

前几天,有个朋友问了我一个问题,他说自己的html设置了cache-control的max-age,为什么chrome浏览器第一次加载的时候是200,之后就走了304。针对这个问题,引出了以下知识。
浏览器缓存
缓存机制是提高资源使用效率最有效的方法。它的思想就是建立一个资源池,webkit请求资源的时候,先从资源池中寻找目标文件,如果有则使用,如果没有则通过网络请求。 浏览器常见的缓存分为强缓存和协商缓存。下面我们用一张流程图来介绍一下强缓存和协商缓存。
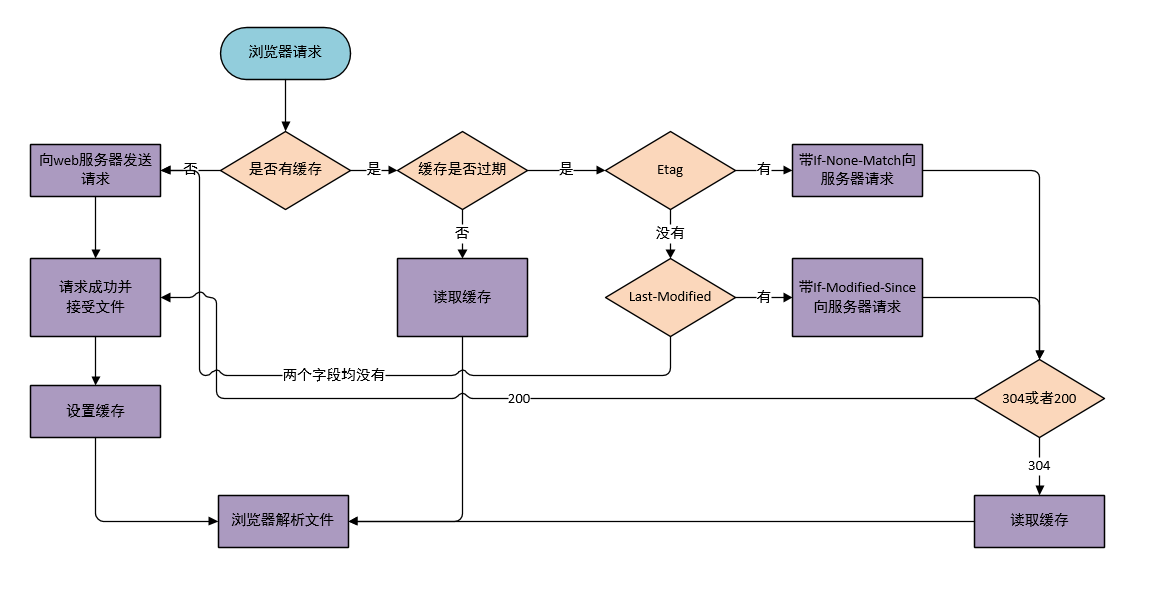
强缓存:浏览器不发送任何请求,直接从本地缓存中读取文件。Status Code: 200 OK。
协商缓存:浏览器发送请求,通过服务器来判定是否读取本地缓存。Status Code:304 Not Modified。
我们简单说一下流程图。 浏览器发送请求时,会判断当前环境是否存在缓存。如果不存在缓存,则发起请求,客户端完成接受及缓存工作。如果存在缓存,则先判断缓存是否过期。
那么怎么判定缓存是否过期呢?
