

使用Python获取数据,目前主要的方法集中在文本文件、Excel文件、关系型和非关系型数据库、API、网页等方面。
获取数据所用到的包:
Numpy中文文档:www.numpy.org.cn/article/bas…
Pands中文文档:www.pypandas.cn/docs/
一、从文本文件读取运营数据
1.1 使用read、readline、readlines读取数据
Python可以读取任意格式的文本数据,使用Python读取文本数据的基本步骤是:
(1)定义数据文件;(2)获取文件对象; (3)读取文件内容; (4)关闭文件对象。
(1)定义数据文件
定义数据文件即定义要读取的文件,该步骤不是必须的,可以跟“获取文件对象”整合。但为了后续操作的便捷性、全局数据对象的可 维护性以及减少代码冗余,建议读者养成习惯,将数据文件预先赋值给一个对象。
定义文本数据文件的方法是:
file_name = [文件名称]
实例:
file_name = 'text.txt'
文件名称中可以只写文件名,此时默认Python读取当前工作目录下 的文件;也可以加入路径,默认使用斜杠,尤其是Windows下要注意用法。
(2)获取文件对象
获取文件对象的意义是基于数据文件产生对象,后续所有关于该数据文件的操作都基于该对象产生。
语法:
fileobject = open(name[,mode][,buffering])
参数:
- name:要读取的文件名称,即上一个环节定义的file_name,必填
- mode:打开文件的模式,选填,在实际应用中,r、r+、w、w+、a、a+是使用最多的模式。
- buffering:文件所需的缓冲区大小,选填;0表示无缓冲,1表示线路缓冲。
返回:通过open函数会创建一个文件对象(fileobject)。示例:
file_name = 'text.txt'
file_object=open(file_name)
或
file_object=open('text.txt')
(3)读取文件内容
Python基于文件对象的读取分为3种方法,以读取text.txt为例:
这是第一行
这是第二行
这是第三行
关于read()方法:
1、读取整个文件,将文件内容放到一个字符串变量中
2、如果文件大于可用内存,不可能使用这种处理
执行代码:
file_name = 'text.txt'
file_object=open(file_name,encoding='utf-8')
text1 = file_object.read()
text1
结果
'这是第一行\n这是第二行\n这是第三行'
关于readline()方法:
1、readline()每次读取一行,比readlines()慢得多
2、readline()返回的是一个字符串对象,保存当前行的内容
执行代码:
file_name = 'text.txt'
file_object=open(file_name,encoding='utf-8')
text2 = file_object.readline()
text2
结果
'这是第一行\n'
关于readlines()方法:
1、一次性读取整个文件。
2、自动将文件内容分析成一个行的列表。
执行代码:
file_name = 'text.txt'
file_object=open(file_name,encoding='utf-8')
text3 = file_object.readlines()
text3
结果
['这是第一行\n', '这是第二行\n', '这是第三行']
在实际应用中,read方法和readlines方法比较常用,而且二者都能读取全部文件中的数据。
二者的区别只是返回的数据类型不同,前者返回字符串,适用于所有行都是完整句子的文本文件,例如大段文字信息;
后者返回列表,适用于每行是一个单独的数据记录,例如日志信息。不同的读取方法会直接影响后续基于内容的处理应用;readline由于每次只读取一行数据,因此通常需要配合seek、next等指针操作才能完整遍历读取所有数据记录。
(4)关闭文件内容
每次使用完数据对象之后,需要关闭数据对象。方法是
file_object.close()
理论上,Python可以读取任意格式的文件,但在这里先讲以读取格式化的文本数据文件为主,其中包括txt、csv、tsv等格式的文件,以及有固定分隔符分隔并以通用数据编码和字符集编码(例如utf8、ASCII、GB2312等)存放的无扩展名格式的数据文件。
另外,Python文件操作中的指针类似于Word操作中的光标,指针所处的位置就是光标的位置,它决定了Python的读写从哪里开始。默认情况下,当通过open函数打开文件时,文件的指针处于第一个对象的位置。因此,在上述通过readline读取文件内容时,获取的是第一行数据。仍然是上面示例中的数据文件,我们通过如下代码演示基于不同指针位置读取的内容:
fn=open('text.txt',encoding='utf-8')#获得文件对象
print(fn.tell())#输出指针位置
line1=fn.readline()#获得文件第一行数据
print(line1)#输出第一行数据
print(fn.tell())#输出指针位置
line2=fn.readline()#获得文件第二行数据
print(line2)#输出第二行数据
print(fn.tell())#输出指针位置
line3=fn.readline()#获得文件第三行数据
print(line3)#输出第三行数据
fn.close()#关闭文件对象
结果:
0
这是第一行
