

在同一个goroutine中:
多个defer的调用栈原理是什么? defer函数是如何调用的?
为了探究其中的奥秘我准备了如下代码:
package main
import "fmt"
func main() {
xx()
}
func xx() {
defer aaa(100, "hello aaa")
defer bbb("hello bbb")
return
}
func aaa(x int, arg string) {
fmt.Println(x, arg)
}
func bbb(arg string) {
fmt.Println(arg)
}
输出: bbb 100 hello aaa 从输出结果看很像栈的数据结构特性:后进先出(LIFO)。
首先从汇编入手去查看xx()函数的执行过程,命令如下:
go tool compile -S main.go >> main.s
"".xx STEXT size=198 args=0x0 locals=0x30
0x0000 00000 (main.go:9) TEXT "".xx(SB), ABIInternal, $48-0
0x0000 00000 (main.go:9) MOVQ (TLS), CX
0x0009 00009 (main.go:9) CMPQ SP, 16(CX)
0x000d 00013 (main.go:9) JLS 188
0x0013 00019 (main.go:9) SUBQ $48, SP
0x0017 00023 (main.go:9) MOVQ BP, 40(SP)
0x001c 00028 (main.go:9) LEAQ 40(SP), BP
0x0021 00033 (main.go:9) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0021 00033 (main.go:9) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0021 00033 (main.go:9) FUNCDATA $3, gclocals·9fb7f0986f647f17cb53dda1484e0f7a(SB)
0x0021 00033 (main.go:10) PCDATA $2, $0
0x0021 00033 (main.go:10) PCDATA $0, $0
0x0021 00033 (main.go:10) MOVL $24, (SP)
0x0028 00040 (main.go:10) PCDATA $2, $1
0x0028 00040 (main.go:10) LEAQ "".aaa·f(SB), AX
0x002f 00047 (main.go:10) PCDATA $2, $0
0x002f 00047 (main.go:10) MOVQ AX, 8(SP)
0x0034 00052 (main.go:10) MOVQ $100, 16(SP)
0x003d 00061 (main.go:10) PCDATA $2, $1
0x003d 00061 (main.go:10) LEAQ go.string."hello aaa"(SB), AX
0x0044 00068 (main.go:10) PCDATA $2, $0
0x0044 00068 (main.go:10) MOVQ AX, 24(SP)
0x0049 00073 (main.go:10) MOVQ $9, 32(SP)
0x0052 00082 (main.go:10) CALL runtime.deferproc(SB)
0x0057 00087 (main.go:10) TESTL AX, AX
0x0059 00089 (main.go:10) JNE 172
0x005b 00091 (main.go:11) MOVL $16, (SP)
0x0062 00098 (main.go:11) PCDATA $2, $1
0x0062 00098 (main.go:11) LEAQ "".bbb·f(SB), AX
0x0069 00105 (main.go:11) PCDATA $2, $0
0x0069 00105 (main.go:11) MOVQ AX, 8(SP)
0x006e 00110 (main.go:11) PCDATA $2, $1
0x006e 00110 (main.go:11) LEAQ go.string."hello bbb"(SB), AX
0x0075 00117 (main.go:11) PCDATA $2, $0
0x0075 00117 (main.go:11) MOVQ AX, 16(SP)
0x007a 00122 (main.go:11) MOVQ $9, 24(SP)
0x0083 00131 (main.go:11) CALL runtime.deferproc(SB)
0x0088 00136 (main.go:11) TESTL AX, AX
0x008a 00138 (main.go:11) JNE 156
0x008c 00140 (main.go:12) XCHGL AX, AX
0x008d 00141 (main.go:12) CALL runtime.deferreturn(SB)
发现aaa()函数的参数及调用函数deferproc(SB):
0x0021 00033 (main.go:10) MOVL $24, (SP)
0x0028 00040 (main.go:10) PCDATA $2, $1
0x0028 00040 (main.go:10) LEAQ "".aaa·f(SB), AX
0x002f 00047 (main.go:10) PCDATA $2, $0
0x002f 00047 (main.go:10) MOVQ AX, 8(SP)
0x0034 00052 (main.go:10) MOVQ $100, 16(SP)
0x003d 00061 (main.go:10) PCDATA $2, $1
0x003d 00061 (main.go:10) LEAQ go.string."hello aaa"(SB), AX
0x0044 00068 (main.go:10) PCDATA $2, $0
0x0044 00068 (main.go:10) MOVQ AX, 24(SP)
0x0049 00073 (main.go:10) MOVQ $9, 32(SP)
0x0052 00082 (main.go:10) CALL runtime.deferproc(SB)
下面重点代码的统一说明:
//1, (SP) 将24放入栈顶(24其实是下面所说的deferd函数参数类型的长度和)。
0x0021 00033 (main.go:10) MOVL $24, (SP)
//2, 8(SP) 将aaa函数指针放入AX;将aaa函数指针放入到8(SP)中。
0x0028 00040 (main.go:10) LEAQ "".aaa·f(SB), AX
0x002f 00047 (main.go:10) MOVQ AX, 8(SP)
//3, 16(SP)把函数aaa第一个参数100放入到16(SP)中。
0x0034 00052 (main.go:10) MOVQ $100, 16(SP)
//4, 24(SP)获取第二个参数的内存地址并赋值给AX;AX中值赋值给24(SP)。
0x003d 00061 (main.go:10) LEAQ go.string."hello aaa"(SB), AX
0x0044 00068 (main.go:10) MOVQ AX, 24(SP)
//5,32(SP),将第二个参数字符串长度9赋值到32(SP)中。
0x0049 00073 (main.go:10) MOVQ $9, 32(SP)
//调用runtime.deferproc(SB)
0x0052 00082 (main.go:10) CALL runtime.deferproc(SB)
0(SP) = 24 //aaa(int, string)参数类型长度和
8(SP) = &aaa(int, string)//deferd函数指针
16(SP) = 100// 第一个参数值100
24(SP) = "hello aaa"//第二个参数
32(SP) = 9//第二个参数字符串长度
从以上2部分汇编代码可以看出,函数相关数据放到了SP中且连续。2,发现 defer aaa(int, string)编译器会插入deferproc(SB)函数。 去看一下源码:
//runtime/panic.go
func deferproc(siz int32, fn *funcval) { // arguments of fn follow fn
if getg().m.curg != getg() {
throw("defer on system stack")
}
sp := getcallersp()
argp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn)
callerpc := getcallerpc()
d := newdefer(siz)
if d._panic != nil {
throw("deferproc: d.panic != nil after newdefer")
}
d.fn = fn
d.pc = callerpc
d.sp = sp
switch siz {
case 0:
// Do nothing.
