

什么是zookeeper?
zookeeper一种分布式协调服务,提供类似文件系统的目录节点树结构的存储方式。注意它不是专门用来存储数据的,而是用来维护和监控存储的数据,可以用zookeeper实现:统一配置管理、分布式锁、集群管理;是分布式一致性的解决方案。
以下为树形结构图:
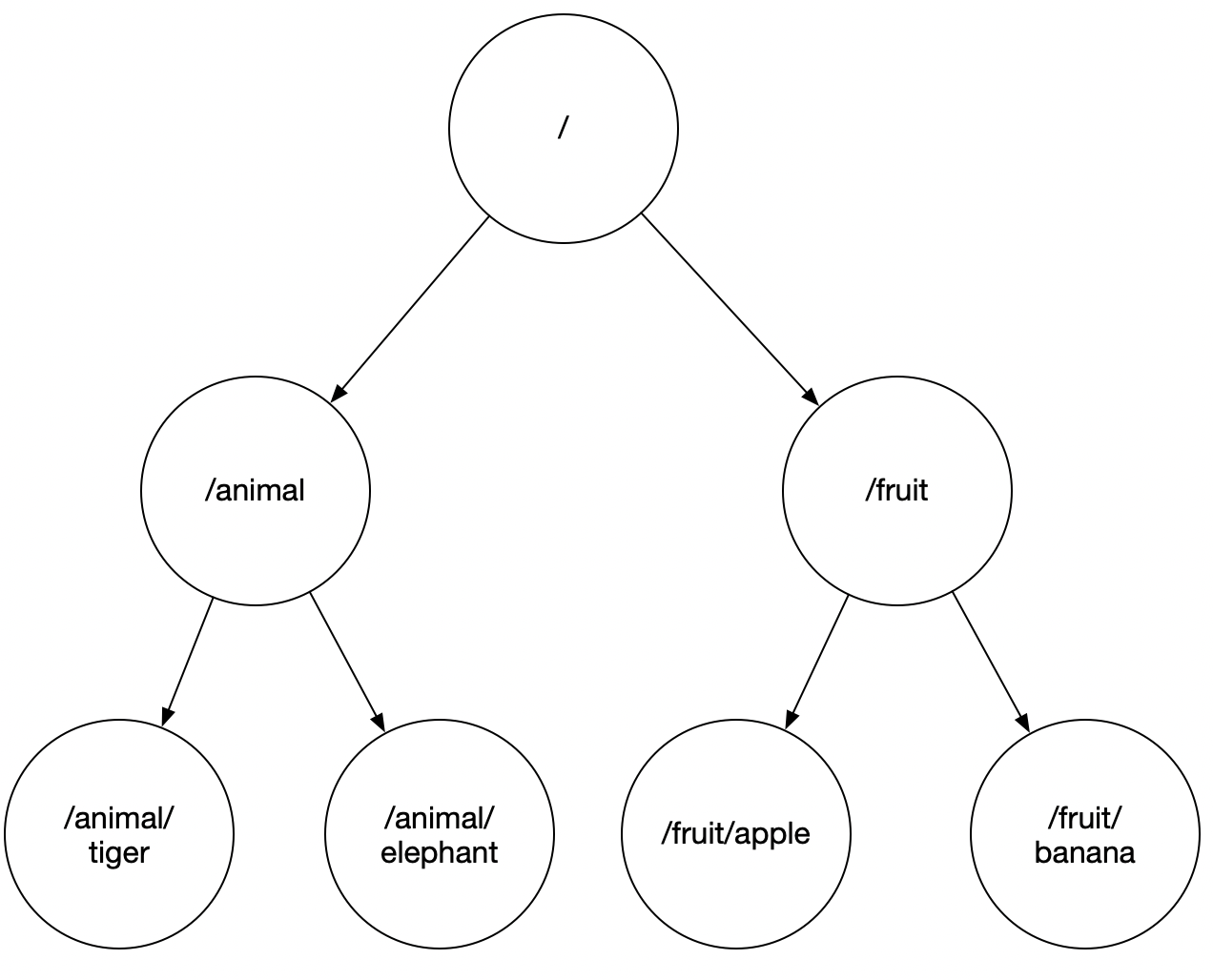
数据模型
与Linux的目录结构不同,Linux存在文件与目录的区别,zookeeper中最小的单位是znode节点,每个znode节点中存储内容包括:数据内容、子节点引用、访问权限、元数据(事务ID、版本号、时间戳、大小)
znode类型
持久节点:一旦创建,将一直保存在zookeeper中,除非主动删除节点
临时节点:生命周期与会话session绑定,一旦会话失效,也将自动清除
监听机制
zookeeper中的watcher机制,实现分布式系统的发布/订阅功能。
可以理解为,注册在指定znode节点上的触发器,当执行create、delete、setData方法时,将会执行注册在节点上对应事件,订阅的客户端也将收到异步通知
zookeeper与CAP关系
Consistency一致性--表示同一时间点,所有节点的数据保持一致,客户端获取数据也就能保证一致
Availability可用性--表示客户端获取数据,任意时刻都能收到响应
Partition tolerance分区容错性--表示当出现网络故障或分区故障,比如有几个节点宕机时,仍然可以提供一致性或可用性的服务
zookeeper是满足CP的,即任何时刻对zookeeper的请求,都能得到一致的数据结构,当遇到并发的时候,可能会抛弃一些请求。
zookeeper实现原理分析
集群网络结构
zookeeper集群包括一个leader以及多个follower,leader是通过内部选举实现的。每一个节点之间都实现互相通信,如果leader挂了,follower会立刻选举出新的leader保证系统可用。
zookeeper中的数据保存在内存中,同时也会持久化到磁盘中。
zookeeper读写数据
写数据时,如果一个follower收到写请求,会转发到leader,leader先本地写数据,然后根据内部的ZAB协议进行原子广播,等待所有的follower写完数据,并且恢回复ack,一次写请求才成功,zookeeper服务器才会回复客户端响应
