

HBaseCon 没来参加怎么办?
三个Track没法同时听,分身乏术怎么办?
没关系~!“小米云技术”将用三期时间带你回顾
全部精华~!
Track 2:Ecology and Solution
在这个 Track,大家主要基于 HBase 根据实际需求构建系统。从横向来看,HBase 除了本身可用于 OLTP 之外,还能与 Spark、Solor 以及 Kafka 等系统集成起来提供 OLAP 的方案,阿里巴巴的云数据库团队提供了这样的例子,来自宝岛台湾的成功大学使用统一的协议用于不同存储系统之间的传输也是一个有意思的实践。从纵向来看,基于 HBase 构建时序、空间以及图数据库都是可行的,小米、阿里以及 Nebula 等公司介绍了这些方面的实践,这也显示了HBase 作为存储系统的通用性以及高性能。另外,大家对 HBase 查询优化的需求也是多方面的,既有阿里巴巴的基于 Phoenix 的查询优化,也有光大银基于协处理器实现了一个轻量级的二级索引系统。那么接下来小编将依次介绍Track2中的7个部分:
1、Big Data NoSQL System:Apsara DB Hbase and Spark
PPT下载链接:http://t.cn/AilB4m6R
来自阿里巴巴的 Wei Li 介绍了基于阿里巴巴云 HBase 构建的融合了计算、存储和检索以及在线和离线的的大数据中台解决方案,同时结合云上的弹性伸缩能力,节省成本。这是ApsaraDB HBase X-Pack 的架构图。
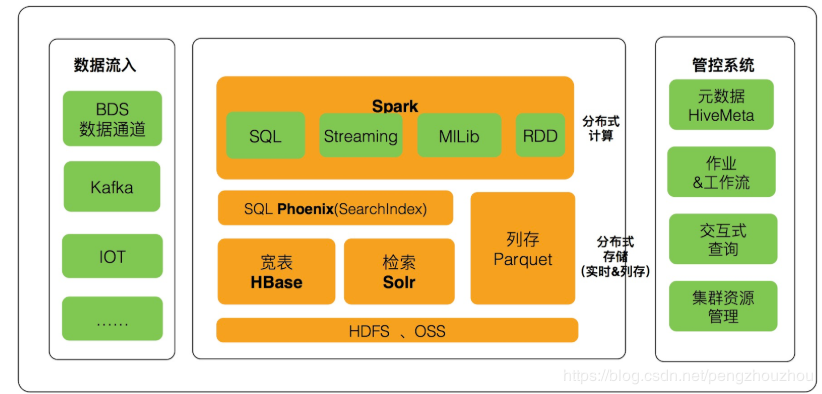
针对扫描大表,造成在线的 HBase 服务不稳定的问题,他们做了一个工作是把在线存储和离线分析使用的数据分离开来,通过一键归档把离线的数据转成列存的格式,带来性能十倍以上的提升,同时也不会影响 HBase 在线服务的稳定性,列存的方式是把源数据通过WAL同步到Spark 集群,存储成列的方式。