case sys.PtrSize:
*(*uintptr)(deferArgs(d)) = *(*uintptr)(unsafe.Pointer(argp))
default:
memmove(deferArgs(d), unsafe.Pointer(argp), uintptr(siz))
}
return0()
}
deferproc(siz int32, fn *funcval)
发现这个函数的参数是int32,*funcval。它们两个代表什么?我们有gdb去跟踪一下具体什么意思:

type stringStruct struct {
str unsafe.Pointer
len int
}
unsafe.Pointer占8个字节,int占8个字节。 具体字符串讲解可以看我以前的文章golang中的string、编码 接下来看*funcval:它的原型如下:
//runtime/runtime2.go
type funcval struct {
fn uintptr
// variable-size, fn-specific data here
}
funcval是个struct,里面的成员是个fn uintptr,根据fn字面意思猜测是函数的指针。
前文已经说过bbb(int, string)函数的相关数据放到了SP中,那func deferproc(siz int32, fn * funcval) 中的参数就是运行时系统会从sp中拿取siz和*fn然后调用deferproc(siz int32, fn * funcval)。
我们用gdb看一下这里面fn指向的函数到底是什么:
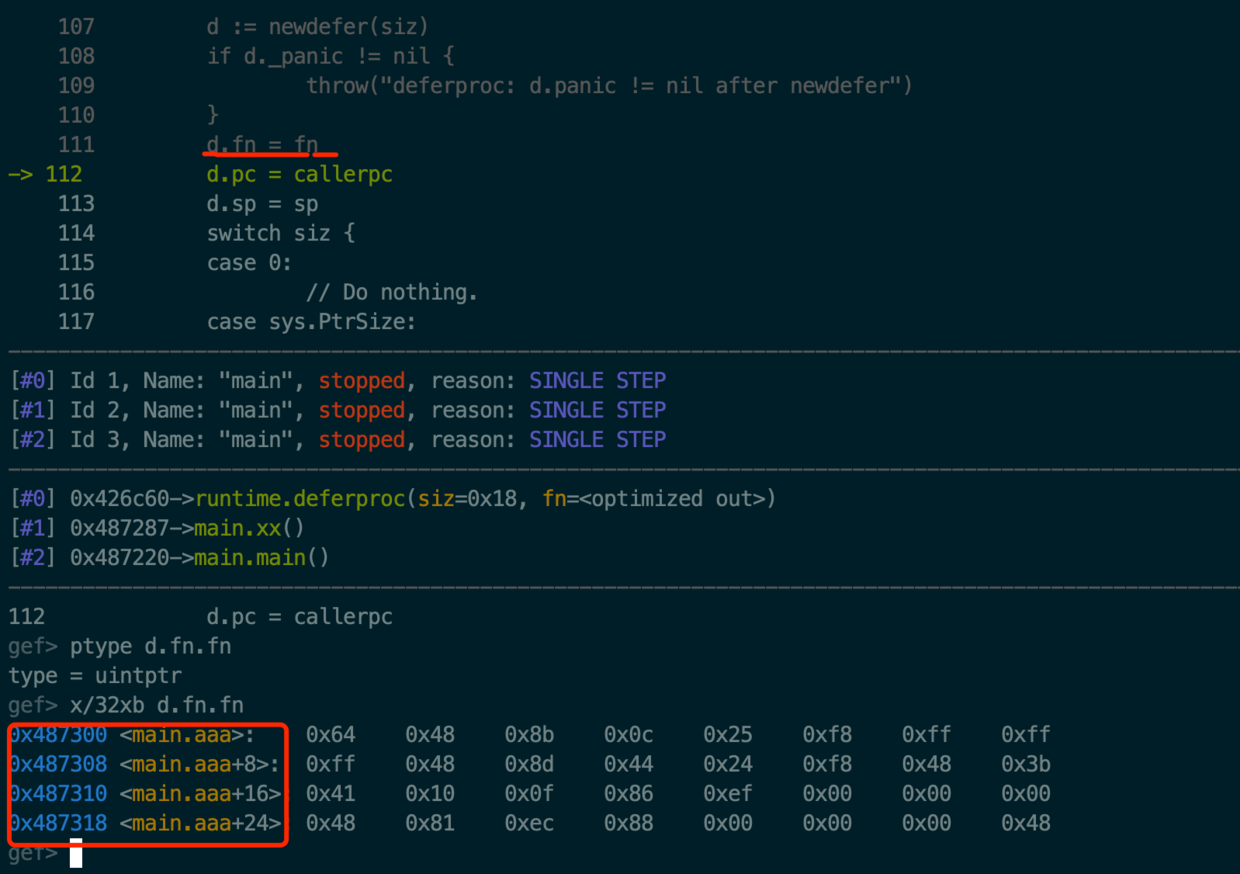
d := newdefer(siz)
去看一下它的原型:
func newdefer(siz int32) *_defer
它的返回值是*_defer,看一下它的定义:
//runtime/runtime2.go
type _defer struct {
siz int32
started bool
sp uintptr // sp at time of defer
pc uintptr
fn *funcval
_panic *_panic // panic that is running defer
link *_defer
}
它是个结构体。我们先查看siz,fn,link这3个参数就好,其他参数由于篇幅有限下文讲解。 siz:deferd函数参数原型字节长度的和。
fn:deferd函数指针。
link: 是什么意思??????
