


0. 前言
现在市面上有非常多介绍Servicemesh概念、架构、方法论以及标准化实现的文章,但是对于Servicemesh应该如何才能被真正有效可靠的落地,我们会面临哪些困难选择,并未太多提及。本文希望从这个角度出发,结合笔者在生产环境落地中的一些经验和踩过的坑,探讨如何才能更好地让系统演进到Servicemesh架构。本文面向对于Servicemesh概念有一定了解或者希望在该领域有所探索的同学。
1. 服务治理理念更迭一瞥
谈论Servicemesh的一些事情之前,我们先来了解一下服务治理的发展史。我们都知道,服务的发展是由单体应用,服务水平分层,服务纵向切割,乃至后续微服务思想的兴起,“两个星期”重构法则和“两张披萨”团队等眼花缭乱的服务拆分方法论充塞你的耳目。这都是些常见的论调,但不是本章节阐述的重点。本章节更关注的是服务治理发展拆分过程中,所必然要面对的一个核心问题—“服务拆分后,之间如何产生联系?”也即:
如何形成复杂服务节点的网络?
限于篇幅,我们来简单回顾下针对该问题的几个重要思潮。
1.1 Server Proxy
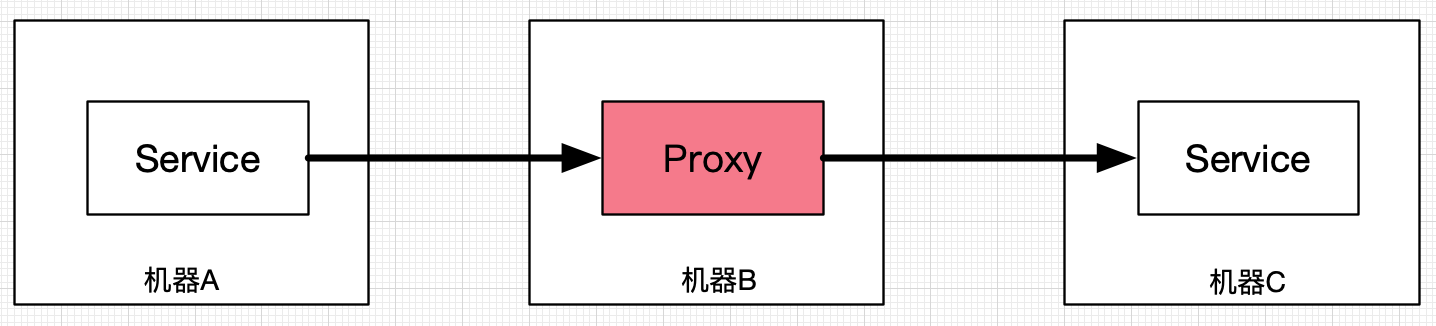
我姑且称之为集中式代理阶段。该阶段也是最朴素的解决方案,多采用集中式的单点服务集群来承担较多服务治理的功能。比如集中式部署 Lvs、Nginx、Haproxy、Tengine、Mycat、Atlas、Codis等等,就是最常见的方式。这种方式的优势在于便于功能的集中维护,且语言无关,上手成本低,所以其实在大中小公司特别是创业公司里面拥有大量受众。但其带来的问题也很明显,以最风靡的域名+Http Rest 调用 + Nginx 组合套装为例,调用链路需要经过 DNS(DNS cache)、KeepAlived、(Lvs)、Nginx 几层。超长的调用链路路和多个单点系统,将会在服务规模上升时引发稳定性和性能问题。在丁丁租房和美团就多次发生类似的单点故障。丁丁租房曾经因为 Nginx、DNS 以及 Codis-Proxy 故障而导致过大面积的业务影响。美团的 DNS、MGW 等都遭遇过类似问题,其进一步因此而推出去内网 Http 调用转为 Thrift 直连的技术项目。总体来看,其必然有用武之地,其更适合初创公司,或者特别强调跨语言的应用场景,Server Proxy 都可作为一个快速上手的解决方案以供使用。但在使用时候,需要对其缺陷有着清晰认识以便于在后续演化中做出正确决策。
