_ARRAY_BUFFER_ARB, dataSize, vertices, GL_STATIC_DRAW_ARB);
// 将数据复制到顶点缓冲区对象中后就可以删除顶点数组了
delete [] vertices;
...
// 程序终止时删除顶点缓冲区对象
glDeleteBuffersARB(1, &vboId);
绘制VBO
因为VBO是基于顶点数组实现的,渲染VBO和使用顶点数组比较类似。唯一的不同点是指向顶点数据的指针现在变成了指向现在绑定的缓冲区对象的偏移量。因此,除了glBindBufferARB()之外绘制VBO不需要额外的API。
// 为顶点数组和索引数组绑定VBO
glBindBufferARB(GL_ARRAY_BUFFER_ARB, vboId1); // 为顶点数组
glBindBufferARB(GL_ELEMENT_ARRAY_BUFFER_ARB, vboId2); // 为索引数组
// 除了指针不同外其他和顶点数组操作一样
glEnableClientState(GL_VERTEX_ARRAY); // 激活顶点数组
glVertexPointer(3, GL_FLOAT, 0, 0); // 最后一个参数是偏移
// 使用索引数组的偏移值绘制6个面
glDrawElements(GL_QUADS, 24, GL_UNSIGNED_BYTE, 0);
glDisableClientState(GL_VERTEX_ARRAY); // 禁用顶点数组
// 绑定0,这样将返回到正常的指针操作
glBindBufferARB(GL_ARRAY_BUFFER_ARB, 0);
glBindBufferARB(GL_ELEMENT_ARRAY_BUFFER_ARB, 0);
最后一行将缓冲区对象绑定到0将关闭VBO操作。这是一个使用VBO之外关闭VBO的好方法,这样正常的顶点数组操作将会被再次激活。
更新VBO
VBO相比于显示列表的优点是客户端可以读取和更改缓冲区对象中的数据,而显示列表不能。最简单的更新VBO中的数据的方法是使用glBufferDataARB()或glBufferSubDataARB()函数将数据一遍又一遍地复制到你所绑定的VBO中。对这种情况,你的应用程序需要一直有一个有效的顶点数组。这意味着你需要有顶点数组的两份拷贝:一份位于你的应用程序中,另一份位于VBO中。
另一个修改缓冲区对象的方式是将缓冲区对象映射到客户端内存中,然后客户端可以使用指向映射到缓冲区的指针更新数据。下面显示了如何将一个VBO映射到客户端内存中并怎样访问被映射的数据。
VBO使用glMapBufferARB()来将缓冲区对象映射到客户端内存中。
void* glMapBufferARB(GLenum target, GLenum access)
如果OpenGL能将缓冲区映射到客户端的内存中,glMapBufferARB()将返回指向缓冲区的指针,否则返回NULL。
第一个参数,target和上面的glBindBufferARB()一样,第二个参数access指定了对那些映射的数据的操作:读,写或者读写都可以。
GL_READ_ONLY_ARB
GL_WRITE_ONLY_ARB
GL_READ_WRITE_ARB
注意glMapBufferARB()将会导致一个同步的问题。如果GPU依然在顶点缓冲区中工作,那么glMapBufferARB()函数将会在GPU结束在指定的缓冲区的工作之后才返回。
为了避免等待,你可以首先使用一个空指针调用glBufferDataARB()函数,然后调用glMapBufferARB()。在这种情况下,之前的数据将会被舍弃,glMapBufferARB()将立即返回一个新分配区域的指针,即使GPU依然在之前的数据上工作。
然而,这种方法只有在你需要更新整个数据集的时候才有效,因为这样将会舍弃之前的数据。如果你只是希望改变部分数据或者只是希望读取数据,你最好不要舍弃之前的数据。
glUnmapBufferARB()修改完VBO的数据之后,必须解除掉缓冲区对象和客户端内存的映射。glUnmapBufferARB()成功时会返回GL_TRUE。当它返回GL_FALSE时VBO的内容会被破坏。破坏的原因是窗口分辨率的改变或者系统时间发生了。在这种情况下,数据需要被再次提交。
GLboolean glUnmapBufferARB(GLenum target)
下面是一个使用映射的方法修改VBO的例子:
// 绑定并映射VBO
glBindBufferARB(GL_ARRAY_BUFFER_ARB, vboId);
float* ptr = (float*)glMapBufferARB(GL_ARRAY_BUFFER_ARB, GL_WRITE_ONLY_ARB);
// 如果映射成功,则更新VBO
if(ptr)
{
updateMyVBO(ptr, ...); // 修改缓冲区数据
glUnmapBufferARB(GL_ARRAY_BUFFER_ARB); // 解除映射
}
// 使用新的VBO绘图
...
