

在前面的几篇文章中已经介绍了Alamofire的request。本篇我们一起来了解一下response。
一、reponse函数
说到response很多小伙伴都会和序列化联系起来,那么Alamofire的response的作用到底是什么呢?
我们来看个栗子🌰:
let urlBD = "https://www.baidu.com"
Alamofire.request(urlBD, method: .get, parameters: ["user": "bo"])
.response { (response) in
print(response)
}
运行结果会打印很多内容,因篇幅原因就不贴图了,就留给小伙伴自行玩耍吧。
这些 response 中的内容是如何来的呢?我们一起来看看源码。
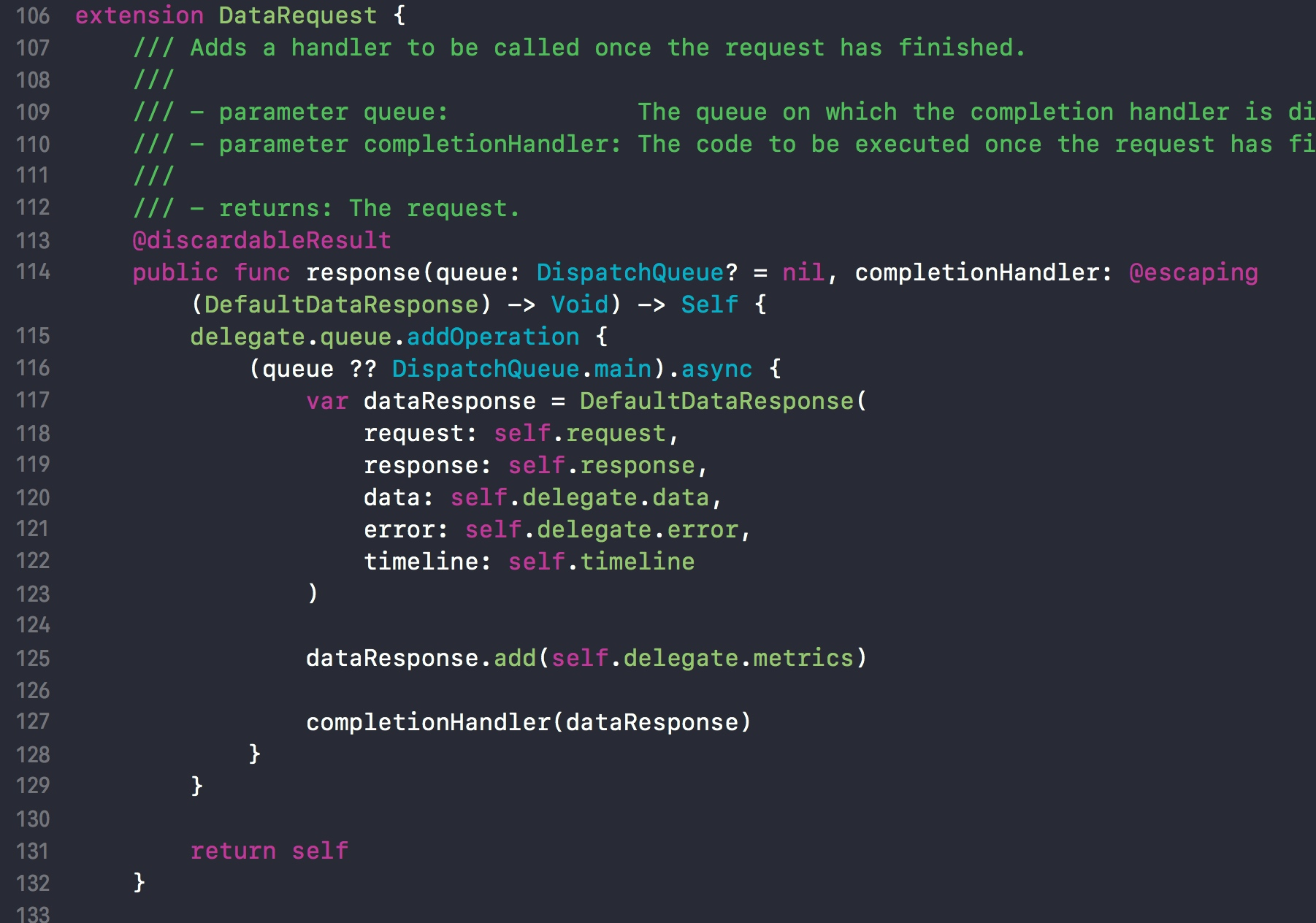