带着问题去看一下newdefer(siz)的实现:
func newdefer(siz int32) *_defer {
var d *_defer
sc := deferclass(uintptr(siz))
// 当前goroutine的g结构体对象
gp := getg()
if sc < uintptr(len(p{}.deferpool)) {
//当前goroutine绑定的p
pp := gp.m.p.ptr()
if len(pp.deferpool[sc]) == 0 && sched.deferpool[sc] != nil {
// Take the slow path on the system stack so
// we don't grow newdefer's stack.
systemstack(func() {//切换到系统栈
lock(&sched.deferlock)
//从全局deferpool拿一些defer放到p的本地deferpool
for len(pp.deferpool[sc]) < cap(pp.deferpool[sc])/2 && sched.deferpool[sc] != nil {
d := sched.deferpool[sc]
sched.deferpool[sc] = d.link
d.link = nil
pp.deferpool[sc] = append(pp.deferpool[sc], d)
}
unlock(&sched.deferlock)
})
}
if n := len(pp.deferpool[sc]); n > 0 {
d = pp.deferpool[sc][n-1]
pp.deferpool[sc][n-1] = nil
pp.deferpool[sc] = pp.deferpool[sc][:n-1]
}
}
if d == nil {//缓存中没有创建defer
// Allocate new defer+args.
systemstack(func() {
total := roundupsize(totaldefersize(uintptr(siz)))
