

1.前言
浏览器输入url到服务器接受数据: juejin.cn/post/684490…
- 经过上面的步骤,数据到达服务器
- 服务器根据TCP协议把数据包还原成请求参数
- 通知到指定的Tomcat
- tomcat分内置和外置,以前普通Spring都需要额外配置Tomcat;而Springboot简化了其中配置,并内置了Tomcat,只需要配路径和端口号即可;
- 内置和外置Tomcat的启动有一定的区别;
2.重要步骤
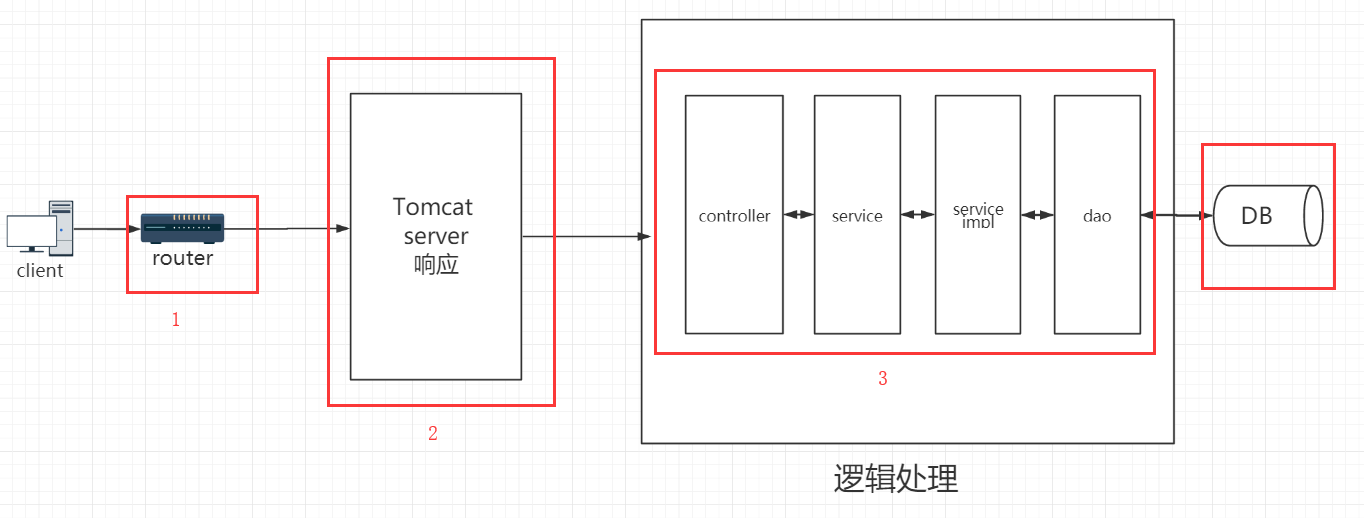
- client发送请求,服务器接收到请求;
- 服务器根据TCP协议把数据包还原成请求参数;
- 服务器把请求转发到对应的Tomcat server上;
- Tomcat接收到请求,找到对应端口,并进行host匹配;
- 业务逻辑处理结束后返回所需的对象,封装HttpResponse;
2.1 Tomcat响应
假设来自客户的请求为: http://localhost:8080/wsota/wsota_index.jsp
主要步骤如下:
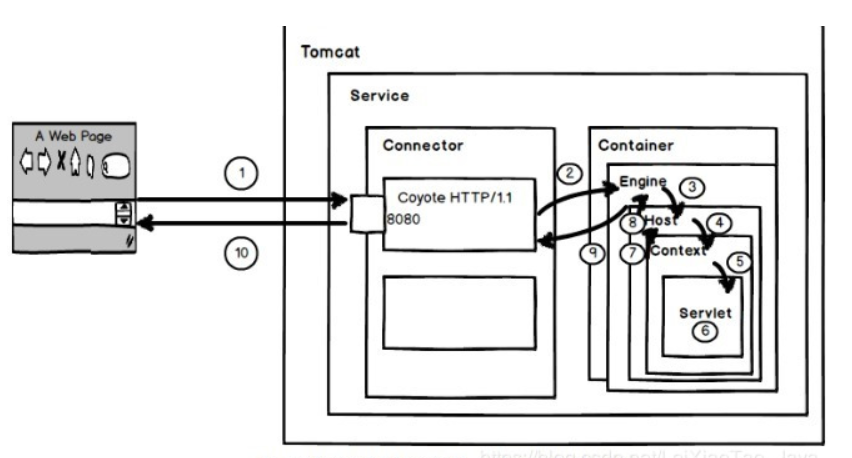
- 请求被发送到本机端口8080,被在那里侦听的Coyote HTTP/1.1 Connector获得
- Connector把该请求交给它所在的Service的Engine来处理,并等待来自Engine的回应
- Engine获得请求localhost/wsota/wsota_index.jsp,匹配它所拥有的所有虚拟主机Host
- Engine匹配到名为localhost的Host(即使匹配不到也把请求交给该Host处理,因为该Host被定义为该Engine的默认主机)
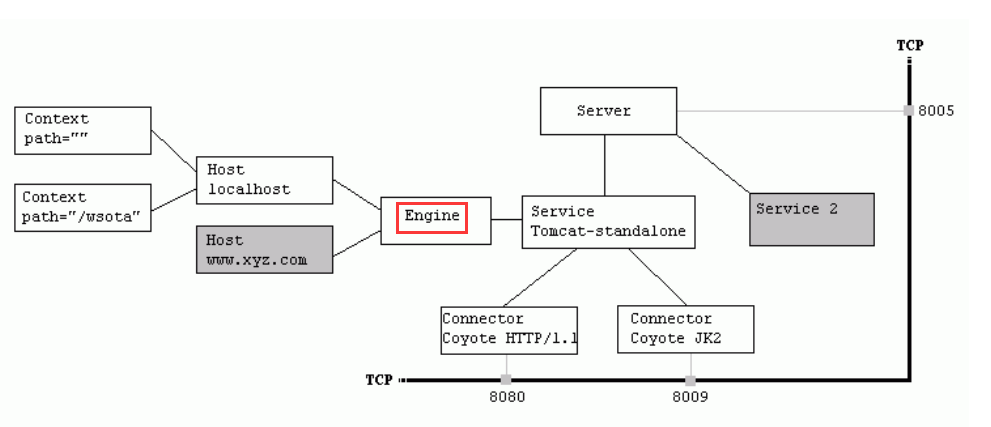
- localhost Host获得请求/wsota/wsota_index.jsp,匹配它所拥有的所有Context
- Host匹配到路径为/wsota的Context(如果匹配不到就把该请求交给路径名为""的Context去处理)
- path="/wsota"的Context获得请求/wsota_index.jsp,在它的mapping table中寻找对应的servlet
- Context匹配到URL PATTERN为*.jsp的servlet,对应于JspServlet类
- 构造HttpServletRequest对象和HttpServletResponse对象,作为参数调用JspServlet的doGet或doPost方法
- Context把执行完了之后的HttpServletResponse对象返回给Host
- Host把HttpServletResponse对象返回给Engine
- Engine把HttpServletResponse对象返回给Connector
- Connector把HttpServletResponse对象返回给客户browser
扩展:Tomcat配置文件:
- context.xml:tomcat 服务器会定时去扫描这个文件; 一旦发现文件被修改(时间戳改变了),就会自动重新加载这个文件,而不需要重启服务器。