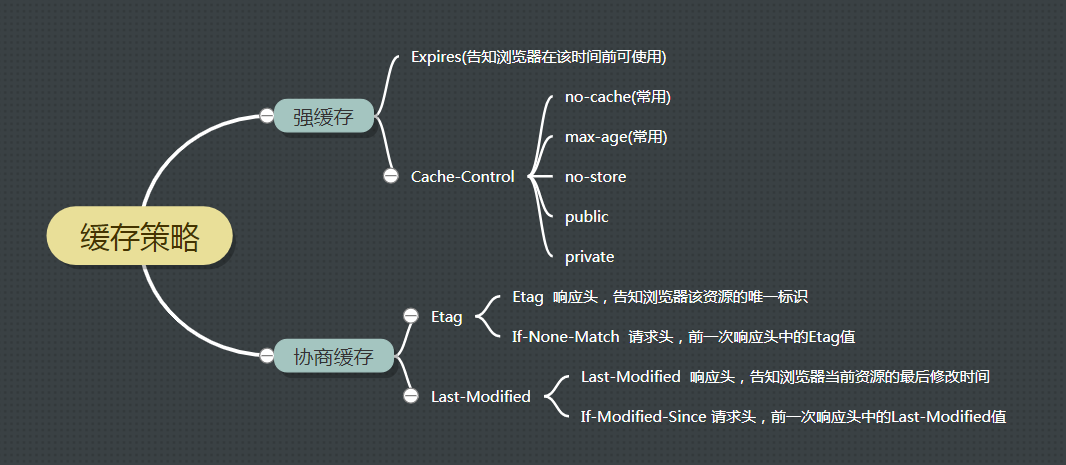
主要有两个字段,一个是Expires,一个是Cache-Control。
Expires是Http1.0的规范,它是一个绝对时间的字符串,告知浏览器在该时间之前可使用资源。
Cache-Control是Http1.1的规范,主要利用max-age设置一个相对时间代表过期时间。Cache-Control也可设置其它值,常用的就是max-age及no-cache。
因此,通过Cache-Control完成缓存是否过期的判断,如果没有过期,则读取本地缓存文件,此时完成的是强缓存的读取。如果已经过期,则强缓存读取失败,进入协商缓存阶段。
那么协商缓存是怎么处理的呢?
协商缓存主要有两对值,分别为Etag/If-None-Match(默认是对文件内容计算得到的Hash值)和Last-Modified/If-Modified-Since(浏览器向服务器发送资源最后的修改时间),他们是成对出现的。
Etag是Http1.1规范,是由服务器生成返回给前端。在协商缓存时,如果存在Etag,则请求服务器时会带上If-None-Match,这个If-None-Match的值就是服务器返回给前端的Etag的值。
Last-Modified是Http1.0规范,是文件在服务器端最后被修改的时间。在协商缓存时,如果Last-Modified存在,则请求服务器时会携带if-modified-since,该字段为上次向服务端请求时返回的Last-Modified。
如果以上两对至少存在一对,则浏览器向服务器发送请求,并携带相关字段,交由服务器判定是否进行协商缓存。在服务端,Etag的优先级要高于Last-Modified。因此服务器先进入Etag的判断,再判断Last-Modified。如果判断通过,则返回304,浏览器读取本地缓存。如果判断未通过,则返回200即文件资源,浏览器接受并重新完成缓存。
以上就是整个浏览器请求时,关于缓存的一系列操作。
Webkit底层缓存机制
那么Webkit内部是如何实现缓存机制的呢?我们都知道,资源加载是网页加载和渲染的第一步,也是最为关键的一步。网页中依赖的资源有很多,通常包括HTML/JS/CSS/图片/SVG/视频等文件,这些类型的文件在Webkit内部都有不同的类来表示。Webkit主要包含以下资源类:
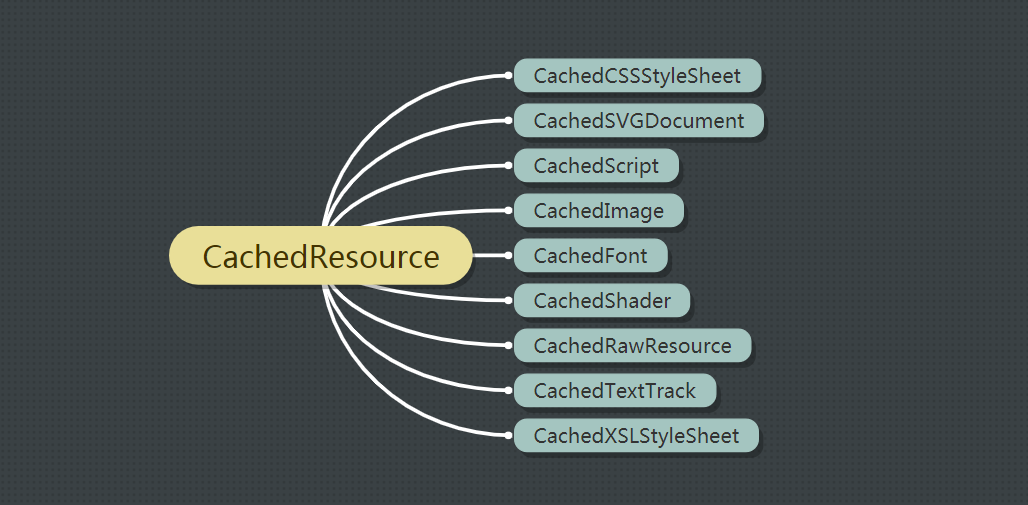
CachedResource。其中,HTML属于MainResource类,与之对应的是CachedRawResource类。
为什么所有的类前面都带有Cached呢?因为所有对资源的请求,默认都先走缓存,再决定是否向服务器发起请求。这个缓存机制的思想就是通过建立一个缓存池,当Webkit需要资源的时候,默认去缓存池中寻找。
靠什么寻找?靠的是URL来寻找,正好符合了URL统一资源定位符的气质。如果匹配则使用,如果不匹配则创建CachedResource下的一个对象,例如图片则创建CachedIamge对象,并通过网络模块获取。此时,我们指的这个缓存就是内存缓存,也就是我们在浏览器中见到的200 from memory,那么什么时候是200 from disk呢?后面我们再来介绍。