1.2 Smart Client
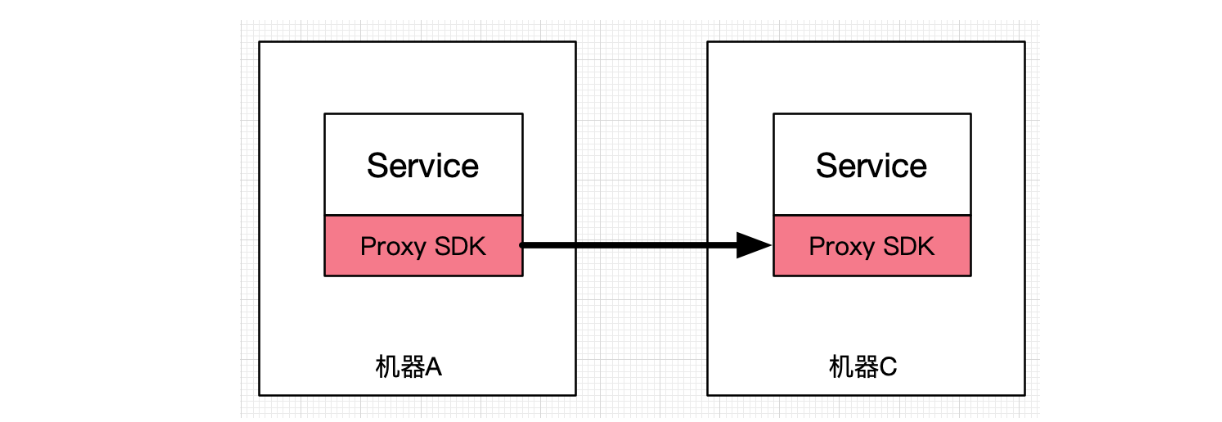
朴素直接的 Server Proxy 带给我们便利的同时,也带给我们大量的问题,而这个时候,为了应对这类问题,Smart Client 快速崛起并绽放出其强大的生命力。我们姑且称之为框架化阶段,该阶段为了解决 Server Proxy 所存在的单点长链路的问题,替代以直连的方式来构建两个节点之间的联系。这一步到位地解决了单点长链路的问题,且能够在直连的基础上,进行更大的性能优化和稳定性的抬升。代表开源产品(服务框架 or Rpc 框架)有比如 Uber 的 Ring-pop、阿里的 Dubbo、蚂蚁的 Sofa-Rpc、当当的 Dubbox、微博的 Motan、点评的 Pigeon/Zebra、百度的brpc/Stargate、Grpc、Thrift等。大的思路即两个:
1. 硬的不行,那就转为软的。硬件式的服务治理行不通,那么就转到软件式的服务治理。
2. 远的不行,那就转为近的。远端集中式部署的方式行不通,那么就拉到和我应用进程里面部署。
如此一来,Server Proxy 思潮中的诸多弊病就被一一化解了。
鼓吹了很久 Smart Client 的优点,那他不存在问题吗?必然还是存在的,而且问题也十分明显和突出。
第一方面,我们知道,微服务领域的气质是趋向自治的。Smart Client 也被成为富客户端,而采取这种方式将很严重地限制我们在技术栈上的选择,换一个语言就需要重新实现一遍基本所有的治理能力,及其之后带来的多套语言下成本增长的维护升级成本,这个对于绝大部分公司来说都是难以承受的负担。Uber 不得不针对 Ring-pop 推出 node 和 go 版,微博的 Motan 也推出了多个语言版本,Grpc、Thrift也没能逃出这个命运。而现在大部分的公司都会混合两种以上的语言进行实际的开发。所以这个问题也必须要进行正视。
第二方面,Smart Client 采用重 SDK 的方式嵌入应用进程进行共存,这将使得服务治理的运维工作和业务应用的维护完全搅到一起。这在现实的工作场景中,给服务治理的运维难度抬升了几个量级,服务治理团队不得不被迫面对多个版本并存的架构代码,以及推行一个版本可能需要半年以上的噩梦。
