

前言
前情概要
上一篇中我们提到了zookeeper伪集群的简单搭建,为了提供可靠的zookeeper服务,我们需要集群的支持。
集群搭建中该注意的点有两个,一个是zoo.cfg文件的参数配置,我们往其加入了dataLogDir路径来存放事务日志,还有要给三个集群的zoo.cfg文件都添加上集群节点配置,二是myid文件,myid是一行只包含机器id的文本,id在集群中必须是唯一的,其值应该在1~255之间,注意目录不能放错(dataDir的路径下)且注意编写时别输入错误的字符即可。
我们还简单地提到了paxos算法,根据一个小的场景描述了其流程,并且解释了zookeeper中选举算法的步骤,并结合打印出来的日志信息分析了其步骤
以往链接
从零开始的高并发(二)--- Zookeeper实现分布式锁
从零开始的高并发(三)--- Zookeeper集群的搭建和leader选举
内容一:(补充)zookeeper集群的工作原理
zookeeper提供了重要的分布式协调服务,它是如何保证集群数据的一致性的?
① ZAB协议的简单描述
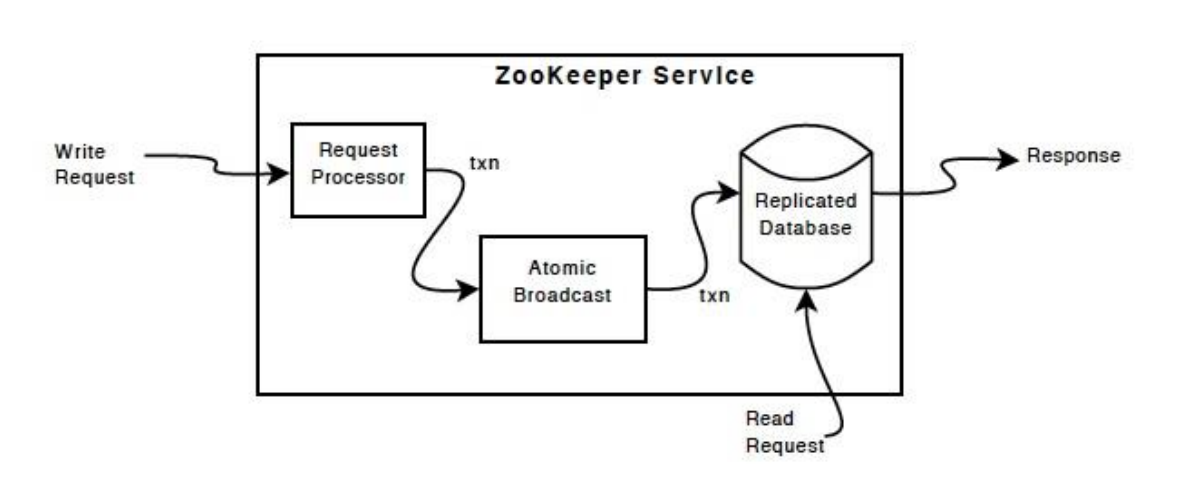
ZAB(zookeeper atomic broadcast)---zookeeper 原子消息广播协议是专门为zookeeper设计的数据一致性协议,注意此协议最主要的关注点在于数据一致性,而无关乎于数据的准确性,权威性,实时性。
ZAB协议过程
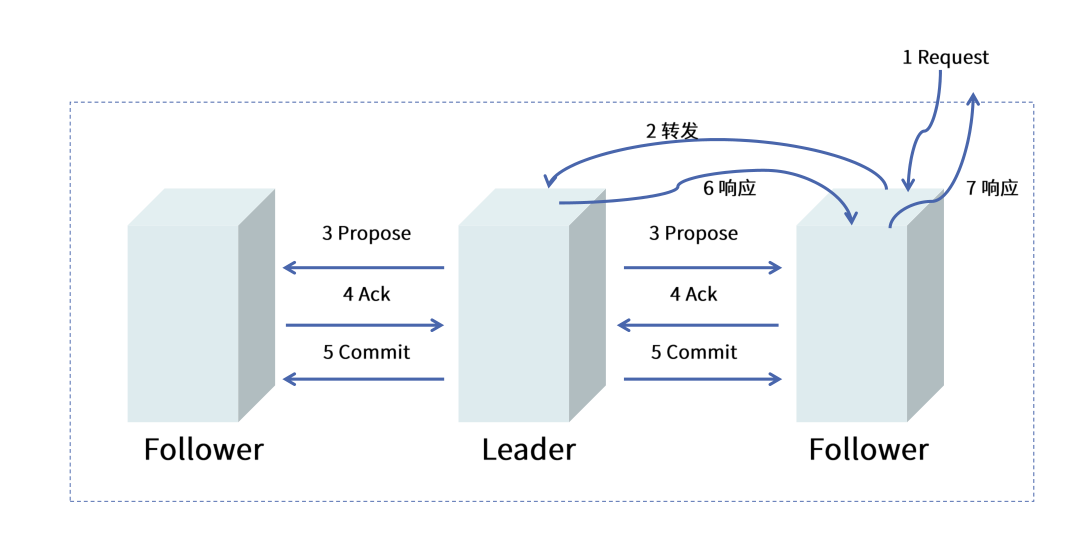
1.所有事务转发给leader(当我们的follower接收到事务请求)
2.Leader分配全局单调递增事务id(zxid,也就是类似于paxos算法的编号n),广播协议提议
3.Follower处理提议,作出反馈(也就是承诺只接受比现在的n编号大的
4.leader收到过半数的反馈,广播commit,把数据彻底持久化(和2pc不同的是,2pc是要等待所有小弟反馈同意)
5.leader对原来转发事务的followe进行响应,follower也顺带把响应返回给客户端
还记得我们说过zookeeper比较适合读比较多,写比较少的场景吗,为什么我们说它效率高,我们可以知道,所有的事务请求,必须由一个全局唯一的服务器进行协调,这个服务器也就是现在的leader,leader服务器把客户端的一个写请求事务变成一个提议,这个提议通过我们的原子广播协议广播到我们服务器的其他节点上去,此时这个协议的编号,也就是zxid肯定是最大的。
由于我们的zxid都是由leader管理的,在上一节也是讲过,leader之所以能成为leader,本来就是因为它的zxid最大,此时的事务请求过来,leader的zxid本身最大的基础上再递增,这样新过来的事务的zxid肯定就是最大的。那么一连串的事务又是如何在leader中进行处理,leader中会内置一个队列,队列的作用就是用来保证有序性(zxid有序且队列先进先出原则),所以后面来的事务不可能跳过前面来的事务。所以这也是ZAB协议的一个重要特性---有序性
② Leader崩溃时的举措
leader服务器崩溃,或者说由于网络原因导致leader失去了与过半follower的联系,那么就会进入崩溃恢复模式
我们回到上一节配置集群节点配置时,提到了在配置各节点时
server.id = host:port:port
id:通过在各自的dataDir目录下创建一个myId的文件来为每台机器赋予一个服务器id,这个id我们一般用基数数字表示
两个port:第一个follower用来连接到leader,第二个用来选举leader
此时第二个port,就是崩溃恢复模式要使用到的
1.ZAB协议规定如果一个事务proposal(提案)在一台机器上被处理成功,那么应该在所有的机器上都被处理成功,