<Context path="/eml" docBase="eml" debug="0" reloadbale="true" privileged="true">
<WatchedResource>WEB-INF/web.xml</WatchedResource>
<WatchedResource>WEB-INF/eml.xml</WatchedResource> #监控资源文件,如果web.xml || eml.xml改变了,则自动重新加载改应用。
<Resource name="jdbc/testSiteds"   #表示指定的jndi名称
auth="Container"   #表示认证方式,一般为Container
type="javax.sql.DataSource"
maxActive="100"   #连接池支持的最大连接数
maxIdle="40"     #连接池中最多可空闲maxIdle个连接
maxWait="30000"   #连接池中连接用完时,新的请求等待时间,毫秒
username="txl"    #表示数据库用户名
password="123456"   #表示数据库用户的密码
driverClassName="com.mysql.jdbc.Driver"   #表示JDBC DRIVER
url="jdbc:mysql://localhost:3306/testSite" />   #表示数据库URL地址
</Context>
- web.xml:Web应用程序描述文件,都是关于是Web应用程序的配置文件。
- tomcat-users.xml:Tomcat Manager的用户配置
- server.xml:可以设置端口号,添加虚拟机这些的,是对服务器的设置
<Server port="8005" shutdown="SHUTDOWN">
<Listener className="org.apache.catalina.startup.VersionLoggerListener" />
<Listener className="org.apache.catalina.security.SecurityListener" />
<Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" />
<Listener className="org.apache.catalina.core.JasperListener" />
<Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" />
<Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" />
<Listener className="org.apache.catalina.core.ThreadLocalLeakPreventionListener" />
<GlobalNamingResources>
<!-- 全局命名资源,来定义一些外部访问资源,其作用是为所有引擎应用程序所引用的外部资源的定义 --!>
<Resource name="UserDatabase" auth="Container"