16
这是第二行
32
这是第三行
1.2 使用Numpy的loadtxt、load、fromfile读取数据
Numpy读取数据的方法包括loadtxt、load和fromfile等3种
(1)numpy的loadtxt()方法
numpy.loadtxt(fname, dtype=<type 'float'>, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0)
| 参数 | 作用 |
|---|---|
| fname | 被读取的文件名(文件的相对地址或者绝对地址) |
| dtype | 指定读取后数据的数据类型 |
| comments | 跳过文件中指定参数开头的行(即不读取) |
| delimiter | 指定读取文件中数据的分割符 |
| converters | 对读取的数据进行预处理 |
| skiprows | 选择跳过的行数 |
| usecols | 指定需要读取的列 |
| unpack | 选择是否将数据进行向量输出 |
| encoding | 对读取的文件进行预编码 |
执行代码:
import numpy as np
txt_array = np.loadtxt('text.txt',dtype=str,comments='#',encoding='utf-8')
print(txt_array)
结果
['这是第一行' '这是第二行' '这是第三行']
(2)numpy的load()方法
numpy.load(file, mmap_mode=None, allow_pickle=True, fix_imports=True, encoding='ASCII')[source])
| 参数 | 作用 |
|---|---|
| file | 要读取的文件,字符串或pathlib.Path。类文件对象必须支持 seek()和read()方法。pickle文件要求类文件对象也支持该readline()方法。 |
| mmap_mode | 内存映射模式,值域为None、'r+'、'r'、'w+'、'c',选填。 |
| allow_pickle | 布尔型,选填,决定是否允许加载存储在npy文件中的pickled对象数组,默认值为True。 |
| fix_imports | 布尔型,选填,仅在Python3上加载Python2生成的pickle文件时才有用,其中包括包含对象数组的npy / npz文件。如果fix_imports为True,则pickle将尝试将旧的Python 2名称映射到Python 3中使用的新名称。 |
| encoding | 字符串,决定读取Python2字符串时使用何种编码,选填。 |
执行代码:
import numpy as np#导入nump库
write_data=np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])#定义要存储的数据 np.save('load_data',write_data)#保存为npy数据文件
np.save('load_data',write_data)#保存为npy数据文件
read_data=np.load('load_data.npy')#读取npy文件
print(read_data)#load()无法直接读取txt文件,只能读取.npy或者.npz的文件。
结果
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
(3)numpy的fromfile()方法
numpy.fromfile(file, dtype=float, count=-1, sep='')
| 参数 | 作用 |
|---|---|
| file | 要读取的文件,字符串或pathlib.Path。 |
| dtype | 数据类型 |
| count | 整数型,读取数据的数量,-1意味着读取所有数据。 |
| sep | 字符串,如果file是一个文本文件,那么该值就是数据间的分隔符。如果为空("")则意味着file是一个二进制文件,多个空格将按照一个空格处理。 |
执行代码:
import numpy as np
txt_array3 = np.loadtxt('text.txt',dtype=str,comments='#',encoding='utf-8')
print(txt_array3)
tofile_name = 'binary'#定义导出二进制文件名
txt_array3.tofile(tofile_name)#导出二进制文件
fromfile_data = np.fromfile(tofile_name,dtype='float32')#读取二进制文件print(fromfile_data)#打印数据
结果
['这是第一行' '这是第二行' '这是第三行']
1.3 使用Pandas的read_csv、read_fwf、read_table读取数据
(1)Pandas的read_csv()方法
pandas.read_csv(filepath_or_buffer: Union[str, pathlib.Path, IO[~AnyStr]], sep=',', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, dialect=None, error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)
| 参数 | 作用 |
