

微服务流行,我也是越来越喜欢MongoDB了,除非必要要用MySQL,我都会倾向于MongoDB。
MongoDB
什么是MongoDB ?
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
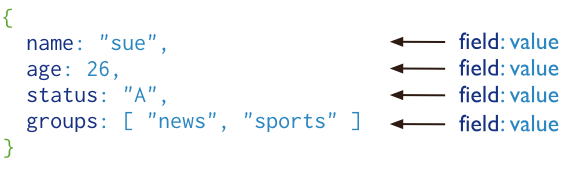
MongoDB特点
- MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
- 你可以在MongoDB记录中设置任何属性的索引 (如:FirstName="Sameer",Address="8 Gandhi Road")来实现更快的排序。
- 你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
- 如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
- MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
- Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
- Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
- Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
- GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
- MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
- MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
- MongoDB安装简单。
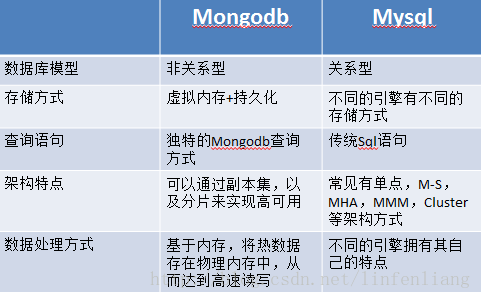
MongoDB与其他数据库的对比
MongoDB 与 MySQL
由于MongoDB独特的数据处理方式,可以将热点数据加载到内存,故而对查询来讲,会非常快(当然也会非常消耗内存);同时由于采用了BSON的方式存储数据,故而对JSON格式数据具有非常好的支持性以及友好的表结构修改性,文档式的存储方式,数据友好可见;数据库的分片集群负载具有非常好的扩展性以及非常不错的自动故障转移(大赞)。
不足:数据库的查询采用了特有的查询方式,有一定的学习成本(不高);索引不咋滴;锁只能提供到collection级别,还做不到行级锁;没有事务机制(不能回滚啊);学习资料肯定没有MySQL的多。
MongoDB与Hadoop的区别
MongoDB侧重于对数据进行操作的应用系统,而Hadoop则侧重于对数据进行分析统计的应用。
MongoDB能够满足对数据库读写性能具有极高要求的应用场景(很消耗memory的),一般这些应用的响应延迟会要求控制在10ms以下,甚至更低。而Hadoop由于每一次的读写操作会包含大量数据(Hadoop更适合少次操作大批量数据的场景),通过聚集分析处理大量数据,这种分析一般都会走MapReduce,会造成很高的延迟(数分钟到数小时不等)


MongoDB查询
查询语法
db.collection.find(query, projection).pretty()
collection:文档名称,或者可写成 getCollection('col_name')
query :可选,使用查询操作符指定查询条件
projection:可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
pretty():易读
条件语法
| 操作 | 格式 | 范例 |
|---|---|---|
| 等于 | {<key>:<value>} |
db.col.find({"by":"菜鸟教程"}).pretty() |
| 小于 | {<key>:{$lt:<value>}} |
db.col.find({"likes":{$lt:50}}).pretty() |
| 小于或等于 | {<key>:{$lte:<value>}} |
db.col.find({"likes":{$lte:50}}).pretty() |
| 大于 | {<key>:{$gt:<value>}} |
db.col.find({"likes":{$gt:50}}).pretty() |
| 大于或等于 | {<key>:{$gte:<value>}} |
db.col.find({"likes":{$gte:50}}).pretty() |
| 不等于 | {<key>:{$ne:<value>}} |
db.col.find({"likes":{$ne:50}}).pretty() |
AND语法
db.col.find({key1:value1, key2:value2}).pretty()
OR语法
db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
AND 与 OR
db.col.find(
{
key1: value1,
$or: [
{key2: value2},
{key3: value3}
]
}
).pretty()
limit()
该参数指定从MongoDB中读取的记录条数。
db.col.find().limit(NUMBER)
skip()
跳过指定数量的数据
db.col.find().limit(NUMBER).skip(NUMBER)
排序
db.col.find().sort({KEY:1})
聚合
db.col.aggregate(AGGREGATE_OPERATION)
举例:现在我们通过以上集合计算每个作者所写的文章数,使用aggregate()计算结果如下:
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
与sql相同:
select by_user, count(*) from mycol group by by_user
管道
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