d = (*_defer)(mallocgc(total, deferType, true))
})
if debugCachedWork {
// Duplicate the tail below so if there's a
// crash in checkPut we can tell if d was just
// allocated or came from the pool.
d.siz = siz
d.link = gp._defer
gp._defer = d
return d
}
}
d.siz = siz //赋值siz
//将g的_defer赋值给d.link
d.link = gp._defer
//d赋值给g._defer
gp._defer = d
return d
}
以上是defer生成过程,大体意思就是先从缓存中找defer如果没有就创建一个,然后将size,link进行赋值。 重点看如下代码:
d.link = gp._defer
gp._defer = d
以上2行代码实现中已经有解释,这里再详细解释一下: 这2句的意思是,将刚刚生成的defer绑定到g._defer上,就是将最新的defer放到 g._defer上作为链表头。然后将g._defer绑定到d.link上,见下方示意图:
[当前的g]{_defer} => [新的d1]{link} => [g]{老的_defer}
如果再有新生成的defer(d2)则链表如下:
[当前的g]{_defer} => [新的d2]{link} => [新的d1]{link} => [g]{老的_defer}
回到deferproc(siz int32, fn *funcval)函数中来,newdefer(siz)上面第二行是什么意思呢?:
argp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn)
继续用gdb跟踪一下,发现涉及到argp的在这一行,见下方截图2:
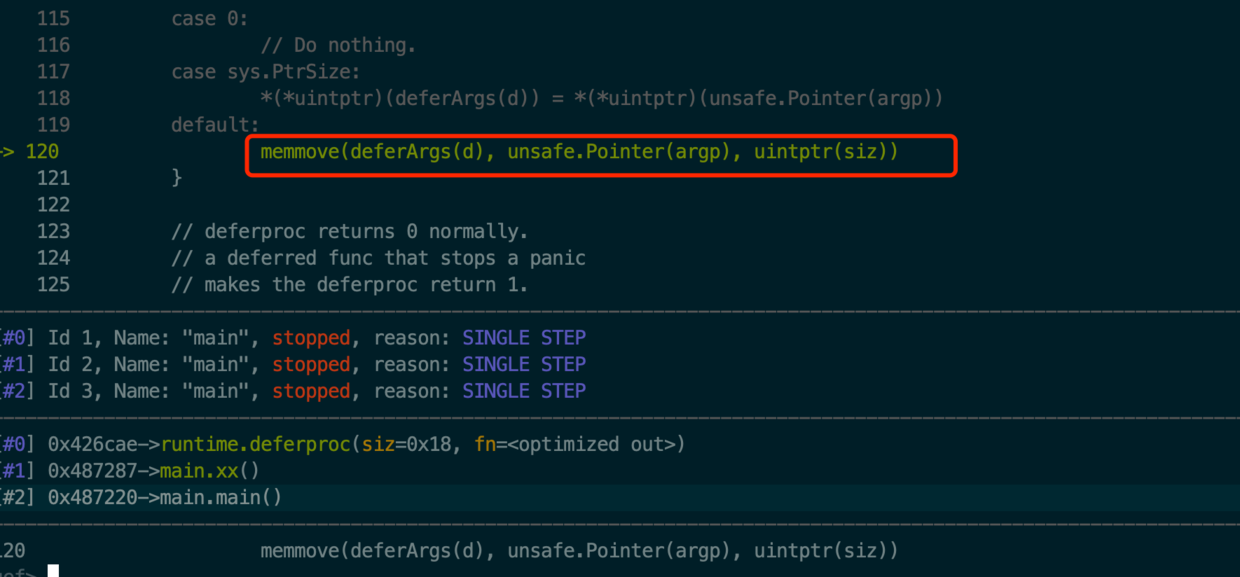
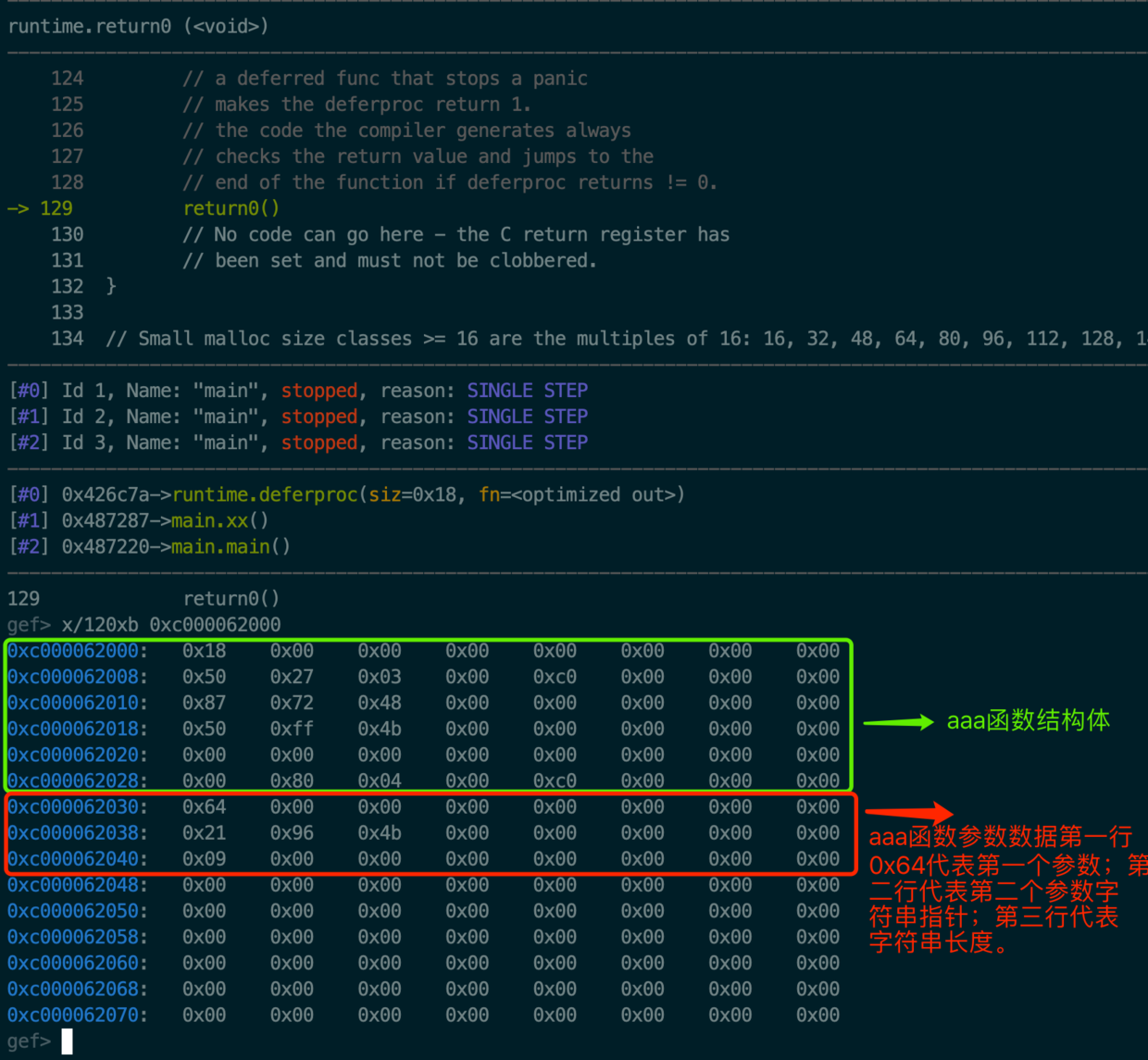