哪怕这台机器已经崩溃或者故障
2.ZAB协议确保那些已经在leader服务器上提交的事务最终被所有服务器都提交
3.ZAB协议确保丢弃那些只在leader服务器上被提出的事务
所以此时我们ZAB协议的选举算法应该满足:确保提交已经被leader提交的事务proposal,同时丢弃已经被跳过的事务proposal
如果让leader选举算法能够保证新选举出来的leader拥有集群中所有机器的最高zxid的事务proposal,那么就可以保证这个新选举出来的leader一定具有所有已经提交的提案,同时如果让拥有最高编号的事务proposal的机器来成为leader,就可以省去leader检查事务proposal的提交和丢弃事务proposal的操作。
③ ZAB协议的数据同步
leader选举完成后,需要进行follower和leader的数据同步,当半数的follower完成同步,则可以开始提供服务。
数据同步过程
leader服务器会为每一个follower服务器都准备一个队列,并将那些没有被各follower服务器同步的事务
以proposal的形式逐个发送给follower服务器,并在每一个proposal消息后面接着发送一个commit消息,
表示该事务已经进行提交,直到follower服务器将所有尚未同步的事务proposal都从leader上同步
并成功提交到本地数据库中,leader就会将该follower加入到可用follower中
④ ZAB协议中丢弃事务proposal
zxid=高32位+低32位=leader周期编号+事务proposal编号
事务编号zxid是一个64位的数字,低32位是一个简单的单调递增的计数器,针对客户端的每一个事务请求,leader产生新的事务proposal的时候都会对该计数器进行+1的操作,高32位代表了leader周期纪元的编号。
每当选举产生一个新的leader,都会从这个leader服务器上取出其本地日志中最大事务proposal的zxid,并从zxid解析出对应的纪元值,然后对其进行+1操作,之后以此编号作为新的纪元,并将低32位重置为0开始生产新的zxid。
基于此策略,当一个包含了上一个leader周期中尚未提交过的事务proposal的服务器启动加入到集群中,发现此时集群中已经存在leader,将自身以follower角色连接上leader服务器后,leader服务器会根据自身最后被提交的proposal和这个follower的proposal进行比对,发现这个follower中有上一个leader周期的事务proposal后,leader会要求follower进行一个回退操作,回到一个确实被集群过半机器提交的最新的事务proposal
⑤ zookeeper的可配置参数
可以从官网上了解zookeeper的可配置参数
zookeeper.apache.org/doc/current…
虽然是全英,但是当大家有需要使用到它们的时候,那英文就自然不成问题了是吧
内容二:zookeeper的典型应用场景
数据发布订阅
命名服务
master选举
集群管理
分布式队列
分布式锁
1.分布式队列的应用场景
① 业务解耦
实现应用之间的解耦,这时所有的下游系统都订阅队列,从而获得一份实时完整的数据
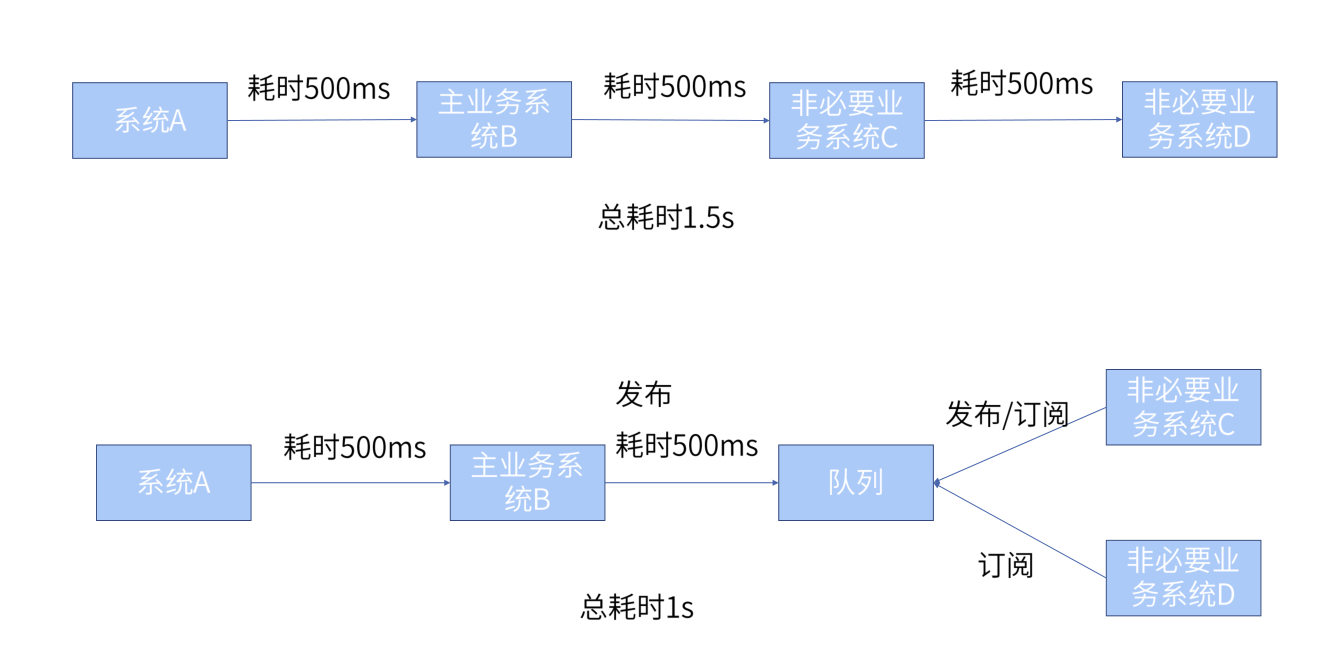
解耦的应用非常广泛,比如我们常见的发货系统和订单系统,以前业务串行的时候,发货系统一定要等订单系统生成完对应的订单才会进行发货。这样如果订单系统崩溃,那发货系统也无法正常运作,引入消息队列后,发货系统是正常处理掉发货的请求,再把已发货的消息存入消息队列,等待订单系统去更新并生成订单,但是此时,订单系统就算崩溃掉,我们也不会一直不发货。
