

日前,由蚂蚁金服算法工程师胡斌斌撰写的论文《Adversarial Learning on Heterogeneous Information Networks》入选全球数据挖掘顶级会议KDD 2019,本文为该论文的详细解读。论文地址:www.kdd.org/kdd2019/acc…
前言
网络表示学习是一种在低维空间中表示网络数据的方法,在异构信息网络分析中得到了广泛的应用。现有的异构信息网络表示学习方法虽然在一定程度上实现了性能的提高,但仍然存在一些主要的不足。最重要的是,它们通常采用负抽样的方法从网络中随机选择节点,而不学习底层的分布以获得更鲁棒的表示。
受生成式对抗网络 (GAN)的启发,我们开发了一个用于异构信息网络表示学习的新框架HeGAN,它在一种极小极大的博弈中同时训练判别器和生成器。与现有异构信息网络表示学习方法相比,我们的生成器可以学习节点分布,生成更好的负样本。与同质网络上的生成对抗网络相比,我们设计的判别器和生成器是关系感知的,以便在异构信息网络上捕获丰富的语义。此外,为了提高采样效率,我们提出了一种广义的生成器,它直接从连续分布中对“潜在”节点进行采样,而不像现有方法那样局限于原始网络中的节点。最后,我们在四个实际数据集进行了大量的实验。结果表明,在所有数据集和任务中,我们始终如一且显著地优于当前的表示学习方法。
