

近日LinkedIn又开源了一个新工具Brooklin,一个近实时分布式可扩展的流数据服务。Brooklin从2016年开始在LinkedIn线上运行,每天处理数千条数据流和2万亿条消息。
为什么开发Brooklin
高速、可靠地传输大规模数据已经不是LinkedIn唯一需要解决的问题,快速增加的数据存储和流式系统的多样性的带来的问题一样十分严峻,LinkedIn构建Brooklin用来解决对系统可扩展性方面的新需求,即系统既要在数据规模方面可扩展,又要在系统多样性方面可扩展。
Brooklin是什么
Brooklin是一个分布式系统,用于跨多个不同的数据存储和消息系统流式传输数据,具有高可靠性。
它暴露了一系列的抽象,通过编写新的Brooklin消费者和生产者,可以扩展其功能,实现从新系统消费和生成数据。
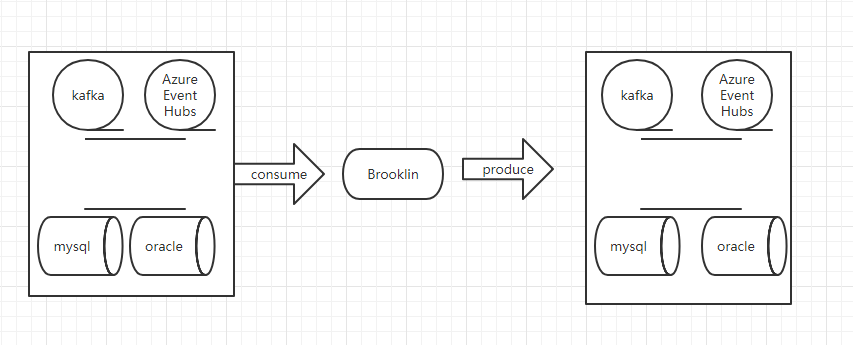
Brooklin 用例
Brooklin有两大类用例:流桥和变更数据捕获。
数据流桥(stream bridge)
数据可以分布在不同的环境(公共云和公司数据中心),地理位置或不同的部署组中。通常,由于访问机制、序列化格式、合规性和安全性等需求都会增加额外的复杂性。Brooklin可以作为这些环境之间传输数据的一个桥。比如,Brooklin可以在不同的云服务之间、一个数据中心不同的集群之间、甚至不同的数据中心之间传输数据。
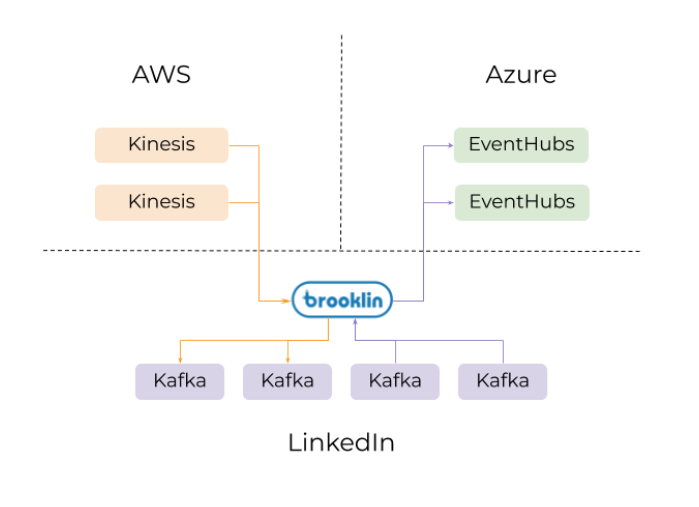
图2 一个假设场景::一个brooklin集群被用作流桥来传输数据,数据从Kinesis传入kafka,再从kafka传入EventHubs
由于Brooklin是一个在不同环境间传输数据流的专属服务,所有的复杂性都可以在一个服务中被管理,所以开发者可以把注意力集中于数据的处理而非传输。此外,这种集中式的、托管式的、可扩展的框架可以让组织实施策略和促进数据治理。举例说明,Brooklin可以配置实施公司范围的策略,比如所有数据流都必须是json格式,或者流中的任何数据都必须是加密的。
Kafka mirroring
在Brooklin之前,Kafka集群之间的的数据传输是通过Kafka MirrorMaker(KMM)实现的,但是它在大规模传输方面存在问题。而Brooklin被设计为传输流数据的通用桥,所以它可以轻松的传输极大规模的kafka数据。
在LinkedIn,一个使用Brooklin作为流桥的例子就是在Kafka集群及数据中心之间镜像kafka数据。
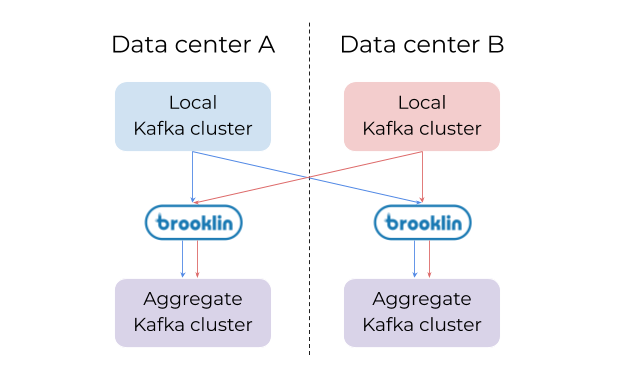
图3 一个假设场景::通过使用Brooklin,让用户在一个数据中访问所有的数据变得很容易。每个数据中心里,一个单独的Brooklin集群可以处理多个source/destination对。
Brooklin镜像kafka数据的方案已经在LinkedIn通过大规模测试,并且已经完全取代KMM。通过使用这个方案,解决了KMM的一些痛点,并从它的新特性中受益,这些特点在下面讨论.