② 异步处理
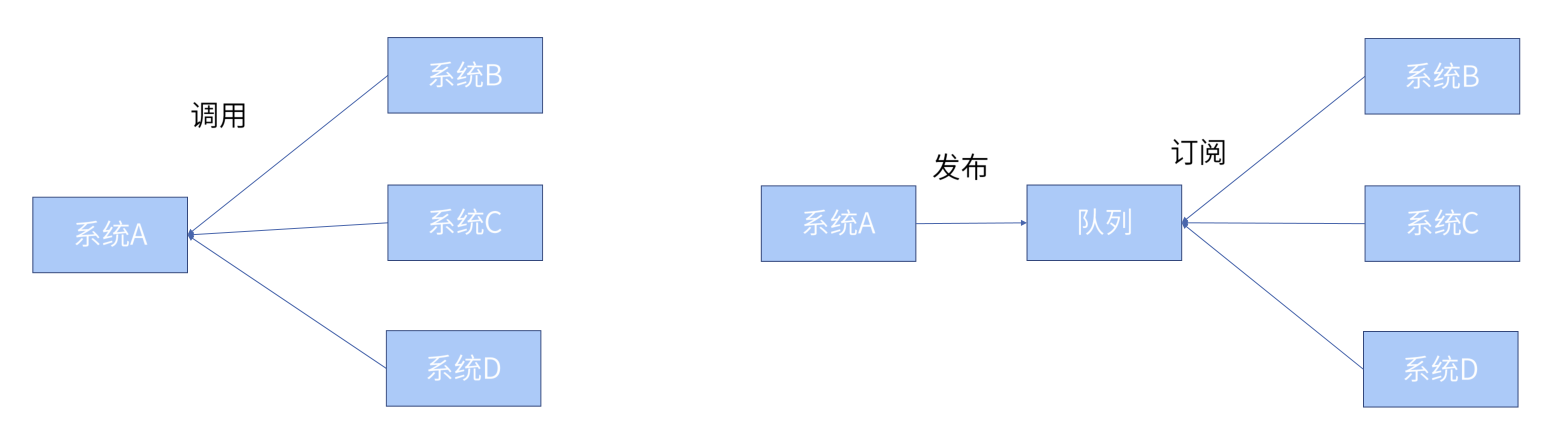
可以看到在此场景中队列被用于实现服务的异步处理,这样做的好处在于我们可以更快地返回结果和减少等待,实现步骤之间的并发,提升了系统的总体性能等
③ 流量削峰
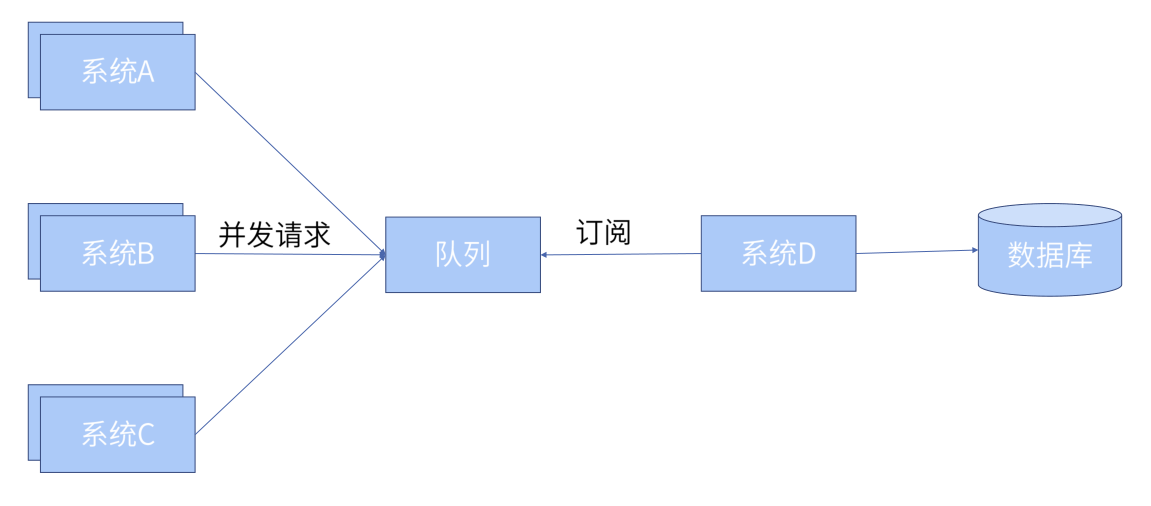
2.zk的分布式队列
① 逻辑分析
顺序节点的应用,类似于我们在用zookeeper实现分布式锁的时候如何去处理惊群效应的做法。 且根据队列的特点:FIFO(先进先出),入队时我们创建顺序节点(ps:为什么上面我们是用了顺序节点而不是说是临时顺序节点,是因为我们根本不考虑客户端挂掉的情况)并把元素传入队列,出队时我们取出最小的节点。使用watch机制来监听队列的状态,在队列满时进行阻塞,在队列空时进行写入即可。
入队操作
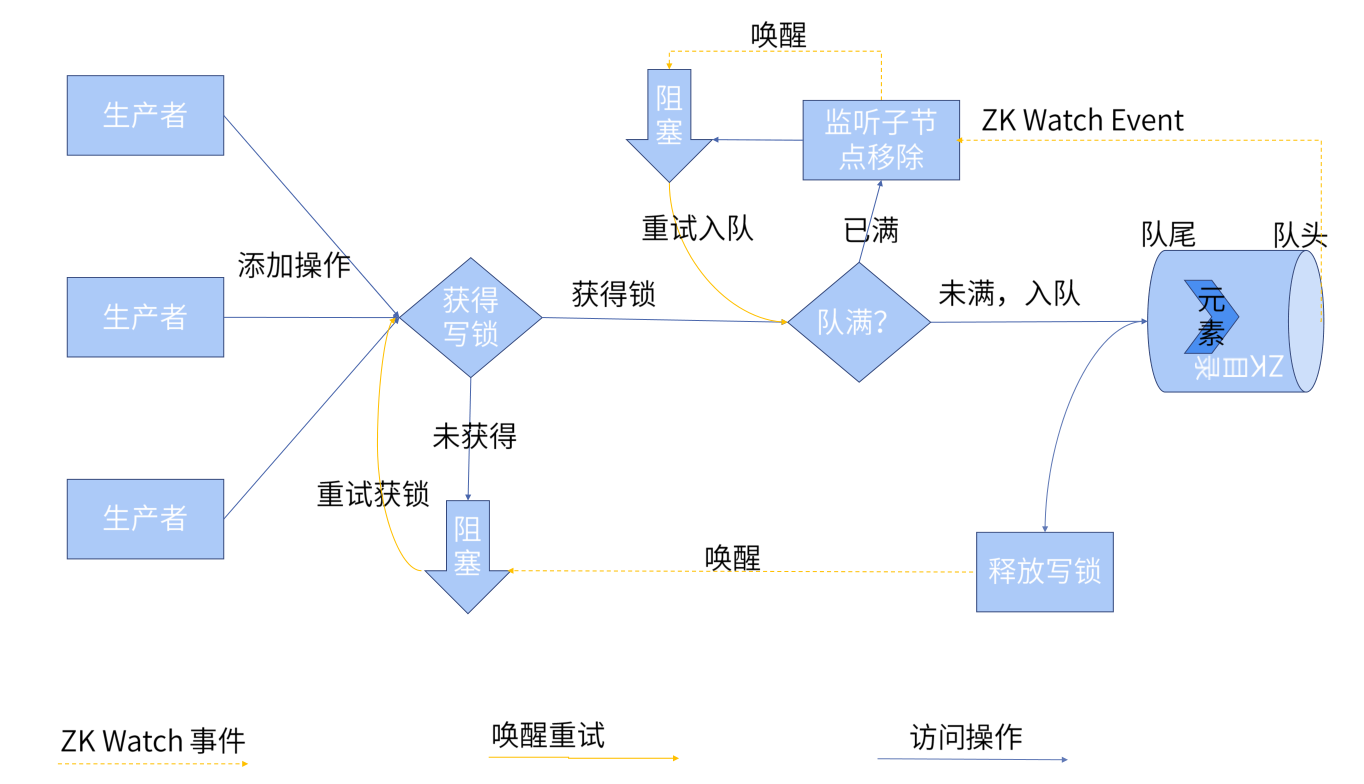
如上图,我们生产者需要对资源进行访问时,会申请获取一个分布式锁,如果未成功抢占锁,就会进行阻塞,抢到锁的生产者会尝试把任务提交到消息队列,此时又会进行判断,如果队列满了,就监听队列中的消费事件,当有消费队列存在空位时进行入队,未消费时阻塞。入队时它会进行释放锁的操作,唤醒之前抢占锁的请求,并让之后的生产者来获取。
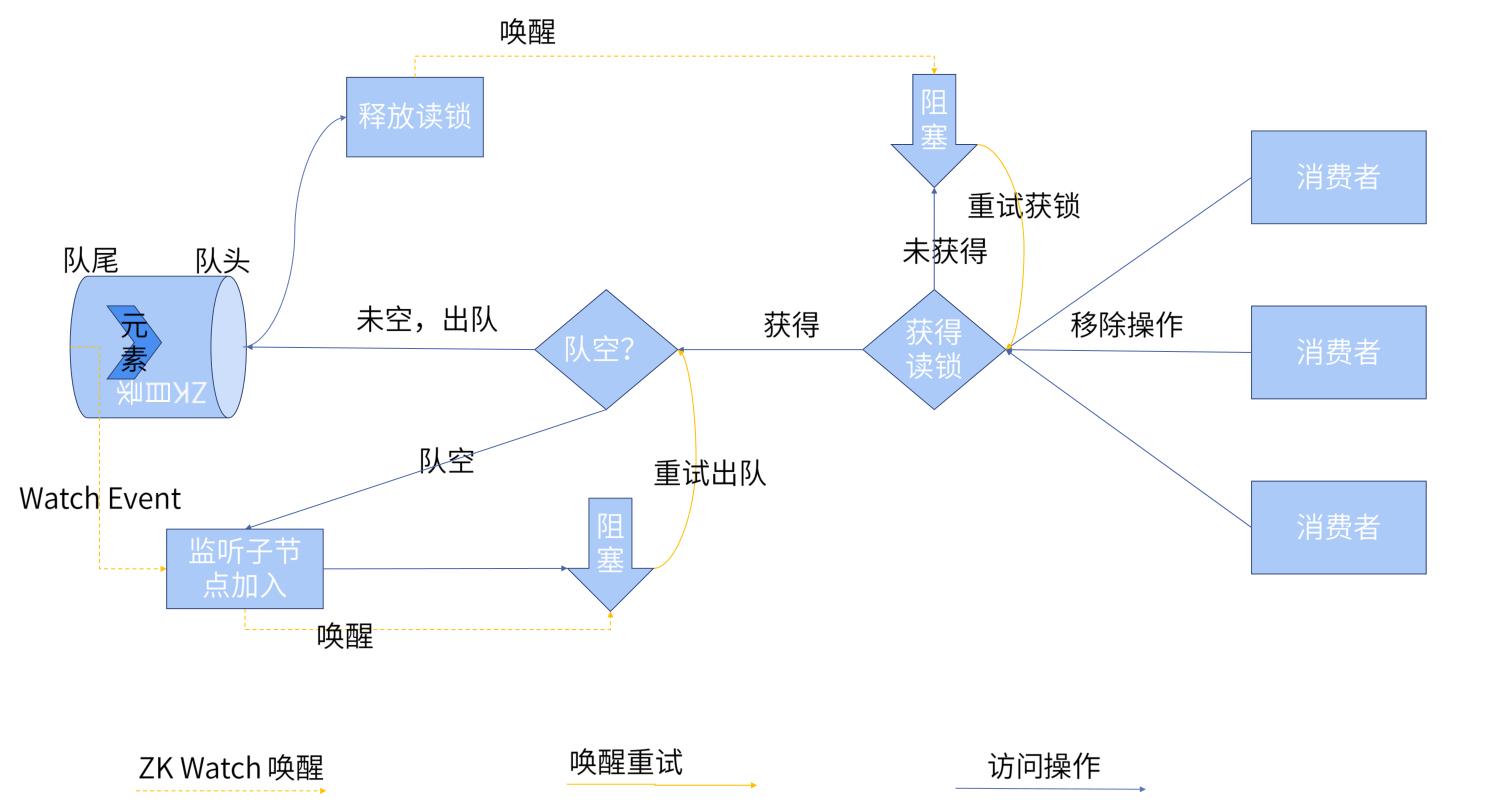
出队操作
出队和入队的机制是十分相似的。
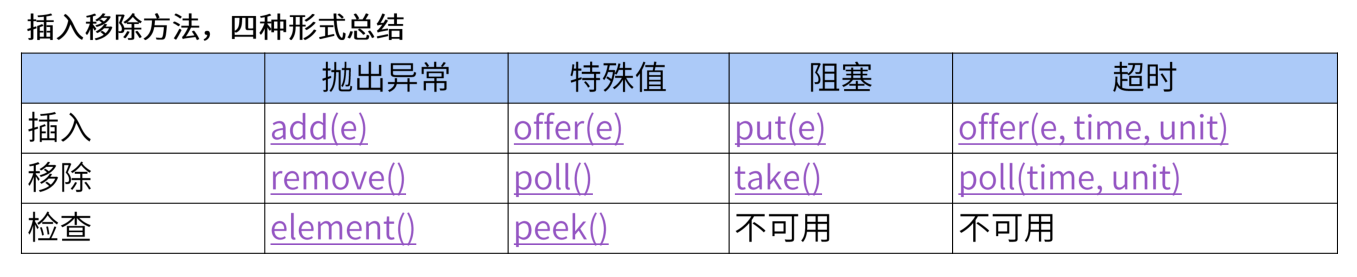
② JDK阻塞队列操作
阻塞队列:BlockingQueue---线程安全的阻塞队列
它以4种形式出现,对于不能立即满足但是在将来某一时刻可能满足的操作,4种形式的处理方式皆不同
1.抛出一个异常
2.返回一个特殊值,true or false
3.在操作可以成功前,无限阻塞当前线程
4.放弃前只在给定的最大时间限制内阻塞
我们将会实现这个阻塞队列接口来实现我们的分布式队列
内容三:分布式队列的代码实现
public class ZkDistributeQueue extends AbstractQueue<String> implements BlockingQueue<String> , java.io.Serializable
继承了AbstractQueue,可以省略部分基础实现
① 基本的配置信息及使用到的参数
/**
* zookeeper客户端操作实例
*/
private ZkClient zkClient;
/**
* 定义在zk上的znode,作为分布式队列的根目录。
*/
private String queueRootNode;
private static final String default_queueRootNode = "/distributeQueue";
/**队列写锁节点*/
private String queueWriteLockNode;
/**队列读锁节点*/
private String queueReadLockNode;
/**
* 子目录存放队列下的元素,用顺序节点作为子节点。
*/
private String queueElementNode;
/**
* ZK服务的连接字符串,hostname:port形式的字符串
*/
private String zkConnUrl;
private static final String default_zkConnUrl = "localhost:2181";
/**
* 队列容量大小,默认Integer.MAX_VALUE,无界队列。
* 注意Integer.MAX_VALUE其实也是有界的,存在默认最大值
