

Babel
Babel 是一个 JavaScript 编译器。
// Babel 输入: ES2015 箭头函数
[1, 2, 3].map((n) => n + 1);
// Babel 输出: ES5 语法实现的同等功能
[1, 2, 3].map(function(n) {
return n + 1;
});
Babel通过转换,让我们写新版本的语法,转换到低版本,这样就可以在只支持低版本语法的浏览器里运行了。
Babel真厉害,它居然‘认识’代码、更改代码。那Babel就是操作代码的代码,酷。
学习Babel对我们能力的提升有很大帮助,我们平时都是用代码来操作各种东西,这次我们操作的对象,变成了代码本身。
这个认识和操作代码的过程,学名叫做代码的静态分析。
代码的静态分析
先来看一个问题,编辑器里代码的高亮,如下:
编辑器可以把代码不同的成员,标记为不同的颜色。显然编辑器要‘认识’代码,对代码进行分析和处理,才能达到这种效果。这就叫代码的静态分析。
静态分析 VS 动态分析
静态分析是在不需要执行代码的前提下对代码进行分析的处理过程。
动态分析是在代码的运行过程中对代码进行分析和处理。上面的代码高亮属于静态分析,在代码没有运行的情况下,进行分析和处理的。
静态分析的用处
静态分析不光能高亮代码,还有就是代码转换,还可以对我们的源代码进行优化、压缩等操作。
AST (抽象语法树)
在对代码静态分析的过程中,要将源码转换成AST (抽象语法树)。
为什么会有AST
源代码对于Babel来说,就是一个字符串。Babel要对这个字符串进行分析。我们平时对字符串的操作,就是使用字符串方法或是正则,但相对字符串(源码)进行复杂的操作,远远不够。
需要将字符串(源码)转换成树的数据结构,才好操作。这个树结构,就叫AST(抽象语法树)。
这里我想到 程序 = 数据结构 + 算法。我们平时写的业务需求,对数据结构要求不高,简单的对象和列表就可以搞定,但要某些特定的复杂问题,比如现在研究的操作代码,就需先思考:我应该把操作的事物放到什么样的数据结构上,才更容易我写算法/逻辑。
把源码解析成AST
对于源码,此时我们就把它看出一个字符串,对其分析的第一步,肯定是先把源码转换成AST,才好后续操作。
有一个在线AST转换器,我们在这上面可以做实验,写出的代码,它就帮我们翻译成AST:
我什么都不写,AST就有一个根结点了:
// AST
{
"type": "Program",
"start": 0,
"end": 0,
"body": [],
"sourceType": "module"
} // 可以看成是一个对象,有一些字段,这代码树的根结点。
然后我写一句代码:
// 源码
const text = 'Hello World';
// AST
{
"type": "Program",
"start": 0,
"end": 27,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 27,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 26,