上面说到了Webkit中的资源,那怎么加载资源,肯定得有相应的加载器。
Webkit主要有三种加载器。
第一种就是特定的加载器,比如加载image就有特定的图片加载器,加载js就有特定的js加载器,加载字体就要特定的字体加载器;
第二种是缓存机制的资源加载器,就是第一种特定加载器先来缓存机制的资源加载器中寻找缓存资源;
第三种是通用的资源加载器,是在Webkit需要从网络或者文件系统获取资源时的加载器。
说到第三种加载器,它是从网络或者文件系统获取资源,那么我们想说的200 from disk也就是在此发生。即from disk 发生在 from memory之后。为什么我们说from disk是通过网络模块获取呢?因为在Webkit中,网络模块包含磁盘缓存。
说到这我们简单说下from disk和from memory。
from memory,字面意思就是来自内存,其实这里表达的也就是字面的意思。指的是我们当前加载的这个资源是从内存中获取的。这种请求不走浏览器,关闭页面时,内存会释放,再次打开也不会出现from memory。
from disk,也是字面意思,就是资源来自磁盘。来自磁盘中的数据肯定是我们之前缓存过得,它不会随着浏览器的关闭而消失,我们往往打开浏览器时会出现的就是from disk。
所以顺序就是from memory => from disk => http request
为什么我们刷新页面的时候在network有些是from memory有些是from disk而有些是重新加载呢?
因为Webkit中的缓存池肯定是有生命周期的,不可能让缓存池一直变大,否则就会内存溢出。因此,必须有相应的机制来控制缓存池的大小。Webkit采用的是LRU算法即最近最少使用算法。该算法是内存管理常见的页面置换算法,它选择最近最久未使用的页面予以淘汰,以此来保障资源池的大小。我们说的这个资源池指的是内存缓存的资源池。那么硬盘缓存呢?
硬盘缓存中,Webkit会维护一个缓存资源表,该表中的关键字就是URL。根据浏览器的情况来更新这个缓存表。同时,Webkit也使用LRU算法来控制这张表的大小。
以上就是Webkit中的基本缓存策略,那么我们回到文章开头提到的那个问题,为什么在Chrom浏览器中是304而不是200呢?查阅了相关的资料,找到了这样一句话。
In particular, main resource loads do not get the benefits of WebKit’s memory cache.
这里讲到的main resource就跟我们前面介绍的HTML属于MainResource类一样,HTML文件并不走memory cache,因此在Chrome浏览器中会出现304,而不会出现200。其实,我们可以认为这是Webkit替我们往前迈了一步。在目前我们开发网页时,通常不会给HTML设置缓存或者设置很短时间的缓存,以保证文件的及时更新,而Webkit走在了最前面。我们在此说的是Webkit,像FireFox浏览器则不是这样。