图3中红框中的第一行是0x64 它的10进制表示为100。证明这个是aaa函数的第一个参数,同理第二行0x4b9621为第二个参数字符串的指针,去看一下是否为预想的那样,见图4:

hello aaa。从而我得出结论deferd函数的参数是在deferd结构体后面。第三行代表字符串长度。也就是说第二行和第三行代表了字符串原型(结构体)的值。
继续跟踪函数执行过程:
defer bbb("hello bbb")
bbb(string)的执行过程和上面aaa(int, string)函数执行过程是一样的,这里不再重复演示。 deferproc栈执行完之后运行return处,见图5:
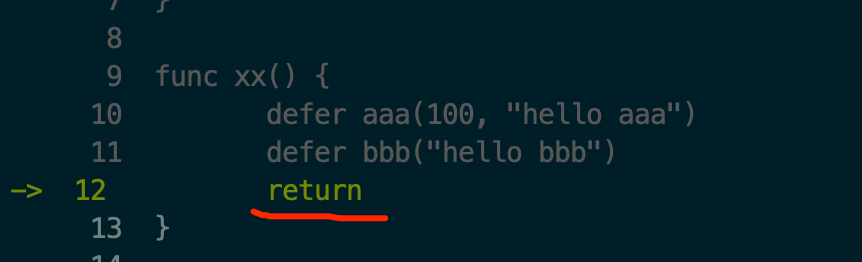
然后按s进入return实现处(到了deferreturn栈),见下图6:
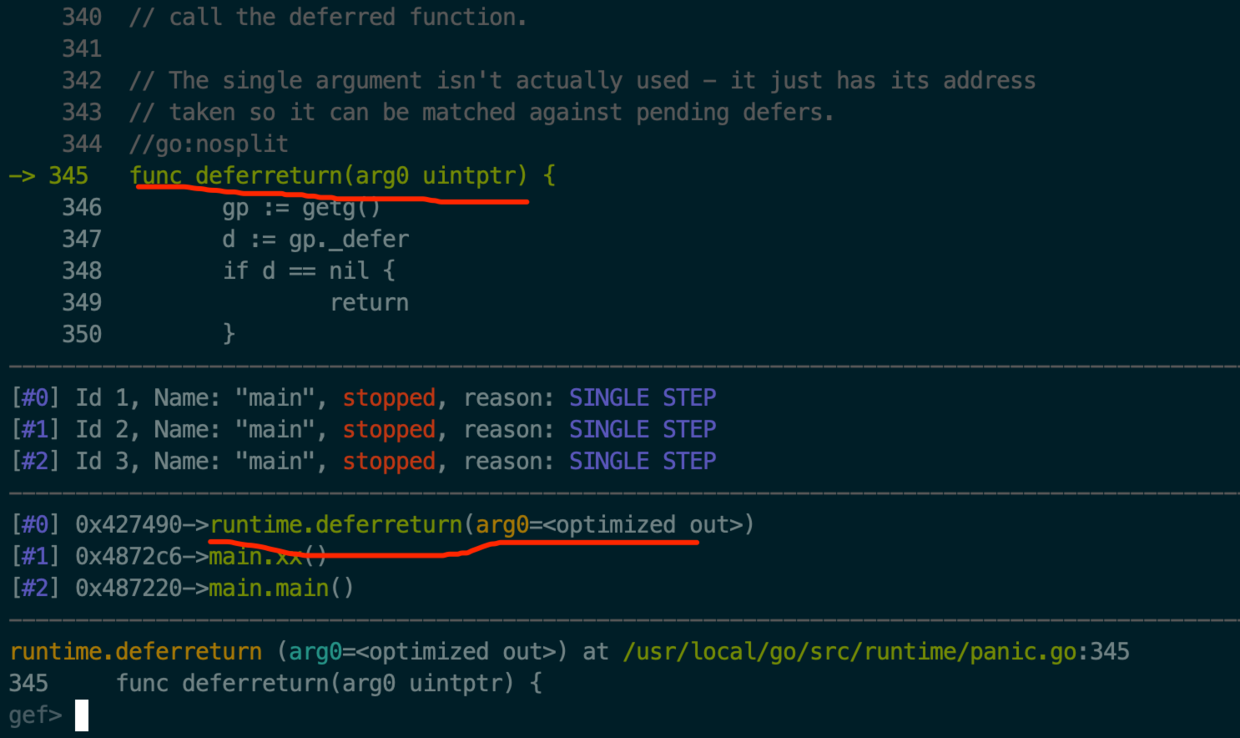
去看一下它的实现:
//rutime/painc.go
//go:nosplit
func deferreturn(arg0 uintptr) {
gp := getg() //获取当前的g
d := gp._defer //获取当前g的_defer链表头
//d为什么可以为nil,因为defer函数可以嵌套例如:
// defer a -> defer b -> defer c
//deferreturn函数被调用至少一次,就是将链表里的defer都执行完就直接返回了。
if d == nil {
return
}
sp := getcallersp()
if d.sp != sp {
return
}
//将deferd函数参数复制到arg0处,为调用deferd函数做准备。
switch d.siz {
case 0:
// Do nothing.
case sys.PtrSize://如果siz的大小为指针大小直接如下复制,目的是减少cpu运算。
*(*uintptr)(unsafe.Pointer(&arg0)) = *(*uintptr)(deferArgs(d))
default:
