

如今,许多公司都会开发与自己业务息息相关的推荐系统。先荐作为第四范式研发的一款智能推荐产品,已为内容行业的众多媒体客户赋能,实现客户的营收增长。在本文中,我们将会简要介绍现有的主要推荐算法及其工作原理。
协同过滤
协同过滤(CF)是最常用的推荐算法之一,即使推荐系统小白也可以轻松上手,用它来构建属于自己的个人电影推荐系统。
当我们想向用户推荐某些内容时,最合乎逻辑的做法是找到与这个用户兴趣相似的其他用户,分析他们的行为,然后向我们的用户推荐相同的物品。或者我们可以查看用户的历史行为,推荐与它们类似的物品。
以上就是CF中的两种基本方法:基于用户(user-based)的协同过滤和基于项目(item-based)的协同过滤。
“最相似”在算法中意味着什么?
已知每个用户的偏好向量(矩阵R的每一行)和每个产品的用户评级向量(矩阵R的每一列)。
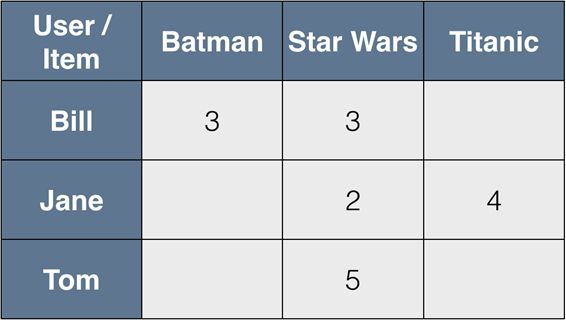
首先,只留下已知的两个向量的值。
其次,假设要比较Bill和Jane这两位用户,从图中可以看到,用户Bill没有看过《泰坦尼克号》,用户Jane也没看过《蝙蝠侠》,所以我们只能通过《星球大战》来测量二者之间的相似性。至于相似性,一般会采用余弦相似性或用户/项目矢量之间的相关性来测量。
最后一步,根据用户相似度,采用加权算术平均值填充表格中的空白单元格。
推荐中的矩阵分解
另一种方法是使用矩阵分解,这种推荐算法相对更“优雅”。一般来说,当涉及到矩阵分解时,不会过多考虑哪些项目将保留在结果矩阵的列和行中。使用这种推荐算法,我们可以看到,u是第i个用户的兴趣向量,v是第j部电影的参数向量。
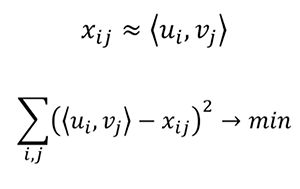
因此,可以把u和v的点积近似为x(从第i个用户到第j个电影的等级),用已知的分数构建向量并用它们来预测未知等级。
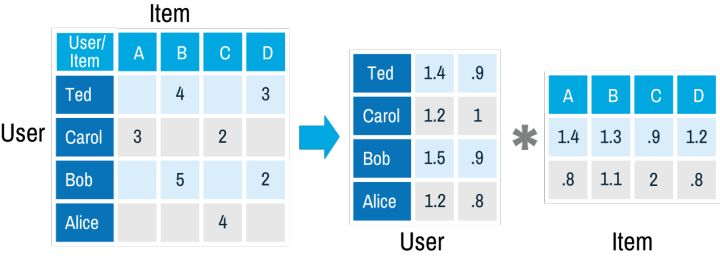
例如,在矩阵分解后,我们得到用户Ted的矢量(1.4, 0.9)和电影A的矢量(1.4, 0.8),之后只要计算矢量(1.4, 0.9)和(1.4, 0.8)的点积,就能得到A-Ted的等级,结果是2.68。
聚类
以前的推荐算法相当简单,这样的算法通常适用于小型的推荐系统。那么想象一下,我们正在建一个大型推荐系统,在这个系统中,协同过滤和矩阵分解会花很长时间。这时候我们应该做的第一件事就是聚类。