当然,尽管有以上问题,但是由于目前没有特别成熟的替代方案,Smart Client 目前仍然在高并发大流量的业务场景中占据着主流地位。如果语言能够尽可能收敛的场景也可以使用,比如可以采用 Java 版的 Smart Client,并对于不高的 Nodejs 流量采用 Http Rest 加上域名的方式来做折中的服务治理。
1.3 Local Proxy
Server Proxy 和 Smart Client 都有着无法回避的问题,那么还有其他的解决方案吗?为了回应这一个问题,Local Proxy 应运而生,既然集中式部署有单点问题,富客户端又有耦合的问题,那么为什么不取一个折中呢?这时候的思路就变为:
就近进行进程级别治理。即采用本地进程级别代理的方式,既可以规避集中式单点部署的问题,又可以回避语言相关和应用耦合的问题。
这个思路开始逐步风靡,非常多的治理方案也在这个思想下如雨后春笋冒出。
airbnb 的 SmartStack 采用了四件套完成了整个核心的服务串联治理过程,是一个朴素解决方案。
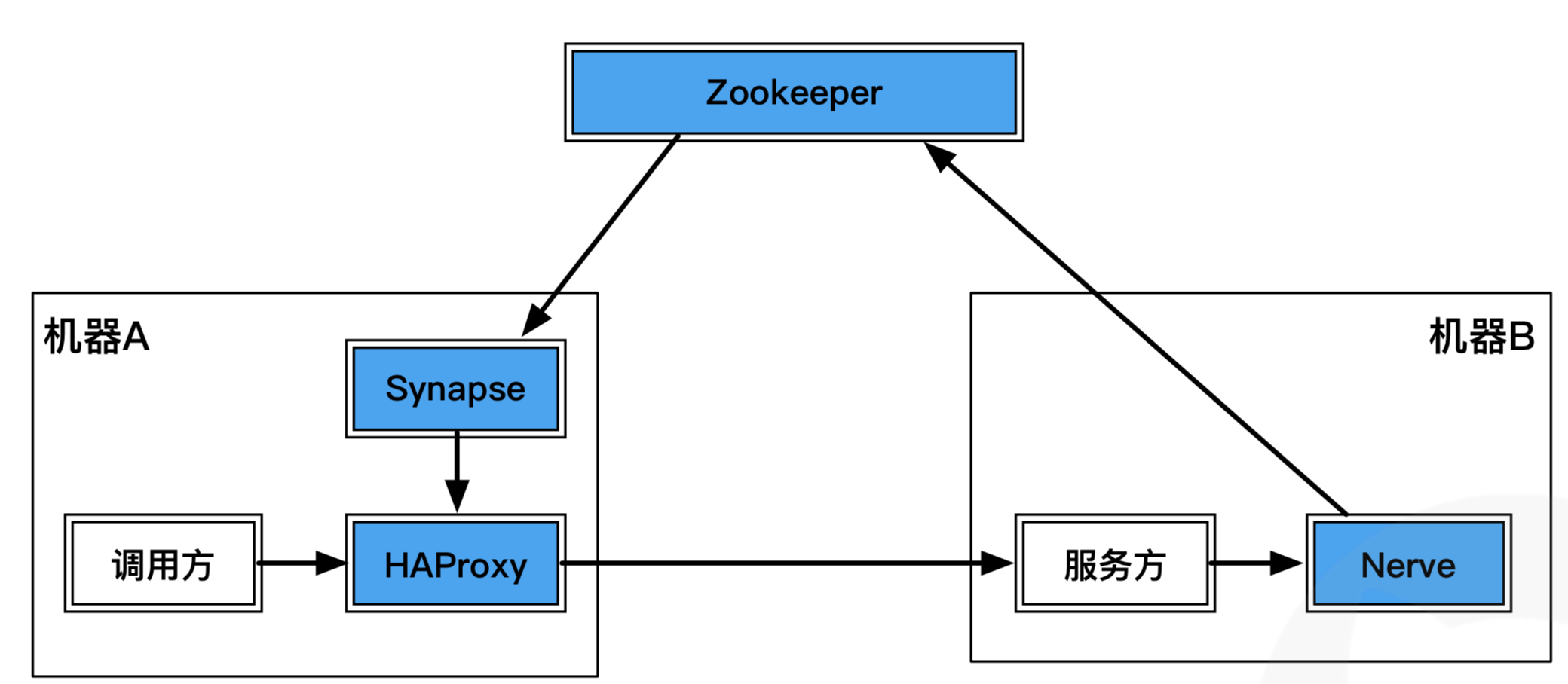
而携程 OSP 也采用类似方式来进行处理,和 airbnb 的差别主要在于将 Synapse 和 Haproxy 的功能整合为了一个 Proxy 来替代。
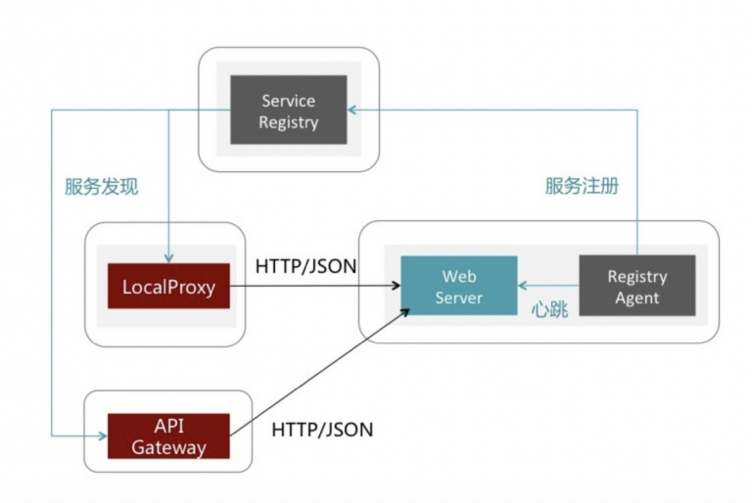
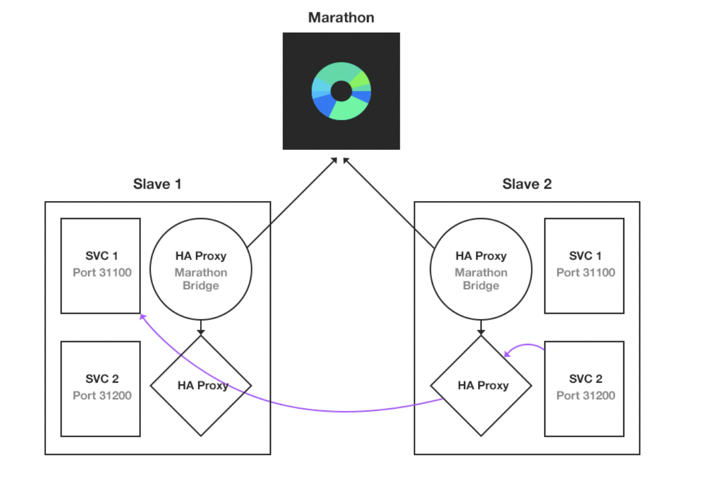
在云领域里面,由于跨语言和运维效率被放在了更为重要的角度来审视,这种思想更是占据了主导的地位,Mesos+Marathon 的云架构中,也有类似方案,采用 Haproxy 进行路由,中控节点会刷新对应的路由信息。
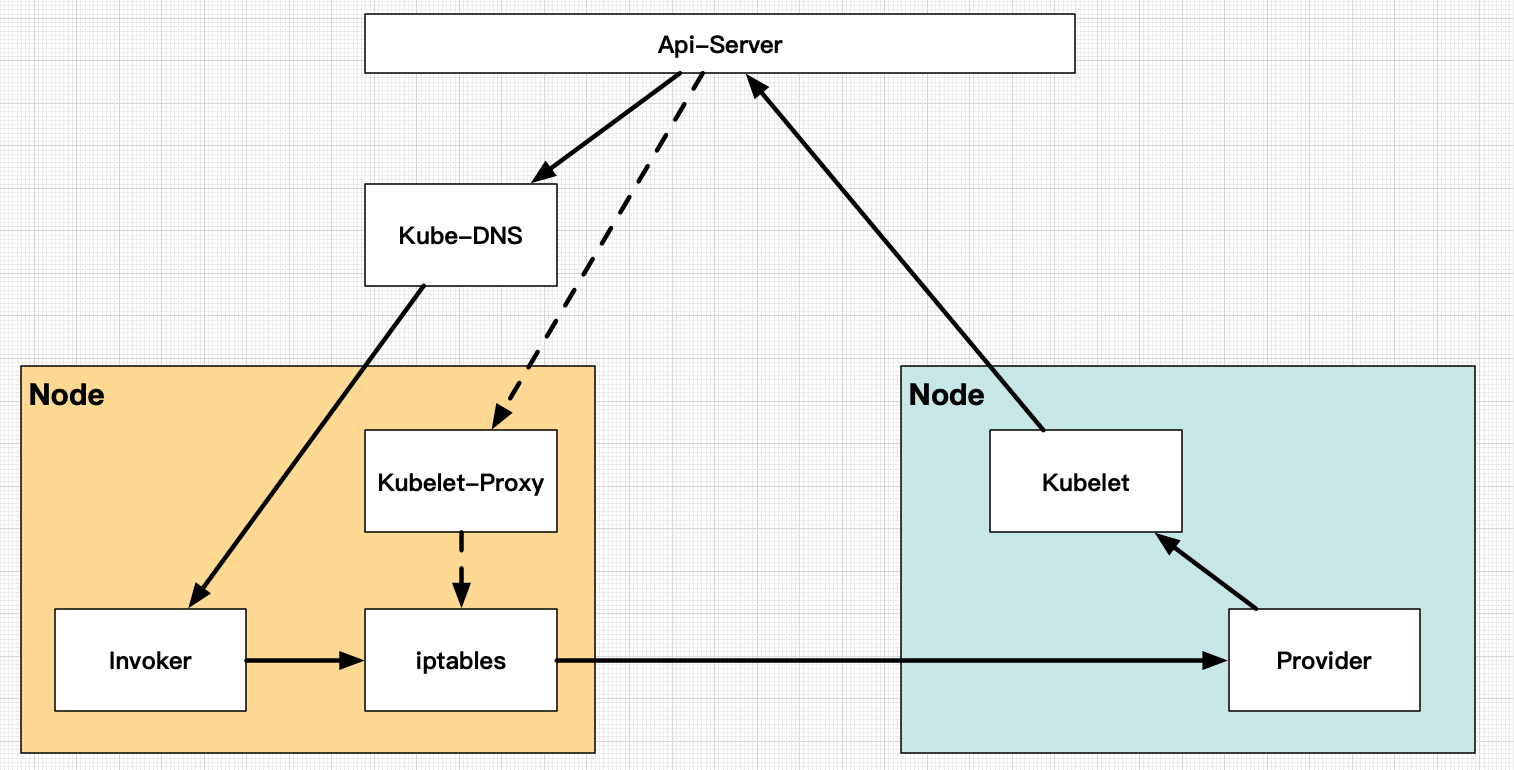
Google 亲儿子 K8s 也是如此,考虑到了 Proxy 的性能问题,进行了折中处理,采用 Iptables 规则注入的方式进行转发(当然,这种方式也有不可回避的问题)
这些方式都有其对应的问题,但是最大的一个问题即:
如何解决其带来的性能下滑。无论 iptables 或者采用 agent 来进行治理、转发、通讯,都会面临着一个绕不过去的问题,在高流量高并发的场景下,其对性能的损耗有多少?相比于众多已经装备有富客户端直连的应用来说,性能的差距有多大?目前已知的部分产品,在高流量下 QPS 和 RT 都有着不小的损耗,有的解决方案甚至能够达到 20% 的性能损耗,这明显在很多场景下是无法接受的。
这时候,Local Proxy 的最后一个杀器 — Servicemesh 正式被推上风口浪尖,2018 年也被称为 Servicemesh 元年。我认为,其理念如下:
1. 牺牲一定的性能和资源,换取服务治理整体的⾼度自治和可运营;
2. 执行和控制分离,数据平面和控制平⾯切割;
3. 虚拟化、标准化、产品化,定义规范。
Servicemesh 从杂乱无章,百家齐放的 Local Proxy 思潮中解放出来,提出了更系统地思考。本文无意对 Servicemesh 做更多概念性的描述,网上已经有相当多类似的文章,此处限于篇幅不展开。于是,有多家巨头合作的 Istio(其本来目的是为了帮助应用更好地上云)的珠玉在前,其他公司也纷纷基于/参考 Isito 做出自己的解决方案:
- 阿里基于 golang 重写了 Envoy 并在这基础上构建了 Sofa-Mosn/Pilot;
- 下沉了 Istio 中颇受诟病的 Mixer 的限流能力;
- 腾讯基于 Envoy 进行改造整合内部的 TSF 服务框架;
- 微博基于 Motan-Go 研制出 Motan-Mesh,整合了自己的服务治理体系;
- 华为的 ServiceComb 也是类似的做法, Mixer完全下沉;
- Twitter推出 Conduit,基于Rust,也将Mixer完成下沉;
- ……
但是,Servicemesh 仍然有几个问题没解决,除了仍然绕不开的性能问题外,目前也有越来越多的人在进行 mesh 反思一个问题:
控制面板和数据面板切割的标准是什么?是不是过于理想化了?
这个问题目前见仁见智,此处不展开。虽然 Servicemesh 目前还在起步阶段,很多问题也还在摸索中,但是从微服务领域发展的趋势来看,上文所述的 Servicemesh 的三个理念与其不谋而合,必然是未来的大势所趋。
1.4 总结