关于“异构信息网络”和“对抗生成学习”
网络结构在现实世界的应用中无处不在,从社会和生物网络到交通和电信系统。因此,网络分析对于解决社交网络的个性化用户推荐、生物网络的基因识别困难等关键问题显得越来越重要。这些问题往往表现为对网络数据进行节点聚类、节点分类和链路预测,所以这些问题从根本上依赖于一种有效的网络表示形式。近年来,网络表示学习已经成为无监督学习节点表示的一个很有前途的方向,其目的是将网络节点投射到低维空间中,同时保持原网络的结构特性。
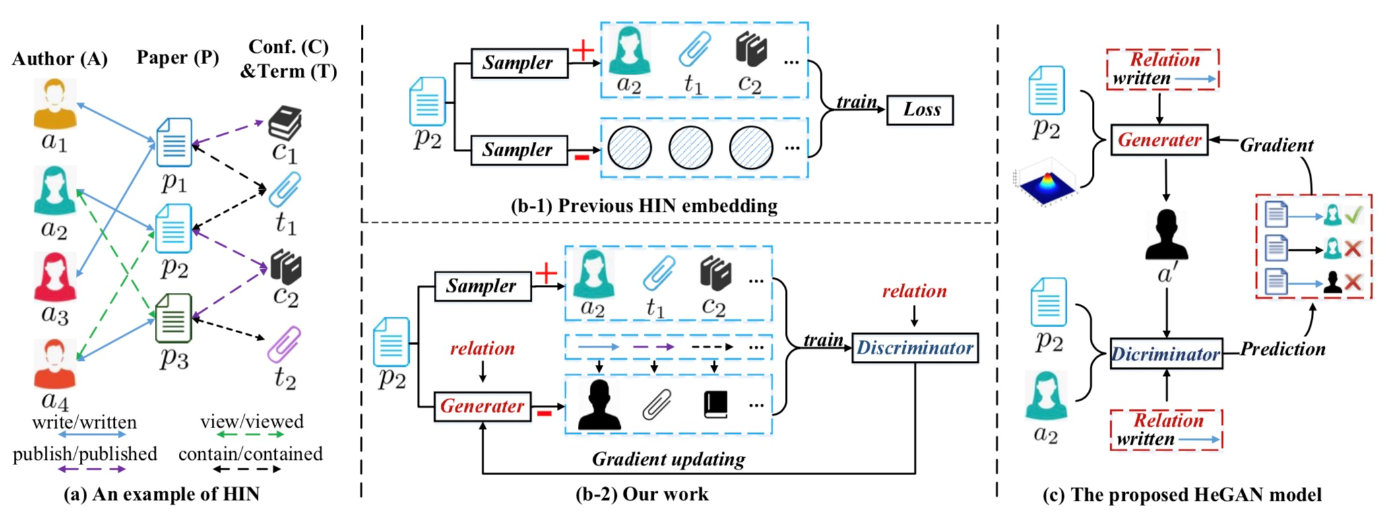
异构信息网络。虽然早期的网络表示学习工作已经取得了相当大的成功,但它们只能处理所谓的同质网络,即网络中只包含一种类型的节点和边。然而,在实际场景中,节点自然地由不同类型的实体构成,这些实体通过多种关系相互。这种网络称为异构信息网络,如图(a)所示。该异构信息网络由多种类型的节点(如author和paper)组成,节点之间通过各种类型的关系(如write/ writing relationship between authorand paper, publish/published relationship between paper and conference)连接。