|---|---|
| file | 要读取的文件,字符串或pathlib.Path。 |
| dtype | 数据类型 |
| count | 整数型,读取数据的数量,-1意味着读取所有数据。 |
| sep | 字符串,如果file是一个文本文件,那么该值就是数据间的分隔符。如果为空("")则意味着file是一个二进制文件,多个空格将按照一个空格处理。 |
text.csv文档原始数据:
1 2
这是第一行第一列 这是第一行第二列
这是第二行第一列 这是第二行第二列
执行代码:
import pandas as pd
txt_array4 = pd.read_csv('text.csv',sep=',',dtype='str',encoding='gbk')
print(txt_array4)
结果
1 2
0 这是第一行第一列 这是第一行第二列
1 这是第二行第一列 这是第二行第二列
(2)Pandas的read_fwf()方法
pandas.read_fwf(filepath_or_buffer, colspecs='infer', widths=None, **kwds)
| 参数 | 作用 |
|---|---|
| filepath_or_buffer | 要读取的文件,字符串或pathlib.Path。 |
| widths | 由整数组成的列表,选填,如果间隔是连续的,可以使用的字段宽度列表而不是“colspecs”。 |
执行代码:
import pandas as pd
txt_array4 = pd.read_fwf('text.csv',sep=',',dtype='str',encoding='gbk')
print(txt_array4)
结果
1,2
0 这是第一行第一列,这是第一行第二列
1 这是第二行第一列,这是第二行第二列
(3)Pandas的read_table()方法
pandas.read_table(filepath_or_buffer, sep='\t', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, skip_footer=0, doublequote=True, delim_whitespace=False, as_recarray=None, compact_ints=None, use_unsigned=None, low_memory=True, buffer_lines=None, memory_map=False, float_precision=None)[source]
参数:对于read_table而言,参数与read_csv完全相同。其实read_csv本来就是read_table中分隔符是逗号的一个特例,表现在语法中是read_csv的sep=','(默认)。因此,具体参数请查阅read_csv的参数部分。
read_csv() 读取以‘,’分割的文件到DataFrame
read_table()读取以‘/t’分割的文件到DataFrame
分割符既有空格又有制表符(‘/t’),sep参数用‘/s+’,可以匹配任何空格。
| 参数 | 作用 |
|---|---|
| filepath_or_buffer | 要读取的文件,字符串或pathlib.Path。 |
| widths | 由整数组成的列表,选填,如果间隔是连续的,可以使用的字段宽度列表而不是“colspecs”。 |
执行代码:
import pandas as pd
txt_array4 = pd.read_table('text.csv',sep='/s+',dtype='str',encoding='gbk')
print(txt_array4)
结果
1,2
0 这是第一行第一列,这是第一行第二列
1 这是第二行第一列,这是第二行第二列
1.4 如何选择最佳读取数据的方法
-
对于纯文本格式或非格式化、非结构化的数据,通常用于自然语言处理、非结构化文本解析、应用正则表达式等后续应用场景下,Python默认的三种方法更为适合。
-
对于结构化的、纯数值型的数据,并且主要用于矩阵计算、数据建模的,使用Numpy的loadtxt方法更为方便,例如本书中使用的sklearn 本身就依赖于Numpy。
-
对于二进制的数据处理,使用Numpy的load和fromfile方法更为合适。
-
对于结构化的、探索性的数据统计和分析场景,使用Pandas方法进行读取效果更佳,因为其提供了类似于R的数据框,可以实现“仿SQL”式的操作方式,对数据进行任意翻转、切片(块等)、关联等都 非常方便。
-
对于结构化的、数值型和文本型组合的数据统计分析场景,使用Pandas更为合适,因为每个数据框中几乎可以装载并处理任意格式的数 据。
二、从EXCEL文件读取运营数据
现有的Excel分为两种格式:xls(Excel 97-2003)和xlsx(Excel 2007及以上)。
Python处理Excel文件主要是第三方模块库xlrd、xlwt、pyexcel-xls、xluntils和pyExcel-erator,以及win32com和openpyxl模块,此外Pandas中也带有可以读取Excel文件的模块(read_excel)。
我们主要说主流的read_excel()
pandas.read_excel(io,sheet_name = 0,header = 0,names = None,index_col = None,usecols = None,squeeze = False,dtype = None, ...)