这一章回顾了服务治理的发展历程,经历了三个大阶段的思潮,我们回归初心,可以看到每个阶段的方案其实都有其适用和不适用的场景,没有最好的方案,只有最合适的方案。我们也可以沿着这三个阶段的思考逻辑发现,其实对于服务的治理,也是处于一个反复摸索、纠结,螺旋上升的过程。
2. 考虑过资源上的损耗吗?
mesh本质上相当于寄生在业务机器上。使用的是业务机器的资源。实际上的测试中发现,由于采用了c++/go实现的mesh对于内存的消耗比较可控,默认情况下只占用几M,在高并发下一般也只会上升至几十M。这对于正常情况下8G/16G内存的应用机器来说基本可以忽略不计。所以内存的额外占用这个问题可以基本忽略。但是其对于cpu资源的消耗则较大,一般会趋近于业务正常使用的cpu资源量。这意味着,加入了mesh之后,有可能业务能使用的cpu资源只剩下本来的一半。这就是一个比较大的问题了。
关于这个问题,目前业内的主要论述认为,由于正常业务机器的资源使用率不到10%,所以这部分的额外占用在实际情况下并不会对业务造成实质性的影响,反而可以让我们更好地利用上闲置资源,避免浪费。业务与mesh互利共赢。
这个逻辑,在未来很长一段时间内肯定都是成立的。但是,我认为基于这个逻辑,会衍生出的两个新问题:
- 资源不会无限期闲置。我们已经注意到,由于涉及到成本分摊,现在越来越多的业务方对于资源使用已经越来越重视,加上未来的主流趋势云原生的目标之一也是希望提升机器资源使用率。按着这个趋势,当有一天资源利用率的问题已经被相对妥善地解决了,那mesh对于CPU占用的这个问题就会凸显,届时将如何解决这一问题呢?如果让mesh绑定单独cpu核或者采取绑定单独pod资源的方式来和每个业务实例资源做区隔,那必然也会带来不小的成本浪费。
- 资源使用率这个数字之外,还有业务高低峰问题。我们都知道业务是有高低峰的。比如外卖业务每日饭点是高峰,酒店业务每到节假日是高峰,电影票业务每到春节是高峰。有高低峰就说明肯定会有资源的适当冗余。所以虽然看着资源使用率不高,但是真到了高峰,部分业务的系统cpu资源会飙升甚至趋近于打满,这种情况下如果引入mesh,则给业务方的直接感受就是:高峰期业务处理能力下滑一半。我相信业务方听到这个结论后都会表示无法接受。这个时候怎么处理这一问题呢?除了业务方扩容一倍机器之外,还有解法吗?
