import numpy as np
name = ['Alice', 'Bob', 'Cathy', 'Doug']
age = [25, 45, 37, 19]
weight = [55.0, 85.5, 68.0, 61.5]
x = np.zeros(4,dtype=int)
data = np.zeros(4,dtype={'names':('name','age','weight'),
'formats':('U10','i4','f8')})
print(data.dtype)
data['name'] = name
data['age'] = age
data['weight'] = weight
print(data)
data['name']
data[0]
data[-1]['name']
data[data['age'] < 30]['name']
np.dtype({'names':('name', 'age', 'weight'),
'formats':('U10', 'i4', 'f8')})
np.dtype({'names':('name', 'age', 'weight'),
'formats':((np.str_, 10), int, np.float32)})
np.dtype([('name', 'S10'), ('age', 'i4'), ('weight', 'f8')])
np.dtype('S10,i4,f8')
'''
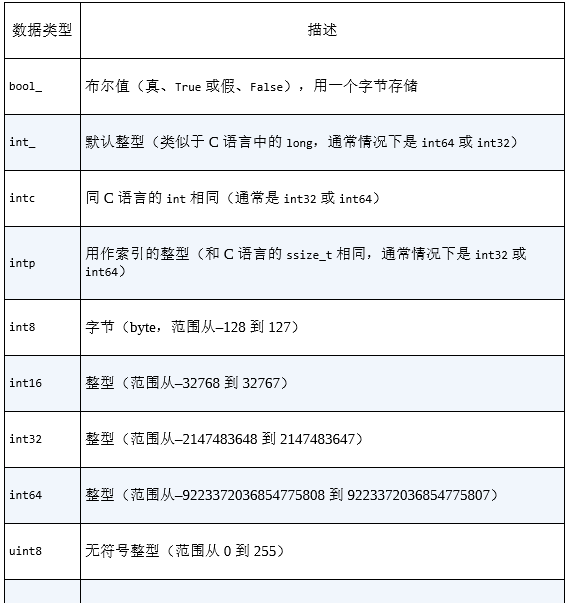
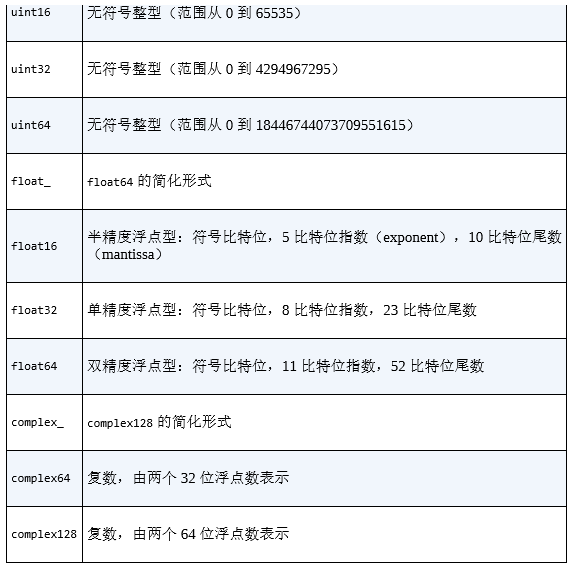
第一个(可选)字符是 < 或者 >,分别表示“低字节 序”(little endian)和“高字节序”(bid endian),
表示字节(bytes)类 型的数据在内存中存放顺序的习惯用法。
后一个字符指定的是数据的类 型:字符、字节、整型、浮点型,等等(如表 2-4 所示)。
最后一个字 符表示该对象的字节大小。
'''
tp = np.dtype([('id','i8'),('mat','f8',(3,3))])
X = np.zeros(1,dtype=tp)
print(X[0])
print(X['mat'][0])
data_rec = data.view(np.recarray)
data_rec.age
%timeit data['age']
%timeit data_rec['age']
%timeit data_rec.age