| 参数 | 作用 |
|---|---|
| io | 字符串,文件的路径对象。 |
| sheet_name | None、string、int、字符串列表或整数列表,默认为0。字符串用于工作表名称,整数用于零索引工作表位置,字符串列表或整数列表用于请求多个工作表,为None时获取所有工作表。 |
| header | 指定作为列名的行,默认0,即取第一行的值为列名。数据为列名行以下的数据;若数据不含列名,则设定 header = None。 |
| names | 默认为None,要使用的列名列表,如不包含标题行,应显示传递header=None。 |
| index_col | 指定列为索引列,默认None列(0索引)用作DataFrame的行标签。 |
| usecols | int或list,默认为None。 |
| squeeze | boolean,默认为False,如果解析的数据只包含一列,则返回一个Series。 |
| dtype | 列的类型名称或字典,默认为None。数据或列的数据类型。例如{'a':np.float64,'b':np.int32}使用对象保存存储在Excel中的数据而不解释dtype。如果指定了转换器,则它们将应用于dtype转换的INSTEAD。 |
| skiprows | 省略指定行数的数据,从第一行开始。 |
| skipfooter | 省略指定行数的数据,从尾部数的行开始。 |
执行代码:
import pandas as pd
txt_array4 = pd.read_excel('text.xlsx',sep='\s+',encoding='gbk')
print(txt_array4)
结果
1 2
0 这是第一行第一列 这是第一行第二列
1 这是第二行第一列 这是第二行第二列
三、从关系型数据库MySQL读取运营数据
3.1 第一步,下载Navicat,连接mysql
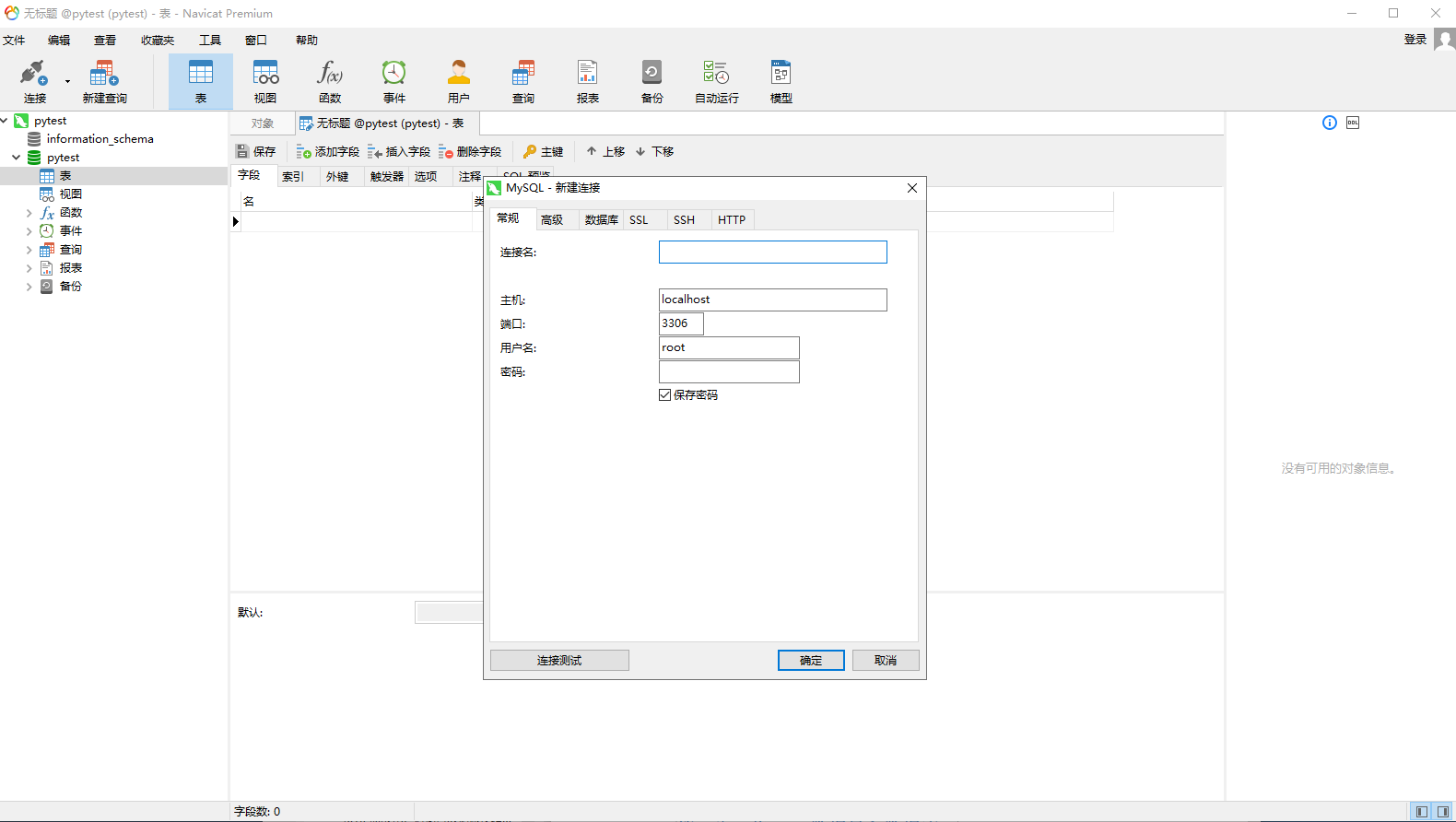
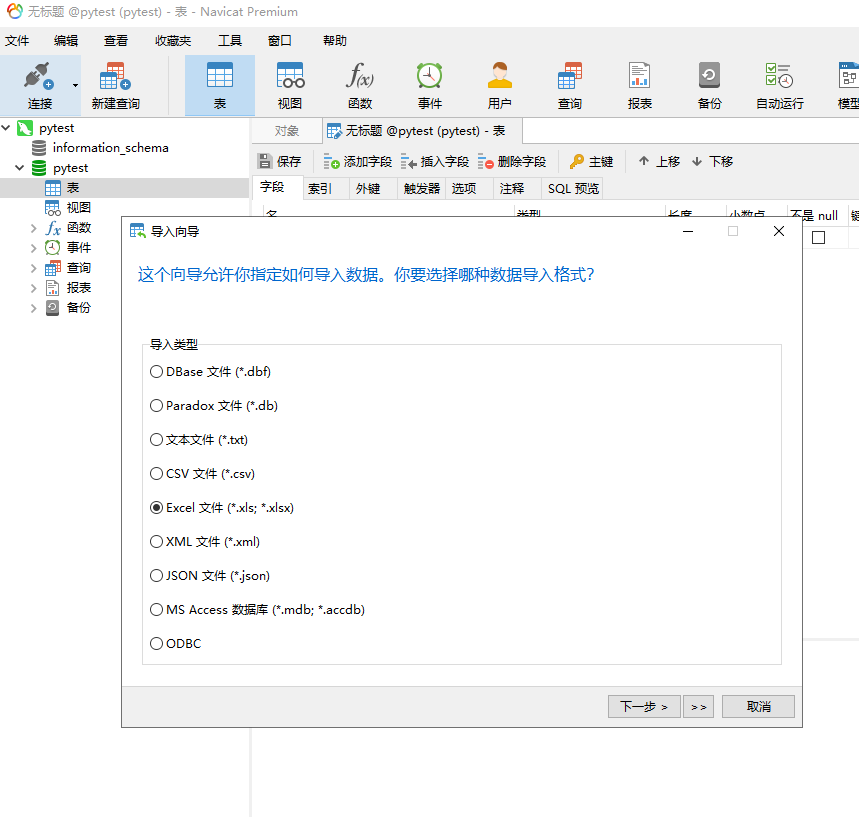
3.2 第二步,将Excel数据导入数据库
选择要导入的表,右键选择“导入向导”,再选择格式类型“EXCEL”。
3.3 第三步,用python的pymysql包连接mysql数据库
pymysql语法教程链接:www.runoob.com/python3/pyt…