**/
private static final int default_capacity = Integer.MAX_VALUE;
private int capacity;
/**
* 控制进程访问的分布式锁
*/
final Lock distributeWriteLock;
final Lock distributeReadLock;
首先我们需要一个zkClient的客户端,然后queueRootNode是分布式队列的存放元素的位置,指定了一个默认的根目录default_queueRootNode,把队列中的元素存放于/distributeQueue下,写锁节点代表往队列中存放元素,读锁节点代表从队列中去取元素,这个设计简单点来说就是,queueRootNode作为最大的目录,其下有3个子目录,分别是queueWriteLockNode,queueReadLockNode和queueElementNode,其他的就是一些需要使用到的配置信息
② 构造器
提供两个构造方法,一个为使用默认参数实现,另外一个是自定义实现
public ZkDistributeQueue() {
this(default_zkConnUrl, default_queueRootNode, default_capacity);
}
public ZkDistributeQueue(String zkServerUrl, String rootNodeName, int initCapacity) {
if (zkServerUrl == null) throw new IllegalArgumentException("zkServerUrl");
if (rootNodeName == null) throw new IllegalArgumentException("rootNodeName");
if (initCapacity <= 0) throw new IllegalArgumentException("initCapacity");
this.zkConnUrl = zkServerUrl;
this.queueRootNode = rootNodeName;
this.capacity = initCapacity;
init();
distributeWriteLock = new ZkDistributeImproveLock(queueWriteLockNode);
distributeReadLock = new ZkDistributeImproveLock(queueReadLockNode);
}
此时在我们分布式锁的构造器中,createPersistent()的参数true是指如果我父目录queueRootNode并没有事先创建完成,这个方法会自动创建出父目录,这样就不怕我们在跑程序之前遗漏掉一些创建文件结构的工作
public ZkDistributeImproveLock(String lockPath) {
if(lockPath == null || lockPath.trim().equals("")) {
throw new IllegalArgumentException("patch不能为空字符串");
}
this.lockPath = lockPath;
client = new ZkClient("localhost:2181");
client.setZkSerializer(new MyZkSerializer());
if (!this.client.exists(lockPath)) {
try {
this.client.createPersistent(lockPath, true);
} catch (ZkNodeExistsException e) {
}
}
}
③ 初始化队列信息的init()方法