type="org.apache.catalina.UserDatabase"
description="User database that can be updated and saved"
factory="org.apache.catalina.users.MemoryUserDatabaseFactory"
pathname="conf/tomcat-users.xml" />
</GlobalNamingResources>
<!-- 定义的一个名叫“UserDatabase”的认证资源,将conf/tomcat-users.xml加载至内存中,在需要认证的时候到内存中进行认证 -->
<Service name="Catalina">
<!-- # 定义Service组件,同来关联Connector和Engine,一个Engine可以对应多个Connector,每个Service中只能一个Engine --!>
<Connector port="80" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" />
<!-- 修改HTTP/1.1的Connector监听端口为80.客户端通过浏览器访问的请求,只能通过HTTP传递给tomcat。还可以设置server与URIEncoding参数 -->
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />
<Engine name="Catalina" defaultHost="test.com">
<!-- 修改当前Engine,默认主机是,www.test.com -->
<Realm className="org.apache.catalina.realm.LockOutRealm">
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
resourceName="UserDatabase"/>
</Realm>
# Realm组件,定义对当前容器内的应用程序访问的认证,通过外部资源UserDatabase进行认证
<Host name="test.com" appBase="/web" unpackWARs="true" autoDeploy="true">
<!-- 定义一个主机,域名为:test.com,应用程序的目录是/web,设置自动部署,自动解压 -->
<Alias>www.test.com</Alias>
<!-- 定义一个别名www.test.com,类似apache的ServerAlias -->
<Context path="" docBase="www/" reloadable="true" />
<!-- 定义该应用程序,访问路径"",即访问www.test.com即可访问,网页目录为:相对于appBase下的www/,即/web/www,并且当该应用程序下web.xml或者类等有相关变化时,自动重载当前配置,即不用重启tomcat使部署的新应用程序生效 -->
<Context path="/bbs" docBase="/web/bbs" reloadable="true" />