从源码可以看出,response 函数并没有做序列化的处理。而是使用 Request 的 self.request、self.response、self.delegate、self.timeline 属性封装成一个新的对象 DefaultDataResponse返回给 completionHandler 闭包。
因为 response 函数是 DataRequest 的扩展。所以 self.request、self.response 比较容易理解。那么 self.delegate.data 是什么呢?我们点击查看源码:
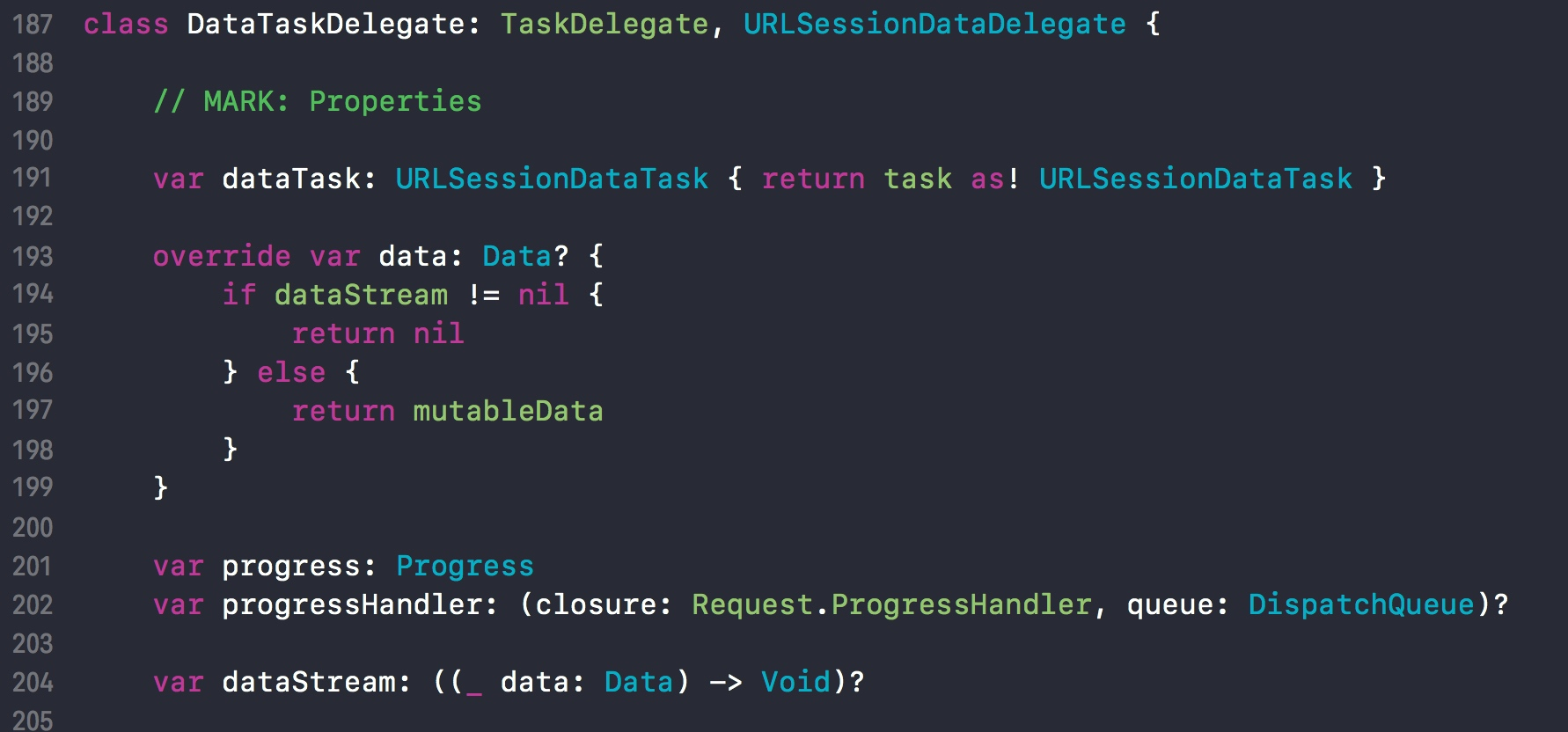
可以看到,如果 dataStream 闭包为空,则返回 mutableData 。所以我们再继续查看 mutableData 是什么时候赋值的。
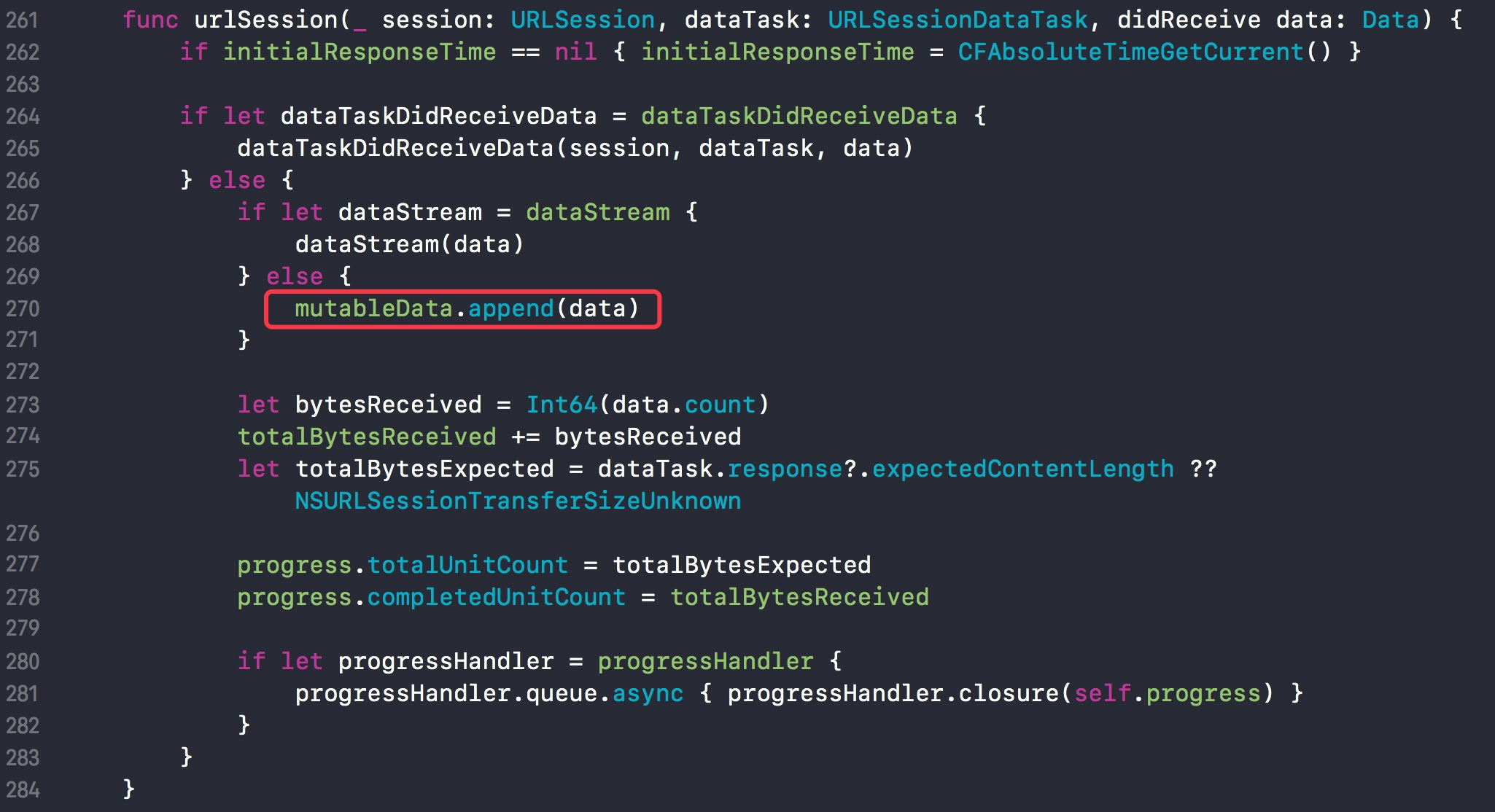
我们找到在 func urlSession(session:dataTask:didReceive:) 回调中,返回的数据 data 会被添加到 mutableData 中。