import pymysql
# 打开数据库连接(IP地址,用户名,密码,数据库名称)
db = pymysql.connect("localhost","testuser","test123","TESTDB" )
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
# 使用 execute() 方法执行 SQL 查询
cursor.execute("SELECT VERSION()")
# 使用 fetchone() 方法获取单条数据.
data = cursor.fetchone()
print ("Database version : %s " % data)
# 关闭数据库连接
db.close()
结果
Database version : 5.5.57-log
3.4 第四步,操作mysql数据
SQL语句教程:www.w3school.com.cn/sql/index.a…
正则表达式教程:www.runoob.com/regexp/rege…
# SQL 查询语句
sql = "SELECT `订单产品数据`.`订单状态`,COUNT(*) FROM `订单产品数据` GROUP BY `订单产品数据`.`订单状态`"
try:
# 执行SQL语句
cursor.execute(sql)
# 获取所有记录列表
results = cursor.fetchall()
print (results)
except:
print ("报错")
结果:
(('交易取消', 33), ('交易完成', 16), ('待发货', 17), ('待收货', 218), ('拍下商品', 20), ('退货完成', 6))
四、从非关系型数据库MongoDB读取运营数据
PyMongo教程:www.runoob.com/python3/pyt…
4.1 安装MongoDB
MongoDB教程:www.runoob.com/mongodb/mon…
4.2 测试是否正常启动
import pymongo
myclient = pymongo.MongoClient('mongodb://localhost:27017/')
dblist = myclient.list_database_names()
if "runoobdb" in dblist:
print("数据库已存在!")
结果
数据库已存在!