由于其异构性, 异构信息网络往往具有极其丰富和复杂的语义。因此,许多研究者开始研究异构信息网络下的表示学习,最值得关注的工作有metapath2vec和HIN2vec。如图1(b-1)所示,现有异构信息网络网络的表示学习方法从思想上可以归结为两个采样器,分别从网络中给定的“中心”节点(如paper p2)选择“上下文”节点作为正例(如author a2)和负例(如阴影圆圈)(注意,每个节点都可以充当中心或上下文,类似于Skip-gram模型)。然后,在这些样本上训练一个损失函数来优化节点表示。虽然这些方法取得了一定的性能提升,但它们也存在严重的局限性。首先,它们通常使用负抽样来随机选择网络中现有的节点作为负抽样。因此,它们的负样本不仅是任意的,而且局限于原始网络的宇宙。其次,它们主要关注于在异构信息网络上捕获丰富的语义信息,而不注意节点的底层分布,因此对于通常稀疏且有噪声的真实的网络缺乏鲁棒性。第三,当前的许多异构信息网络方法依赖于适当的元路径来匹配所需的语义,这通常需要领域知识,而这些知识有时是主观的,而且通常很难获取。
对抗生成学习。生成对抗网络(GAN)已被开发用于学习各种应用中鲁棒的潜在表示。GANs依赖于对抗性学习的思想,判别器和生成器相互竞争,不仅要训练更好的判别模型,还要学习底层的数据分布。后者使得模型对稀疏或有噪声数据的鲁棒性更强[13,24],也提供了更好的样本来降低标注要求。鉴于这些优点,基于GAN的网络表示学习已经有了一些初步的尝试。然而,这些研究只研究了同质网络,没有考虑节点和关系的异构性,导致在语义丰富的异构信息网络上性能不理想。
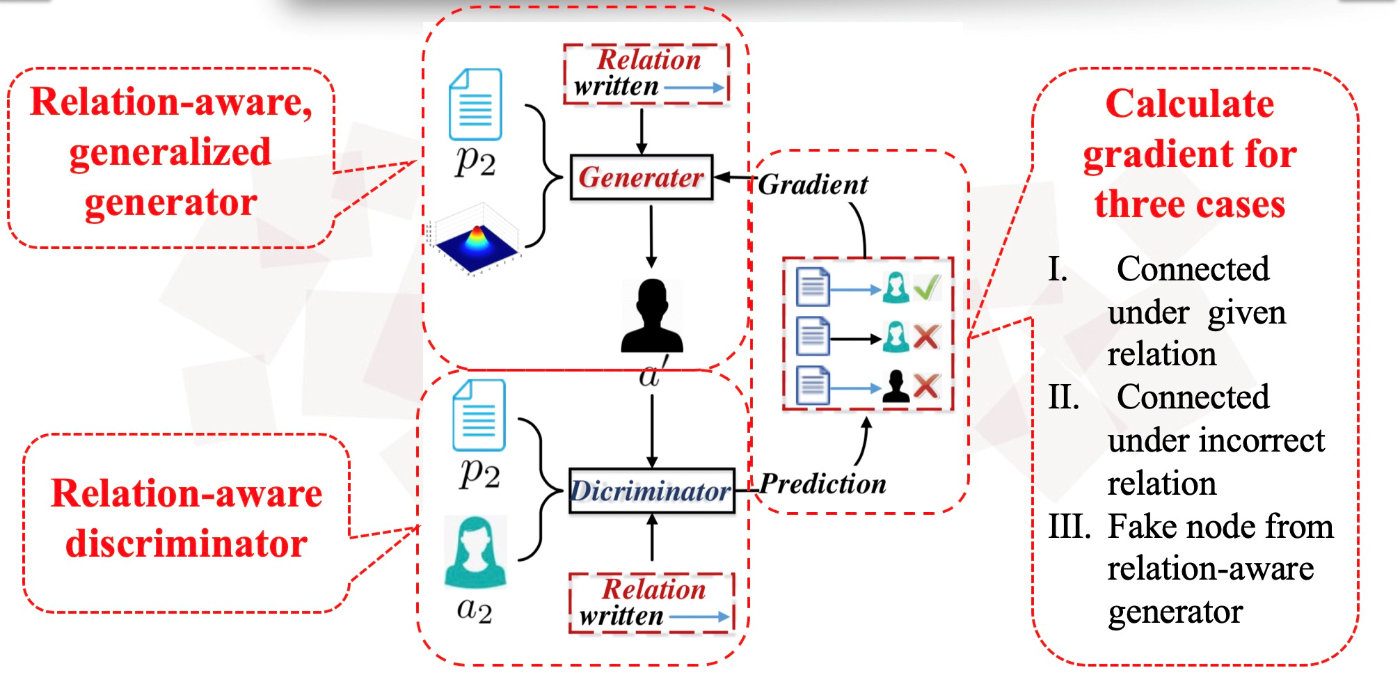
HeGAN及其贡献。为了克服现有工作的局限,我们提出了一个新的框架HeGAN,基于GAN的异构信息网络表示框架。具体地,我们提出了一种新的判别器和生成器,如图(b-2)所示。首先,我们的判别器和生成器被设计成关系感知的,以便区分由不同关系连接的节点。也就是说,对于任何关系,判别器都可以分辨出一个节点对是真还是假,而生成器可以生成模仿真节点对的假节点对。特别是,只有节点对是(i)基于网络拓扑结构的正对且(ii)在正确的关系下形成对时,才认为该节点对是正例对;。其次,我们设计了一个广义生成器,它能够直接从连续分布中抽取潜在节点,因此(i)不需要softmax的计算; (ii)假样本不局限于现有节点。总之,本文做出了以下贡献。