这看似是一个无解的命题,因为servicemesh的架构就是这样。资源也就是这些,不会凭空多出来。但是,笔者想问一下,我们是不是可以打破servicemesh的架构,或者说,优化servicemesh的架构?
回顾下我们前面介绍服务治理发展史时候提到的三个重要的思潮:
Server Proxy
Smart Client
Local Proxy
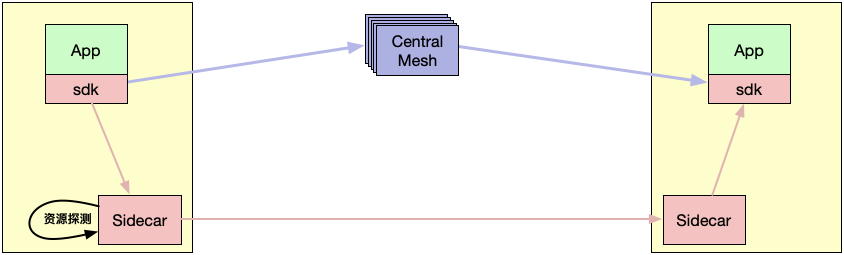
Servicemesh即属于Local Proxy之一,可以解决与业务方强耦合、语言强相关、单点等问题。但其他思潮就一无是处吗?显然答案是否定的。其他的方式仍然具备着强大的生命力和存在的价值。我们的解决方案即使用Server Proxy作为闲置资源不够时的兜底方案,采取逻辑上的Central Mesh来解决上述的问题:
- Sidecar进行闲置资源探测
- 当发现闲置资源即将不足,则告知sdk切换流量至Central Mesh
- Central Mesh完成Sidecar所有的工作。
Central Mesh装载有所在区域所需的的所有信息,承担起Sidecar的所有能力。即Central Mesh也作为所在区域Sidecar的backup,在Sidecar失灵或者闲置资源不足以正常运转Sidecar的情况下,主动切换流量。
Central Mesh之所以称之为“逻辑上”,是因为Central Mesh不一定是就一组中央集群,而是可以分散就近部署,以尽量降低网络延时和单点带来的额外风险。比如可以按机房、按地域、按网关甚至就近部署到宿主机上。
3. 考虑过性能上的损耗吗?
性能上的损耗是回避不了的一个问题。由于多进行了一次转发以及要进行服务治理,所以性能天然地比直连RPC的方式的性能要差。基于我们实际的性能测试结果,其相比于直连,mesh方式的性能会退化20-50%左右,这还是在不采用iptables这种更耗性能的方式下进行的测试。当然,这个增加的延时在毫秒级,对于大部分的业务要求来说,其实是可接受的。对业务性能的影响微乎其微。
但是,我们还是需要考虑如下的潜在问题:
- 业务应用问题。对于一些高并发的业务场景,可能本身延时就低(毫秒级),且对延时敏感,加上一次调用链路可能会有七八次甚至十次以上的RPC调用,如果以这种方式进行改造,则可能导致这类业务性能退化严重,甚至可能引起比如超时、线程池打满等问题。
- 基础应用问题。如果servicemesh的未来趋势是所有通讯流量都mesh化而不仅仅是业务应用的流量,那么我们就还需要考虑,比如类似redis这样的对延时极度敏感的存储流量进行mesh化后,我们对于mesh带来额外延时的忍耐度将进一步降低。redis本身就是一个超高并发、极度低延时、非常延时敏感的场景。多出一毫秒的延时都很有可能会引起Redis可用性的成倍下滑甚至引起业务故障。
所以针对以上问题,一方面,我们需要对于性能的退化有心理预期,另一方面,我们也应该竭尽所能地优化甚至压榨servicemesh的性能极限,而不是说选择了mesh就放弃了性能听之任之了。想想netty著名的压榨性能到极致的“eventloop挑选”。
在mesh的通讯性能优化上,有几个可以考虑的点:
- 本地进程通讯优化。mesh由于和业务进程在同一机器上,具备利用本地进程通讯加速通讯性能的前提条件。本地进程通讯存在多种方式,比如mmap、unix domain socket、pipe、signal等等。其中又以mmap性能最为突出,traffic-shm 是一个异步无锁的IPC框架,能够轻松支撑百万 TPS,其就采用了 mmap 来进行通讯。通过实际测试,采用mmap结合适当的事件通知机制,在某些高并发的场景上,其性能相较于tcp的方式会提升30%以上。
