

全文共4857字,预计学习时长10分钟

图片来源:unsplash.com/@dulgier
事实上,你的模型可能还停留在石器时代的水平。估计你还在用32位精度或*GASP(一般活动仿真语言)*训练,甚至可能只在单GPU上训练。如果市面上有99个加速指南,但你可能只看过1个?(没错,就是这样)。但这份终极指南,会一步步教你清除模型中所有的(GP模型)。

这份指南的介绍从简单到复杂,一直介绍到你可以完成的大多数PITA修改,以充分利用你的网络。例子中会包括一些Pytorch代码和相关标记,可以在 Pytorch-Lightning训练器中用,以防大家不想自己敲码!
这份指南针对的是谁? 任何用Pytorch研究非琐碎的深度学习模型的人,比如工业研究人员、博士生、学者等等……这些模型可能要花费几天,甚至几周、几个月的时间来训练。

1. 使用DataLoader。
2. DataLoader中的进程数。
3. 批尺寸。
4. 累积梯度。
5. 保留计算图。
6. 转至单GPU。
7. 16位混合精度训练。
8. 转至多GPU(模型复制)。
9. 转至多GPU节点(8+GPUs)。
10. 有关模型加速的思考和技巧
Pytorch-Lightning

文中讨论的各种优化,都可以在名为Pytorch-Lightning(https://github.com/williamFalcon/pytorch-lightning?source=post_page---------------------------) 的Pytorch图书馆中找到。
Lightning是基于Pytorch的一个光包装器,它可以帮助研究人员自动训练模型,但关键的模型部件还是由研究人员完全控制。
参照此篇教程,获得更有力的范例(https://github.com/williamFalcon/pytorch-lightning/blob/master/examples/new_project_templates/single_gpu_node_template.py?source=post_page---------------------------)。
Lightning采用最新、最尖端的方法,将犯错的可能性降到最低。
MNIST定义的Lightning模型(https://github.com/williamFalcon/pytorch-lightning/blob/master/examples/new_project_templates/lightning_module_template.py?source=post_page---------------------------),可适用于训练器。
from pytorch-lightning import Trainermodel = Lightning
Module(…)trainer = Trainer()trainer.fit(model)1. DataLoader

这可能是最容易提速的地方。靠保存h5py或numpy文件来加速数据加载的日子已经一去不复返了。用 Pytorch dataloader (https://pytorch.org/tutorials/beginner/data_loading_tutorial.html?source=post_page---------------------------)加载图像数据非常简单。(关于NLP数据,请参照TorchText:https://torchtext.readthedocs.io/en/latest/datasets.html?source=post_page---------------------------)
dataset = MNIST(root=self.hparams.data_root, train=train, download=True)
loader = DataLoader
(dataset, batch_size=32, shuffle=True)
for batch in loader: x, y = batch model.training_step(x, y) ...在Lightning中,你无需指定一个训练循环,只需定义dataLoaders,训练器便会在 需要时调用它们(https://github.com/williamFalcon/pytorch-lightning/blob/master/examples/new_project_templates/lightning_module_template.py?source=post_page---------------------------#L163-L217)。
2. DataLoaders中的进程数

加快速度的第二个秘诀在于允许批量并行加载。所以,你可以一次加载许多批量,而不是一次加载一个。
# slowloader = DataLoader(dataset, batch_size=32, shuffle=True)
# fast (use 10 workers)loader = DataLoader
(dataset, batch_size=32, shuffle=True, num_workers=10)
3. 批量大小(Batch size)
在开始下一步优化步骤之前,将批量大小调高到CPU内存或GPU内存允许的最大值。
接下来的部分将着重于减少内存占用,这样就可以继续增加批尺寸。
记住,你很可能需要再次更新学习率。如果将批尺寸增加一倍,最好将学习速度也提高一倍。
4. 累积梯度