重新定义好读锁写写锁和任务存放路径,然后把zkClient连接上,创建queueElementNode作为任务元素目录,参数true上文作用已经提到了
/**
* 初始化队列信息
*/
private void init() {
queueWriteLockNode = queueRootNode+"/writeLock";
queueReadLockNode = queueRootNode+"/readLock";
queueElementNode = queueRootNode+"/element";
zkClient = new ZkClient(zkConnUrl);
zkClient.setZkSerializer(new MyZkSerializer());
if (!this.zkClient.exists(queueElementNode)) {
try {
this.zkClient.createPersistent(queueElementNode, true);
} catch (ZkNodeExistsException e) {
}
}
}
④ 使用put()方法进行队列元素入队操作
// 阻塞操作
@Override
public void put(String e) throws InterruptedException {
checkElement(e);
//尝试去获取分布式锁
distributeWriteLock.lock();
try {
if(size() < capacity) { // 容量足够
enqueue(e);
System.out.println(Thread.currentThread().getName() + "-----往队列放入了元素");
}else { // 容量不够,阻塞,监听元素出队
waitForRemove();
put(e);
}
} finally {
//释放锁
distributeWriteLock.unlock();
}
}
checkElement()方法是一个简单的参数检查,我们也可以定义有关于znode的命名规范的一些检查,不过一般情况下只要是String类型的参数都是没有问题的
private static void checkElement(String v) {
if (v == null) throw new NullPointerException();
if("".equals(v.trim())) {
throw new IllegalArgumentException("不能使用空格");
}
if(v.startsWith(" ") || v.endsWith(" ")) {
throw new IllegalArgumentException("前后不能包含空格");
}
}
size()方法也很简单,就是先取得父目录然后调用zkClient自带的countChildren()方法得出结果返回即可
public int size() {
int size = zkClient.countChildren(queueElementNode);
return size;
}
在从零开始的高并发(二)--- Zookeeper实现分布式锁中已经对等待移除的这个方法进行解释,主要就是通过subscribeChildChanges()监听子节点的数据变化,在size() < capacity条件成立时,就会唤醒等待队列,而当size() >= capacity,就会判断队列已经被填满,从而进行阻塞,
/**
* 队列容量满了,不能再插入元素,阻塞等待队列移除元素。
*/
private void waitForRemove() {
CountDownLatch cdl = new CountDownLatch(1);