<!-- 定义另外一个独立的应用程序(虚拟主机),访问路径为:www.test.com/bbs,该应用程序网页目录为/web/bbs -->
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="/web/www/logs"
prefix="www_access." suffix=".log"
pattern="%h %l %u %t "%r" %s %b" />
<!-- 定义一个Valve组件,用来记录tomcat的访问日志,日志存放目录为:/web/www/logs如果定义为相对路径则是相当于$CATALINA_HOME,并非相对于appBase,这个要注意。定义日志文件前缀为www_access.并以.log结尾,pattern定义日志内容格式,具体字段表示可以查看tomcat官方文档 -->
</Host>
<Host name="manager.test.com" appBase="webapps" unpackWARs="true" autoDeploy="true">
<!-- 定义一个主机名为man.test.com,应用程序目录是$CATALINA_HOME/webapps,自动解压,自动部署 -->
<Valve className="org.apache.catalina.valves.RemoteAddrValve" allow="172.16.100.*" />
<!-- 定义远程地址访问策略,仅允许172.16.100.*网段访问该主机,其他的将被拒绝访问 -->
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="/web/bbs/logs"
prefix="bbs_access." suffix=".log"
pattern="%h %l %u %t "%r" %s %b" />
<!-- 定义该主机的访问日志 -->
</Host>
</Engine>
</Service>
</Server>
1.Server元素:整个配置文件的根元素。表示整个Catalina容器;
className:实现了org.apache.catalina.Server接口的类名,标准实现类是org.apache.catalina.core.StandardServer类;
Port:Tomcat服务器监听用于关闭Tomcat服务器的命令(必须);
Shutdown:发送到端口上用于关闭Tomcat服务器的命令;
2.Connector元素:连接器,负责接收客户的请求,以及向客户端回送响应的信息;
3.Engine元素:为特定的Service处理所有的请示。每个Service只能包含一个Engine元素。它负责接收和处理此Service所有的连接器收到的请求,向连接发回响应,并最终显示在客户端。Engine至少有一个Host元素,必须至少有一个Host属性的名字与defaultHost指定的名字相匹配;
4.Host元素:表示一个虚拟主机,为特定的虚拟主机处理所有请求;
5.context元素:一个web应用程序,处理当前web应用程序的所有请求,每个Context必须使用唯一的上下文路径。
2.1.1 tomcat多线程处理http请求
线程池