读数据时,因为每一个节点都保持强一致性,所以每个节点的数据一致,读数据时,在任何一个节点上都可以
zookeeper工作原理
zookeeper的核心是广播,保证leader服务器与follower服务器之间的同步,实现这种机制的核心是ZAB协议。
ZAB原子消息广播,专门为zookeeper设计,用来支持崩溃恢复和消息广播的算法。核心思想是所有的客户端请求都会由一个全局唯一的leader服务器来协调处理,它会将请求转化为事务提议(Proposal),并且分配一个唯一的事务ID(zxid)然后分发给所有的follower;之后leader将等待follower执行完之后,回复ACK到leader,当收到超过半数以上的ACK回复,leader会再次向所有的服务器发送commit指令,提交上一次的事务提议
ZAB采用的是一种简化版的2PC模式,只需要等到半数以上的回复,而不是等待所有的follower回复,因为等待所有的回复,容易造成很大的阻塞,影响线程
ZAB协议规定,leader节点会给每一个follower创建一个专属的FIFO消息队列,将需要发送到follower的消息都通过异步的方式发送到队列,实现解耦,效率更高
ZAB协议的模式分为崩溃恢复和消息广播
当整个服务框架启动、leader出现宕机或网络中断时,ZAB协议会从所有的节点中选举出一个节点作为leader节点,同时集群中有超过半数以上节点已经完成与leader的数据同步后,ZAB协议退出崩溃恢复模式,进入消息广播模式。
如果此时新加入一个支持ZAB协议的节点加入到集群中,如果集群中已经存在leader节点,则新加入节点直接进入数据同步,完成后进入消息广播模式。
选举过程
looking
首先每一个节点发起投票,投票中包含了自己的服务器ID和本地最新的zxid,当节点收到其他节点的投票后,会先进行筛选,选出zxid最大的一个节点,并发起第二次投票,在每一次投票后,都会统计是否存在某一个节点得到半数以上的选票,如果存在,则选为leader进入discovery状态
discovery
新选为leader的节点需要向其他follower节点发送指令,每个节点回复本地最新事务ID,leader进行比较选择最新的zxid,并更新本地事务日志
synchronization
同步阶段,leader将最新的事务日志发送给所有的follower完成数据同步
