

SnowFlake 结构
SnowFlake生成的ID一共占位64bit,其结构图如下:
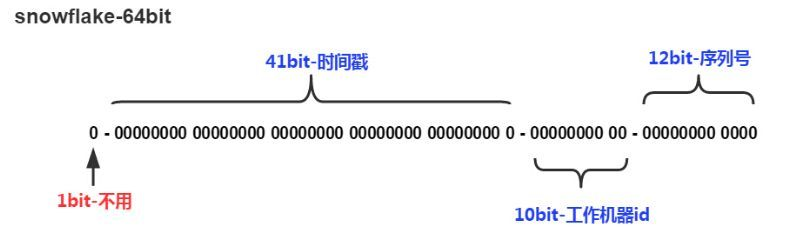
- 第一位0是占位符,其值始终是0,无实际作用。
- 第2位至第42位,占用41bit,是时间戳。可以精确到毫秒,41位长总共可以容纳大约69年,即2^69/(1000*60*60*24*365)=69.73年。
- 第43位至第52位,占用10bit,代表的是工作机器ID。其中高5位代表数据中心ID(机房ID),低5位代表的是工作节点ID(服务器ID),10bit可以容纳2^10=1024个服务器节点。
- 第53位至第64位,占用12bit,代表的是序列号。可以容纳2^12=4096个序列。
java 代码实现
public class SnowFlake {
//机器ID
private long workerId;
//数据中心ID
private long datacenterId;
//自增序列
private long sequence = 0L;
//起始时间戳 Thu, 04 Nov 2010 01:42:54 GMT
private long twepoch = 1288834974657L;
//节点ID
private long workerIdBits = 5L;
//数据中心ID
private long datacenterIdBits = 5L;
//最大支持机器节点数0~31,一共32个
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
//最大支持数据中心节点数0~31,一共32个
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
//序列号12位
private long sequenceBits = 12L;
//机器节点左移12位
private long workerIdShift = sequenceBits;
//数据中心节点左移17位
private long datacenterIdShift = sequenceBits + workerIdBits;
//时间毫秒数左移22位
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
//4095
private long sequenceMask = -1L ^ (-1L << sequenceBits);
//记录上次生成ID的时间戳
private long lastTimestamp = -1L;
public synchronized long nextId() {
//获取当前毫秒数
long timestamp = timeGen();
//如果服务器时间有问题(时钟后退) 报错。
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format(
"Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果上次生成时间和当前时间相同,在同一毫秒内
if (lastTimestamp == timestamp) {
//sequence自增,因为sequence只有12bit,所以和sequenceMask相与一下,去掉高位
sequence = (sequence + 1) & sequenceMask;
//判断是否溢出,也就是每毫秒内超过4095,当为4096时,与sequenceMask相与,sequence就等于0
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp); //自旋等待到下一毫秒
}
} else {
sequence = 0L; //如果和上次生成时间不同,重置sequence,就是下一毫秒开始,sequence计数重新从0开始累加
}
lastTimestamp = timestamp;
// 最后按照规则拼出ID。
return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift)
| (workerId << workerIdShift) | sequence;
}
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
protected long timeGen() {