memmove(unsafe.Pointer(&arg0), deferArgs(d), uintptr(d.siz))
}
fn := d.fn //将d.fn拷贝一份
d.fn = nil //将d.fn设置为空
gp._defer = d.link//将当前defer的下一个defer绑定到链表头。
freedefer(d) //将d释放掉
//fn为deferd函数,第二个参数为deferd函数的参数
jmpdefer(fn, uintptr(unsafe.Pointer(&arg0)))
}
fn := d.fn
d.fn = nil
gp._defer = d.link
freedefer(d)
重点解释一下上面4行代码:将链表下一个defer绑定到gp._defer处。将当前的defer释放掉。见下方示意图:
[当前的g]{_defer} => [新的d2]{link} => [新的d1]{link} => [g]{老的_defer}
运行完d2:
[当前的g]{_defer} => [新的d1]{link} => [g]{老的_defer}
然后看一下下方jmpdefer函数:
jmpdefer(fn, uintptr(unsafe.Pointer(&arg0)))
这个函数是具体执行defer函数地方,我们看它实现之前先记住下图图7的deferreturn入口地址,下面会说到这个地址。
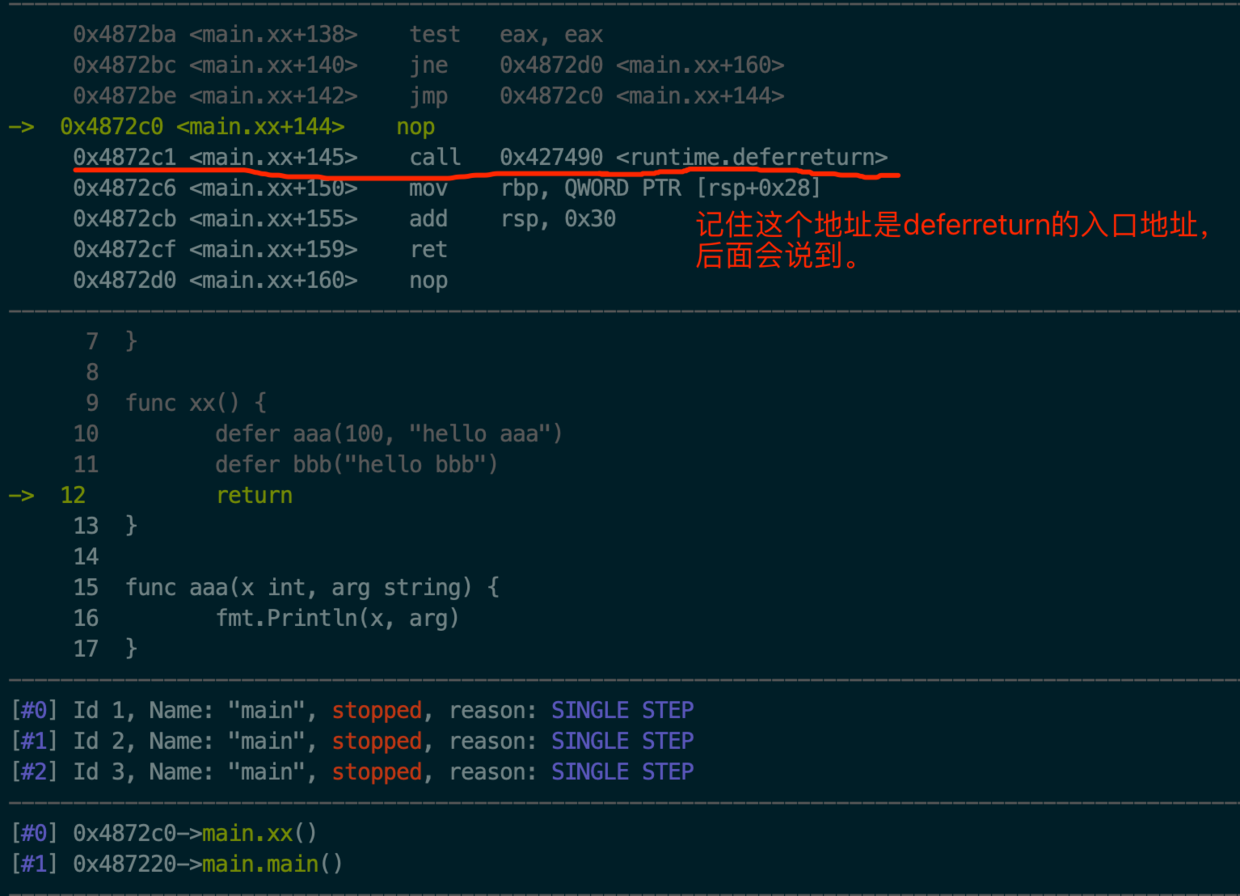
jmpdefer函数实现见下方代码:
TEXT runtime·jmpdefer(SB), NOSPLIT, $0-16
MOVQ fv+0(FP), DX // fn
MOVQ argp+8(FP), BX // caller sp
LEAQ -8(BX), SP // caller sp after CALL
MOVQ -8(SP), BP // restore BP as if deferreturn returned (harmless if framepointers not in use)
SUBQ $5, (SP) // return to CALL again
MOVQ 0(DX), BX