"id": {
"type": "Identifier",
"start": 6,
"end": 10,
"name": "text"
},
"init": {
"type": "Literal",
"start": 13,
"end": 26,
"value": "Hello World",
"raw": "'Hello World'"
}
}
],
"kind": "const"
}
],
"sourceType": "module"
}
懵逼,一句const text = 'Hello World'; 就生成这么多东西。看懂它、理解AST是学习Babel的第一个门槛。
理解AST
看下图,这就是AST Explorer的界面,左边写代码,右边就帮助我们翻译成AST,AST有两种表达方式,Tree和JSON,上面都是用JSON形式表示AST,后来我发现还是用Tree的形式看更容易些,因为Tree的形式更突出节点的类型:
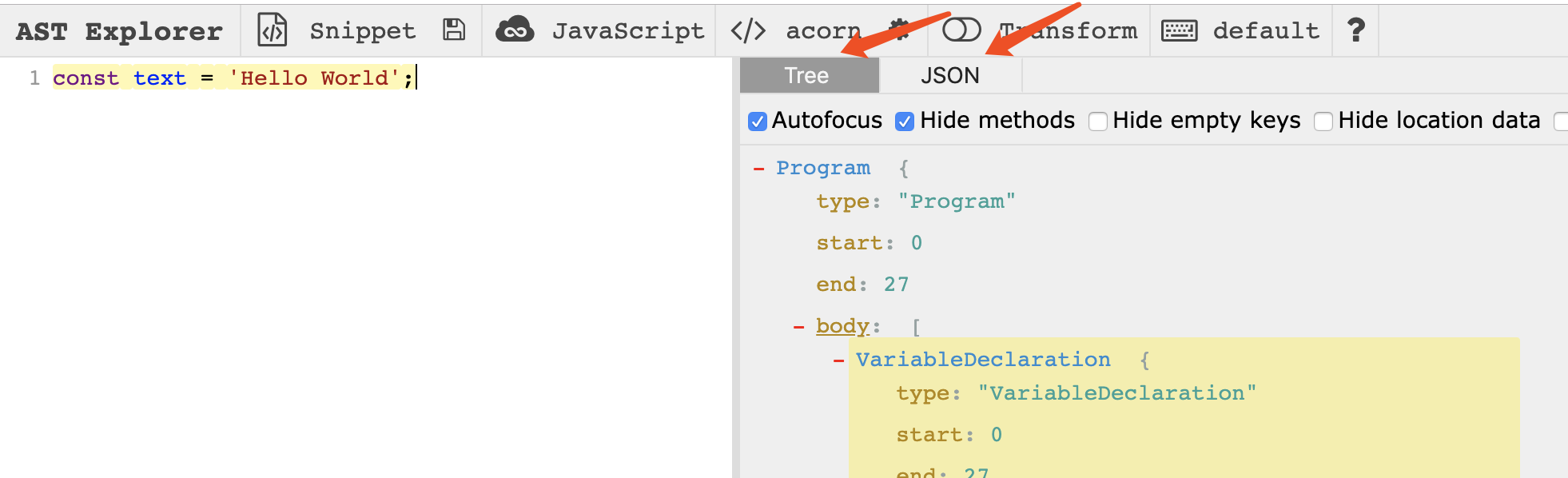
我将AST表达的树画出来,如下:
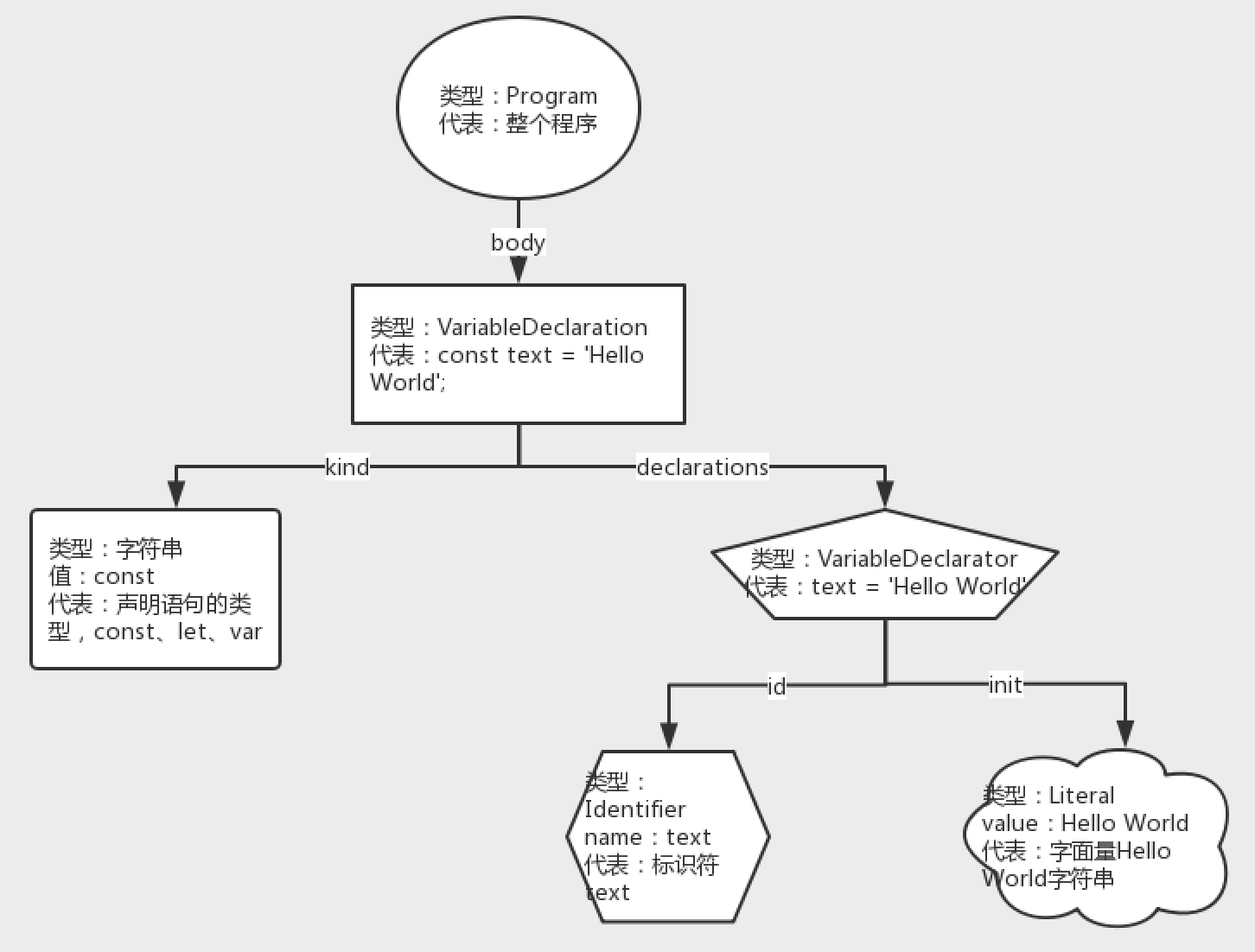
总结AST树的特点:
- 节点是有类型的。我们学习树这种数据结构时,节点都是最简单的,这里复杂了,有类型。
- 节点与子节点的关系,是通过节点的属性链接的。我们学习的树结构,都是left、right左孩子右孩子的。但是AST树,不同类型的节点,属性不同,Program类型节点的子节点是它的body属性,VariableDeclaration类型的子节点,是它的declarations、kind属性。也就是节点的属性看作是节点的子节点,并且子节点也可能有类型,近而形成一个树。
- 父节点是所有子节点的组合,我们可以看到VariableDeclaration代表的const text = 'Hello World'被拆分成了下面两个子节点,子节点又继续拆分。
希望能从上面的分析中,让大家对AST有一个最直观的认识,就是节点有类型的树。
那么节点的类型系统就很必要了解了,这里是Babel的AST类型系统说明。大家可以看看,可以说类型系统是抽象了代码的各种成员,标识符、字面量、声明、表达式。所以拥有这些类型的节点的树结构,可以用来表达我们的代码。
参照类型系统,多实验,我们就会对AST的结构大体掌握和理解了。
额外:V8引擎也用到AST
额外提一下,V8中也用到了AST。V8引擎有四个主要模块:
- 转换器Paser:将源代码转换成AST。
- 解释器:将AST转换为Bytecode。
- 编译器:将Bytecode转换为汇编代码。
- 垃圾回收模块:负责管理内存空间回收。
可以看到AST也是V8执行的关键一环。下面下来看看Babel对于AST的利用,及运行步骤。
Babel 的处理步骤
回看Babel的处理过程
- 解析(parse)。将源代码变成AST。
- 转换(transform)。操作AST,这也是我们可以操作的部分,去改变代码。
- 生成(generate)。将更改后的AST,再变回代码。
解析器 babylon