thread = threadPool.getThread();
thread.executeHttp(htttpRequest);
thread的start方法执行里面调用:每个thread里再获取所有的controller,根据传进入thread的httprequest找到相应的controllerer对象获取出来,controller对象就开始执行。
2.2 数据库访问
主要是sql上的处理以及优化。
以查询某一个用户为例,需要理解以下:
- 具体功能是什么?
- 用户请求参数是什么?
- 发送请求之后,服务器捕捉之后,如何处理这个请求,如果同时有大量的请求,服务器应该如何应对?
- Tomcat是如何根据router转发到不同的函数主体上?
- 实现逻辑是?主要的SQL查询体现在哪里?
- 你是如何查询?有什么优化?
- 数据量变多,数据库能有什么优化的点?
- 数据处理之后,如何封装并返回?
3.几个问题思考
对于大型网站来说,主要问题体现在:
1.访问量大
2.数据量多
- 单个服务器负载过高,如何解决?---(服务器集群)
- 如果用户量增加,当多个http请求同时发送,服务器如何缓解负载?---(高并发)
- 数据库数据量过高,如何处理?查询操作多的话,数据库应如何应对?---(数据库缓存)
4.优化点
4.1 集群
问题:用户量增加的情况下,单机服务器负载过高,会加快硬件的老化。
解决:
1.数据库服务器和业务分离;
把数据库服务器单独出来;应用服务器宕机之后,数据库不会受影响;
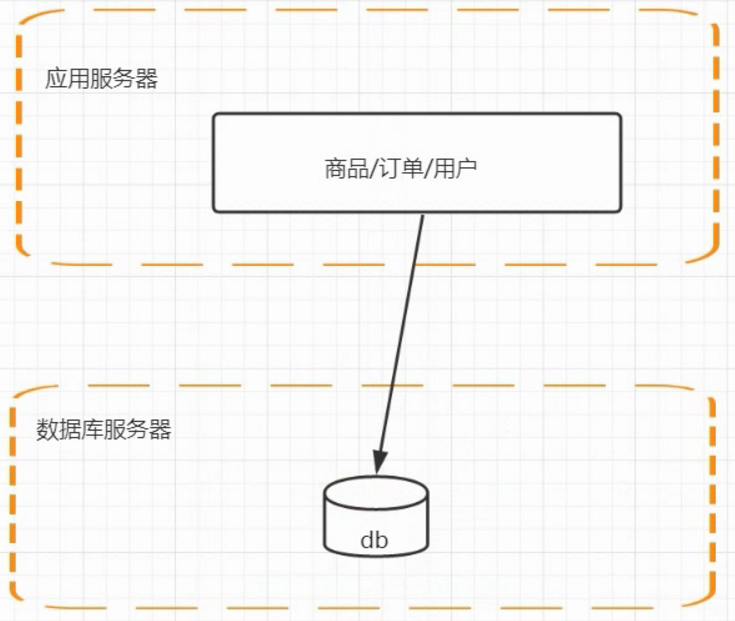
分布式是以缩短单个任务的执行时间来提升效率的;
集群是通过提高单位时间内执行的任务数来提升效率;
集群主要分为:高可用集群(High Availability Cluster),负载均衡集群(Load Balance Cluster,nginx即可实现),科学计算集群(High Performance Computing Cluster);
分布式是指将不同的业务分布在不同的地方;而集群指的是将几台服务器集中在一起,实现同一业务。分布式中的每一个节点,都可以做集群。 而集群并不一定就是分布式的;
每个大型网站都会有不同的架构模式,而架构内容也就是在处理均衡负载,缓存,数据库,文件系统等,只是在不同的环境下,不同的条件下,架构的模型不一样,目的旨在提高网站的性能。
参考:https://www.cnblogs.com/liangxiaofeng/p/4920267.html
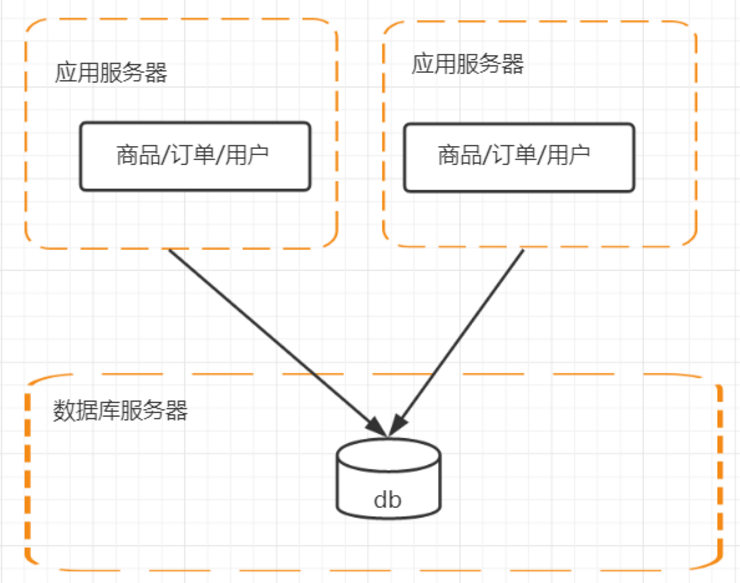
1.session如何共享?
2.前端服务器如何做请求转发?见4.2负载均衡
4.2 负载均衡
问题:当用户量增加,多个http请求同时发送,服务器如何缓解?
解决: 负载均衡的目的就是让请求到达不同的服务器上。一次请求到服务器之间,有那么多环节,因此可以实现的方法有很多种,实际应用中不外乎以下几种方式。
- HTTP重定向负载均衡--不熟
- DNS域名解析负载均衡--
- 反向代理负载均衡--
- 网络层负载均衡--
- 数据链路层负载均衡--
4.3 数据库缓存优化
问题:数据库数据量过高,如何处理?查询操作多的话,数据库应如何应对?
