

这篇文章的主要目的是用较为简单的术语来解释一下,浏览器是怎样一步步把HTML,CSS和JS变成你能看到(交互)的页面
知道浏览器是怎样把网页呈现给你的这个过程之后,就能够帮助你去优化你的网页应用,从而提升速度和性能。
介绍
浏览器如何呈现网站?
我马上就会阐述这个过程,但是首先,需要回顾一些基本概念。
一个网页浏览器从远程服务器上(或者本地文件)加载文件来显示给你看,允许你进行操作。
浏览器里有一个浏览器引擎。
不同的浏览器,都有一个浏览器引擎,基于获取到的那个文件来知道怎样显示页面。
浏览器引擎是主流浏览器的核心组件,不同浏览器制造商把他们的引擎起不同的名字。
Firefox浏览器的引擎叫Gecko,Chrome的叫Blink(是Webkit的一个分支)。别因为这些名字感到困惑,它们只是名字而已,没什么大不了的。 更多浏览器引擎看这里
在本文中,我可能会把“浏览器”和“浏览器引擎”互换着使用。不要有疑惑,我们讨论的核心就是浏览器引擎。
发送 & 接受数据
这里不是一堂计算机网络的课程,不过你应该记得数据是被当作“包(packets)”在网络中传输的,以字节(bytes)大小为单位。
我想说的关键是当你写了HTML,CSS和JS后,想用浏览器来打开这个HTML文件,浏览器会从硬盘(网络)上读取原始字节(raw bytes)。
浏览器获取到了字节数据后,无法用它来做任何事情。
这些字节数据必须转换成能够理解的形式,这就是第一步。
从HTML的原始字节数据转换到DOM
浏览器需要用文档对象模型(DOM)来工作。 那么,DOM是怎么来的? 首先,原始字节会转成字符(characters)。这些字符就是你之前写的代码。这个转换工作是由HTML的字符编码器来完成的。 此时,浏览器从字节数据转到了文件真实的字符。 字符内容不错,但是他们还不是最终产物。 这些字符被进一步解析成标记(tokens)。
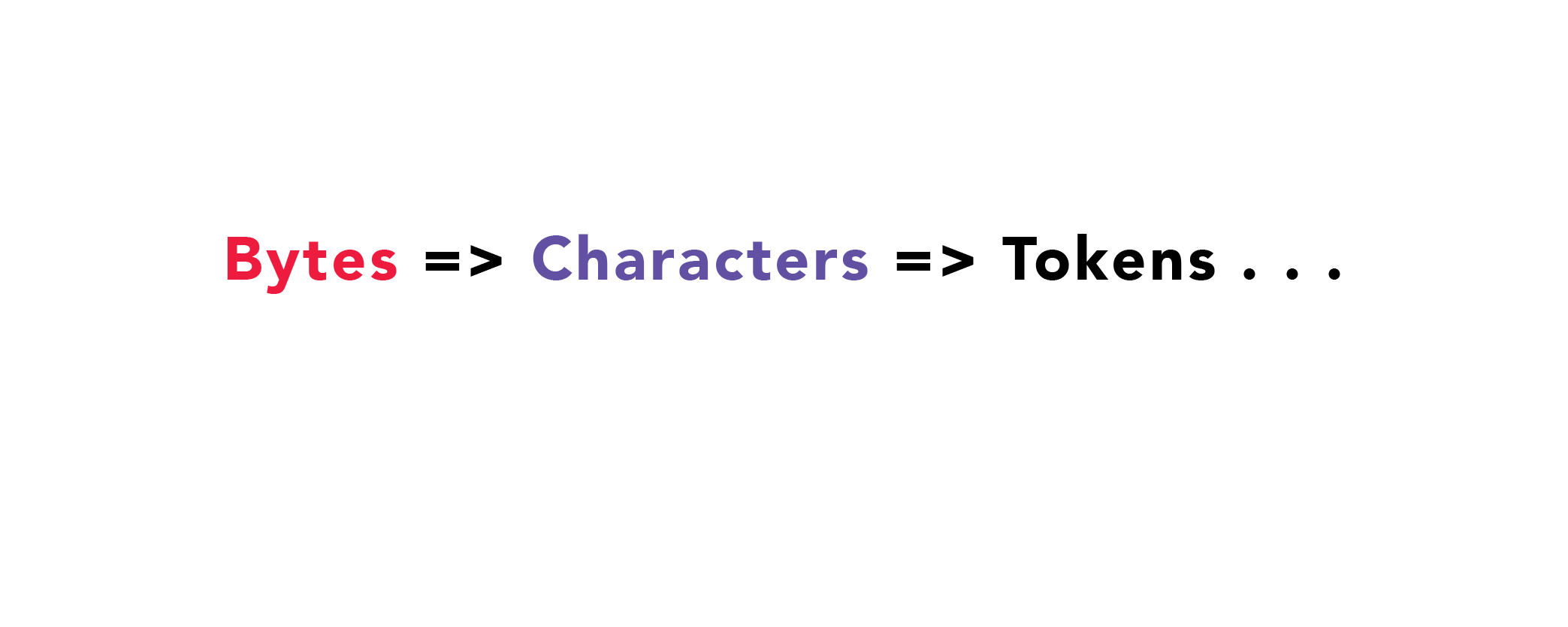
当你把文件保存成.html扩展名后,就是提醒浏览器用html文档的方式来解释这个文件。浏览器来“解释”这个文件第一步就是先解析它。
在这个解析过程中,特别是在标记化中,(浏览器)会去考虑每个开始和结束的html标签(tags)。
解析器会去理解每个在监控号里的字符串,比如<html> <p>,并知道这些字符串的规则。比如,<a>标记和<p>具有不同的属性。
从概念上来说,会把标记(tokens)看作是某种数据结构,它包含了某个html标签的信息。实际上,一个html文件会被拆分成一个个小的标记(tokens)。

