

源码在https://github.com/Lotus-Blue/Python-crawls-douban-data-through-proxy-ip
爬虫最怕是被封ip,我相信很多爬虫新手都会傻傻地拿自己的ip用户爬取数据(顺序1的文件),前几次可能成功,但过了这个时间后,你会发现请求抛出403状态码,这是因为你的请求频率太高了,系统会认为你在爬虫,暂时把你的ip封了。
那如何解决这个问题呢?主要有下面三种办法
- 伪装请求报头(request header)
- 减轻访问频率,速度
- 使用代理IP
一般办法1作用不大,办法2的话又导致耗时太大,所以办法3是又省时又奏效的好办法
1、首先我们国内高匿代理IP 获得代理IP数据
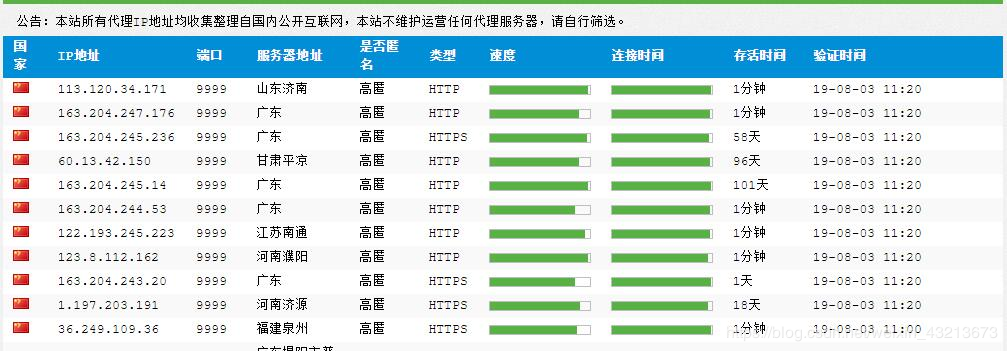
ip够你用的了,但是也不能任性,还是尽量不要同时运行多个爬虫程序
运行文件2之后,你会得到一个下面这样的文件
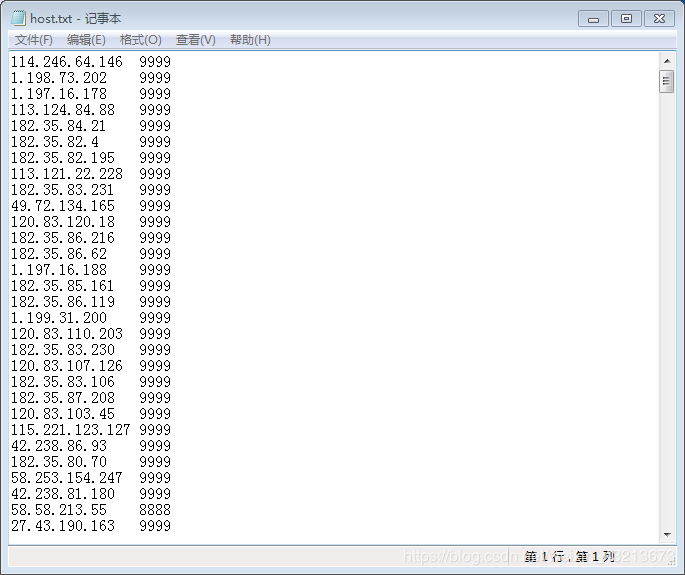
2、检验这些ip是否可用,经本人测试,一般都是状态码200,所以这步你忽略也没关系
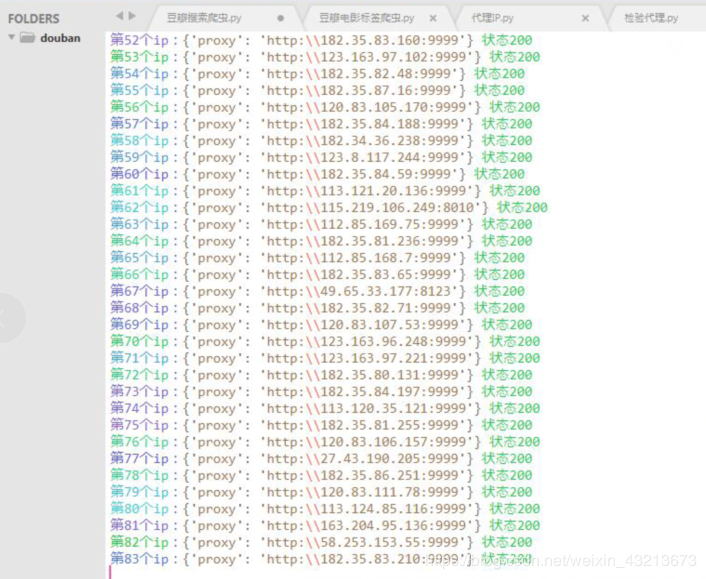
3、智能更换代理ip(但没有检验通过该代理,请求是否成功)
def change_proxy(proxies):
proxy=random.choice(proxies)
if proxy==None:
proxy_support=urllib.request.ProxyHandler({})
else:
proxy_support = urllib.request.ProxyHandler({"http": proxy})
opener = urllib.request.build_opener(proxy_support)
opener.addheaders=[("User-Agent",headers["User-Agent"])]
urllib.request.install_opener(opener)
print('智能切换代理:%s' % ('本机' if proxy == None else proxy))
4、检验通过该代理,请求是否成功
respones = requests.get(url, headers=headers, proxies=random.choice(proxys))
while respones.status_code!=200:
respones = requests.get(url, headers=headers, proxies=random.choice(proxys))
获取get接口
打开chrome的“检查”工具->切换到network界面->选择XHR,准备看网站的真实请求地址
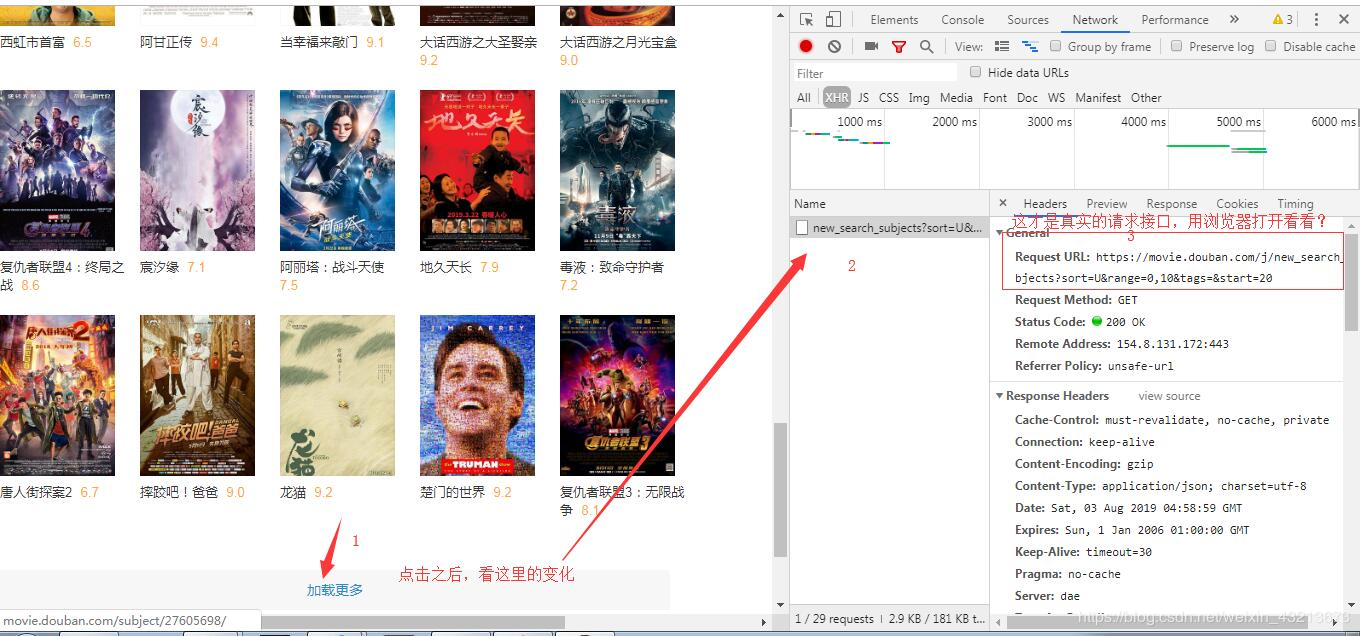
sort:按热度排序为T、按时间排序为R、按评分排序为S
tags:类型
countries:地区
geners:形式(电影、电视剧…)
start:“加载更多”
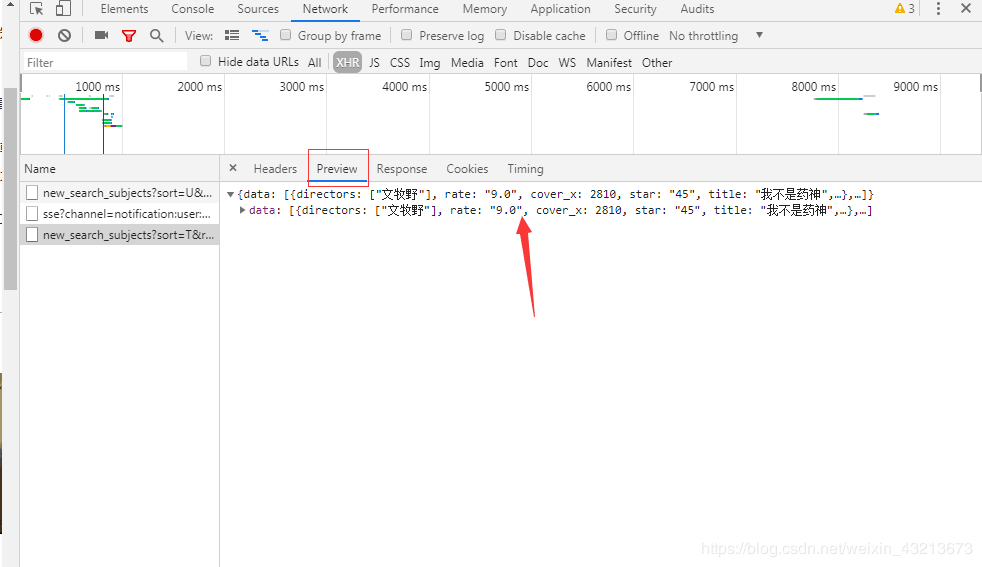
json数据是很好的
==总之先看下真实请求接口有没有好东西,没有的话再爬取网站源码数据==