(1)我们是第一个将对抗性学习应用于异构信息网络表示的,从而来利用异构信息网络上的丰富的语义,同时保证学习到的表示的鲁棒性。
(2)我们提出了一种新型的HeGAN框架,该框架不仅能够感知关系以获取丰富的语义,而且还具有高效的生成负样本的机制。
(3)我们在四个公共数据集进行一系列下游任务的实验。结果表明HeGAN具有明显的优越性。
异构信息网络上的对抗生成学习
生成对抗的网络。我们的工作受到GANs的启发,GANs可以被看作是两个玩家之间的一个极小极大的博弈,即生成器G和鉴别器D。具体的优化形式如下所示:
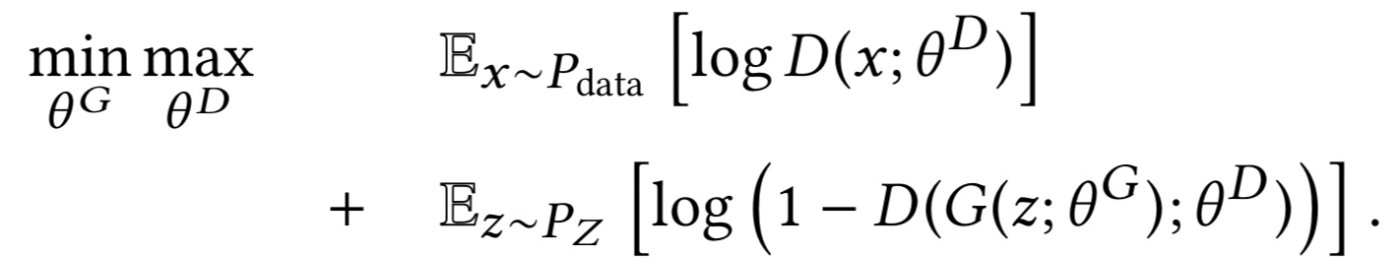
HeGAN的总体框架。如图(c)所示,我们的框架主要由两个相互竞争的模块组成,即判别器和生成器。给定一个节点,生成器尝试生成与给定节点相关联的伪样本,以提供给判别器,而判别器则尝试改进其参数来将假样本与实际连接到给定节点的真实样本分离。在这个重复的过程中,训练好的判别器会迫使生产器产生更好的假样本,而判别器则也会增强其判断能力。在这样的迭代过程中,生成器和判别器都得到了正强化。