数据归档完成之后,处理完的数据还需要写回到 HBase,这些数据的具体细节没有说明,可能跟业务有关,猜测是一些经过处理之后的聚合类数据等。他们没有通过传统的使用 HBase API 的方式,而是直接加载 HFile.最后一点是成本,使用云端数据库能带来两个方面的成本节省。一个是计算资源,一个是存储。计算资源是因为不同的业务有不同的波峰和波谷;存储是因为可以利用云上的廉价存储。最后他根据具体的几个 case 详细讲述了这套方案的案例。
2、OpenTSDB at Xiaomi
PPT下载链接:http://t.cn/AilBbhjp
来自小米的 Junhong Xu 首先介绍了时序数据和 OPenTSDB,然后详细介绍了 OpenTSDB 内部的实现以及底层的存储模型,最后是他们在实践中一些比较重要的配置项以及注意的问题。第二部分详细介绍了 OpenTSDB 迁移到 Kubernetes 的实践,包括需求、整个的流程和结构,每个组件的作用和配置,他们还在此基础上把它服务化,提供一个管理系统供用户申请、使用和管理。
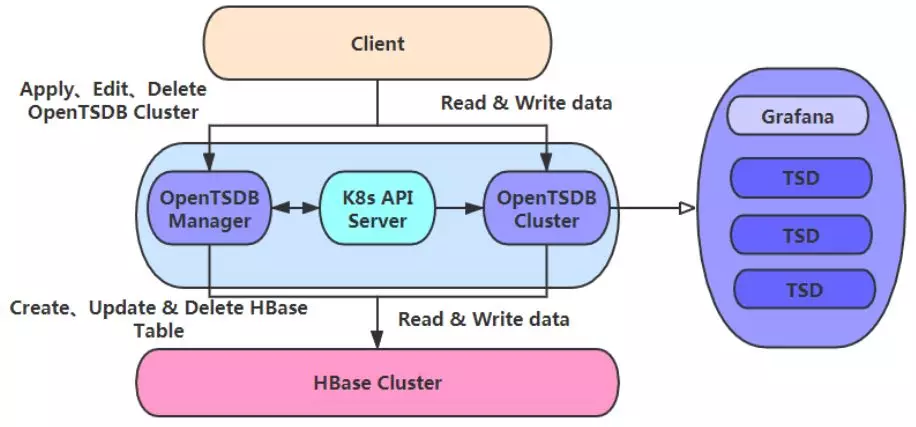
相比之前的物理机搭建流程,新流程的效率从几个小时缩减到几分钟。最后是一些内部使用OpenTSDB 的案例。
3、Phoenix Improvements and Practices on Cloud HBase at Alibaba
PPT下载链接:http://t.cn/AilBbxCh
来自阿里巴巴的 Yun Zhang 介绍在阿里,他们是把 Phoenix 当做数据库来做的,既提供了直接访问下层的 HBase 能力,也提供了基于Solr构建二级索引快速访问HBase和搜索的能力,类似于传统数据库或者一些 New SQL 操作型分析和即时查询,响应时间是毫秒到秒级。

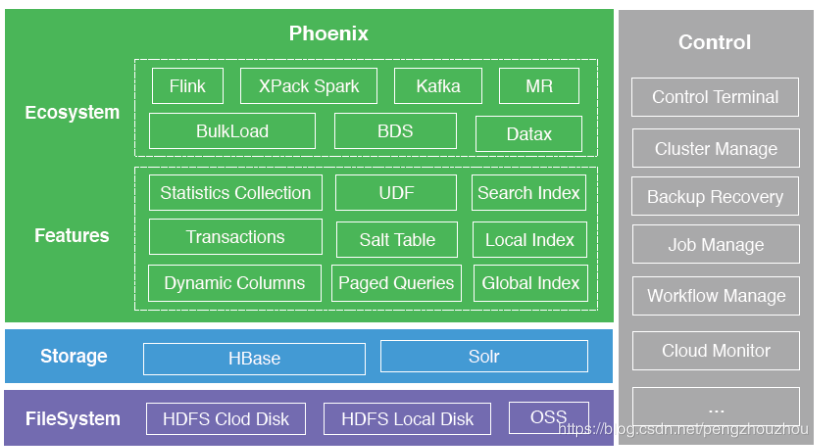