假如已经最大限度地使用了计算资源,而批尺寸仍然太低(假设为8),那我们则需为梯度下降模拟更大的批尺寸,以供精准估计。
假设想让批尺寸达到128。然后,在执行单个优化器步骤前,将执行16次前向和后向传播(批量大小为8)。
# clear last stepoptimizer.zero_grad()
# 16 accumulated gradient stepsscaled_loss = 0for
accumulated_step_i in range(16):
out = model.forward()
loss = some_loss(out,y)
loss.backward()
scaled_loss += loss.item()
# update weights after 8 steps. effective batch = 8*16optimizer.step()
# loss is now scaled up by the number of accumulated
batchesactual_loss = scaled_loss / 16而在Lightning中,这些已经自动执行了。只需设置标记:https://williamfalcon.github.io/pytorch-lightning/Trainer/Training%20Loop/?source=post_page---------------------------#accumulated-gradients
trainer = Trainer(accumulate_grad_batches=16)trainer.fit(model)
5. 保留计算图

撑爆内存很简单,只要不释放指向计算图形的指针,比如……为记录日志保存loss。
losses = []...losses.append(loss)print(f'current loss: {torch.mean(losses)'})上述的问题在于,loss仍然有一个图形副本。在这种情况中,可用.item()来释放它。
# badlosses.append(loss)# goodlosses.append(loss.item())Lightning会特别注意,让其无法保留图形副本 (示例:https://github.com/williamFalcon/pytorch-lightning/blob/master/pytorch_lightning/models/trainer.py?source=post_page---------------------------#L767-L768)
6. 单GPU训练