4.3 创建集合,插入多个文档
mydb = myclient["runoobdb"]
mycol = mydb["sites"]
mylist = [
{ "name": "Taobao", "alexa": "100", "url": "https://www.taobao.com" },
{ "name": "QQ", "alexa": "101", "url": "https://www.qq.com" },
{ "name": "Facebook", "alexa": "10", "url": "https://www.facebook.com" },
{ "name": "知乎", "alexa": "103", "url": "https://www.zhihu.com" },
{ "name": "Github", "alexa": "109", "url": "https://www.github.com" }
]
x = mycol.insert_many(mylist)
# 输出插入的所有文档对应的 _id 值
print(x.inserted_ids)
结果
[ObjectId('5b236aa9c315325f5236bbb6'), ObjectId('5b236aa9c315325f5236bbb7'), ObjectId('5b236aa9c315325f5236bbb8'), ObjectId('5b236aa9c315325f5236bbb9'), ObjectId('5b236aa9c315325f5236bbba')]
4.4 查询集合中所有数据
mydb = myclient["runoobdb"]
mycol = mydb["sites"]
for x2 in mycol.find():
print(x2)
结果
{'_id': ObjectId('5d4390faa89575889f30d11e'), 'name': 'RUNOOB', 'alexa': '10000', 'url': 'https://www.runoob.com'}
{'_id': ObjectId('5d439138a89575889f30d11f'), 'name': 'Taobao', 'alexa': '100', 'url': 'https://www.taobao.com'}
{'_id': ObjectId('5d439138a89575889f30d120'), 'name': 'QQ', 'alexa': '101', 'url': 'https://www.qq.com'}
{'_id': ObjectId('5d439138a89575889f30d121'), 'name': 'Facebook', 'alexa': '10', 'url': 'https://www.facebook.com'}
{'_id': ObjectId('5d439138a89575889f30d122'), 'name': '知乎', 'alexa': '103', 'url': 'https://www.zhihu.com'}
{'_id': ObjectId('5d439138a89575889f30d123'), 'name': 'Github', 'alexa': '109', 'url': 'https://www.github.com'}
在企业实际应用中,非关系型数据库往往基于“大数据”的场景产生,伴随着海量、实时、多类型等特征。这些数据库通过舍弃了关系型数据库的某些特征和约束,然后在特定方面进行增强,因此才能满足特定应用需求。非关系型数据库由于约束性、规范性、一致性和数据准确性低于关系性数据库,因此常用于实时海量数据读写、非结构化和半结构化信息读写、海量集群扩展、特殊场景应用等。所以在金融、保险、财务、银行等领域内,这种应用比较少;而互联网、移动应用等新兴产 业和行业领域则应用较多。
五、从API获取运营数据
为了更好地让所有读者都能了解从API获取数据的具体过程,本节使用百度免费API作为实际数据来源。百度API提供了众多地图类功 能,如基本地图、位置搜索、周边搜索、公交驾车导航、定位服务、地理编码及逆地理编码等。本节使用的是百度Web服务API中的Geocoding API。
Geocoding API用于提供从地址到经纬度坐标或者从经纬度坐标到地址的转换服务,用户可以发送请求且接收JSON、XML的返回数。 该应用可用于对运营数据中的地址相关信息进行解析,从而获得经纬度信息,这些信息可用于进一步基于地理位置进行解析、展示和分析等。
要获得该API,需要拥有百度相关账户和AK信息。
第一步 获得百度账户,没有账户的读者可在 passport.baidu.com/v2/?reg 处免费注册获取。
第二步 注册成为百度开放平台开发者,读者可进入 lbsyun.baidu.com/apicon-sole… 完成相关注册。 该过程非常简单,遵循引导整个过程在5分钟内即可完成。
第三步 注册完成之后,会有一个名为“【百度地图开放平台】开发者激活邮件”的验证链接发送到指定(注册时邮箱)邮箱,点击链接即可完成验证。
第四步 点击“申请秘钥”进入创建应用界面,在该应用创建中,我 们主要使用Geocoding API v2,其他应用服务根据实际需求勾选。IP白名单区域,如果不做限制,请设置为“0.0.0.0/0”。设置完成后,点击提 交。
第五步 获得AK秘钥。完成上述步骤之后,会默认跳转到应用列表界面,界面中的“访问应用(AK)”便是该应用的秘钥。
5.1 获取并解析XML数据
我们先通过Python请求该API来获得JSON格式的数据。本示例的目标是通过给百度API发送一条地理位置数据,返回其经纬度信息。 本节会用到Python第三方库requests,读者需要先通过pip install requests进行安装。完整代码如下:
import requests # 导入库
add = '广州市天河区正佳广场' # 定义地址