JMP BX // but first run the deferred function
一行一行解释:
MOVQ fv+0(FP), DX // fn
将函数第一个参数fn指针复制给DX,从而后续代码可以从DX中取fn的指针来执行deferd函数。
MOVQ argp+8(FP), BX // caller sp
将函数第二个参数argp指针复制给BX,这个指针是deferd函数第一个参数地址。
LEAQ -8(BX), SP // caller sp after CALL
从上面第2条指令可知BX存放的是deferd函数第一个参数地址。因为此时gbd调试的是bbb(string)这个函数,所以此时的参数是个字符串结构体,总共占16个字节,前8个字节是数据指针,后8个是长度。那-8(BX)里面又是什么数据呢,就是说bbb(string)参数值前面(低位)是什么东东。用gdb跟一下执行完这条指令看一下SP(因为赋值给了SP)中内存的值是啥,见图8。

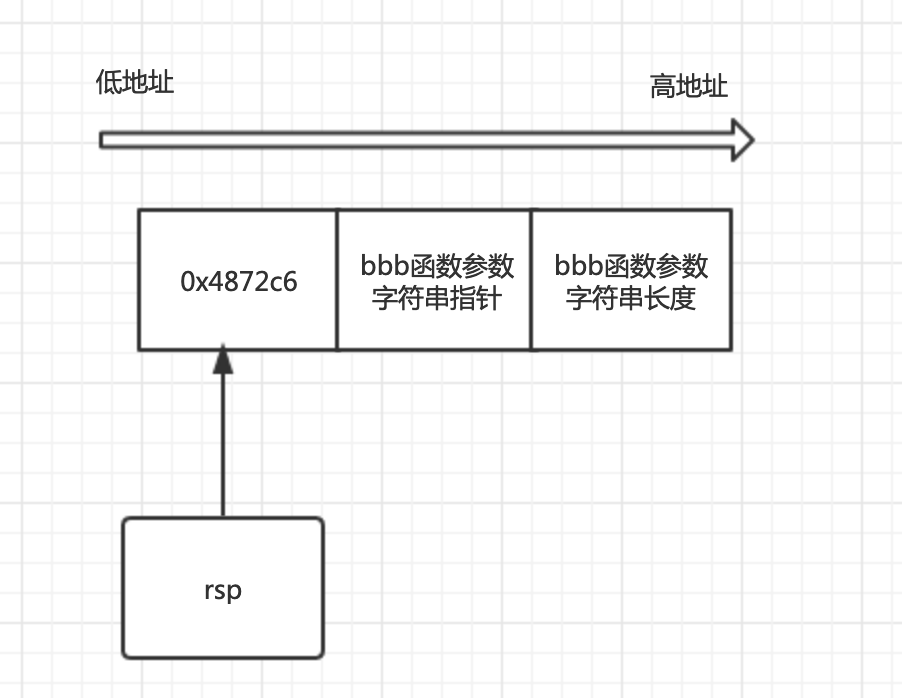
0x4872c6是什么,指针?试着去看一下它是否能指向具体内存见下图10


0x4872c6与图10是一样的值。根据图11,这个地址是rutime.deferreturn(SB)的下一个指令,就是说这个地址是rutime.deferreturn(SB)返回地址。
仔细观察这两个地址:
0x4872c1 == rutime.deferreturn(SB)
0x4872c6 == rutime.deferreturn(SB)的下一个指令地址(也叫返回地址)
发现他们相差5个字节。根据汇编知识可知,cpu是如何找到下一个指令的呢,是通过当前指令所占字节数所确定的。 len(0x4872c6) - len(0x4872c1) == 5 可知
call runtime.deferreturn(sb)
占5个字节,所以0x4872c1+5就可得到下一个指令首地址。
第4行:
MOVQ -8(SP), BP // restore BP as if deferreturn returned (harmless if framepointers not in use)
