

最近在使用正则匹配的时候,我遇到一个非常有意思的现象,代码如下所示:
const reg = /\.jpg/g;
const arr = [
'test1.jpg',
'test2.jpg',
'test3.jpg',
'test4.jpg',
'test5.jpg',
];
arr.map(item => console.log(reg.test(item)));
这段代码很好理解:它的规则就是判断字符串中是否含有.jpg,然后再循环地和数组中的字符串进行匹配,打印出结果。
很显然这非常之简单嘛,输出的结果当然是全为true啦~
然而,图样图森破,它的结果是这样的:

代码的执行结果非常神奇:它并没有全部打印true,而是交替打印true和false值,这到底是为什么?
为了查清楚到底是怎么回事,我开始上网搜索相关资料,经过一番搜索后,发现正则并没有我们想象的那么简单...
what's going on?
首先正则有一个属性叫lastIndex,它表示正则下一次匹配时的起始位置。一般情况下我们是使用不到它的,但在正则中包含全局标志g时,正则的test和exec方法就会使用到它,具体规则如下:
- 初始状态下
lastIndex的值为0 - 若成功匹配,
lastIndex的值就被更新成被匹配字符串后面的第一个字符的index,或者可理解为被匹配字符串的最后一个字符index + 1, - 若匹配失败,
lastIndex则被重置为0。 - 如果我们继续使用原先的正则进行下一轮匹配,它则会从字符串
lastIndex的位置开始进行
为验证这个结论,我特意做了两个实验:
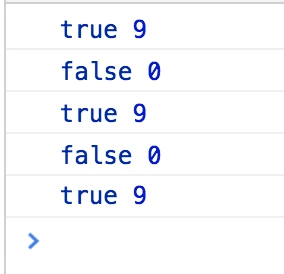
第一个就是直接将正则的lastIndex打印出来:
const reg = /\.jpg/g;
const arr = [
'test1.jpg',
'test2.jpg',
'test3.jpg',
'test4.jpg',
'test5.jpg',
];
arr.map(item => console.log(reg.test(item), reg.lastIndex));
第二个就对数组中的字符串稍作修改:
const reg = /\.jpg/g;
const arr = [
'test1.jpg',
'longTest4.jpg',
'test3.jpg',
'longTest4.jpg',
'test5.jpg',
];
arr.map(item => console.log(reg.test(item), reg.lastIndex));
通过两组实验的对比观察,发现确实如此:
在第一个实验中,由于数组中字符串的长度都是一致的,成功匹配后lastIndex的值直接更新为9,下次匹配的时候直接从第10个字符开始(很明显根本就没第10个字符嘛),因此匹配失败,lastIndex重置为0。以此类推,最终以9、0、9的形式交替打印。
而第二个实验由于我们增加了部分字符串的长度,因此对于第2、4个字符串而言,即使从第9个字符开始匹配,依然能匹配到后边的.jpg,故lastIndex继续更新到13
通过这次小小的实验,我们发现使用正则的时候还是要多加小心,对于test和exec方法,最好还是不要随意加上全局标志g。
