

1.数据分析平台搭建的若干主题
笔者从事大数据功能平台建设若干年,在笔者就职的公司,业务分析人员常使用到如SparkSql, PySpark,hive,python等方式分析数据。搭建一个安全、稳定同时满足所有业务分析人员使用习惯的大数据功能分析功能平台并不是一个简单的任务,因为要考虑的东西比较多,笔者认为通常有以下几点。
-
1.资源的细粒度以及多维度管控。
-
2.多租户隔离。
-
3.多样的执行方式支持。
-
4.用户使用界面友好。
-
5.功能平台的稳定与高可用。
2.公司平台的现状以及问题
公司现在运行的平台主要是基于Zeppelin进行开发。我们同时在一套新的环境部署了Cloudera的一款开源产品——Livy。Livy在一定程度上结合了Spark JobServer和Zeppelin的优点,同时也解决了两者的一些痛点。相较于两位前辈,Livy的一大优势是能够支持Spark的Yarn-Cluster模式,因此有着比前两者有更强的扩展性。我们在技术选型的时候,也是看到了这个新兴开源项目的一些优势,准备在我们的平台进行部署以提升集群的能力。
Livy开放的用户提交作业的接口还是比较丰富的,用户可以通过三种方式进行提交:
-
1).使用LivyClient进行提交,这个方式需要实现编程接口,对于后台开发者友好,但是对于公司的数据分析人员就显得门槛较高了。
-
2).使用REST API的session接口提交代码片段,这个接口是数据分析人员最常使用的接口,他们将自己的脚本代码通过REST方式提交到Spark集群,然后从集群中获取作业执行的结果。
-
3).使用REST API的batch接口提交jar包执行,这个方式一般用来进行跑批任务。
我们在试用Livy的时候,发现他的优点在我们生产表现并不明显,反而缺点让我们有点头疼。例如它不支持sparksql的提交,同时他对其他类型的大数据作业如hive、单机python等不支持扩展。另外,livy没有提供对用户友好的界面,平台还需要针对接口进行前端的开发,这项工作从开发到调试到维护也是一项颇费人力的事情。另外LivyServer在当前还有单点的风险,这些使用上的缺点让我们组的人员对Livy这个新产品逐渐失去了兴趣。慢慢对Livy的支持也变少了。
3.意外的邂逅-Linkis
淘沙邂逅得黄金,莫便沙中著意寻。如诗所言,我在github上面搜索关于大数据IDE前端的相关开源项目时,看到微众银行最新开源的Scriptis项目(github.com/WeBankFinTe…) 的演示(www.oschina.net/p/scriptis)。觉得他们做的这款前端IDE产品几乎完美符合我们的业务分析人员的需求,操作友好,页面简洁,还有日志、进度这些用户关心内容的返回,瞬间被圈粉。深入了解之后,发现他与微众银行另一个开源的产品——Linkis(github.com/WeBankFinTe… )是配合使用的,当时就一个感觉,这么爽,直接可以打包使用啊。
Linkis官方文档介绍自己说是用了微服务的架构方式,向用户暴露了REST和websocket两种接口。内部将执行的微服务抽象成了 Entrance、EngineManager和Engine 三个微服务,我理解Entrance应该是用户作业的管理者,Engine是用户作业真正的执行者,EngineManager是Engine的启动者和管理者。Linkis还直接开源了Spark(sql、pyspark、scala)、hive、python、pipeline等四个Engine,支持的执行作业内容涵盖了我们公司平台的使用范围。
除了上面三个抽象,我觉得最吸引我的还是要属他们更细粒度和多维度的资源管理器,从事大数据平台建设这些年里,我觉得很头疼的一件事就是集群资源的管控,有时候也会出现队列资源被某些用户占光的问题。Linkis自身实现了一套资源管控的方案,他能将用户启动的Engine进行控制,这个功能非常瞩目。
另外,我要考察了他们多租户隔离的方案,他们的方案是用户启动Engine的时候,是要以服务器上的实名用户进行启动,这样启动的进程就是在该用户的权限下,该进程能够接触的数据也只能局限在该用户能操作的数据。
4.Linkis的测试试用