打印BP的值=0xc000032778 看一下栈的情况,见图12
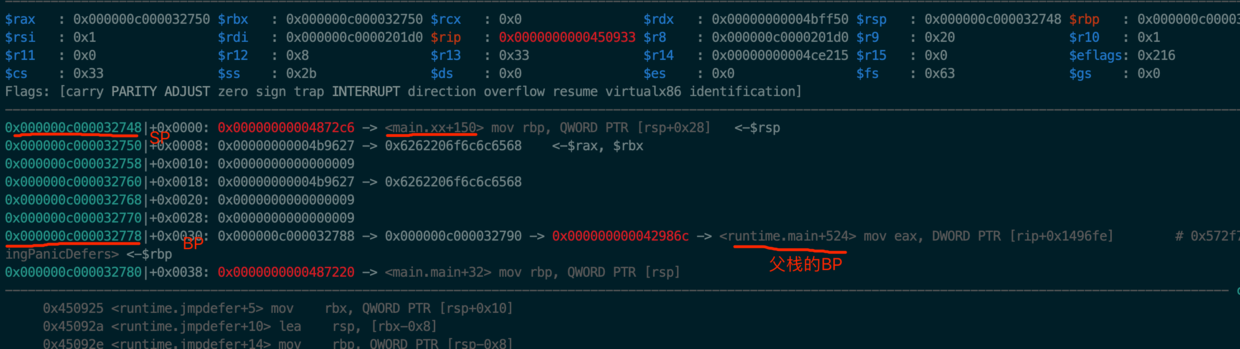
第5行:
SUBQ $5, (SP) # return to CALL again
从第3行中的解释可知,如果SP所指向的数据(runtime.deferreturn返回地址)减5的话,正好是runtime.deferreturn(SB)的指令入口。见图13:
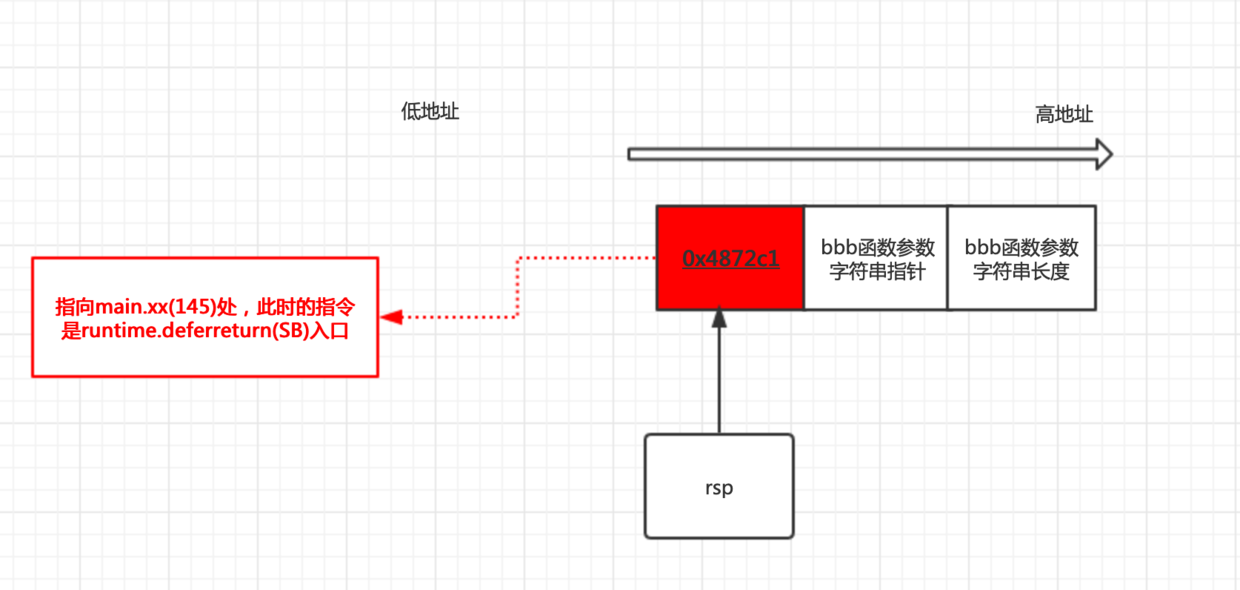
第6,7行:
MOVQ 0(DX), BX
JMP BX // but first run the deferred function
将DX所指向的函数指令赋值给BX 执行fn.fn也就是bbb(string)。 执行到bbb(string)处,见图14
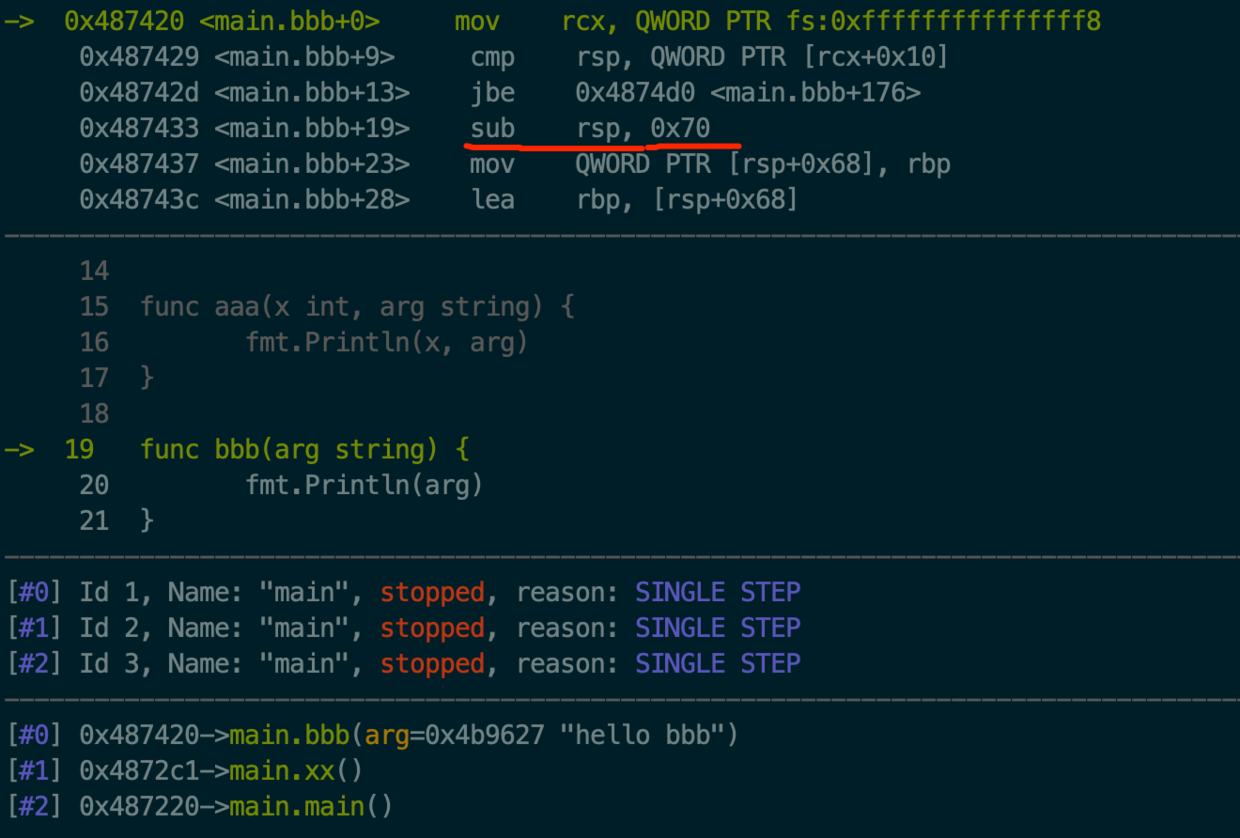
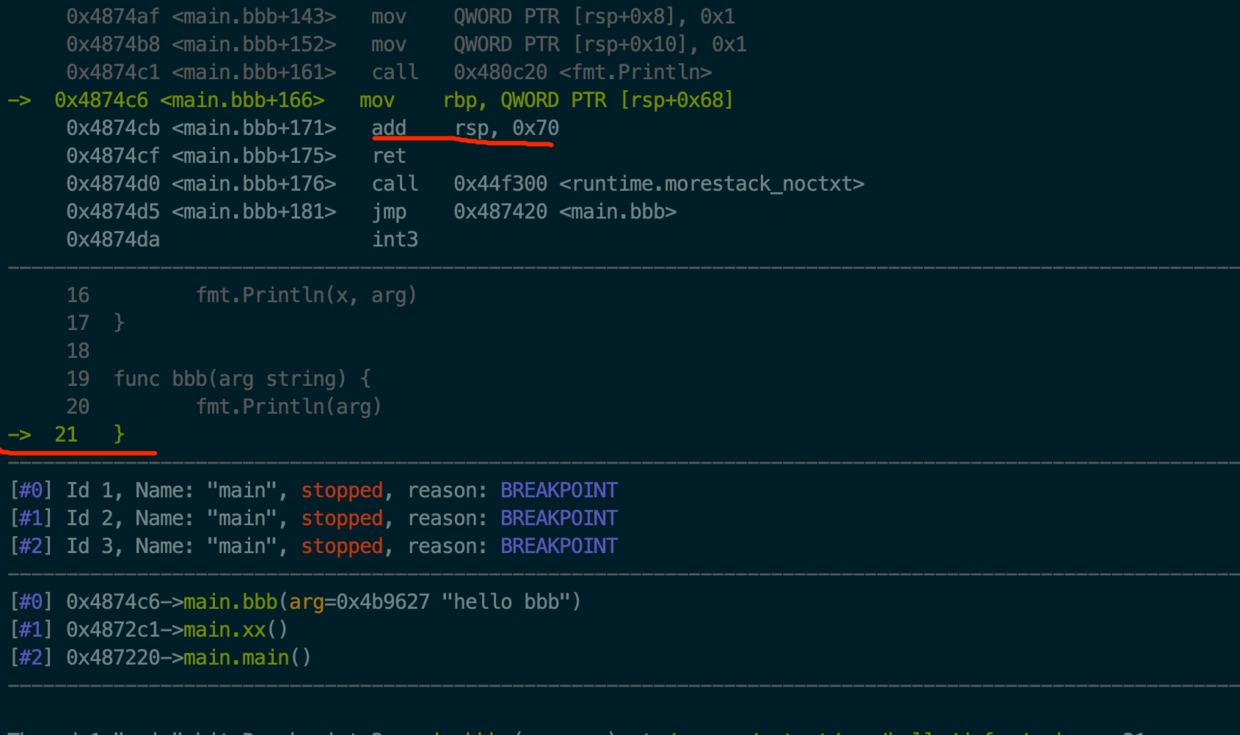
add rsp, 0x70指令下一行是个ret指令。这个在bbb(string)函数是没有的,是编译器添加上去的,目的是pop当前栈顶的8个字节到rip寄存器中,这样cpu执行rip里的指令就会执行到runtime.deferreturn(SB)里从而实现了类似递归的调用deferreturn(SB)的作用。这样就依次可以把deferd链上的执行完。
继续到runtime.deferreturn(SB)中 如下代码:
if d == nil {
return
}
这个个if语句就是判断defer链上是否还有deferd函数,如果没有就直接返回了。从而避免无限递归循环下去。 里面还有几句代码:
sp := getcallersp()
if d.sp != sp {
return
}
有兴趣的小伙伴可以去试着看一下这里为什么这么写,由于时间有限这段代码的研究就不在这里展开了。
这篇文章主要是讲解defer的执行过程,由于篇幅原因,我把panic、recover、还有容易出错的defer语句的探究在下一篇中讲解,敬请期待~