一旦完成了前面的步骤,就可以进入GPU训练了。GPU的训练将对许多GPU核心上的数学计算进行并行处理。能加速多少取决于使用的GPU类型。个人使用的话,推荐使用2080Ti,公司使用的话可用V100。
刚开始你可能会觉得压力很大,但其实只需做两件事: 1)将你的模型移动到GPU上,2)在用其运行数据时,把数据导至GPU中。
# put model on GPUmodel.cuda(0)
# put data on gpu (cuda on a variable returns a cuda copy)x = x.cuda(0)
# runs on GPU nowmodel(x)如果使用Lightning,则不需要对代码做任何操作。只需设置标记(https://williamfalcon.github.io/pytorch-lightning/Trainer/Distributed%20training/?source=post_page---------------------------#single-gpu):
# ask lightning to use gpu 0 for trainingtrainer = Trainer(gpus=[0])trainer.fit(model)在GPU进行训练时,要注意限制CPU和GPU之间的传输量。
# expensivex = x.cuda(0)# very expensivex = x.cpu()x = x.cuda(0)例如,如果耗尽了内存,不要为了省内存,将数据移回CPU。尝试用其他方式优化代码,或者在用这种方法之前先跨GPUs分配代码。
此外还要注意进行强制GPUs同步的操作。例如清除内存缓存。
# really bad idea.Stops all the GPUs until they all catch uptorch.cuda.empty_cache()但是如果使用Lightning,那么只有在定义Lightning模块时可能会出现这种问题。Lightning特别注意避免此类错误。
7. 16位精度
16位精度可以有效地削减一半的内存占用。大多数模型都是用32位精度数进行训练的。然而最近的研究发现,使用16位精度,模型也可以很好地工作。混合精度指的是,用16位训练一些特定的模型,而权值类的用32位训练。
要想在Pytorch中用16位精度,先从NVIDIA中安装 apex 图书馆 并对你的模型进行这些更改。
# enable 16-bit on the model and the optimizermodel, optimizers = amp.
initialize(model, optimizers, opt_level='O2')
# when doing .backward, let amp do it so it can
scale the losswith amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()amp包会处理大部分事情。如果梯度爆炸或趋于零,它甚至会扩大loss。
在Lightning中, 使用16位很简单(https://williamfalcon.github.io/pytorch-lightning/Trainer/Distributed%20training/?source=post_page---------------------------#16-bit-mixed-precision),不需对你的模型做任何修改,也不用完成上述操作。
trainer = Trainer(amp_level=’O2', use_amp=False)trainer.fit(model)
8. 移至多GPU
现在,事情就变得有意思了。有3种(也许更多?)方式训练多GPU。
分批量训练
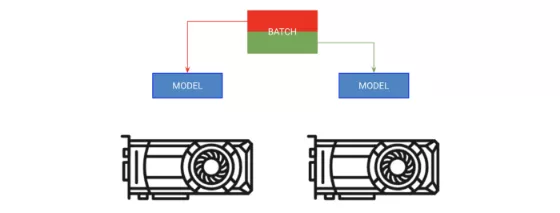
第一种方法叫做分批量训练。这一策略将模型复制到每个GPU上,而每个GPU会分到该批量的一部分。
# copy model on each GPU and give a fourth of the
batch to eachmodel = DataParallel(model, devices=[0, 1, 2 ,3])
# out has 4 outputs (one for each gpu)out = model(x.cuda(0))在Lightning中,可以直接指示训练器增加GPU数量,而无需完成上述任何操作。
# ask lightning to use 4 GPUs for trainingtrainer = Trainer(gpus=[0, 1, 2, 3])trainer.fit(model)分模型训练
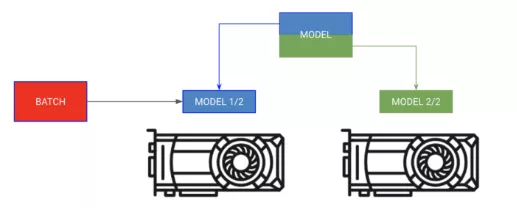
有时模型可能太大,内存不足以支撑。比如,带有编码器和解码器的Sequence to Sequence模型在生成输出时可能会占用20gb的内存。在这种情况下,我们希望把编码器和解码器放在单独的GPU上。
# each model is sooo big we can't fit both in memoryencoder_rnn.cuda(0)decoder_rnn.cuda(1)
# run input through encoder on GPU 0out = encoder_rnn(x.cuda(0))
# run output through decoder on the next GPUout = decoder_rnn(x.cuda(1))
# normally we want to bring all outputs back to GPU 0out = out.cuda(0)对于这种类型的训练,无需将Lightning训练器分到任何GPU上。与之相反,只要把自己的模块导入正确的GPU的Lightning模块中:
class MyModule(LightningModule):def __init__():
self.encoder = RNN(...)
self.decoder = RNN(...)def forward(x):
# models won't be moved after the first forward because
# they are already on the correct GPUs
self.encoder.cuda(0)
self.decoder.cuda(1)
out = self.encoder(x)
out = self.decoder(out.cuda(1))
# don't pass GPUs to trainermodel = MyModule()trainer = Trainer()trainer.fit(model)混合两种训练方法
在上面的例子中,编码器和解码器仍然可以从并行化每个操作中获益。我们现在可以更具创造力了。
