

前因
通常程序读取文件的时候,文件的内容都能准确被获取,但有时候最前面会多出几个奇怪的字符,直接打开文件却什么都看不到【哭的表情】,如下图,运行程序时在“Java咖啡屋”前多了一个神奇的字符。
- 什么是Unicode
- 为什么会有UTF-8,UTF-16
- 什么是字节序(BOM, Byte Order Mark)
1. 什么是Unicode
维基百科的解释是
Unicode是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得计算机可以用更为简单的方式来呈现和处理文字。
这就是说Unicode对大多数文字都进行了编码,基本上每一个字符都能在Unicode找到对应的编码,这样全球人民都只认可一个标准就够了,这就是Unicode。
Unicode有UCS-2和UCS-4之分,UCS-2只有2个字节,16位,最多表示65536个字符,其中中文字符占了20000多个(我国文字在Unicode里占了大头,可喜可贺),其编码从4E00到9FA5,例如“严”=4E25, “赟”=8D5F
但是6万多个字符还不足以表示全世界的文字(但常用的已经足够了),因此推出了UCS-4这种4字节编码,作为UCS-2的子集。 另外,在Java内存中总是以UCS-2进行编码,String的length()方法也是以字符为单位,常用中文字符长度为1,生僻字(UCS-4才能编码的)的长度是2.

2. 为什么会有UTF-8、UTF-16
Unicode只规定了字符该如何编码,但并没有定义编码后该如何存储。例如“严”的Unicode编码是4E25,同时“N”的编码是4E,“%”的编码是25,那么计算机看到4E25究竟是“严”还是“N%”呢,UTF-8、UTF-16就是用来解决这个问题。
维基百科对UTF-8的解释是
UTF-8是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字优先采用的编码。
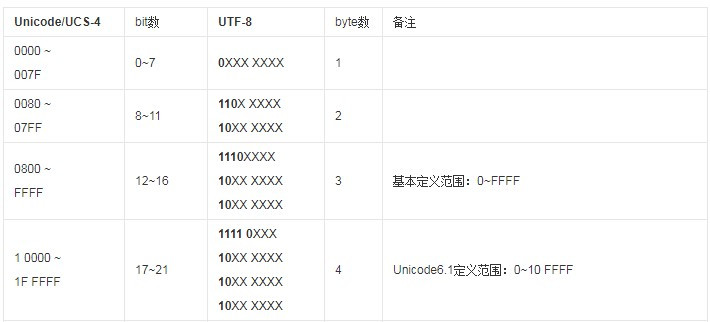
例如“N”的Unicode编码是4E(0100 1110),属于0000~007F,因此它的UTF-8还是4E(0100 1100),同理“%”的Unicode编码和UTF-8编码都是25。按照UTF-8的规范,ASCII在UTF-8下的编码没有变化。
“严”的Unicode编码是4E25(0100 1110 0010 0101),属于0800~FFFF内,因此它的UTF-8编码是E4B8A5(1110 0100 10111000 10100101,粗体部分就是Unicode编码)。所以会出现中文字符在UTF-8编码下占用了3个字节存储空间的现象。
要注意的是,如果中文字符的编码超出了0800~FFFF的范围,就像表中的最后一行,这些中文字符都是生僻字,会占用4个字节的存储空间。
因此,UTF-8是一种变长的存储方式,对于N个字符的文本,根据字符的不同,存储空间在N~4N不等。适合文本中大量ASCII字符的场景。
例如,Sting的getBytes()方法可以返回不同编码方式下的字节数组,“严”在UTF-8下占3个字节,在GBK下占2个字节。

UTF-16简单理解就是UCS-2是什么,UTF-16就存储什么。(这里只说最简单最通用的,我也不是特别清楚UTF-16的复杂情况)。例如“Java咖啡屋”的UTF-16编码

FEFF是字节序,下文详细解释。
004A = J
0061 = a
0076 = v
0061 = a
5469 = 咖
5561 = 啡
5C4B = 屋
我们可以看到UTF-16每一个字符对应2个字节16位。
对于ASCII字符,高位补0,其余使用Unicode编码。
对于常用中文字符,直接使用Unicode编码。
因此UTF-16存储ASCII的空间比UTF-8大,但存储中文字符的空间比UTF-8小。
3. 什么是字节序(BOM, Byte Order Mark)
计算机硬件存储一个双字节字符有两种方式:
- 高位字节在前,低位字节在后,称为大端字节序(big endian),也是人类习惯阅读的方式。
- 低位字节在前,高位字节在后,称为小端字节序(little endian)
为什么要搞出两种字节序,统一不行吗?
因为计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。
但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。 上文提到的FEFF是指大端字节序,如果以小端字节序存储,如下图,对比上图的大端字节序都高低位颠倒了。

特别的,UTF-8是单字节编码,所以字节序BOM对UTF-8来说没有意义。
但是!!!Windows记事本有个很坑的地方,文件虽然以UTF-8存储,但是还是会在前面加入字节序FEFF,FEFF在UTF-8的编码是EFBBBF,所以用记事本新建一个空文件保存为UTF-8,会发现这个文件竟然占用3个字节,这就是UTF-8下的BOM。
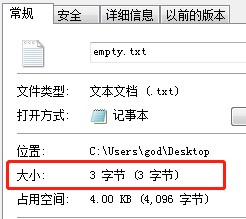
再次回到文章一开始遇到的问题,那个神奇的字符就是BOM,只要将文件用notepad++或者sublime text等编辑软件重新保存,就不会出现文中的问题了。
这告诉了我们一个道理,珍惜生命,远离记事本!远离记事本!远离记事本!