解决: 1.数据库读写分离
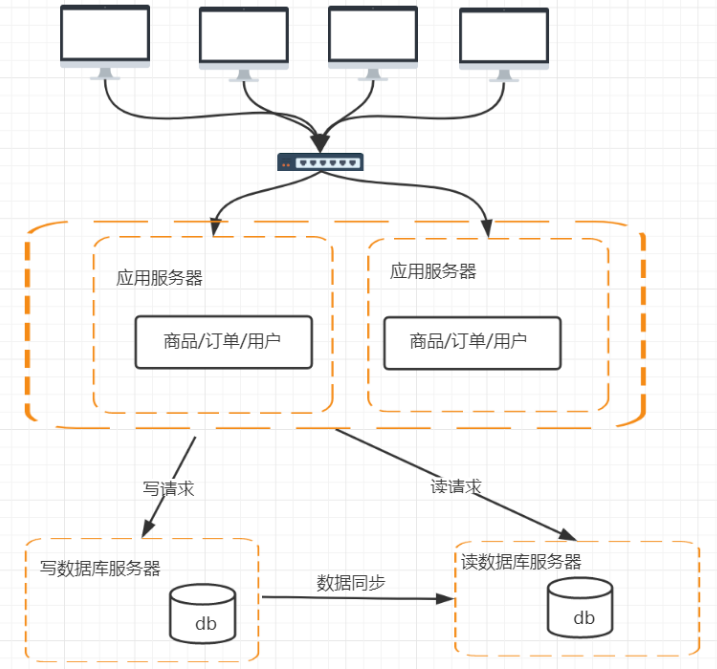
数据库读写分离如何操作;
数据库的数据同步如何操作;
2.搜索引擎
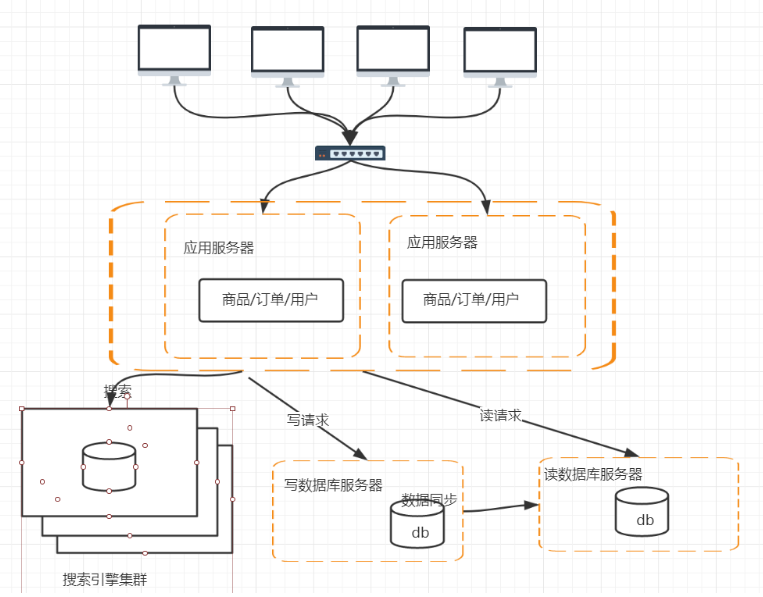
缺点:
搜索引擎的数据如何同步?
实时增量同步?
还是定时全量同步?