为什么需要 mutableData 呢?因为请求的数据可能是分段返回的,所以需要一个中间变量来存储每次返回的数据。
和 self.delegate.data 类似, self.delegate.error 也是在回调函数 didCompleteWithError 中判断,如果有错误,则给 error 赋值。
至于 self.timeline,我们在上一篇 Alamofire之request补充 已有介绍,这里不再赘述,想了解的小伙伴请移步。
综上,可以总结出,其实
response函数并没有做其他处理,仅做为保存数据和返回数据的载体,其整合了request请求的各个返回结果,作为一个整体返回给用户,供用户随时取用。
二、序列化
在查看 response 函数源码的时候,如果往下翻小伙伴可能会发现另一个 reponse 函数。
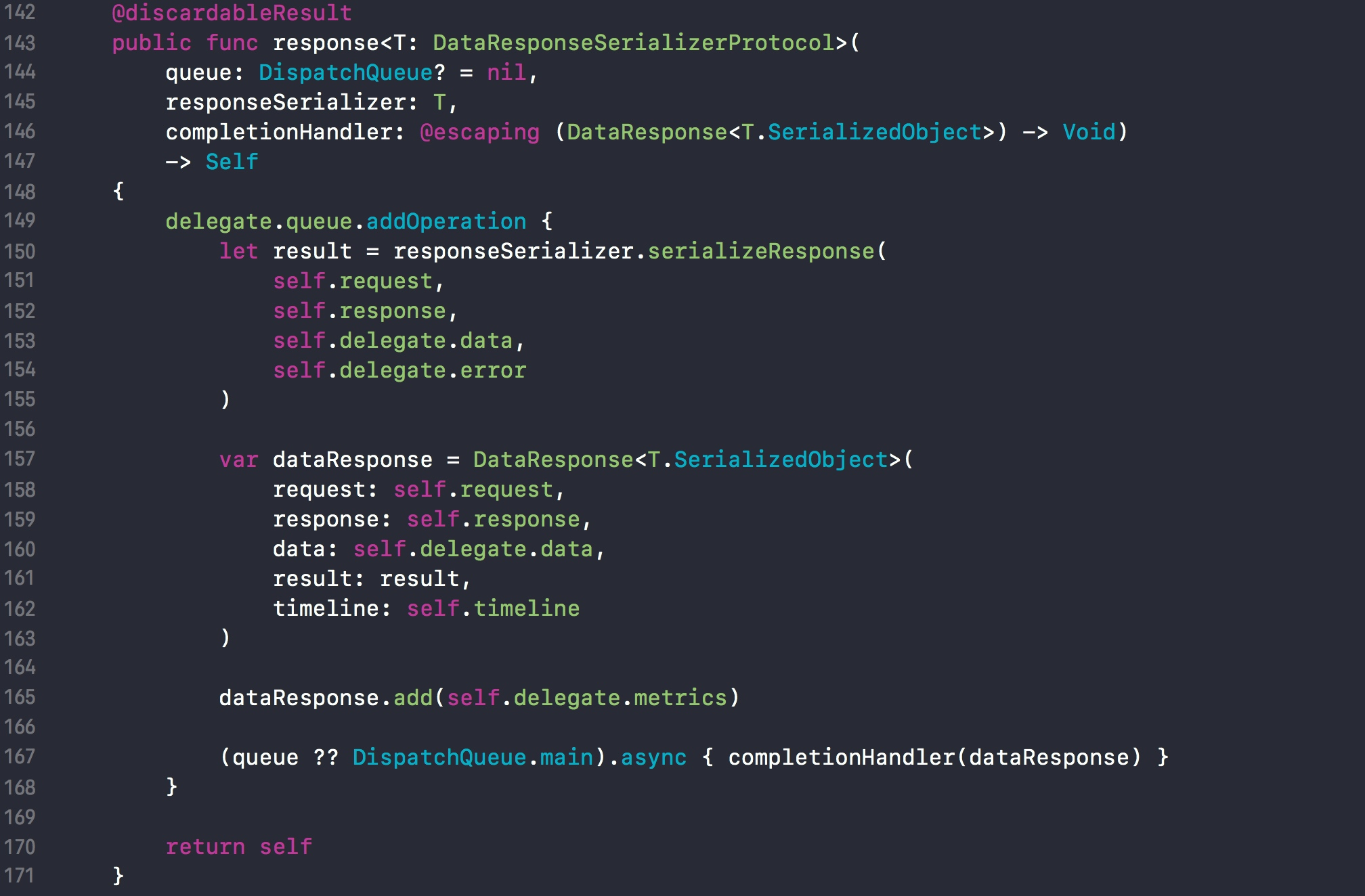
这个 response 函数和上一个相比,多了一个 responseSerializer 参数,这个参数就是序列化器。