// 注册watcher
IZkChildListener listener = new IZkChildListener() {
@Override
public void handleChildChange(String parentPath, List<String> currentChilds) throws Exception {
if(currentChilds.size() < capacity) { // 有任务移除,激活等待的添加操作
cdl.countDown();
System.out.println(Thread.currentThread().getName() + "-----监听到队列有元素移除,唤醒阻塞生产者线程");
}
}
};
zkClient.subscribeChildChanges(queueElementNode, listener);
try {
// 确保队列是满的
if(size() >= capacity) {
System.out.println(Thread.currentThread().getName() + "-----队列已满,阻塞等待队列元素释放");
cdl.await(); // 阻塞等待元素被移除
}
} catch (InterruptedException e) {
e.printStackTrace();
}
zkClient.unsubscribeChildChanges(queueElementNode, listener);
}
在waitForRemove()方法执行后,我们的等待线程被唤醒,这时重新执行put(e),尝试重新入队
入队操作由enqueue(e)来完成,就是创建顺序节点的步骤
/**
* 往zk中添加元素
* @param e
*/
private void enqueue(String e) {
zkClient.createPersistentSequential(queueElementNode+"/", e);
}
⑤ 消费操作take
@Override
public String take() throws InterruptedException {
//老套路,先获取锁
distributeReadLock.lock();
try {
List<String> children = zkClient.getChildren(queueElementNode);
if(children != null && !children.isEmpty()) {
//先对children进行一个排序,然后取出第一个,也就是最小编号的节点
children = children.stream().sorted().collect(Collectors.toList());
String takeChild = children.get(0);
String childNode = queueElementNode+"/"+takeChild;
String elementData = zkClient.readData(childNode);
//进行出队操作
dequeue(childNode);
System.out.println(Thread.currentThread().getName() + "-----移除队列元素");
return elementData;
}else {
//如果children本来就是空的,那就是没有元素需要消费,那就继续等待
waitForAdd(); // 阻塞等待队列有元素加入
return take();
}
} finally {
distributeReadLock.unlock();
}
}
//出队操作