在业务开始时,缺乏用户之前的评分,聚类是最好的方法。
在数据足够多的时候,最好使用聚类作为协同过滤中缩小相关选择的第一步。除此此外,聚类还可以改善复杂推荐系统的性能。
每个群集分别代表一类典型的用户,基于用户群集中用户的兴趣画像,群集中的用户也会收到对应的推荐结果。
推荐中的的深度学习方法
在过去的10年中,神经网络技术取得了巨大的进步。现在,神经网络被广泛地应用于各个领域,并逐渐取代传统的ML方法。接下来我们就分析一下YouTube是如何使用深度学习方法的。
毫无疑问,由于用户规模大、动态语料库和各种不可控的外部因素,为这样的业务场景搭建推荐系统是一项非常具有挑战性的任务。
据相关研究Deep Neural Networks for YouTube Recommendations,YouTube推荐系统算法由两组神经网络组成:一组用于候选生成,一组用于排序。以下是这项研究的主要内容:
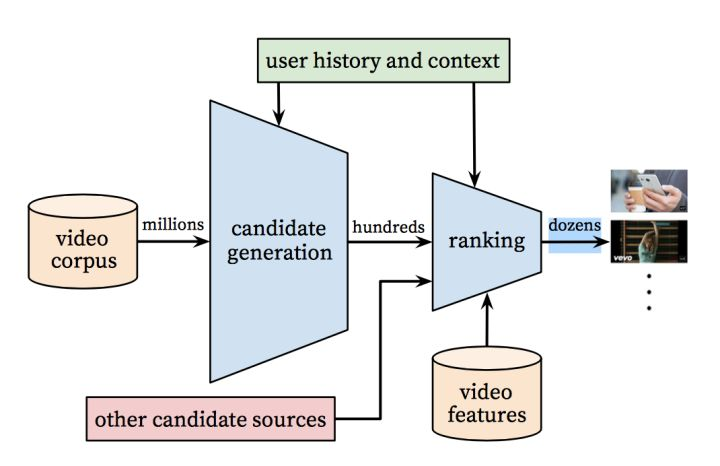
将用户的历史事件作为输入,通过候选生成网络显著减少视频量,然后从大型语料库中创建一组最相关的视频。
生成的候选者与用户相关性最高,之后预测候选者的等级。该网络的目的是通过协同过滤提供个性化推荐。
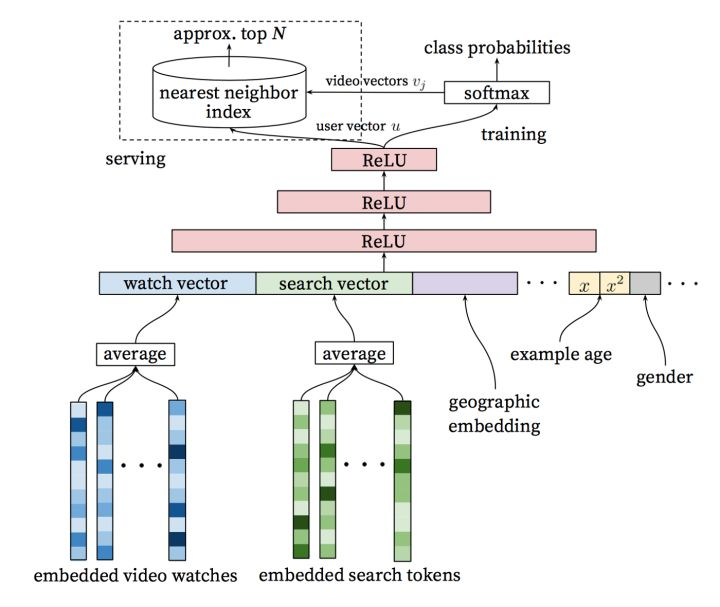
在此步骤中会有少量与用户相似的候选者。接下来我们需要越加仔细地分析这些候选者,以便做出最好的决策——该任务由排序网络完成。
排序网络可以根据目标函数为每个视频打分,该目标函数使用的是描述视频的数据和与用户行为相关的信息。打分最高的视频会按分数排序,呈现给用户。
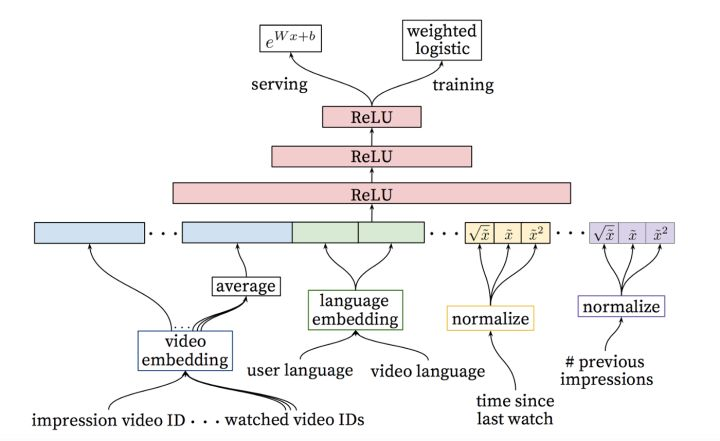
经过以上这两个步骤,我们可以实现把庞大的视频集精准推荐给用户的操作,同时确保少数视频仍是个性化推荐。
文章来源:Recommendation System Algorithms
以上内容由第四范式-先荐编译。
相关阅读:
如欲了解更多,欢迎搜索并关注先荐微信公众号(ID:dsfsxj)。
本账号为第四范式智能推荐产品先荐的官方账号。账号立足于计算机领域,特别是人工智能相关的前沿研究,旨在把更多与人工智能相关的知识分享给公众,从专业的角度促进公众对人工智能的理解;同时也希望为人工智能相关人员提供一个讨论、交流、学习的开放平台,从而早日让每个人都享受到人工智能创造的价值。