OpenGL像素缓冲区对象(PBO)
OpenGL中的ARB_pixel_buffer_object扩展和ARB_vertex_buffer_object扩展非常类似。这样非常简单地扩充ARB_vertex_buffer_object是为了不仅能在缓冲区对象中存储顶点数据也能存储像素数据。这个存储像素数据的缓冲区对象叫做像素缓冲区(PBO)。ARB_pixel_buffer_object扩展借用了所有VBO的框架和API,并且添加了两个额外的"target"值。这个“target”值方便PBO的内存管理机制决定缓冲区对象在内存中的最佳位置,是将缓冲区对象放置在系统内存中,还是共享内存中,还是显卡内存中。这个“target”值也清晰地指明了PBO的使用范围:GL_PIXEL_PACK_BUFFER_ARB表示将像素数据“传入”到PBO,GL_PIXEL_UNPACK_BUFFER_ARB表示数据从PBO中“传出”。
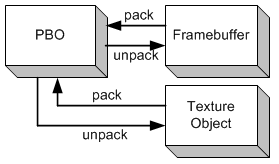
例如,glReadPixels()和glGetTexImage()是“传入”操作,glDrawPixels(),glTexImage2D()和glTexSubImage2D()是“传出”操作。当一个PBO使用GL_PIXEL_PACK_BUFFER_ARB 显示使用范围时,glReadPixels()从OpenGL的帧缓冲区中读取像素并将数据写入(”传入“)PBO中。当一个PBO使用GL_PIXEL_UNPACK_BUFFER_ARB 显示使用范围时,glDrawPixels()从PBO中读取(”传出“)数据并将它们复制到OpenGL中的帧缓冲区中。
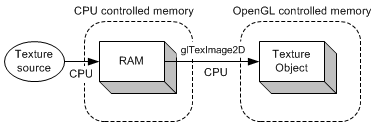
PBO最大的优点是使用DMA(Direct Memory Access,直接内存访问)的方式快速地将数据传入到显卡或从显卡传出,它不需要等待CPU的周期。PBO的另外一个优点是可以使用异步地DMA方式传输数据。让我们来比较一下传统的纹理传输的方式和使用PBO的区别。如下图所示,第一幅图显示传统的方式从数据源(图片文件或视频流)中加载纹理数据。数据源首先被加载到系统内存中,然后使用glTexImage2D()冲系统内存中复制到OpenGL中的纹理对象中。这两个步骤(加载和复制)都是在CPU中进行的。
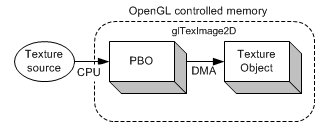
第二幅图片则正好相反,数据源能直接被加载到PBO中,而PBO是被OpenGL控制的。CPU也参与了加载数据源到PBO,但是不会将PBO中的纹理数据传输到纹理对象中。反而由GPU(OpenGL驱动器)管理将数据从PBO复制到纹理对象中。这意味着OpenGL进行了DMA方式的传输操作而不需要等待CPU的周期。除此之外,OpenGL甚至还可以使用异步地传输方式。因此glTexImage2D()会立即返回,CPU可以执行其他的事情而不需要等待像素数据传输完。
有两种主要的使用PBO提高传输像素数据的方式:上传到纹理和从帧缓冲区中进行异步回读。
创建PBO
像之间提到过的那样,像素缓冲区对象(PBO)借用了顶点缓冲区对象(VBO)中的所有API。唯一的区别是为”target“表示增加了两个值:GL_PIXEL_PACK_BUFFER_ARB和GL_PIXEL_UNPACK_BUFFER_ARB。GL_PIXEL_PACK_BUFFER_ARB用来表示将数据从OpenGL中传输到你的应用程序中,GL_PIXEL_UNPACK_BUFFER_ARB表示将数据从应用程序中传输到OpenGL中。OpenGL使用这些标示来决定将PBO放置在最合适的地方,例如,显卡内存用来上传(unpack)纹理,系统内存用来冲帧缓冲区中读取(pack)数据。然而,这些标记都是单独使用的,OpenGL驱动将会为你指定合适的位置。
创建PBO需要3步:
1.使用glGenBuffersARB()创建一个缓冲区对象
2.使用glBindBufferARB()绑定一个缓冲区对象
3.使用glBufferDataARB()将像素数据复制到缓冲区对象中
如果在glBufferDataARB()中为数据源数组传入了NULL,那么PBO只会分配一个指定大小的空间。glBufferDataARB()函数的最后一个参数是另个用来指定PBO如何使用的性能指标,GL_STREAM_DRAW_ARB表示通过流的方式上传纹理,GL_STREAM_READ_ARB表示异步地从帧缓冲区中进行回读。
映射PBO
PBO提供了内存映射的机制来将OpenGL中的缓冲区对象映射到客户端的内存区域中。因此客户端可以通过使用glMapBufferARB()和glUnmapBufferARB()修改缓冲中的部分内容或者整个缓冲区。
void* glMapBufferARB(GLenum target, GLenum access)
GLboolean glUnmapBufferARB(GLenum target)
glMapBufferARB()如果成功将会返回一个指向缓冲区对象的指针,否则将会返回NULL。target参数是GL_PIXEL_PACK_BUFFER_ARB 或者 GL_PIXEL_UNPACK_BUFFER_ARB。第二个参数,access指定了对映射来的缓冲区的操作方式:从PBO中读取数据(GL_READ_ONLY_ARB),将数据写入到PBO(GL_WRITE_ONLY_ARB)中,或者两个都可以(GL_READ_WRITE_ARB)。