private boolean dequeue(String e) {
boolean result = zkClient.delete(e);
return result;
}
附:生产者和消费者的模拟
① 生产者
模拟了两台服务器,两个并发,每睡3秒钟就往消息队列put
public class DistributeQueueProducerTest {
public static final String queueRootNode = "/distributeQueue";
public static final String zkConnUrl = "localhost:2181";
public static final int capacity = 20;
public static void main(String[] args) {
startProducer();
}
public static void startProducer() {
// 服务集群数
int service = 2;
// 并发数
int requestSize = 2;
CyclicBarrier requestBarrier = new CyclicBarrier(requestSize * service);
// 多线程模拟分布式环境下生产者
for (int i = 0; i < service; i++) {
new Thread(new Runnable() {
public void run() {
// 模拟分布式集群的场景
BlockingQueue<String> queue = new ZkDistributeQueue(zkConnUrl, queueRootNode, capacity);
System.out.println(Thread.currentThread().getName() + "---------生产者服务器,已准备好---------------");
for(int i =0; i < requestSize; i++) {
new Thread(new Runnable() {
@Override
public void run() {
try {
// 等待service台服务,requestSize个请求 一起出发
requestBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
while(true) {
try {
queue.put("123");
System.out.println(Thread.currentThread().getName() + "-----进入睡眠状态");
TimeUnit.SECONDS.sleep(3);
System.out.println(Thread.currentThread().getName() + "-----睡眠状态,醒来");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}, Thread.currentThread().getName()+"-request-" + i).start();
}
}
}, "producerServer-" + i).start();
}
try {
Thread.currentThread().join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
② 消费者
public class DistributeQueueConsumerTest {
public static void main(String[] args) {
satrtConsumer();
}