第一步:解析,Babel中的解析器是babylon。我们来体验一下:
// 安装
npm install --save babylon
// 实验代码
import * as babylon from "babylon";
const code = `const text = 'Hello World';`;
const ast = babylon.parse(code);
console.log('ast', ast);
code变量是我们的源代码,ast变量是AST,我们看一下打印结果:

和我们预期的一样,得到AST了。这里我注意到还有start、end、loc这样位置信息的字段,应该可以对生成Source Map有用的字段。
转换器 babel-traverse
第二步:转换。得到ast了,该操作它了,Babel中的babel-traverse用来干这个事。
// 安装
npm install --save babel-traverse
// 实验代码
import * as babylon from "babylon";
import traverse from "babel-traverse";
const code = `const text = 'Hello World';`;
const ast = babylon.parse(code);
traverse(ast, {
enter(path) {
console.log('path', path);
}
})
console.log('ast', ast);
babel-traverse库暴露了traverse方法,第一个参数是ast,第二个参数是一个对象,我们写了一个enter方法,方法的参数是个path,咋不是个node呢?我们看一下输出:
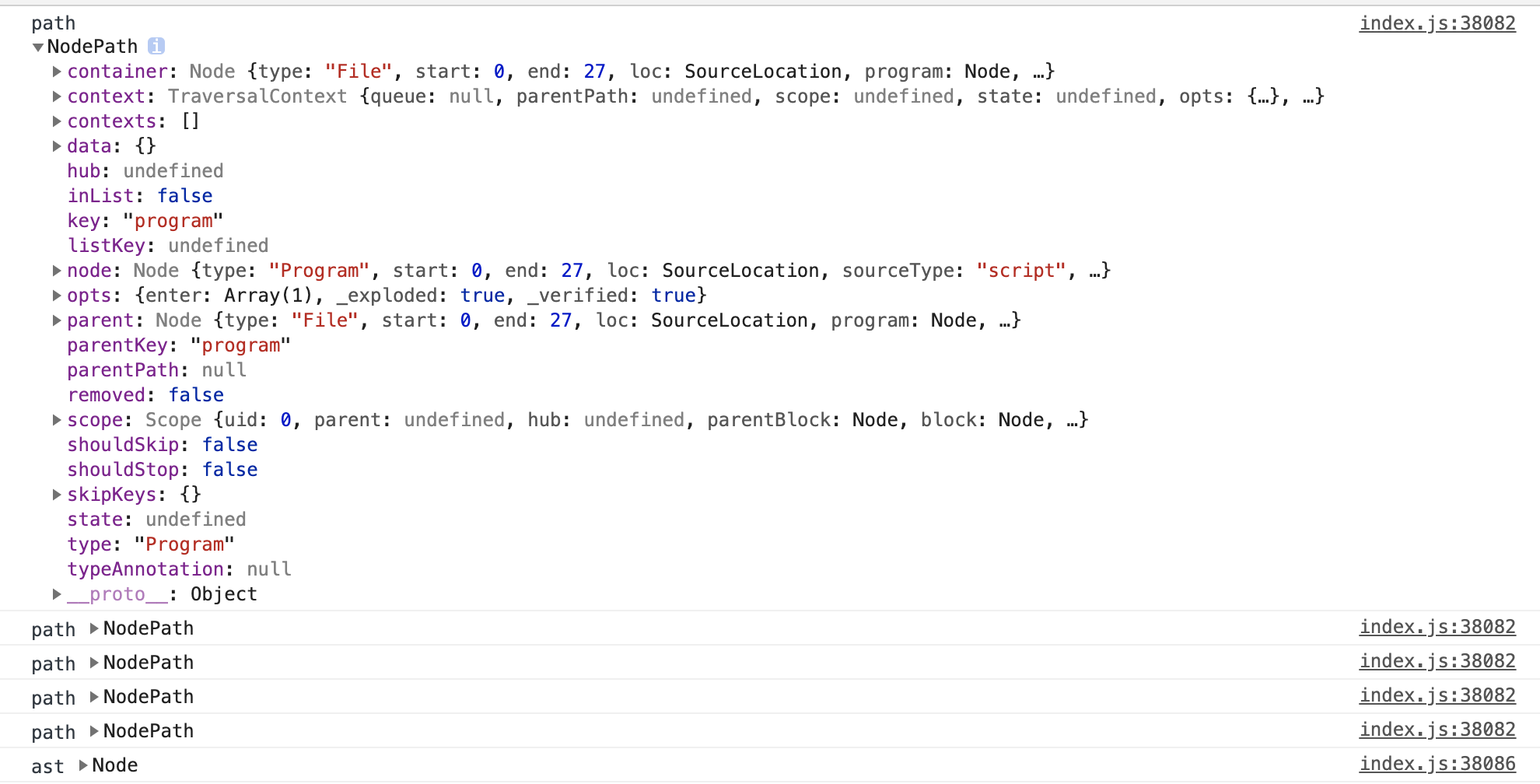
path被打印了5次,ast上确实也是有5个节点,是对应的。traverse方法是一个遍历方法,path封装了每一个节点,并且还提供容器container,作用域scope这样的字段。提供个更多关于节点的相关的信息,让我们更好的操作节点。
我们来做一个变量重命名操作:
import * as babylon from "babylon";
import traverse from "babel-traverse";
const code = `const text = 'Hello World';`;
const ast = babylon.parse(code);
traverse(ast, {
enter(path) {
if (path.node.type === "Identifier"
&& path.node.name === 'text') {
path.node.name = 'alteredText';
}
}
})
console.log('ast', ast);
看结果:

确实我们的ast被更改了,用这个ast生成的code就会是const alteredText = 'Hello World';