那么这个 response 函数该如何使用呢?我们先来分析 responseSerializer 参数是个什么类型。
responseSerializer 的参数是一个泛型。泛型需要实现一个协议: DataResponseSerializerProtocol。

同时我们在其下方发现一个已经实现该协议的类型 DataResponseSerializer。
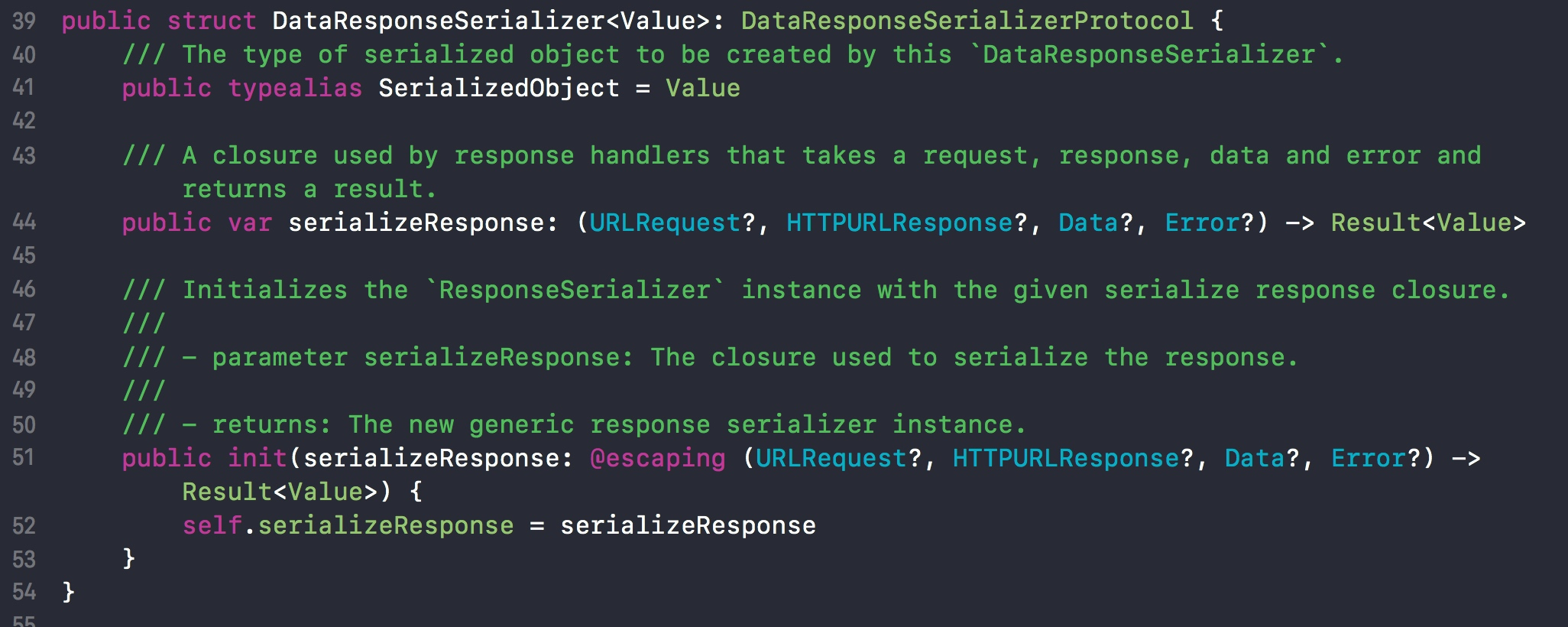
所以我们可以使用这个类作为序列化器。
let urlBD = "https://www.baidu.com"
Alamofire.request(urlBD, method: .get, parameters: ["user": "bo"])
.response { (response) in
print(response)
}