注意如果GPU仍然工作在一个缓冲区对象上,glMapBufferARB()将会在GPU在指定的缓冲区对象中工作完成之后才返回。为了避免等待,你可以首先使用一个空指针调用glBufferDataARB()函数,然后调用glMapBufferARB()。这样OpenGL将会废除旧的缓冲区,并为缓冲区对象分配新的空间。
缓冲区对象使用完后必须使用glUnmapBufferARB()解除映射,glUnmapBufferARB()成功时返回gl_TRUE,否则返回GL_FALSE。
例子:使用PBO上传到纹理
在PBO模式中纹理源每帧都被直接写入到映射的像素缓冲区中。然后这些数据使用glTexSubImage2D()从PBO中传输到纹理对象中。通过使用PBO,OpenGL能在PBO和纹理对象中使用异步的DMA方式传输数据。它非常有效地提高了纹理传输的性能。如果异步的DMA方式被支持,glTexSubImage2D()会被立即返回,CPU不需要等待实际的纹理复制到PBO完成就可以继续做其他工作了。
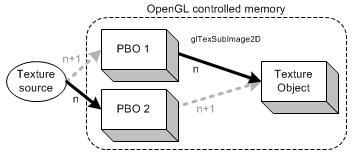
为了最大化地提示传输的性能,你可以使用两个像素缓冲区对象。上图显示了2个PBO同时被使用的情况;glTexSubImage2D()将像素数据从PBO中复制到纹理对象中时纹理源正好被写入到另一个PBO。 对第n帧而言,PBO1在执行glTexSubImage2D()操作,PBO2则在读取纹理。那么在第n+1帧时,2个PBO交换操作并且继续更新纹理。因为异步地DMA方式传输,更新和复制操作可以同时进行。CPU更新纹理源时GPU会从PBO会从PBO中复制数据。
// "index" 被用来从PBO中复制像素到纹理对象中
// "nextIndex" 被用来在另一个PBO中更新像素
index = (index + 1) % 2;
nextIndex = (index + 1) % 2;
// 绑定纹理和PBO
glBindTexture(GL_TEXTURE_2D, textureId);
glBindBufferARB(GL_PIXEL_UNPACK_BUFFER_ARB, pboIds[index]);
// 从PBO中复制像素到到纹理对象中
// 使用偏移量而不是指针
glTexSubImage2D(GL_TEXTURE_2D, 0, 0, 0, WIDTH, HEIGHT,
GL_BGRA, GL_UNSIGNED_BYTE, 0);
// 绑定PBO来更新纹理源
glBindBufferARB(GL_PIXEL_UNPACK_BUFFER_ARB, pboIds[nextIndex]);
//注意glMapBufferARB()将会导致一个同步的问题。
//如果GPU依然在顶点缓冲区中工作,那么glMapBufferARB()函数
//将会在GPU结束在指定的缓冲区的工作之后才返回。
//为了避免等待,你可以首先使用一个空指针调用glBufferDataARB()函数,
//然后调用glMapBufferARB()。在这种情况下,之前的数据将会被舍弃,
//glMapBufferARB()将立即返回一个新分配区域的指针,
//即使GPU依然在之前的数据上工作。
glBufferDataARB(GL_PIXEL_UNPACK_BUFFER_ARB, DATA_SIZE, 0, GL_STREAM_DRAW_ARB);
// 将缓冲区对象映射到客户端内存中
GLubyte* ptr = (GLubyte*)glMapBufferARB(GL_PIXEL_UNPACK_BUFFER_ARB,
GL_WRITE_ONLY_ARB);
if(ptr)
{
// 在映射的缓冲区中直接更新数据
updatePixels(ptr, DATA_SIZE);
glUnmapBufferARB(GL_PIXEL_UNPACK_BUFFER_ARB); // 释放映射的缓冲区
}
// PBO使用完后使用将它绑定到0是一种释放PBO的很好的方法
// 当被绑定到0后, all pixel operations are back to normal ways.所有的像素操作变成了正常的方式
glBindBufferARB(GL_PIXEL_UNPACK_BUFFER_ARB, 0);
例子:使用PBO进行异步地回读
传统的glReadPixels()函数会阻塞渲染管线,它会一直等待直到所有的像素数据传输完成。然后才会将控制权交给应用程序。相反,使用PBO时glReadPixel()使用异步地DMA方式传输并且能立即返回。因此,应用程序(CPU)可以立即执行其他程序,这时数据会被OPenGL(GPU)使用DMA的方式传输。
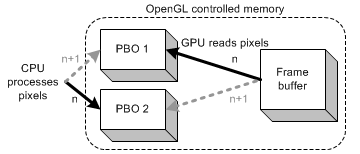
这个例子使用两个像素缓冲区。在第n帧,应用程序使用glReadPixels()从OpenGL帧缓冲区中读取数据到PBO1中,并处理PBO2中的像素数据。这个读取和处理的过程可以同时进行,因此glReadPixels()函数会立即返回这样CPU开始处理PBO2中的数据。我们会在每一帧中交替PBO1和PBO2.