现有的研究只是利用GAN来区分节点与给定节点在结构连接上是真还是假,而没有考虑到异构信息网络的不同语义。例如,给定一篇论文p2,它们将节点a2、a4视为真,节点a1、a3为伪(根据图(a)所示的网络的拓扑结构),。但是,a2和a4连接到p2的原因不同: a2写了p2, a4读了p2。因此,它们忽略了异构信息网络所包含的有价值的语义,无法区分a2和a4,因为它们扮演着不同的语义角色。在语义保持的表示学习方面,HeGAN引入了一个关系感知的判别器和生成器,以区分节点之间的各种类型的语义关系。在以上的异构信息网络上,给定节点p2和一个关系,比如write/ write,我们的判别器能够分辨出a2和a4,而我们的生成器将尝试生成更像a2而不是a4的假样本。
其次,现有的研究在假样本的生成的有效性和效率上有局限性。他们通常对在原始网络中的所有节点上使用某种形式的softmax来生成假样本。在有效性方面,他们的假样本受限于网络中已经存在的节点,或许最具代表性的假样本可能不存在于现有的可观察到的节点。例如,给定一个节点p2,他们只能选择来自空间V(V为网络中所有节点的集合)的样本,比如a1和a3。然而,两者可能都不是与实际节点a2充分相似。为了更好的样本生成, 我们引入一个广义生成器,可以生成例如a’之类的假样本,其中,a’可能并不属于V。我们可以只为a’可能是a1、a3的“平均”,更类似于真正的样本a2。