Phoenix 在数据库主要面向 TB、PB 级的数据体量,查询延时在毫秒和秒级的即时响应场景,另外过滤后的数据量不能太大,查询模式不能太多,便于 Phoenix 建立二级索引。另外,由于稳定性、维护性的问题,他们把 Phoenix 的重客户端模式演变成了轻客户端模式。最后他结合实际案例给出了一些最佳实践。
4、Pharos as a Pluggable Secondary Index Component
PPT下载链接:http://t.cn/Ailriayg
来自光大银行的 Lei Wang,主要内容是他们自己设计了一个 HBase 的二级索引系统,这个系统的主要作用是提高查询的效率。他们的设计目标是希望降低侵入性同时保证架构的简洁。由于需要排序等全局性的功能,所以客户端除了提供一个自定义的Condition查询条件外还需要提供额外的全局协调者的功能。

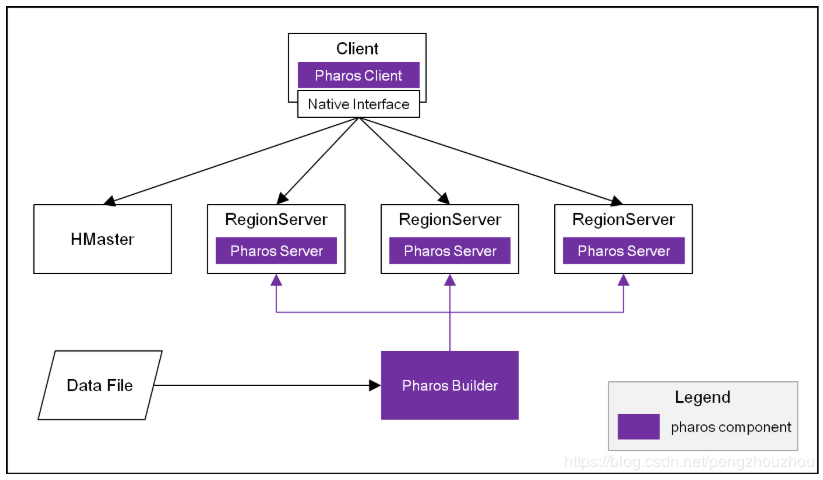
他们这个设计有趣的地方是通过 rowkey 的设计和影子 Column Family 使索引文件与数据文件处于同一个 region 内,为了防止 Region Split 造成索引与数据文件不一致的问题,他们使用Index Builder 来基于数据重新生成索引。接下来他分别介绍了排序、分页和缓存的实现。最后展望了一些未来的规划,基于谷歌的 Percolator 提供事务的一致性、Bitmap 索引以及 CBO优化、与 Presto 集成等。
5、Bridging the Gap between Big Data System Software Stack and Applications:The Case of Distributed Storage Service for Semiconductor Wafer Fabrication Foundries
PPT下载链接:http://t.cn/AilriTRG
来自台湾成功大学的 Hung-chang Hsiao 带来的有关 HBase 应用于半导体晶圆制造行业的例子。