ak = 'DdOyOKo0VZBgdDFQnyhINKYDGkzBkuQr' # 创建访问应用时获得的AK
url = 'http://api.map.baidu.com/geocoder/v2/?address=%s&output=xml&ak=%s' # 请求URL
res = requests.get(url % (add, ak)) # 获得返回请求
add_info = res.text # 返回文本信息
print (add_info) # 打印输出
结果
<?xml version="1.0" encoding="utf-8"?>
<GeocoderSearchResponse>
<status>0</status>
<result>
<location>
<lng>113.333581818</lng>
<lat>23.1383236194</lat>
</location>
<precise>1</precise>
<confidence>80</confidence>
<comprehension>100</comprehension>
<level>购物</level>
</result>
</GeocoderSearchResponse>
接着我们通过引入一个XML格式化处理库来从中提取经纬度信息。
# 设置字符编码为utf-8
import importlib
importlib.reload(sys)
import xml.etree.ElementTree as Etree # 导入XML中的ElementTree方法
root = Etree.fromstring(add_info) # 获得XML的根节点
lng = root[1][0][0].text # 获得lng数据
lat = root[1][0][1].text # 获得lat数据
print ('lng: %s' % lng) # 格式化打印输出
print ('lat: %s' % lat) # 格式化打印输出
结果
lng: 113.333581818
lat: 23.1383236194
5.2 获取并解析JSON数据
import requests # 导入库
add = '广州市天河区正佳广场' # 定义地址
ak = 'DdOyOKo0VZBgdDFQnyhINKYDGkzBkuQr' # 创建访问应用时获得的AK
url = 'http://api.map.baidu.com/geocoder/v2/?address=%s&output=json&ak=%s' # 请求URL
res = requests.get(url % (add, ak)) # 获得返回请求
add_info = res.text # 返回文本信息
print (add_info) # 打印输出
结果
{"status":0,"result":{"location":{"lng":113.33358181846966,"lat":23.138323619365097},"precise":1,"confidence":80,"comprehension":100,"level":"购物"}}
该结果可以通过JSON进行格式化处理
import json # 导入库
add_json = json.loads(add_info) # 加载JSON字符串对象
lat_lng = add_json['result']['location'] # 获得经纬度信息
print (lat_lng) # 打印输出
结果
{'lng': 113.33358181846965, 'lat': 23.138323619365096}
有关百度API的更多信息,具体查阅
在API应用中,中文的编码处理因细节太多而常常让人头疼。因此,如果可以则应尽量减少直接在API的数据中出现中文字符。在实际企业应用中,会出现多种API形式,但无论哪种形式,其基本实现思路 都是一致的:导入库→定义请求变量→发送请求→获得返回数据→格式化并获得目标数据,因此需要掌握JSON和XML的数据与其他数据的转换方法。
六、读取非结构化网页、文本、图像、视频、语音
6.1 读取非结构化网页
举个简单的例子
import requests # 导入库
url = 'https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=python&oq=python' # 定义要抓取的网页地址
res = requests.get(url) # 获得返回请求
html = res.text # 返回文本信息
print(html) # 打印输出网页源代码
想进阶的朋友看Scrapy爬取网页教程:www.imooc.com/learn/1017
6.2 读取非结构化文本
非结构化的文本数据指的是文本数据中没有结构化的格式,需要定制化解析才能获取数据,并且每条记录的字段也可能存在差异,这意味 着传统的结构化读取方式很难工作。非结构化的日志就是一个典型示例,服务器的日志可由运维工程师自行定义,因此不同公司的日志格式有所不同;另外在网站日志中还可能包含通过页面“埋码”的方式而采集来的用户行为数据,这些都会使日志面临非结构化的解析问题。
file = 'file_log'
fn = open(file, 'r') # 打开要读取的日志文件对象
content = fn.readlines() # 以列表形式读取日志数据
print(content[:2])
fn.close() # 关闭文件对象
其实日志文件只是普通文本文件中的一种类型而已,其他的非结构化数据文件都可以以类似的方法读取,即使文件没有任何扩展名。 对于非结构化的文本处理,通常更多地侧重于特定场景,通用性较差,原因就在于非结构化的形式本身变化多样。自然语言理解、文本处 理和挖掘、用户日志和机器日志解析等都是该领域中的主要工作。
6.3 读取图像数据
Python读取图像通常使用PIL和OpenCV两个库,相对而言,笔者使用后者的情况更多。
OpenCV教程:juejin.cn/post/684490…
import cv2