标记(tokens)仍然不是我们要的最后产物。
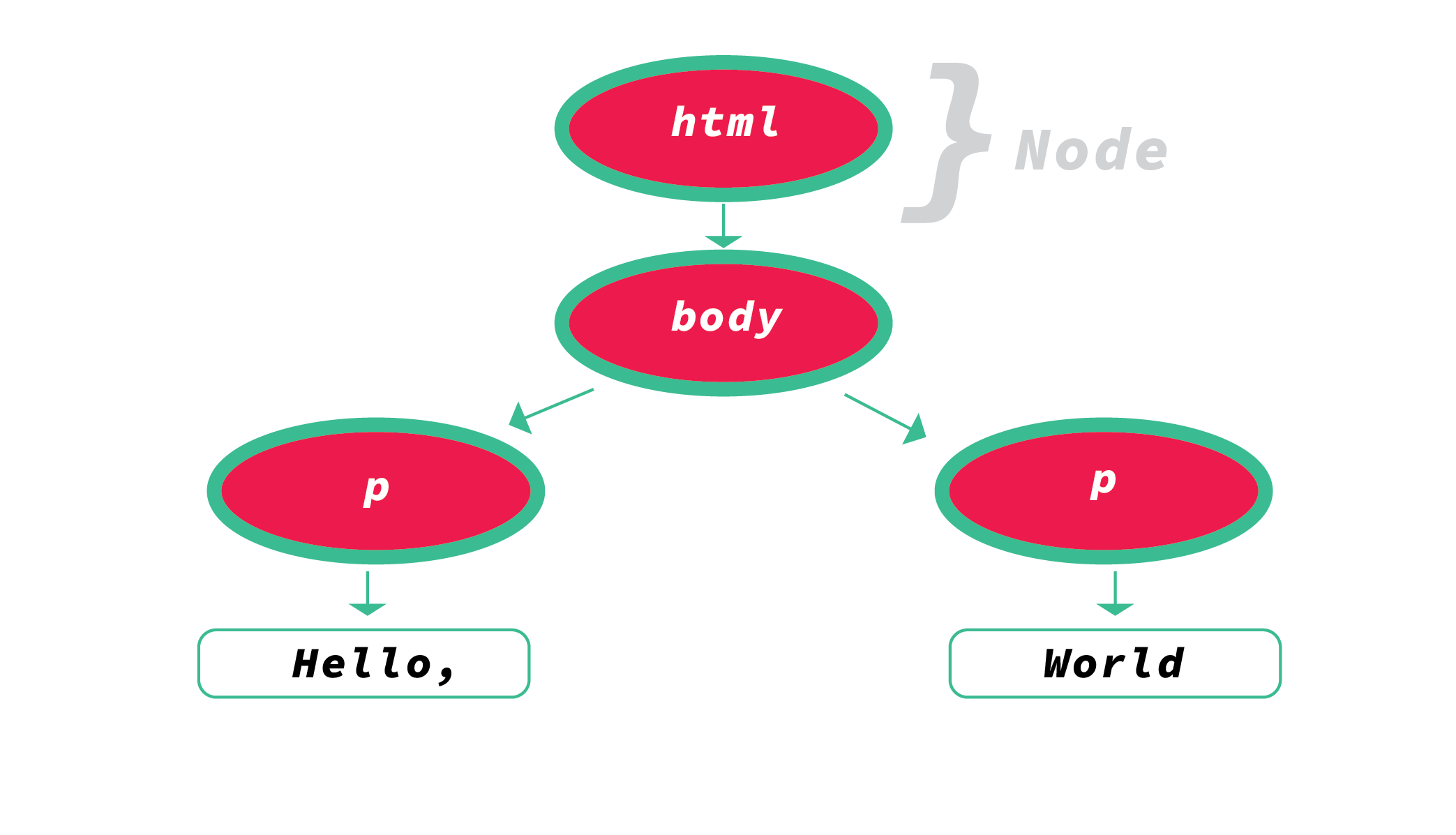
标记化结束后,这些标记还会被转换成节点(nodes)。
你可以把节点认为是具有特定属性的不同的对象。实际上,更好的解释是把节点看做是文档对象树里的一个单独的实体。
节点(nodes)仍然不是最后结果。
好了,接下来是最后一点。
创建好节点后,这些节点会被连接成一棵树状的数据结构,也就是DOM树。
DOM建立了父-子关系,兄弟关系等。
现在,这是我们可以使用的东西了。
一般,你不会用浏览器打开css和js文件来看网页,一般会打开HTML文件,大多数情况下打开的是index.html。
这正是你这样做的原因:浏览器做任何事之前,必须先把html文件的原始数据转换成DOM。
根据这个html文件,DOM构建过程可能都需要一些时间(无论大小)。