- 线程模型。基本高性能服务的底层都采用了Reactor模式来实现线程模型。当然,配合线程池/协程池,以及 Reactor 的层次,可以有多种的实现路径。有类似 Nginx 这样的一主多子进程 + 单 Reactor 单线程(高版本提供了线程池机制)的模型,evio 和 Envoy 利用“单 Reactor 协程池(线程池)”, Netty 采用多级 Reactor + 多级线程池。避免mesh出现阻塞式设计。
- 字节重用。我们习惯于对每个请求去新创建一个他所需要的空间来存放一些信息。但是当并发量上来后,这样的空间分配将会导致较大的性能开销和回收压力。所以基于伙伴算法或者Slab算法或其他的方式,进行一个字节内存使用的分配管理,将会让你收益良多。比如 Netty 由于申请了堆外内存而采用了伙伴算法,Nginx 则采用了 Slab 机制,Mosn 在 Golang 分配机制的基础上引入多级容量加 sync.Pool 机制的缓存来进行优化。
- 内存对齐。操作系统按照页进行内存管理。如果你直接操作内存地址进行数据传输(比如用 mmap)的话,那么如果没有内存对齐,将会导致你拉取到并不需要的内存空间,且会有内存移动拼接的额外开销,这将会直接导致你性能的下滑。高性能内存队列 Disruptor 也是采用了内存对齐的方式进行优化。
- 无锁化。通讯的第一反应即需要处理并发安全的问题,很多时候你可能不得不通过锁的方式来保障安全。这个时候,考虑下通过利用硬件层面的CAS操作来替代常规的锁操作,也可以采取类似 Redis 这样单线程处理的方式,或者 Envoy 这样虽然采用了线程池,但是连接会进行单个线程的绑定操作来规避并发问题。
- 池化。线程资源是很宝贵的,加上线程本身不可能申请几千上万个出来,所以线程池是默认的标配。这边要谈的是,比如你用了协程技术,虽然协程被神化为轻量级线程,性能非常高且可以轻松开出几万个而面不改色。但是你需要知道,这也会很严重地影响你实际的处理性能,并且由于 golang 本身的协程分配原理,协程的一些元数据并不会在使用后被回收,这是由于 golang 开发者的理念是“一旦到达过这样的流量,就说明系统有可能再次面临这样的洪峰,那么就提前做好准备”。所以我们对于协程,仍然需要考虑池化的问题。Motan-Go 和 Thrift 的 golang 版本中目前并没有这方面的考虑,而 Sofa-Mosn 已经做了对应的池化处理。
还有很多其他的性能优化手段,此处就不再一一列举。
4. Sidecar功能的相互影响
我们去做Servicemesh的一大初衷,是为了解决和业务强耦合的现状,进行了服务治理能力的下沉。但是,下沉的时候,我们发现,服务治理本身也囊括了非常多的东西,动态配置、流控、熔断、故障演练、负载均衡、路由、通讯、服务注册发现、集中式日志、分布式链路调用、监控埋点等等。这些东西都一股脑地揉入到一个单薄的Sidecar里。我们做这一件事的时候,是不是也需要开始审视一下,服务治理本身那么多的功能之间是不是也有类似的问题,会产生组织层面和技术层面的相互干扰、依赖、影响甚至是冲突?没错,这就是会延伸出来的问题。
- 比如,如何确保日志采集这种大规模但不重要的流量,完全不会影响核心业务流量?
- 比如,如何确保某个功能的升级,不影响核心业务通讯?
- 比如,如何多个团队一起维护一个Sidecar?
- ……
以上都是可能带来的问题,当然,你可以用隔离舱,可以用热部署,可以代码仓库想办法分割。但是,当一切都下沉的时候,面对本来七八个团队一起管理维护的能力集,你真的能很好地解决上述的问题吗?