// "index" 用来表示将数据从帧缓冲区中读入PBO中
// "nextIndex" 更新另一个PBO的像素
index = (index + 1) % 2;
nextIndex = (index + 1) % 2;
// 设置帧缓冲区可读
glReadBuffer(GL_FRONT);
// 从帧缓冲区中读取数据到PBO中
// glReadPixels() 会立即返回.
glBindBufferARB(GL_PIXEL_PACK_BUFFER_ARB, pboIds[index]);
glReadPixels(0, 0, WIDTH, HEIGHT, GL_BGRA, GL_UNSIGNED_BYTE, 0);
// 映射数据到PBO
glBindBufferARB(GL_PIXEL_PACK_BUFFER_ARB, pboIds[nextIndex]);
GLubyte* ptr = (GLubyte*)glMapBufferARB(GL_PIXEL_PACK_BUFFER_ARB,
GL_READ_ONLY_ARB);
if(ptr)
{
processPixels(ptr, ...);
glUnmapBufferARB(GL_PIXEL_PACK_BUFFER_ARB);
}
// 返回正常的像素操作中
glBindBufferARB(GL_PIXEL_PACK_BUFFER_ARB, 0);
OpenGL帧缓冲区对象(FBO)
在OpenGL渲染管线中,几何数据和纹理经过了几次变换和测试最终作为二维像素被渲染到屏幕中。OpenGL渲染管线中的目的地是帧缓冲区。帧缓冲区是被OpenGL使用的二维数组的集合,包括颜色缓冲区,深度缓冲区,模板缓冲区和累积缓冲区。默认情况下OpenGL使用完全被窗口创建和管理的帧缓冲区作为渲染的目的地。默认的帧缓冲区被叫做”窗口系统提供的“帧缓冲区。
OpenGL的扩展,GL_ARB_framebuffer_object提供了接口用来创建不渲染的帧缓冲区对象(FBO)。为了和”窗口系统提供的“帧缓冲区相区分开来这个帧缓冲区叫做”应用程序创建的“帧缓冲区。通过使用帧缓冲区对象(FBO),一个应用程序可以重定向渲染结果到”应用程序创建的“帧缓冲区对象(FBO)而不是传统的”窗口系统提供的“帧缓冲区中。这个过程是完全被OpenGL控制的。
和”窗口系统提供的“帧缓冲区类似,一个FBO也包含颜色缓冲区,深度缓冲区,模板缓冲区。(注意FBO中没有累积缓冲区)。FBO中的这些逻辑上的缓冲区被叫做“附加到帧缓冲区中镜像“(framebuffer-attachable images),这些二维的像素数据可以被附加到帧缓冲区对象中。
有两种“附加到帧缓冲区中”镜像:纹理镜像和渲染缓冲区镜像。如果一个纹理对象的镜像被附加到帧缓冲区,OpenGL执行”渲染到纹理“的操作。如果一个渲染缓冲区对象的镜像被附加到帧缓冲区中,那么OpenGL执行”离屏渲染“。
顺便说一下,渲染缓冲区对象是在GL_ARB_framebuffer_object扩展中定义的一种新的存储对象类型。它被用来作为在渲染过程中简单二维图片的渲染目的地。
下面这幅图显示了帧缓冲区对象(FBO),纹理对象(Texture Object),渲染缓冲区对象(Renderbuffer Object)之间的连接关系。多个纹理对象和渲染缓冲区对象可以通过附加点被附加到帧缓冲区对象中。
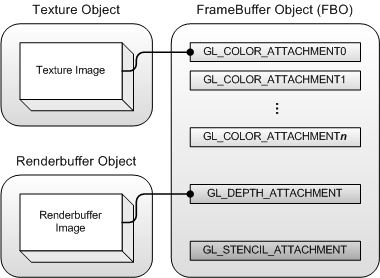
一个FBO中有多个颜色附加点(GL_COLOR_ATTACHMENT0,..., GL_COLOR_ATTACHMENTn),一个深度附加点(GL_DEPTH_ATTACHMENT),一个模板附加点(DL_STENCIL_ATTACHMENT)。颜色附加点的数目是依赖于显卡的,但是每个FBO对象中至少含有一个颜色附加点。你可以使用GL_MAX_COLOR_ATTACHMENTS查询显卡支持的颜色顶点的最大数。一个FBO中有多个颜色附加点的原因是为了同时将颜色缓冲区渲染到多个目的地。GL_ARB_draw_buffers扩展实现了”多个渲染目标(mutiple render targets ,MRT)“的功能。注意帧缓冲区对象自身并不包含存储数据的二维数组,但是它有多个附加点。
帧缓冲区对象(FBO)提供了一种高效的切换机制:从帧缓冲区对象中分离之前附加的对象,或者附加一个新对象到帧缓冲区对象中。切换帧缓冲区对象中的附加对象比切换FBO快很多。FBO提供了glFramebufferTexture2D()来切换纹理对象,提供glFramebufferRenderbuffer()来切换渲染缓冲区对象。
创建FBO
创建帧缓冲区对象(FBO)和创建顶点缓冲区对象(VBO)类似。
void glGenFramebuffers(GLsizei n, GLuint* ids)