CSS
一个典型的html文件加入一个css链接,如下:
<!DOCTYPE html>
<html>
<head>
<link rel="stylesheet" type="text/css" media="screen" href="main.css" />
</head>
<body>
</body>
</html>
当浏览器引擎接收到原始数据并开始创建DOM的时候,也会发送请求去获取main.css样式表。
浏览器开始解析html,一旦发现有link标签,同时就会去请求这个css文件。
你可能猜到了,浏览器获取到的CSS数据也是原始字节数据(不管从网络还是本地)。
但是这些CSS的原始数据是怎样被处理的呢?
CSS原始字节数据到CSSOM
当浏览器获取到CSS原始数据的时候,也会启动一个类似处理HTML原数据的进程, 就像我上面所说的那样,原始数据->字符->标记化->节点->树。
这个树是什么?
许多人知道DOM树,同样的,也有一课叫做CSS对象模型的树(CSSOM)。
你看到了,浏览器不能用HTML和CSS的原始数据来做事情。必然要经过转换后变成浏览器能够是别的才可以——也就是这些树结构。

CSS里有一种叫做级联(Cascade)的机制,让浏览器用来决定元素应该是采用哪种样式。
影响一个元素的样式有:从父元素那里继承过来,或者设置在自己身上,因此CSSOM树变得比较重要。
为什么?
这是因为浏览器必须递归遍历CSS树来确定某个元素的样式。
渲染树
到现在为止,我们有了两棵独立的树结构(DOM和CSSOM),似乎毫不相关。
DOM包含了所有HTML元素的关系,而CSSOM包含了元素的样式。
OK,浏览器现在把DOM和CSSOM组合成了渲染树(render tree)。

渲染树包含了所有的可见的DOM内容,以及不同节点的所有所需要的CSSOM信息。
注意,如果一个元素通过display:none;方式隐藏的话,那它不会出现在渲染树里。
这个隐藏的元素在DOM树里,但是不在渲染树里。
因为渲染树是从DOM和CSSOM合成出来的,所以它知道不包含这个隐藏的元素。
当渲染树建好之后,浏览器开始下一步操作,回流(layout)!
回流(layout)
现在我们已经有了能显示在屏幕上的内容和样式信息,但是我们还没有渲染任何东西。
首先,浏览器需要计算每个元素的准确大小以及位置。回流就是通过DOM和CSSOM来执行所需要的计算。
“layout”,“reflow”,中文翻译回流。
开始画吧
通过DOM,CSSOM,以及回流计算后,最后,浏览器就把各个节点画到屏幕上了。