# change these linesself.encoder = RNN(...)self.decoder = RNN(...)
# to these
# now each RNN is based on a different gpu setself.
encoder = DataParallel(self.encoder, devices=[0, 1, 2, 3])self.
decoder = DataParallel(self.encoder, devices=[4, 5, 6, 7])
# in forward...out = self.encoder(x.cuda(0))
# notice inputs on first gpu in devicesout = self.decoder(out.cuda(4))
# <--- the 4 here使用多GPUs时需注意的事项
· 如果该设备上已存在model.cuda(),那么它不会完成任何操作。
· 始终输入到设备列表的第一个设备上。
· 跨设备传输数据非常昂贵,不到万不得已不要这样做。
· 优化器和梯度将存储在GPU 0上。因此,GPU 0使用的内存很可能比其他处理器大得多。
9. 多节点GPU训练
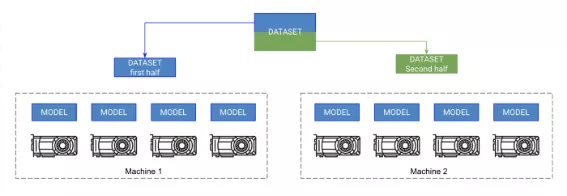
做到了这一步,就可以在几分钟内训练Imagenet数据集了! 这没有想象中那么难,但需要更多有关计算集群的知识。这些指令假定你正在集群上使用SLURM。
Pytorch在各个GPU上跨节点复制模型并同步梯度,从而实现多节点训练。因此,每个模型都是在各GPU上独立初始化的,本质上是在数据的一个分区上独立训练的,只是它们都接收来自所有模型的梯度更新。
高级阶段:
1. 在各GPU上初始化一个模型的副本(确保设置好种子,使每个模型初始化到相同的权值,否则操作会失效。)
2. 将数据集分成子集。每个GPU只在自己的子集上训练。
3. On .backward() 所有副本都会接收各模型梯度的副本。只有此时,模型之间才会相互通信。
Pytorch有一个很好的抽象概念,叫做分布式数据并行处理,它可以为你完成这一操作。要使用DDP(分布式数据并行处理),需要做4件事:
def tng_dataloader():
d = MNIST()
# 4: Add distributed sampler
# sampler sends a portion of tng data to each machine
dist_sampler = DistributedSampler(dataset)
dataloader = DataLoader(d, shuffle=False, sampler=dist_sampler)
def main_process_entrypoint(gpu_nb):
# 2: set up connections between all gpus across all machines
# all gpus connect to a single GPU "root"
# the default uses env://
world = nb_gpus * nb_nodes
dist.init_process_group("nccl", rank=gpu_nb, world_size=world)
# 3: wrap model in DPP
torch.cuda.set_device(gpu_nb)
model.cuda(gpu_nb)
model = DistributedDataParallel(model, device_ids=[gpu_nb])
# train your model now...if __name__ == '__main__':
# 1: spawn number of processes
# your cluster will call main for each machine
mp.spawn(main_process_entrypoint, nprocs=8)Pytorch团队对此有一份详细的实用教程(https://github.com/pytorch/examples/blob/master/imagenet/main.py?source=post_page---------------------------)。
然而,在Lightning中,这是一个自带功能。只需设定节点数标志,其余的交给Lightning处理就好。
# train on 1024 gpus across
128 nodestrainer = Trainer(nb_gpu_nodes=128,
gpus=[0, 1, 2, 3, 4, 5, 6, 7])Lightning还附带了一个SlurmCluster管理器,可助你简单地提交SLURM任务的正确细节(示例:https://github.com/williamFalcon/pytorch-lightning/blob/master/examples/new_project_templates/multi_node_cluster_template.py?source=post_page---------------------------#L103-L134)
10. 福利!更快的多GPU单节点训练
事实证明,分布式数据并行处理要比数据并行快得多,因为其唯一的通信是梯度同步。因此,最好用分布式数据并行处理替换数据并行,即使只是在做单机训练。
在Lightning中,通过将distributed_backend设置为ddp(分布式数据并行处理)并设置GPU的数量,这可以很容易实现。
# train on 4 gpus on the same machine MUCH faster
than DataParalleltrainer = Trainer
(distributed_backend='ddp', gpus=[0, 1, 2, 3])
有关模型加速的思考和技巧
如何通过寻找瓶颈来思考问题?可以把模型分成几个部分:
首先,确保数据加载中没有瓶颈。为此,可以使用上述的现有数据加载方案,但是如果没有适合你的方案,你可以把离线处理及超高速缓存作为高性能数据储存,就像h5py一样。
接下来看看在训练过程中该怎么做。确保快速转发,避免多余的计算,并将CPU和GPU之间的数据传输最小化。最后,避免降低GPU的速度(在本指南中有介绍)。
接下来,最大化批尺寸,通常来说,GPU的内存大小会限制批量大小。自此看来,这其实就是跨GPU分布,但要最小化延迟,有效使用大批次(例如在数据集中,可能会在多个GPUs上获得8000+的有效批量大小)。
但是需要小心处理大批次。根据具体问题查阅文献,学习一下别人是如何处理的!0

留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”

(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)