void glDeleteFramebuffers(GLsizei n, const GLuint* ids)
glGenFramebuffers()需要两个参数:第一个参数标示要创建的帧缓冲区的数目,第二个参数表示存放生成的帧缓冲区ID的GLuint类型的变量或数组的地址。它返回为使用的帧缓冲区对象的ID。ID为0标示默认的帧缓冲区,就是”窗口系统提供的“帧缓冲区。
当FBO不再使用的时候可以使用glDeleteFramebuffers()来删除它。
当FBO创建以后,在使用它之前需要先绑定它。
void glBindFramebuffer(GLenum target, GLuint id)
第一个参数target需要是GL_FRAMEBUFFER,第二个参数是帧缓冲区对象的ID。当一个FBO绑定以后,所有的OpenGL操作将会作用在这个绑定的帧缓冲区对象上。ID为0的帧缓冲区对象是”窗口系统提供的“帧缓冲区。因此为了解除当前正在使用的帧缓冲区(FBO),使用glBindFramebuffer()绑定到0。
渲染缓冲区对象
渲染缓冲区对象(renderbuffer object)是在离屏渲染(offscreen rendering)中新介绍到的。它允许将一个场景直接渲染到渲染缓冲区对象而不是纹理对象中。缓冲缓冲区对象是一个包含可渲染的内部格式镜像的数据存储区。它被用来存储OpenGL中没有相关联的的纹理格式的逻辑缓冲区,如模板缓冲区和深度缓冲区。
void glGenRenderbuffers(GLsizei n, GLuint* ids)
void glDeleteRenderbuffers(GLsizei n, const Gluint* ids)
当一个渲染缓冲区创建以后,它会返回一个非零的正数。0为OpenGL保存。
void glRenderbufferStorage(GLenum target,
GLenum internalFormat,
GLsizei width,
GLsizei height)
当一个渲染缓冲区对象被创建以后,它不包含任何的数据存储区,因此我们必须为它分配空间。这可以使用glRenderbufferStorage()来实现。第一个参数必须是GL_RENDERBUFFER。第二个参数可以是渲染颜色(GL_RGB,GL_RGBA,等),渲染深度(GL_DEPTH_COMPONENT),或者渲染模板格式(GL_STENCIL_INDEX)。width和height是渲染缓冲区镜像的尺寸(以像素为单位)。
width和height的值应该小于GL_MAX_RENDERBUFFER_SIZE的值,否则会产生一个GL_INVALID_VALUE的错误。
void glGetRenderbufferParameteriv(GLenum target,
GLenum param,
GLint* value)
你也可以得到现在正在使用的渲染缓冲区的参数。target必须是GL_RENDERBUFFER,第二个参数是是要获得的参数的名字,最后一个参数是指向存储返回的整型变量的指针。可使用的渲染缓冲区的参数的名字的名字如下:
GL_RENDERBUFFER_WIDTH
GL_RENDERBUFFER_HEIGHT
GL_RENDERBUFFER_INTERNAL_FORMAT
GL_RENDERBUFFER_RED_SIZE
GL_RENDERBUFFER_GREEN_SIZE
GL_RENDERBUFFER_BLUE_SIZE
GL_RENDERBUFFER_ALPHA_SIZE
GL_RENDERBUFFER_DEPTH_SIZE
GL_RENDERBUFFER_STENCIL_SIZE
附加镜像到FBO
FBO自身并没有缓冲区,而是由我们将”可以附加到帧缓冲区“的镜像(framebuffer-attachable iamges,纹理对象或渲染缓冲区对象)附加到FBO中。这种机制允许FBO快速切换(detach and attach,分离和附加)在FBO中的”可以附加到帧缓冲区“的镜像。切换这种绑定的镜像比在FBO中更加快速。并且,减少了没必要的数据拷贝和内存消耗。例如,一个纹理对象可以附加到多个帧缓冲区对象中,它的缓冲区可以被多个FBO共享。
附加二维纹理镜像到FOB中
glFramebufferTexture2D(GLenum target,
GLenum attachmentPoint,
GLenum textureTarget,
GLuint textureId,
GLint level)
glFramebufferTexture2D()将一个二维纹理镜像附加到FBO中。第一个参数必须是GL_FRAMEBUFFER。第二个参数是连接纹理镜像的附加点,一个FBO中有多个颜色附加点(GL_COLOR_ATTACHMENT0, ...,GL_COLOR_ATTACHMENTn),一个深度附加点(GL_DEPTH_ATTACHMENT),和一个模板附加点(GL_STENCIL_ATTACHMENT)。第三个参数,"texture Target"大多数情况下为GL_TEXTURE_2D。第四个参数是纹理对象的标示符。最后一个参数附加纹理的映射级别。
