Hadoop部署集群
架构
h-master
role:NameNode/JobTracker
ip:192.168.0.210
app:hadoop/hive
jobs:主节点,总管分布式数据和分解任务的执行;主节点负责调度构成一个作业的所有任务
h-slave
role:DataNode/Tasktracker
ip:192.168.0.211
app:hive
jobs:从节点,负责分布式数据存储以及任务的执行;从节点负责由主节点指派的任务
mapreduce框架
主节点JobTracker
每个从节点TaskTracker
安装步骤
配置h-master无密码ssh登录h-slave
ssh-keygen -t rsa -b 2048
ssh-copy-id hadoop@h-slave
ssh hadoop@h-slave
安装Java环境
<!--install_java.sh-->
#!/bin/bash
java_env=java.env
rpm -ivh jdk-8u221-linux-x64.rpm
cp /etc/profile /etc/profile.old
cat ${java_env} >> /etc/profile.old
source /etc/profile
java -version
<!--java.env-->
export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64
export PATH=${PATH} :${JAVA_HOME}
安装Hadoop(All Servers)
h-master服务器
<!--install_hadoop.sh-->
#!/bin/bash
hadoop_dir=/opt/hadoop-3.1.2
pwd_dir=$(echo `pwd `)
host_name=$(echo 'hostname' )
tar -xzvf hadoop-3.1.2.tar.gz -C /opt
groupadd hadoop
useradd -g hadoop hadoop
passwd hadoop
chown -R hadoop:hadoop ${hadoop_dir}
cp /etc/profile /etc/profile.add
cat hadoop.env >> /etc/profile
source /etc/profile
firewall-cmd --zone=public --add-rich-rule='rule family="ipv4" source address="192.168.0.210" port port="9000" protocol="tcp" accept' --permanent
firewall-cmd --zone=public --add-rich-rule='rule family="ipv4" source address="192.168.0.210" port port="9870" protocol="tcp" accept' --permanent
firewall-cmd --zone=public --add-rich-rule='rule family="ipv4" source address="192.168.0.0/24" port port="8088" protocol="tcp" accept' --permanent
firewall-cmd --zone=public --add-rich-rule='rule family="ipv4" source address="192.168.0.0/24" port port="10020" protocol="tcp" accept' --permanent
firewall-cmd --zone=public --add-rich-rule='rule family="ipv4" source address="192.168.0.0/24" port port="19888" protocol="tcp" accept' --permanent
firewall-cmd --reload
mkdir /opt/hadoop-3.1.2/hdfs/namenode
mv ${hadoop_dir} /etc/hadoop/core-site.xml ${hadoop_dir} /etc/hadoop/core-site.xml.old
mv ${hadoop_dir} /etc/hadoop/hdfs-site.xml ${hadoop_dir} /etc/hadoop/hdfs-site.xml.old
mv ${hadoop_dir} /etc/hadoop/mapred-site.xml ${hadoop_dir} /etc/hadoop/mapred-site.xml.old
mv ${hadoop_dir} /etc/hadoop/yarn-site.xml ${hadoop_dir} /etc/hadoop/yarn-site.xml.old
cp core-site-master.xml ${hadoop_dir} /etc/hadoop/core-site.xml
cp hdfs-site-master.xml ${hadoop_dir} /etc/hadoop/hdfs-site.xml
cp mapred-site-master.xml ${hadoop_dir} /etc/hadoop/mapred-site.xml
cp yarn-site-master.xml ${hadoop_dir} /etc/hadoop/yarn-site.xml
cd ${hadoop_dir} /etc/hadoop && cp workers workser.old
sed -i '1d' workers
echo "h-slave" > workers
chown -R hadoop:hadoop ${hadoop_dir}
echo "export JAVA_HOME=/usr/java/jdk1.8.0_221-amd64" >> ${hadoop_dir} /etc/hadoop/hadoop_env.sh
<!--hadoop.env-->
export HADOOP_HOME=/opt/hadoop-3.1.2
export PATH=${PATH} :${HADOOP_HOME} /bin:${HADOOP_HOME} /sbin
<!--core-site-master.xml-->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://h-mster:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/tmp</value>
</property>
</configuration>
<!--hdfs-site-master.xml-->
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop-3.1.2/hdfs/namenode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop-3.1.2/hdfs/data</value>
</property>
</configuration>
<!--mapred-site-master.xml-->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://h-master:9001</value>
</property>
</configuration>
<!--yarn-site-master.xml-->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>http://h-master:9001</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>h-master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>h-master:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/home/hadoop/history /tmp</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/home/hadoop/history /done </value>
</property>
</configuration>
su hadoop
hdfs namenode -format
cd /opt/hadoop-3.1.2/sbin && ./start-all.sh
mapred --daemon start jobhistory
jps
注意
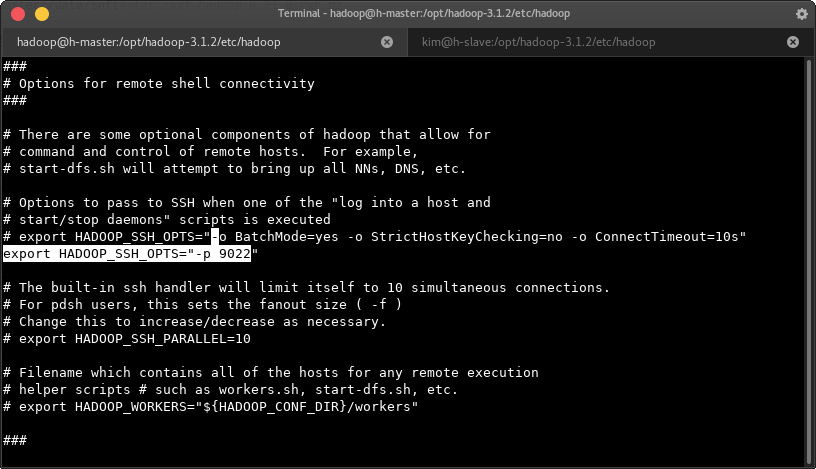
如果ssh端口不是默认的22,需要在文件hadoop_env.sh中修改,具体的位置是HADOOP_SSH_OPTS="-p 9022"
h-slave服务器
在主服务器中复制hadoop安装目录到slave
删除workers文件中的内容
配置环境变量
在hadoop_env.sh文件中添加java环境变量
Web UI
参考
Hadoop多节点集群的构建 hadoop分布式集群搭建 How to Install and Set Up a 3-Node Hadoop Cluster Hadoop Cluster Setup