在计算效率方面,softmax函数的计算开销较大,必须采用负采样和图softmax等近似方法。相反,我们的生成器可以直接从连续的空间中采样假节点,而无需使用softmax。我们的具体框架如下所示。
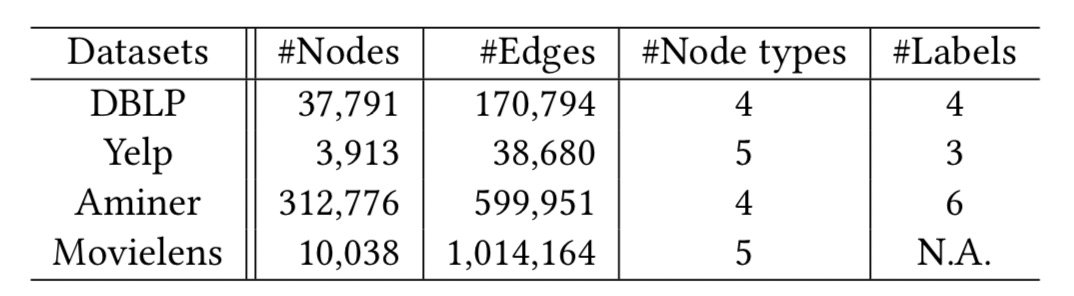
我们在DBLP、Yelp、Aminer、Movielens四个数据集上进行了实验,具体在节点聚类、节点分类、链路预测和推荐四个任务上验证了有效性。实验数据集如下所示。
首先,我们依此来看下节点分类、链路预测、节点聚类、推荐四个任务下的实验结果。
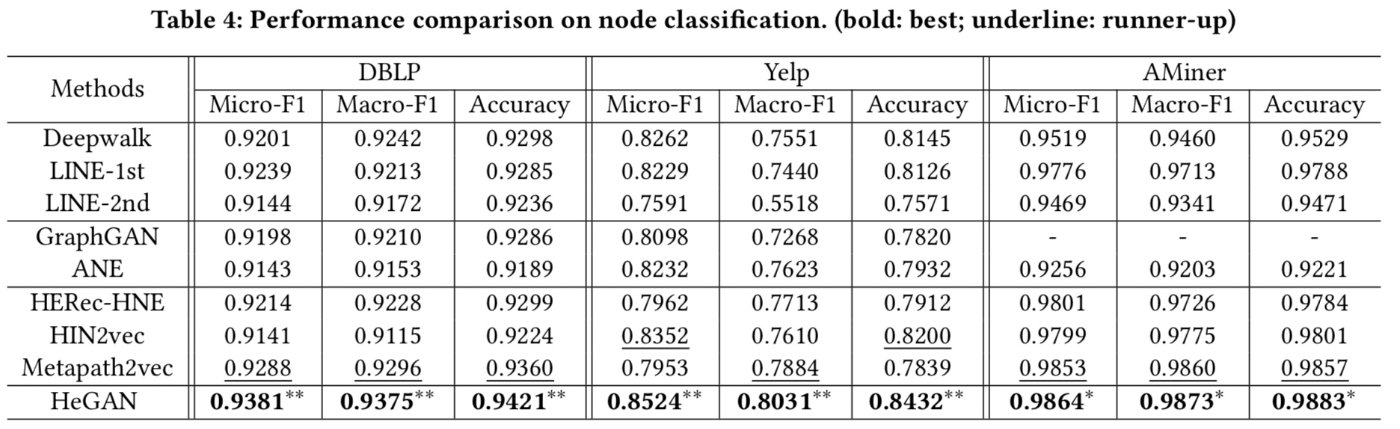
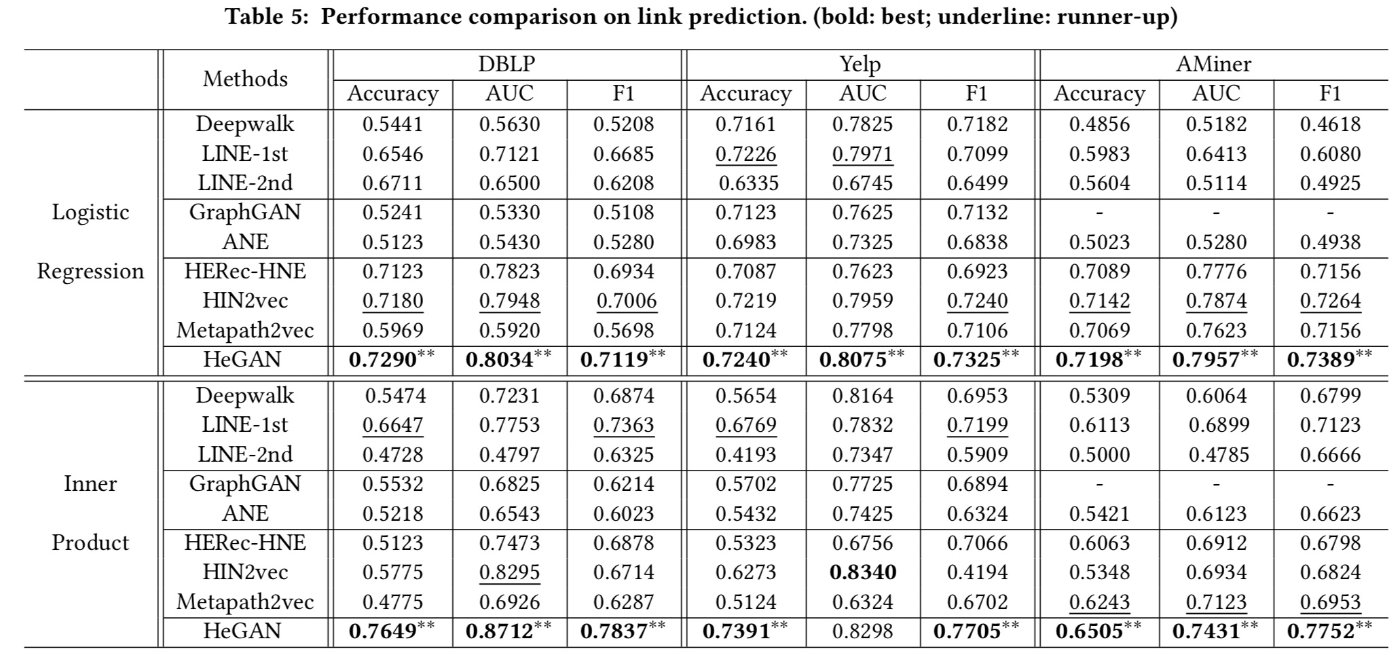
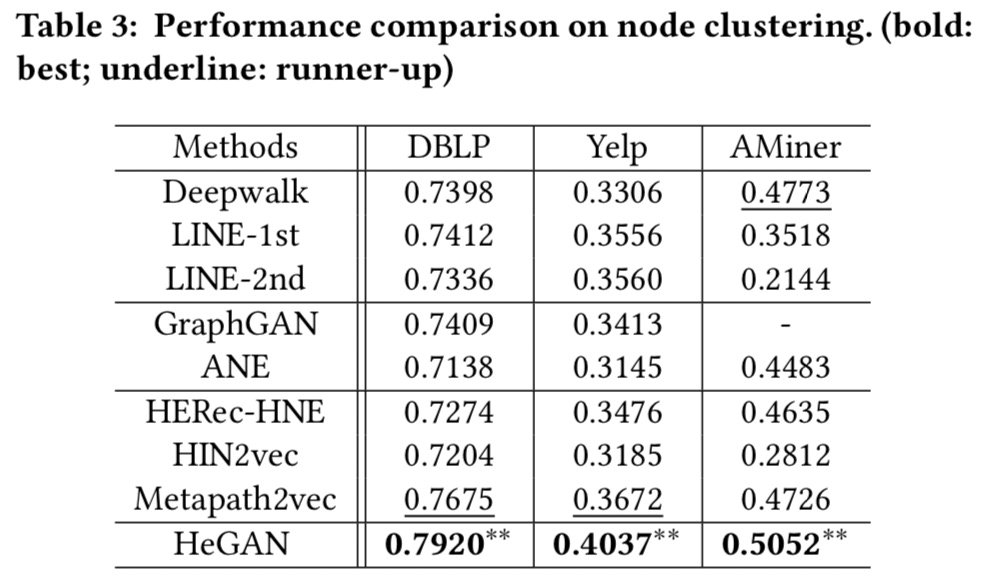
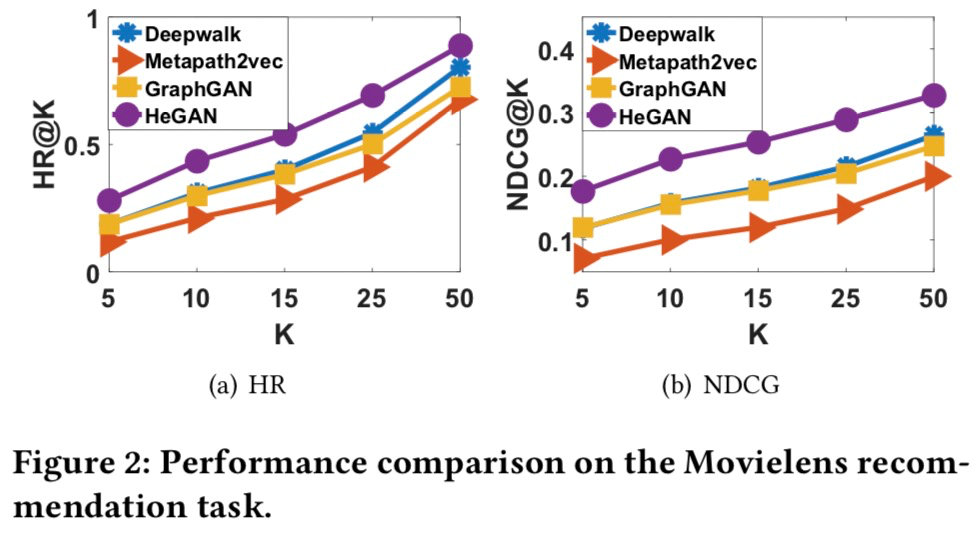
其次我们来可视化一下节点表示的空间(Yelp数据集),

由图可知,HeGAN的边界更清晰,集群更加密集。