如果textureId的值为0,那么纹理镜像会从PBO中分离。如果一个纹理对象在它还附加到FBO中时被删除了,那么这个纹理对象会自动从当前绑定的FBO中分离。然而,如果它被附加到多个FBO并且被删除了,那么将只会从当前被绑定的FBO中删除,而不会从未绑定的FBO中删除。
附加渲染缓冲区镜像到FBO中
void glFramebufferRenderbuffer(GLenum target,
GLenum attachmentPoint,
GLenum renderbufferTarget,
GLuint renderbufferId)
可以使用glFramebufferRenderbuffer()将一个渲染缓冲区镜像附加到FBO中。第一个参数和第二个参数和glFramebufferTexture2D()一样。第三个参数必须是GL_RENDERBUFFER。最后一个参数是渲染缓冲区对象的标示。
如果renderbufferId参数被设置成0,那么渲染缓冲区对象将会从FBO中的附加点分离。如果一个渲染缓冲被附加到FBO时被删除了,它会自动从当前被绑定的FBO中分离开来。然而,它不会从其他未被绑定的FBO中分离出来。
检查FBO的状态
当一个可附加的镜像(纹理对象或渲染缓冲区对象)被附加到FBO中以后并且在FBO执行操作之前,你必须使用glCheckFramebufferStatus()来检查FBO的状态是否完整。如果FBO不是完整的,那么任何绘制或读取的命令(glBegin,glCopyTexImage2D()等)都会失败。
GLenum glCheckFramebufferStatus(GLenum target)
glCheckFramebufferStatus()检查附加到当前被绑定的FBO的镜像和帧缓冲的参数。并且这个函数不能在glBegin()和glEnd()之间。target参数必须是GL_FRAMEBUFFER。检查完FBO后会返回一个非零的值。如果所有的条件和规则都满足,会返回GL_FRAMEBUFFER_COMPLETE。否则,它返回一个有关的错误值,这个错误值会告诉违反了那条规则。
FBO中完整的规则如下:
附加到帧缓冲区镜像的width和height必须是非零的。
如果一个镜像被附加到颜色附加点,那么这个镜像必须有一个可渲染颜色(color-renderable)的内部格式。(GL_RGBA,GL_DEPTH_COMPONENT,GL_LUMINANCE等)
如果一个镜像被附加到GL_DEPTH_ATTACHMENT,那么这个镜像必须有可渲染深度(depth-renderable)的内部格式。(GL_DEPTH_COMONENT,GL_DEPTH_COPONENT24等)
如果一个镜像被附加到GL_STENCIL_ATTACHMENT,那么这个镜像必须有可渲染模板(stencil-renderable)的内部格式。(GL_STENCIL_INDEX,GL_STENCIL_INDEX8等)
FBO必须至少有一个附加的镜像。
所有附加到FBO的镜像必须有相同的宽体和高度。
所有附加到颜色附加点的镜像必须有相同的内部格式。
注意即使上面所有的条件都满足,你的OpenGL驱动(GPU)可能不支持某些内部的格式或参数。如果某个特殊的实现不被OpenGL驱动支持,那么glCheckFramebufferStatus()会返回GL_FRAMEBUFFER_UNSUPPORTED。
例子:渲染到纹理
有时,你需要生成动态的纹理。最普遍的例子是生成镜像/反射的效果,动态的立方体/环境映射和阴影映射。动态的纹理可以使用渲染场景到纹理中来生成。一个传统的渲染到纹理的方法是按照正常的步骤绘制一个场景到帧缓冲区中,然后使用glCopyTexSubImage2D()将帧缓冲区中的镜像复制到纹理中。
使用FBO,我们可以直接将一个场景渲染到纹理中,因此我们完全不需要使用”窗口系统提供的“帧缓冲区。除此之外,我们还可以减少额外的数据复制(从帧缓冲区到纹理)。
除了性能方面的区别外,FBO还有另外一个优点,在传统的渲染到纹理的模式中如果纹理的分辨率比渲染窗口大,那么纹理中窗口区域之外的部分会被裁剪掉,然后使用FBO不会产生这种裁剪的问题。你可以创建一个比显示窗口大的可渲染的帧缓冲区镜像。
下面的代码在渲染操作开始之前设置了一个FBO和附加到帧缓冲区的镜像。注意不仅纹理镜像可以附加到FBO中,渲染缓冲区镜像(深度缓冲,模板缓冲)也可以被附加到FBO。我们不会实际使用深度缓冲,然而FBO需要它进行深度测试。如果我们不将深度缓冲附加到FBO中,那么渲染输出的结果会被破坏因为缺少了深度测试。如果在FBO渲染时需要模板测试,那么额外的模板缓冲需要附加到GL_STENCIL_ATTACHMENT附加点。