3.引入缓存机制
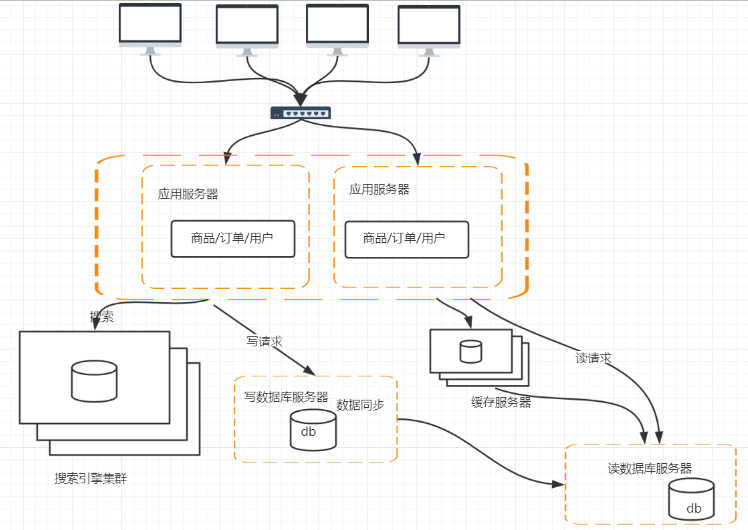
缓存分为服务器缓存和应用程序缓存;
先去读缓存服务器,如果没有命中,则去读数据库服务器。
4.数据库的水平/垂直拆分
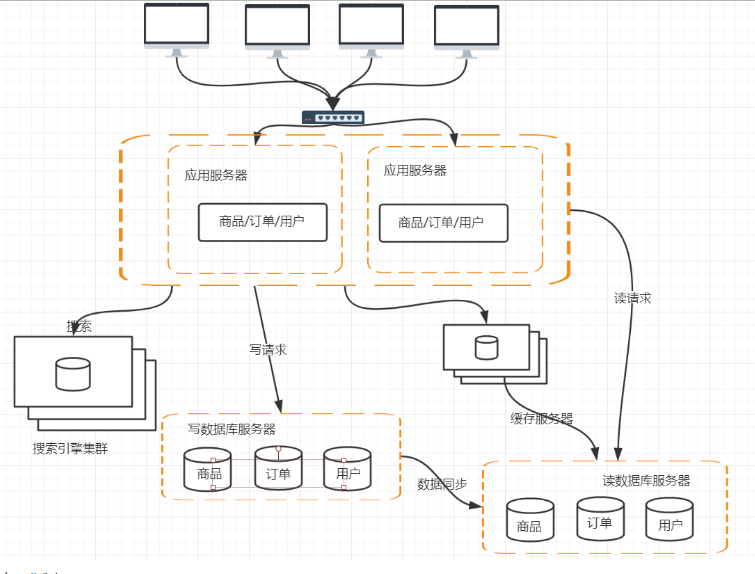
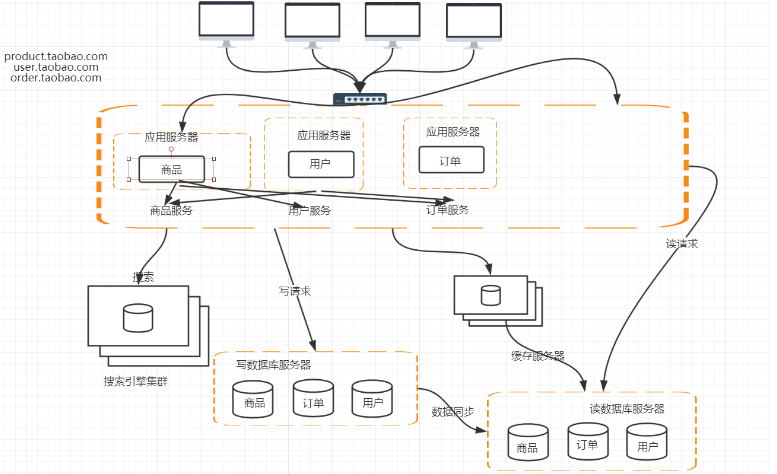
5.总结
- 对于整个服务器接受浏览器请求到响应的流程要熟悉,至少对其中两个模块特别熟悉,并且了解其中的实现机制。
- 同样的业务用多个服务器,加负载均衡
- 业务拆分,不同的Server提供不同的服务
- 数据库拆分,水平拆分,垂直拆分
- 动态的东西静态化,缓存
- 数据缓存,例如用Redis等高速缓存,Redis再做集群等
参考:
my.oschina.net/u/2543341/b…
www.cnblogs.com/sunshine-1/…
www.cnblogs.com/liangxiaofe…