我们给出了Yelp上的HeGAN生成器器和判别器的学习曲线,从损失变化和聚类效果两方面进行分析。在损失的初始波动之后,生成器和判别器开始了他们之间的极小极大的博弈,两者的损失逐渐减少。经过大约20个epoch的对抗性训练,两者的损失趋于收敛,而胜者实现了更好的性能。注意,当训练了更多的epoch时,由于过度拟合,聚类性能下降。
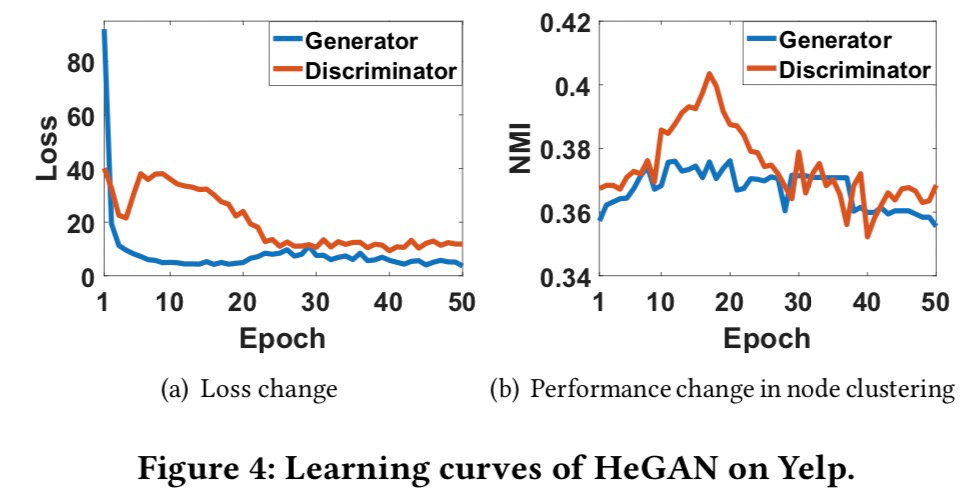
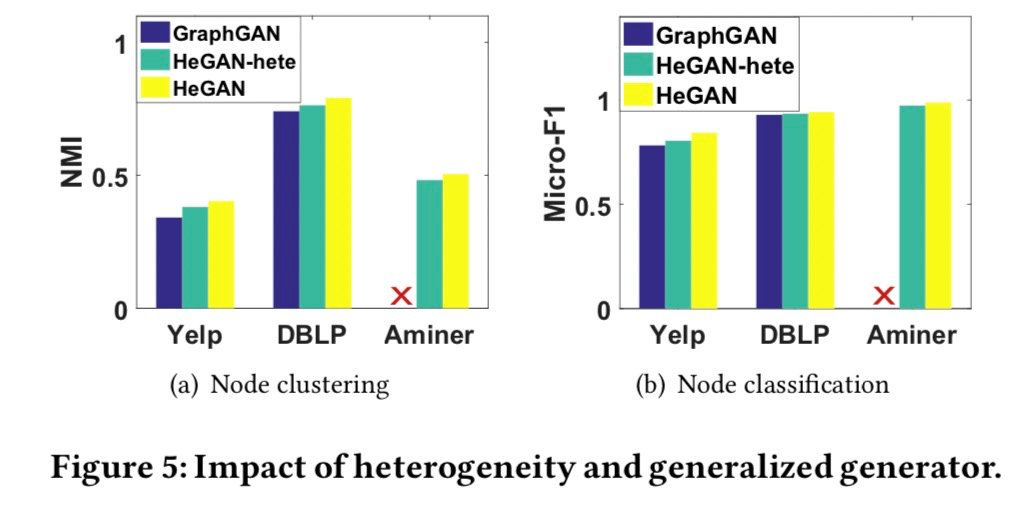
之后,我们在节点聚类和节点分类两个任务上验证异构信息和我们提出的广义的生成器的有效性,我们可以得出如下结论:(1) 在异构信息网络中,不同类型的节点和关系应加以区分。(2) 我们的广义生成器确实可以产生更有代表性的样本。
最后,我们来看一下HeGAN的效率。
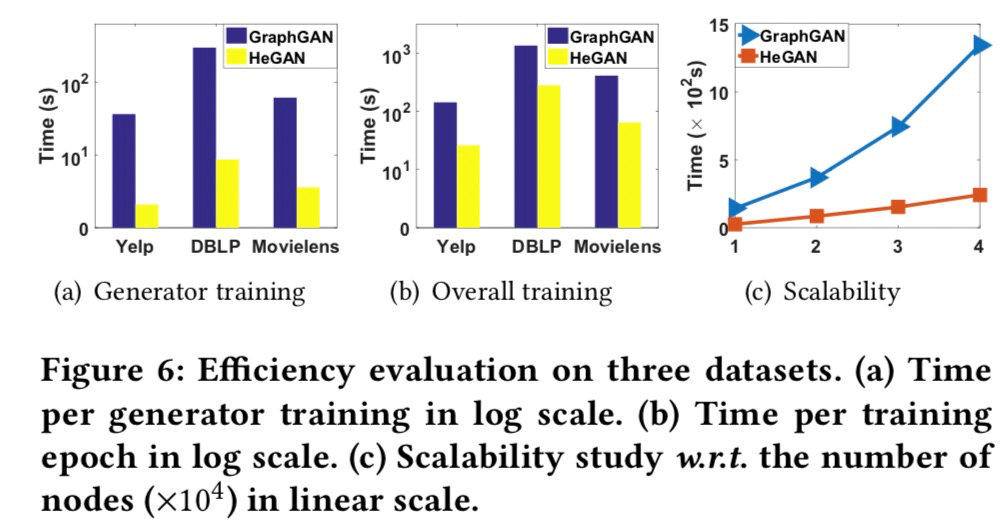
从图中我们可以看到HeGAN的训练时间和节点数成线性关系,时间性能大大优于基于softmax的GraphGAN。
结语
本文涉及的技术主要为异构信息网络和对抗生成学习。实际中所涉及的网络往往不会只包含单一类型的节点或者关系,网络由越来越多的复杂关系构成是大势所趋。所以如何更好利用和表示这种复杂的网络来产生更多的价值一直研究的重点。其次,现有的网络往往存在很多噪声,或者抗噪能力薄弱,这激励着我们学习更加鲁棒性的网络表示。