babel-traverse的Lodash : babel-types
在利用babel-traverse操作AST时,也可以利用工具库帮助我们写出更加简洁有效的代码,就可以使用babel-types。
npm install --save babel-types
import * as babylon from "babylon";
import traverse from "babel-traverse";
import * as t from "babel-types";
const code = `const text = 'Hello World';`;
const ast = babylon.parse(code);
traverse(ast, {
enter(path) {
// 使用babel-types
if (t.isIdentifier(path.node, { name: "text" })) {
path.node.name = 'alteredText';
}
}
})
console.log('ast', ast);
使用babel-types实现和上例中一样的功能,代码量更少了。
生成器 babel-generator
第三步:生成。得到操作后的ast,该生成新代码了。Babel中的babel-generator用来干这个事。
npm install --save babel-generator
// 加入babel-generator
import * as babylon from "babylon";
import traverse from "babel-traverse";
import * as t from "babel-types";
import generate from "babel-generator";
const code = `const text = 'Hello World';`;
const ast = babylon.parse(code);
traverse(ast, {
enter(path) {
if (t.isIdentifier(path.node, { name: "text" })) {
path.node.name = 'alteredText';
}
}
})
const genCode = generate(ast, {}, code);
console.log('genCode', genCode);
来看打印结果:

nice! 在code字段里,我们看到里新生成的代码。
当然,上面提到的这四个库,还有更多细节,有兴趣的可以再研究研究。
这些库的集合,就是我们的Babel。
插件
我们研究过了Babel的内部,现在跳出来,我们需要在外部操作AST,而不是进Babel内部去改traverse。
从外部操作AST,就需要插件了。我们来研究一个插件babel-plugin-transform-member-expression-literals
使用次插件后:
// 转换前
obj.const = "isKeyword";
// 转换后
obj["const"] = "isKeyword";