特性1 Multitenancy(多租户)
在KMK部署模型中,镜像只能在两个Kafka集群之间进行。这就造成要为每个数据pipeline都搭建一个KMM,结果就是会出现几十上百个KMM集群,这会造成管理十分困难。但是,Brooklin被设计成可以同时管理不同的数据pipeline,所以我们只需部署一个Brooklin集群就可以了。通过对比图3和图4,你可以有一个更直观的感受。
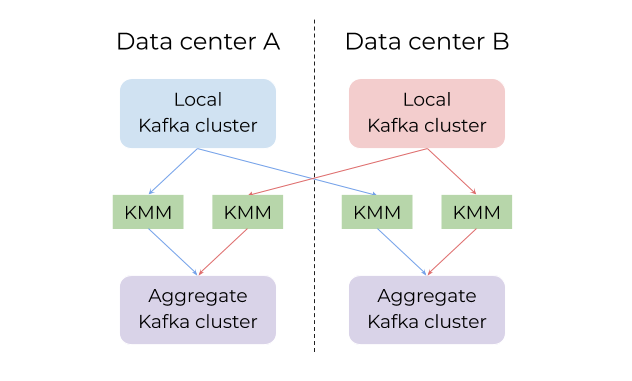
图4 一个假设场景: 使用KMM来实现跨数据中心的数据镜像
特性2 Dynamic provisioning and management(动态配置和管理)
使用Brooklin,只需对REST端点进行HTTP调用即可轻松完成创建新data pipeline(也称为data stream)和修改现有data pipeline。对于Kafka镜像用例,此端点可以非常轻松地创建新的镜像管道或修改现有管道的镜像白名单,而无需更改和部署静态配置。
虽然镜像管道可以在同一个集群中共存,但Brooklin可以单独控制和配置每个管道。例如,可以编辑管道的镜像白名单或向管道添加更多资源,而不会影响任何其他管道。此外,Brooklin允许按需暂停和恢复单个管道,这在临时操作或修改管道时非常有用。对于Kafka镜像用例,Brooklin支持暂停或恢复整个管道,白名单中的单个主题,甚至单个主题分区。
特性3 Diagnostics(诊断)
Brooklin还公开了一个诊断REST端点,可以按需查询数据流的状态。此API可以轻松查询管道的内部状态,包括任何单个主题分区滞后或错误。由于诊断端点整合了整个Brooklin集群的所有发现,因此这对于快速诊断特定分区的问题非常有用,而无需扫描日志文件。
Special features(特殊功能)
由于Brooklin被用来替代KMM,所以Brooklin在稳定性和可操作性方面做了优化。另外还专门为Kafka镜像提供了一些特性。
- 故障隔离: 最重要的是,我们努力实现更好的故障隔离,因此镜像特定分区或主题的错误不会像使用KMM那样影响整个管道或集群。 Brooklin能够在分区级别检测错误并自动暂停这些有问题的分区的镜像。这些自动暂停的分区可以在一段可配置的时间后自动恢复,这样就不需要手动干预,对瞬态错误特别有用。同时,其他分区和管道的处理不受影响。
- 无刷生成模式: 为了改善镜像延迟和吞吐量,Brooklin Kafka镜像还可以在无刷生成模式(flushless-produce mode)下运行,其中Kafka消耗进度在分区级别进行跟踪。检查点是针对每个分区而不是管道级别完成的。这允许Brooklin避免进行昂贵的Kafka生产者刷新调用,这是同步阻塞调用,通常可以使整个流水线停顿几分钟。
通过使用Brooklin替代KMM,LinkedIn将镜像集群从几百个降低到了十几个。同时,这也提高了添加新功能和提升的迭代速度。