既然Linkis自己吹的这么好,还是有必要试一下的 ,趁着一个周末,我将他们最新的后台release包下载了下来,好家伙,将近500M,果然是一个很大的工程。
他们的安装还是比较简单的,需要配置好微服务的IP和端口,同时设定好一些必要的path,另外还有数据库的一些配置,执行他们的install.sh,执行完之后,start-all一下,然后去自己的Eureka地址那里看一下是否启动成功。当然启动并不是那么顺利,如果失败了,还是需要自己去查看一下日志,毕竟这个是第一个release版本,肯定有兼容问题。根据笔者的经验,需要启动的微服务有Gateway,datasource, publicService,PythonEntrance,PythonEngineManager(如果要执行python),要执行spark的话,需要spark的entrance和EM。
然后需要装上Scriptis,Scriptis的安装比较简单,只需要将gateway的ip和端口指定到nginx的配置文件中就可以了,然后直接启动成功。
用浏览器打开Scriptis的部署的ip和port之后,首先会需要登录,Linkis文档告诉我们他们使用的是LDAP的登陆方式,同时也开放了一个超级用户登录,就是这个linkis项目的部署用户,我用的是hadoop用户部署的,同时密码也是hadoop,然后直接登陆。登陆之后报了一个错,说是根目录不存在,查看日志后发现是需要为用户创建一个根目录,这个问题我觉得是微众银行应该是在用户管理的时候,首先会为用户新建根目录,然后用户才能有资格访问这个系统。不过没有问题,我们直接在服务器本地创建了一个目录就行。建好之后,刷新页面,如下面所示。
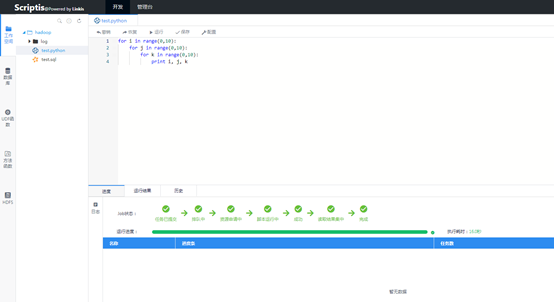
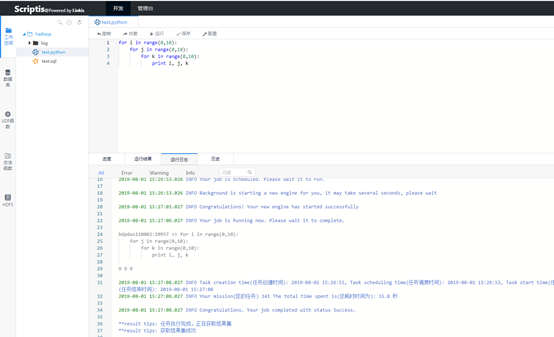
然后我迫不及待地新建了一个python脚本进行执行,因为毕竟这个最简单,不需要多余的环境变量配置。写完一个简单的脚本测试,经过一系列的过程之后,成功跑出了结果(* ̄︶ ̄)。日志、进度、状态等信息也是返回的很精确。
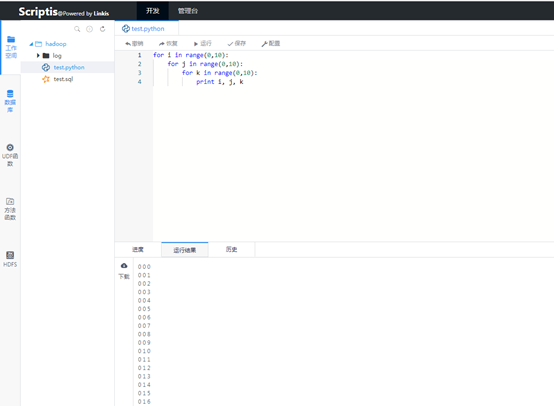
当然,单机的python能运行并不能说明问题,毕竟集群运行的spark和hive才是关键,新建了一个spark sql的脚本,然后点击运行,不出意外的,果然报错了(怎么可能会这么顺利的嘛),查看日志,我发现是spark在启动Engine去请求队列的资源的时候,报了一个队列不存在的问题,但是这个队列明明是存在的。
自己排查很久之后,没有能够解决。后来,我加入了他们的微信群,把这个问题提了出来,群里的工作人员让我排查了我的fair-scheduler.xml是不是正确的,最后才发现我们的hadoop版本是不一样的,我的hadoop版本是2.8+的,返回的json是他们的RM不能解析的,他们公司内部使用的是2.7.2,这个小小的兼容性问题让我和微众银行的同行也搞了好久。
后来解决之后,点击运行开始执行任务,他们引擎启动方式也是默认yarn-client方式,这次算是成功执行了(幸好我的spark版本是2.1.0),可以直接运行,结果也是正确的。
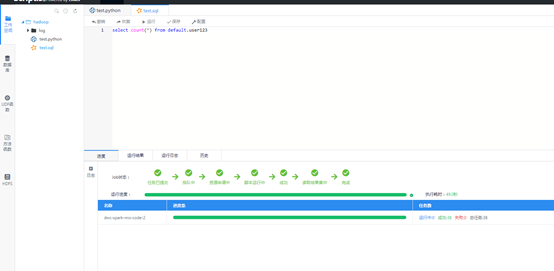
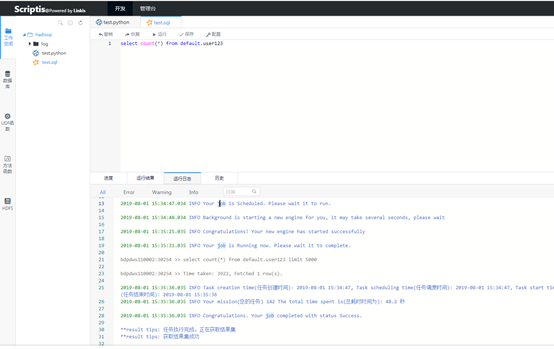
5.简单的总结
当然对一个刚刚开源的产品来说,Linkis是不可能直接拿来就用的,因为不知道这种重型后台项目能不能抗住生产性能的问题,还有各种安全的问题,需要在测试环境上做很多的验证才行。
另外Linkis本身对非微众银行的环境兼容性问题也是比较大的一个挑战,毕竟这个产品在他们银行能够跑得很好,其他的公司就不一定了。
当然,他的优势还是很明显的,前后台同时开源,独特的资源管理功能,使用了当下最新的微服务架构,这个架构模式对于技术人员来说,不论是学习还是使用,都有很大的借鉴意义,我觉得这个系统会在我们公司的测试环境先运行一两个月,查看一下Linkis的性能和兼容、安全问题,毕竟这是一款值得尝试和学习的好产品。