我们再来看看这个插件的源码:
{
name: "transform-member-expression-literals",
visitor: {
MemberExpression: {
exit({ node }) {
const prop = node.property;
if (
!node.computed &&
t.isIdentifier(prop) &&
!t.isValidES3Identifier(prop.name)
) {
// foo.default -> foo["default"]
node.property = t.stringLiteral(prop.name);
node.computed = true;
}
},
},
},
};
}
这里我尝试将它放到我们的实验代码里,如下:
import * as babylon from "babylon";
import traverse from "babel-traverse";
import * as t from "babel-types";
import generate from "babel-generator";
const code = `const obj = {};obj.const = "isKeyword";`;
const ast = babylon.parse(code);
const plugin = {
MemberExpression: {
exit({ node }) {
const prop = node.property;
console.log('node', node);
if (
!node.computed &&
t.isIdentifier(prop)
// !t.isValidES3Identifier(prop.name) 这里注释掉,我们的t里没这个方法
) {
// foo.default -> foo["default"]
node.property = t.stringLiteral(prop.name);
node.computed = true;
}
},
},
};
traverse(ast, plugin)
const genCode = generate(ast, {}, code);
console.log('genCode', genCode);
输出的代码是"const obj = {};obj["const"] = "isKeyword";"。符合预期,也就是说,Babel的插件,会传给内部的traverse方法。并且是一种符合访问者模式的,让我们可以针对节点类型(如这里的visitor.MemberExpression)的操作。这里用的是exit,而不是enter了,解释一下,traverse是对树的深度遍历,向下遍历这棵树我们进入(entry)每个节点,向上遍历回去时我们退出(exit)每个节点。就是对于AST,traverse遍历了两遍,我们可以选择在进入还是退出的时候,操纵节点。
结束语
我的参考:
今天的研究就到这里,理解Babel内部机制和基本的插件工作方式。