Change data capture (CDC)
Brooklin的第二类主要用例是变更数据捕获。这些情况下的目标是以低延迟更改流的形式流式传输数据库更新。例如,LinkedIn的大部分真实数据(例如作业,连接和配置文件信息)都驻留在各种数据库中。有些应用程序有兴趣了解何时发布新作业,建立新的专业连接或更新成员的个人资料。而不是让这些感兴趣的应用程序中的每一个都对在线数据库进行昂贵的查询以检测这些变化,而不是实时地流式传输这些数据库更新。使用Brooklin生成变更数据捕获事件的最大优势之一是应用程序和在线存储之间更好的资源隔离。应用程序可以独立于数据库进行扩展,从而避免了数据库宕机的风险。使用Brooklin,我们在LinkedIn为Oracle,Espresso和MySQL构建了变更数据捕获解决方案;此外,Brooklin的可扩展模型有助于编写新的连接器,为任何数据库源添加CDC支持。
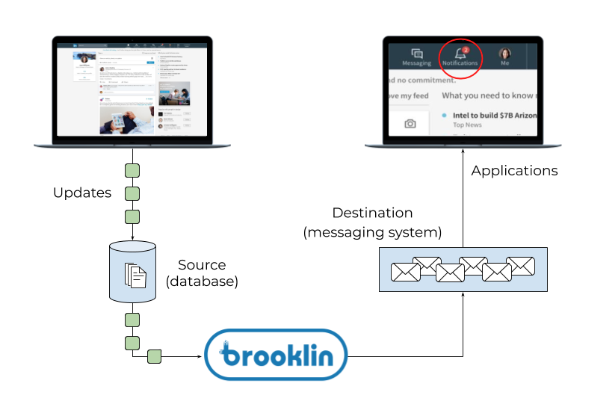
图5
特性1 Bootstrap support(初始化支持)
有时,在使用增量更新之前,应用程序可能需要数据存储的完整快照。当应用程序第一次启动或者由于处理逻辑的更改而需要重新处理整个数据集时,可能会发生这种情况。 Brooklin的可扩展连接器模型可以支持这种用例。
特性2 Transaction support(事务支持)
许多数据库都有事务支持,对于这些源,Brooklin连接器可以确保维护事务边界。
更多信息
有关Brooklin的更多信息,包括其架构和功能的概述,请查看我们之前的工程博客文章。
在Brooklin的第一个版本中,引进了Kafka镜像功能,可以使用我们提供的简单指令和脚本来测试驱动器。我们正在努力为项目增加对更多来源和目的地的支持 - 敬请期待!
未来
自2016年10月以来,Brooklin已成功运行于LinkedIn生成环境。它已取代Databus作为Espresso和Oracle源的变更捕获解决方案,是我们在Azure,AWS和LinkedIn之间移动数据的流桥解决方案,包括镜像我们众多kafka集群一天数万亿条的消息。
我们将继续构建连接器以支持其他数据源(MySQL,Cosmos DB,Azure SQL)和目标(Azure Blob存储,Kinesis,Cosmos DB,Couchbase)。我们还计划为Brooklin添加优化功能,例如基于流量需求进行自动扩展的功能,在镜像方案中跳过解压缩和重新压缩消息以提高吞吐量的能力,以及额外的读写优化。
项目地址
总结
- Brooklin是个分布式数据流传输服务,可以对接不同类型的数据存储和消息系统
- Brooklin目前已经实现了Kafka镜像功能,并提供多租户、动态配置和管理、诊断、故障隔离、无刷生成模式等特细。
- Brooklin还提供CDC功能,但是目前仅支持Espresso和Oracle源,还没有Mysql,Azure SQL等连接器