# 1、文件的读取 2、封装格式解析 3、数据解码 4、数据加载
img = cv2.imread('canton.jpg',1)
cv2.imshow('image',img)
# jpg png 1、文件头 2、文件数据
cv2.waitKey (0)
# waitKey(0),以毫秒为单位延迟。0是指“永远”的特殊值
6.4 读取视频数据
Python读取视频最常用的库也是OpenCV。
import cv2 # 导入库
cap = cv2.VideoCapture("test.avi") # 获得视频对象
status = cap.isOpened() # 判断文件知否正确打开
# 输出基本属性
if status: # 如果正确打开,则获得视频的属性信息
frame_width = cap.get(3) # 获得帧宽度
frame_height = cap.get(4) # 获得帧高度
frame_count = cap.get(7) # 获得总帧数
frame_fps = cap.get(5) # 获得帧速率
print('frame width: ', frame_width) # 打印输出
print('frame height: ', frame_height) # 打印输出
print('frame count: ', frame_count) # 打印输出
print('frame fps: ', frame_fps) # 打印输出
# 读取视频内容并展示视频
success, frame = cap.read() # 读取视频第一帧
while success: # 如果读取状态为True
cv2.imshow('vidoe frame', frame) # 展示帧图像
success, frame = cap.read() # 获取下一帧
k = cv2.waitKey(int(1000 / frame_fps)) # 每次帧播放延迟一定时间,同时等待输入指令
if k == 27: # 如果等待期间检测到按键ESC
break # 退出循环
# 操作结束释放所有对象
cv2.destroyAllWindows() # 关闭所有窗口
cap.release() # 释放视频文件对象
6.5 读取语音数据
对于语音文件的读取,可以使用Python的audioop、aifc、wav等库实现。但针对语音处理这一细分领域,当前市场上已经具备非常成熟的 解决方案,例如科大讯飞、百度语音等,大多数情况下,我们会通过调用其API实现语音分析处理,或者作为分析处理前的预处理。
以百度语音API服务应用为例,说明如何通过请求百度语音的API,将语音数据转换为文字信息。
申请百度语音API教程:jingyan.baidu.com/article/f3e…
# 导入库
import json # 用来转换JSON字符串
import base64 # 用来做语音文件的Base64编码
import requests # 用来发送服务器请求
# 获得token
API_Key = 'DdOyOKo0VZBgdDFQnyhINKYDGkzBkuQr' # 从申请应用的key信息中获得
Secret_Key = 'oiIboc5uLLUmUMPws3m0LUwb00HQidPx' # 从申请应用的key信息中获得
token_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s" # 获得token的地址
res = requests.get(token_url % (API_Key, Secret_Key)) # 发送请求
res_text = res.text # 获得请求中的文字信息
token = json.loads(res_text)['access_token'] # 提取token信息
# 定义要发送的语音
voice_file = 'baidu_voice_test.pcm' # 要识别的语音文件
voice_fn = open(voice_file, 'rb') # 以二进制的方式打开文件
org_voice_data = voice_fn.read() # 读取文件内容
org_voice_len = len(org_voice_data) # 获得文件长度
base64_voice_data = base64.b64encode(org_voice_data).decode('utf-8') # 将语音内容转换为base64编码格式
# 发送信息
# 定义要发送的数据主体信息
headers = {'content-type': 'application/json'} # 定义header信息
payload = {
'format': 'pcm', # 以具体要识别的语音扩展名为准
'rate': 8000, # 支持8000或16000两种采样率
'channel': 1, # 固定值,单声道
'token': token, # 上述获取的token
'cuid': 'B8-76-3F-41-3E-2B', # 本机的MAC地址或设备唯一识别标志
'len': org_voice_len, # 上述获取的原始文件内容长度
'speech': base64_voice_data # 转码后的语音数据
}
data = json.dumps(payload) # 将数据转换为JSON格式
vop_url = 'http://vop.baidu.com/server_api' # 语音识别的API
voice_res = requests.post(vop_url, data=data, headers=headers) # 发送语音识别请求
api_data = voice_res.text # 获得语音识别文字返回结果
text_data = json.loads(api_data)['result']
print(api_data) # 打印输出整体返回结果
print(text_data) # 打印输出语音识别的文字