...
// 创建一个纹理对象
GLuint textureId;
glGenTextures(1, &textureId);
glBindTexture(GL_TEXTURE_2D, textureId);
glTexParameterf(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexParameterf(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR);
glTexParameterf(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameterf(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_GENERATE_MIPMAP, GL_TRUE); // 自动贴图
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA8, TEXTURE_WIDTH, TEXTURE_HEIGHT, 0,
GL_RGBA, GL_UNSIGNED_BYTE, 0);
glBindTexture(GL_TEXTURE_2D, 0);
// 创建一个渲染缓冲区对象来存储深度信息
GLuint rboId;
glGenRenderbuffers(1, &rboId);
glBindRenderbuffer(GL_RENDERBUFFER, rboId);
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH_COMPONENT,
TEXTURE_WIDTH, TEXTURE_HEIGHT);
glBindRenderbuffer(GL_RENDERBUFFER, 0);
// 创建一个帧缓冲区对象
GLuint fboId;
glGenFramebuffers(1, &fboId);
glBindFramebuffer(GL_FRAMEBUFFER, fboId);
// 将纹理对象附加到FBO的颜色附加点上
glFramebufferTexture2D(GL_FRAMEBUFFER, // 1. fbo target: GL_FRAMEBUFFER
GL_COLOR_ATTACHMENT0, // 2. attachment point
GL_TEXTURE_2D, // 3. tex target: GL_TEXTURE_2D
textureId, // 4. tex ID
0); // 5. mipmap level: 0(base)
// 将渲染缓冲区对象附加到FBO的深度附加点上
glFramebufferRenderbuffer(GL_FRAMEBUFFER, // 1. fbo target: GL_FRAMEBUFFER
GL_DEPTH_ATTACHMENT, // 2. attachment point
GL_RENDERBUFFER, // 3. rbo target: GL_RENDERBUFFER
rboId); // 4. rbo ID
// 检查FBO的状态
GLenum status = glCheckFramebufferStatus(GL_FRAMEBUFFER);
if(status != GL_FRAMEBUFFER_COMPLETE)
fboUsed = false;
// 切换到窗口系统提供的帧缓冲区中
glBindFramebuffer(GL_FRAMEBUFFER, 0);
...
渲染到纹理的过程和普通的绘制过程基本一样。我们只需要将渲染的目的地由”窗口系统提供的“帧缓冲区改变成"应用程序创建的"帧缓冲区(FBO)中。
...
// 设置FBO为渲染的目的地
glBindFramebuffer(GL_FRAMEBUFFER, fboId);
// 清除缓冲区
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
// 直接绘制一个场景到纹理中
draw();
// 解除FBO的绑定
glBindFramebuffer(GL_FRAMEBUFFER, 0);
// 贴图生成
// 注意:如果GL_GENERATE_MIPMAP被设置成 GL_TRUE, 那么glCopyTexSubImage2D()
//会自动生成贴图. 然而, 附加到FBO的纹理需要使用glGenerateMipmap()来生成贴图
glBindTexture(GL_TEXTURE_2D, textureId);
glGenerateMipmap(GL_TEXTURE_2D);
glBindTexture(GL_TEXTURE_2D, 0);
...