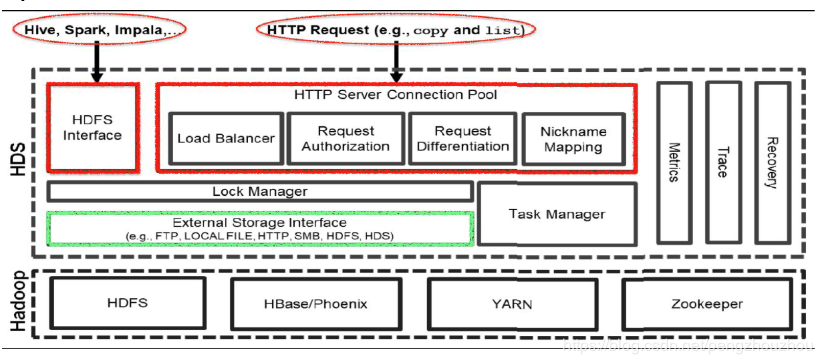
他们提供了一种融合多种不同存储系统的方案,解决了小文件问题,以及设计一个统一的协议使不同的存储系统之间和兼容以及透明传输,此外他们还设计和实现了一个负载均衡系统,并发表在 IEEE 上。
6、Nebula: A graph DB based on HBase
PPT下载链接:http://t.cn/Ailrirld
接下来是陈恒带来的使用 HBase 实现图数据库Nebula的介绍。

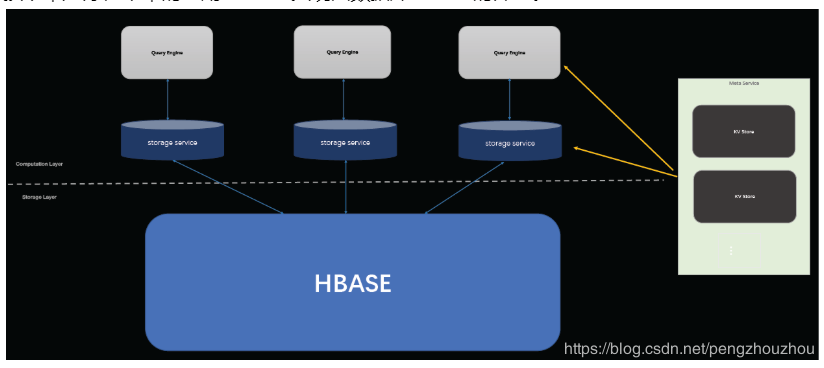
他首先介绍了图数据库是当前很流行的一个数据库,主要用于社交网络和知识图谱等。接下来他介绍了图数据库面临的一些挑战,包括传统的数据库读写带来的读写放大、在线海量数据查询等。然后 他介绍了 Nebula 的一些特点,包括存储于计算分离、类 SQL 查询(但不支持嵌套查询)以及与 MySQL 类似的存储引擎插件等。
7、Spatio-temporal Data Management based on HBase Ganos and its Spark Extension
PPT下载链接:http://t.cn/Ailr6Zh2
最后是阿里巴巴的技术专家 Fei Xiao。首先他介绍了时空数据的背景知识。
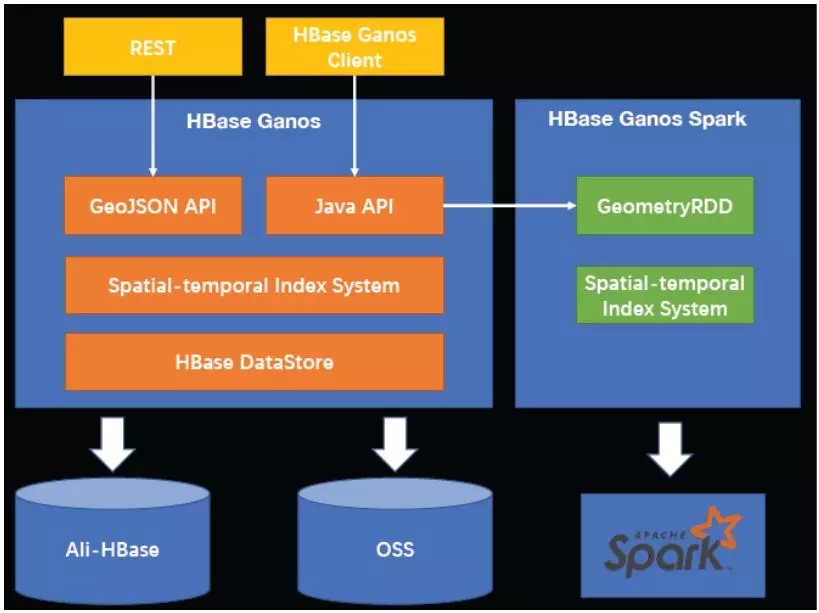
目前阿里内部主要有两条线来做时空数据库,一种是关系型数据库的模式,比如 PolarDB 或者PG,另一种是非关系型数据库。前者功能完备,但支持的数据量以及并发度不高,后者可扩展性较好,但功能没那么完善。接下来他介绍了基于 HBase 实现的时空数据库,并详细介绍了时空索引的原理。时空数据专业性较强,数据量较大,需要一些编码和解码以提高效率,同时也需要一些领域相关的知识。
本文首发于公众号“小米云技术”,转载请注明出处,原文链接:HBaseCon Asia 2019 Track 2 概要回顾