return System.currentTimeMillis();
}
}
运算符
因为部分代码涉及到了位运算,在这里先讲解下位运算。
需要特别注意的是当有负数参与位运算时,需要使用补码进行运算。 正数的补码是他本身。 负数的补码为各位取反然后加1(最高位保持为1不变)
&
& 作为位运算时,称之为“按位与”, 1&1=1,1&0=0,0&1=0,0&0=0。
举例说明:
3 & 5 = 0000 0011 & 0000 0101,即011 & 101 = 001 = 0000 0001 = 1。
|
| 作为位运算时,称之为“按位或”, 1|1=1,1|0=1,0|1=1,0|0=0。
举例说明:
3 | 5 = 0000 0011 | 0000 0101,即011 | 101 = 111 = 0000 0111 = 7。
^
^ 作为位运算时,称之为“异或”,异或就是不能相同, 1^1=0,1^0=1,0^1=1,0^0=0。
举例说明:
3 ^ 5 = 0000 0011 | 0000 0101,即011 ^ 101 = 110 = 0000 0110 = 6。
<<
<< 作为位运算时,称之为“左移”,即低位向高位移动,原位补0。正数左边第一位补0,负数补1。
举例说明:
5 << 2 = 0000 0101 << 2 = 0001 0100 = 20。
>>
>> 作为位运算时,称之为“右移”,即高位向地位移动,原位补0。正数左边第一位补0,负数补1,等于除以2的N次方。
举例说明:
5 >> 2 = 0000 0101 >> 2 = 0000 0001 = 1。
计算maxWorkerId、 datacenterIdBits 和 sequenceMask
maxWorkerId = -1L ^ (-1L << workerIdBits) = -1L ^ (-1L << 5L) = -1L ^ -32L = 1111 1111 ^ 1110 0000 = 0001 1111 = 31。同理可得出 datacenterIdBits = 31, sequenceMask = 4095。
sequenceMask 的作用是和 sequence 进行“按位与”运算,以此来判断 sequence 占用的12位bit是否重复使用了。
nextId() 逻辑流程
nextId() 是获取订单Id的主要方法,其逻辑流程图如下:
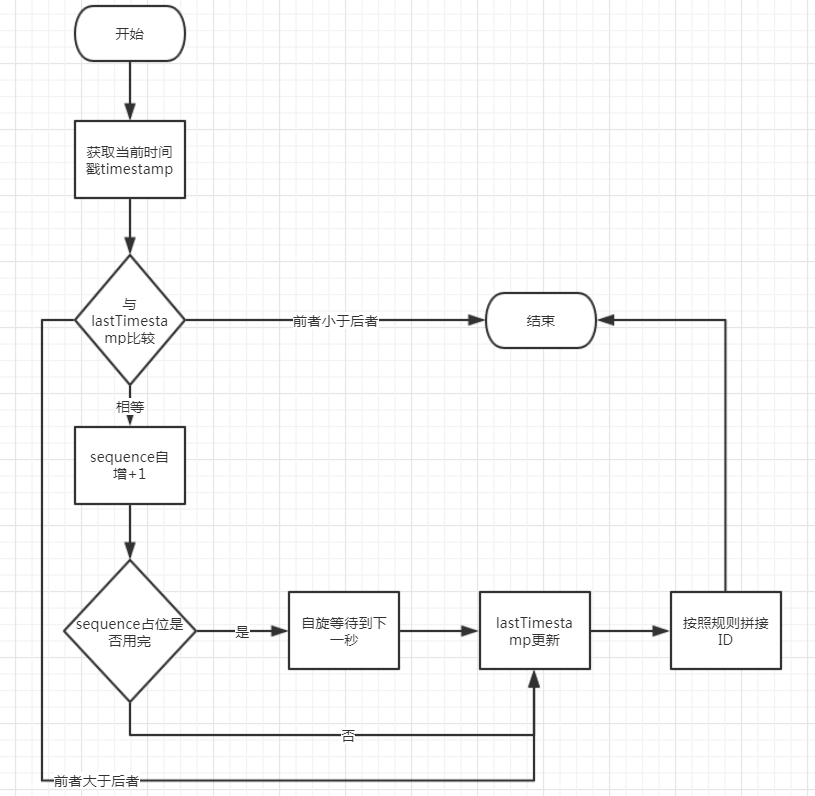
1. 获取timestamp
获取当前时间戳 timestamp 。并将之与上次获取 ID 的时间戳 lastTimestamp 对比。
2.1 timestamp 小于 lastTimestamp
说明服务器系统时钟不正确,直接抛出异常。
2.2 timestamp 等于 lastTimestamp
因为 timestamp 和 lastTimestamp 相同,能够改变的bit位就只剩下了序列,所以接下来的逻辑就是获取序列 sequence。
首先将 sequence 自增加1,然后判断 sequence 的值是否大于4095。如果 sequence 的值大于4095,则说明12位 sequence 已经全部使用了。此时,需要做的便是自旋等待直到下一毫秒。到了下一毫秒后直接将 sequence 重置为0。
2.3 timestamp 大于 lastTimestamp
如果当前时间戳 timestamp 大于 lastTimestamp,为了避免继续使用 sequence 产生混乱,直接将sequence重置为0。
3. 更新lastTimestamp
sequence 的值确定后,接下来就是更新 lastTimestamp,以便下次生成ID时使用。
4. 组装ID
时间戳 timestamp 、序列 sequence的值确定后,即可开始按照SnowFlake的规则组装ID了。即:
return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift)
| (workerId << workerIdShift) | sequence;
- 当前时间戳减去起始时间戳,然后左移22位;
- 数据中心ID左移17位;
- 节点ID左移12位;
- 序列不进行移动;
SnowFlake的优缺点
优点
- 生成ID时不依赖于DB,完全在内存生成,高性能高可用。
- ID呈趋势递增,后续插入索引树的时候性能较好。
缺点
依赖于系统时钟的一致性。如果某台机器的系统时钟回拨,有可能造成ID冲突,或者ID乱序。
