

越来越觉得基础太重要了,要成为一个合格的算法工程师而不是调包侠,一定要知道各个基础模型的HOW&WHY,毕竟那些模型都是当年的SOTA,他们的思想也对之后的NLP模型影响很大。最近找到了一个还不错的nlp-tutorial,准备抽时间过一遍基础模型,模型的大致思想以及数学公式可能就带过了,主要是实现上的细节。
1. NNLM
1.1 思想
通过神经语言模型学习词向量,网络结构如图:
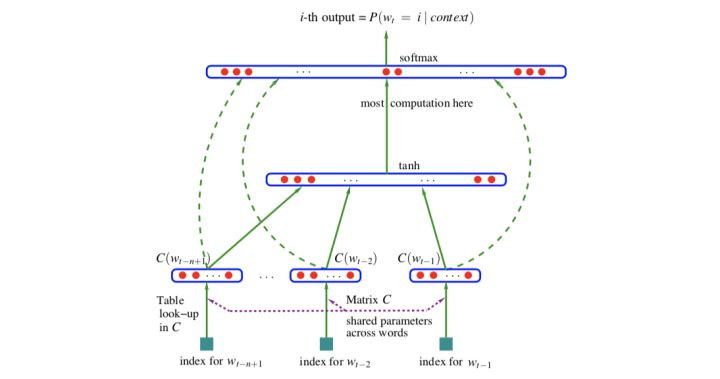
解决了统计语言模型(n-gram model)的以下问题:
- 维度灾难:高维下的数据稀疏会导致很多统计概率为0,本文提出了分布式词表示
- 长距离依赖:n-gram一般最多为3
- 词的相似关系:在本文中,词以向量的方式存在,通过LM训练后相似的词会具有相似的词向量
1.2 源码
![[公式]](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2019/7/15/16bf627dca8cfa6f~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m)
self.H = nn.Parameter(torch.randn(n_step * m, n_hidden).type(dtype))
self.W = nn.Parameter(torch.randn(n_step * m, n_class).type(dtype))
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype))
self.U = nn.Parameter(torch.randn(n_hidden, n_class).type(dtype))
self.b = nn.Parameter(torch.randn(n_class).type(dtype))
def forward(self, X):
X = self.C(X)
X = X.view(-1, n_step * m) # [batch_size, n_step * emb_dim]
tanh = torch.tanh(self.d + torch.mm(X, self.H)) # [batch_size, n_hidden]
output = self.b + torch.mm(X, self.W) + torch.mm(tanh, self.U) # [batch_size, n_class]
return output要注意的点:
- 模型输入x是所有词向量的拼接,而不是平均
- 模型有两个隐层:一个是线性层C,一个是非线性层tanh。W矩阵中的参数是有可能为0的
- 模型输出层embedding参数矩阵不共享