我们建议,这种时候,拆开Sidecar吧。以一定的规则,基于你的mesh所在的发展阶段综合考虑,拆开你的Sidecar。也许拆开它,一切就都解决了。在本文撰写期间,也确实看到了比如蚂蚁金服的Sofa-mosn已经拆出了单独的dbmesh。
需要关注的是,拆开的Sidecar不宜过多,否则会导致Sidecar泛滥而花费高昂的运维升级成本。所以你看,是不是和服务化的历程有些类似,都在“拆拆拆”的过程中,简化问题,同时引入新的问题?这才是我们所身处的事业的美妙之处,因为你总能在一些看似不相关的地方找到他们的相似之处。
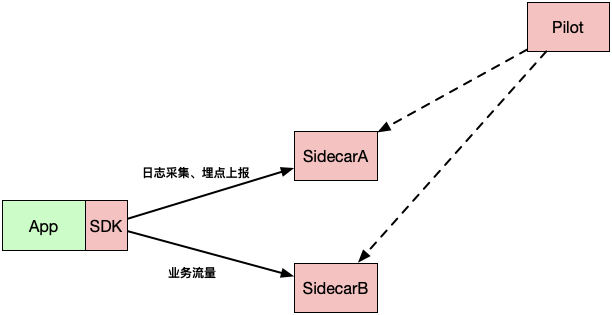
5. 只负责服务订阅不负责服务发布?
Pilot可以进行服务订阅,并桥接到XDS接口体系中。但是,为什么没有进行服务注册的能力呢?笔者猜测这是因为Servicemesh是在云原生背景下基于Local Proxy所演进而来的。而Local Proxy在云原生方案里面,基本都不会负责服务注册,因为他们会将服务注册交给云(Mesos、Marathon、K8s等都有现成方案)来实现,或者会一般会结合consul/etcd/zk单独另起agent来完成服务注册。此时Local Proxy则朴素地只关注反向代理的工作。
而这,对于我们实际生产环境的使用来说,则显得没那么友好。因为业务发展到一定阶段,一般都有自己的一套服务治理框架,采用自己的服务注册订阅方式。他们不太可能为了将服务治理mesh化,反而把整套服务订阅发布体系迁移到云原生体系中去,那就有点本末倒置了。所以就必然会选择进行适配。而适配的过程中,为了使用上服务订阅发布,他们就不得不深度改造Sidecar,加入服务注册的能力,再让Sidecar对接第三方的注册中心。工作繁琐复杂的同时,也打破了Servicemesh希望控制平面屏蔽基础设施差异性的初衷。
所以笔者认为Servicemesh是需要彻底屏蔽掉具体注册中心的存在的。发布和订阅应该都经过Pilot,为使用方提供统一门面。以后无论注册中心如何切换,都无需再深度侵入修改Sidecar。
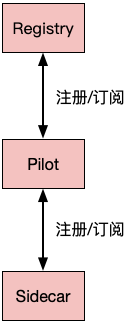
6. 控制面板和数据面板如何切割?
这是一个老大难的问题。控制面板中的Mixer现在基本是处于一个“墙倒众人推”的地步。Istio比较偏执地将其单拎出来,处理限流和数据遥测等事宜。前者会带来很大的性能瓶颈(即使Istio后续在Envoy中增加了缓存机制也无力回天),后者会带来双倍的流量消耗。很多Servicemesh的实现都摒弃或者简化了Mixer。网上对应的文章有不少,此处不复赘述。
虽然Istio的这一设计太过于理想化,希望通过这种方式屏蔽基础设施差异性,然后为Sidecar提供无限庞大的内存容量支持,同时将一些复杂多变逻辑尽可能剔除出Sidecar,来保证Sidecar尽可能稳定可靠。但是现实还是很残酷的,有通讯的地方就会产生问题。分布式环境的复杂性大半就是由于网络导致的。
而如果将Mixer一股脑地下沉,则不得不面对各种复杂逻辑下如何保障Sidecar本身足够稳定可靠,消耗足够少资源,引入尽量少依赖,足够小而美的状态?
虽然控制面试和数据面板的切割是一个很困难的命题,而Istio这方面也引起了一些吐槽,但是从先驱者的角度上来看,Istio成功整合了发展了很长时间的Local Proxy方案,并将其上升到了方法论的高度,成功引发了业内对于控制面板和数据面板的体系化思考,这才是Istio做出的最大贡献,这是一场从战术到战略的变革,从术到道的创新。
7. 结语
我们从多个角度,分析了Servicemesh发展至今可能存在的一些问题。提出了一些基于实际生产经验总结出的解决方案,希望能给大家带来一些帮助。当然所有的选择都很难,我们也没有标准答案,如何结合各自公司的实际情况trade-off才是体现能力和价值的地方。虽然Servicemesh有一些问题,但是其必然是未来发展的大势所趋。其能为我们带来极大的想象力和人力的解放。