注意为了在修改纹理镜像的基础级别后显示地生成贴图glGenerateMipmap()也被当做FBO的扩展。如果GL_GENERATE_MIPMAP被设置为GL_TRUE,那么glTex{Sub}Image2D()和glCopyTex{Sub}Image2D()会自动触发生成贴图(在OpenGL 1.4版本或更高的版本中)。然而,FBO当它的基础纹理被更改后不会自动生成它的贴图这是因为FBO不会调用glCopyTex{Sub}Image2D()来修改纹理。因此,glGenerateMipmap()必须被显示地调用。
如果你需要快速地出来纹理,可以联合像素缓冲区对象(PBO)一起修改纹理。
OpenGL网格化
网格化是将凹多边形或有边相交的多边形划分成凸多边形。由于openGL渲染时只接受凸多边形,这些非凸多边形在渲染之前必须先被网格化。
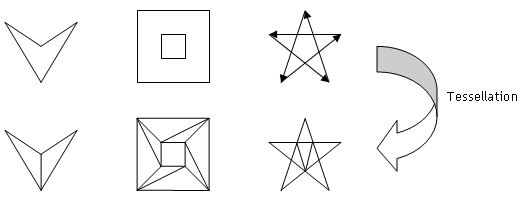
第一行中第一个图形是4条边的凹多边形,第二个图形中间有个洞,第三个图形有相交的边.
网格化基本的步骤是将所有非凸多边形的顶点坐标发送到网格器而不是直接发送到OpenGL渲染管线中,然后网格器将所有多边形网格化。最后,网格化工作完成以后,网格器使用用户定义的回调模式调用实际的OpenGL命令来渲染网格化后的多边形。
OpenGL提供了一系列的将凹多边形处理成凸多边形的模式。
GLUtessellator* gluNewTess()
void gluDeleteTess(GLUtessellator *tess)
gluNewTess()创建一个网格器对象,gluDeleteTess()删除指定的网格器对象。如果创建失败,将会返回NULL。
void gluTessBeginPolygon(GLUtessellator *tess, void *userData)
void gluTessEndPolygon(GLUtessellator *tess)
不像之前使用glBegin()和glEnd()块来描述多边形的顶点,你需要使用特殊的网格器块,gluTessBeginPolygon()和gluTessEndPolygon().你必须在这个块中描述非凸多边形。
void gluTessBeginContour(GLUtessellator *tess)
void gluTessEndContour(GLUtessellator *tess)
一个多边形可能有多个封闭的轮廓线(封闭的回路),例如,一个有洞的多边形有2条回路,里面一条外面一条。每一个回路必须被gluTessBeginContour()和gluTessEndContour()包含。这是在gluTessBeginPolygon()和gluTessEndPolygon()中内嵌的块。
void gluTessVertex(GLUtessellator *tess, GLdouble cords[3], void *vertexData)
gluTessVertex()指定了回路的顶点。网格器使用这些顶点坐标执行网格化。所有的顶点需要位于同一个面中。第二个参数是网格化需要的顶点坐标,第三个参数是实际用来渲染的坐标,它可能不仅是顶点坐标,也可能是颜色坐标,法向量坐标,纹理坐标。
void gluTessCallback(GLUtessellator *tess, GLUenum type, void (*fn)())
在网格化的过程中,当OpenGL准备渲染网格化后的多边形形时网格器会调用一系列的回调模式。你必须指定适当的回调函数,这些回调函数包括实际渲染多边形的OpenGL命令,如glBegin(),glEnd(),glVertex*()等。
// 创建网格器
GLUtesselator *tess = gluNewTess();
// 注册回调函数
gluTessCallback(tess, GLU_TESS_BEGIN, beginCB);
gluTessCallback(tess, GLU_TESS_END, endCB);
gluTessCallback(tess, GLU_TESS_VERTEX, vertexCB);
gluTessCallback(tess, GLU_TESS_COMBINE, combineCB);
gluTessCallback(tess, GLU_TESS_ERROR, errorCB);
// 描述非凸多边形的顶点
gluTessBeginPolygon(tess, user_data);
// 第一条回路
gluTessBeginContour(tess);
gluTessVertex(tess, coords[0], vertex_data);
...
gluTessEndContour(tess);
// 第二条回路
gluTessBeginContour(tess);
gluTessVertex(tess, coords[5], vertex_data);
...
gluTessEndContour(tess);
...
gluTessEndPolygon(tess);
// 处理完成后删除网格器
gluDeleteTess(tess);