public static void satrtConsumer() {
// 服务集群数
int service = 2;
// 并发数
int requestSize = 2;
CyclicBarrier requestBarrier = new CyclicBarrier(requestSize * service);
// 多线程模拟分布式环境下消费者
for (int i = 0; i < service; i++) {
new Thread(new Runnable() { // 进程模拟线程
public void run() {
// 模拟分布式集群的场景
BlockingQueue<String> queue = new ZkDistributeQueue(zkConnUrl, queueRootNode, capacity);
System.out.println(Thread.currentThread().getName() + "---------消费者服务器,已准备好---------------");
for(int i =0; i < requestSize; i++) { // 操作模拟线程
new Thread(new Runnable() {
@Override
public void run() {
try {
// 等待service台服务,requestSize个请求 一起出发
requestBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
while(true) {
try {
queue.take();
System.out.println(Thread.currentThread().getName() + "-----进入睡眠状态");
TimeUnit.SECONDS.sleep(3);
System.out.println(Thread.currentThread().getName() + "-----睡眠状态,醒来");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}, Thread.currentThread().getName()+"-request-" + i).start();
}
}
}, "consummerServer-" + i).start();
}
try {
Thread.currentThread().join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
执行结果
① 先执行生产者
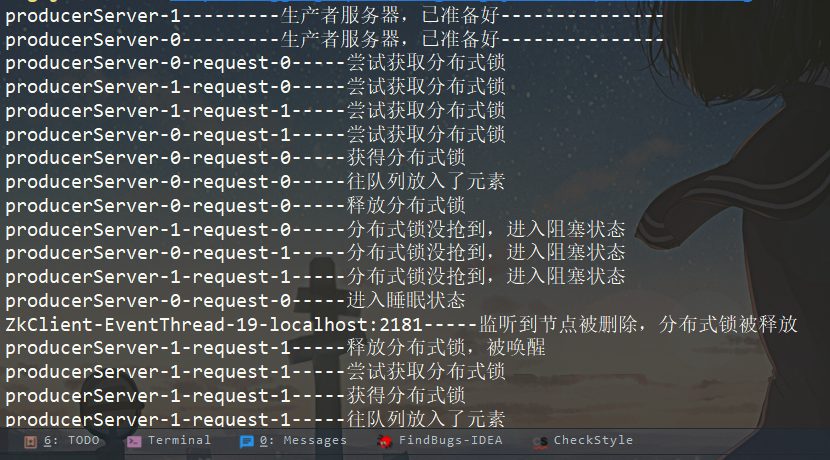
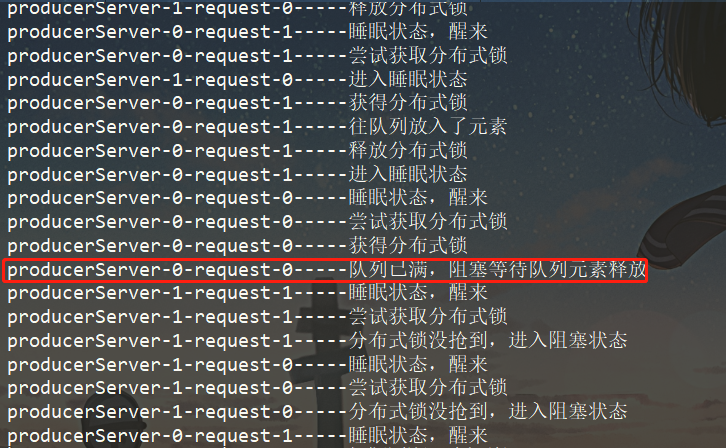
此时没有消费者去进行消费,所以队列没一下子就满了,我们需要注意,阻塞的不仅仅是队列,分布式锁也被阻塞了。
② 启动消费者
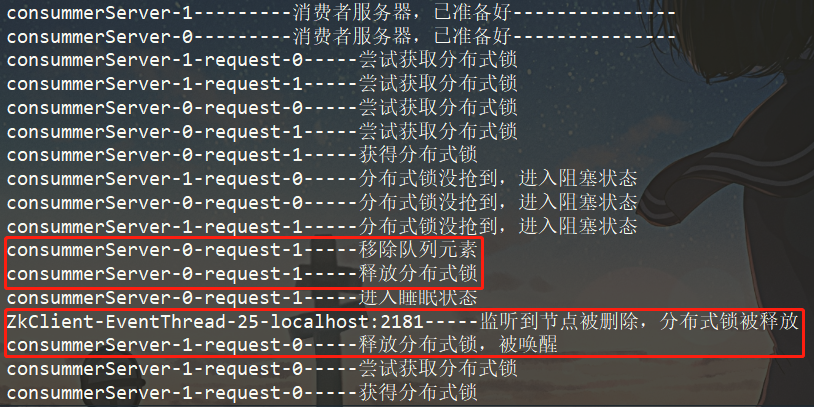
基本上是生产者放入一个消费者就消费一个的状态。从而证明该分布式队列已经正常工作了。
finally
篇幅和上次一样比较长,主要是补充了上次没讲到的集群的ZAB协议和zookeeper的其中一个分布式队列的应用场景,其实在日常开发中使用zookeeper来实现队列是基本不会发生的,比较常见的都是activeMQ,rabbitMQ,kafka等等。不过仍然有必要去了解队列的基本工作思路。我们也相当于自己手写了一个拥有基础功能的MQ
你一定听过dubbo+zookeeper的万金油组合配置中心到底是什么?zookeeper又是如何依靠自身机制来实现配置中心的?
下一篇:从零开始的高并发(五)--- Zookeeper的经典应用场景2