.response(responseSerializer: DataResponseSerializer<String>.init(serializeResponse: { (request, response, data, error) -> Result<String> in
if error == nil {
return .success("网络请求成功")
} else {
return .failure(NSError(domain: "网络请求失败", code: 10080, userInfo: nil))
}
})) { (reponse) in
print("序列化结果: \(reponse)")
}
DataResponseSerializer 初始化需要传入一个闭包,且闭包的返回值为 Result 类型。
从运行结果会发现,在打印出未序列化的 reposne 之后,会再打印出序列化后的结果。
以上就是response序列化器的分析,包括 Alamofire提供的
responseJSON函数,其内部仅是对 JSON序列化器做了一次封装而已。
三、多表单上传
先举个栗子🌰:
let url = "http://www.baidu.com/"
Alamofire.upload(multipartFormData: { (formData) in
formData.append("BO".data(using: .utf8)!, withName: "name")
formData.append("122345".data(using: .utf8)!, withName: "pwd")
}, to: url) { (result) in
print(result)
}
上面👆这段代码就是多表单上传的例子。然后使用抓包工具 Charles 抓包。
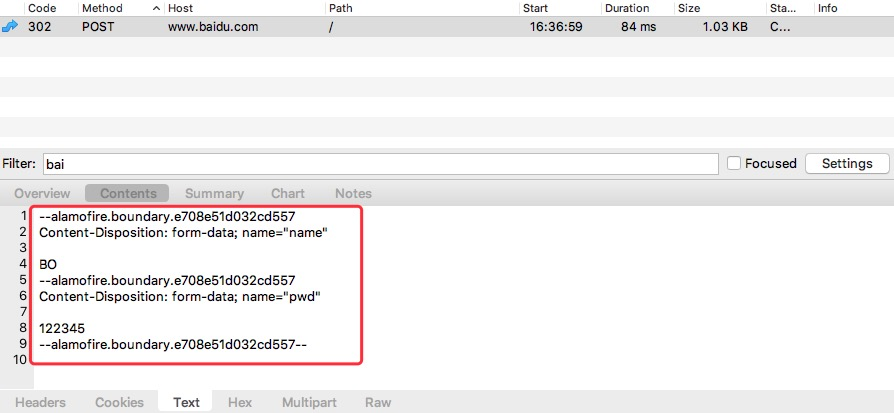
就可以看到如上所示的结果。
其实在进行多表单上传时,需要将表单数据按照一定的格式(如上图)封装到httpBody中。具体格式请小伙伴自行google。
那么Alamofire是如何封装的呢?我们一路查看源码,很容易就能找到这里:
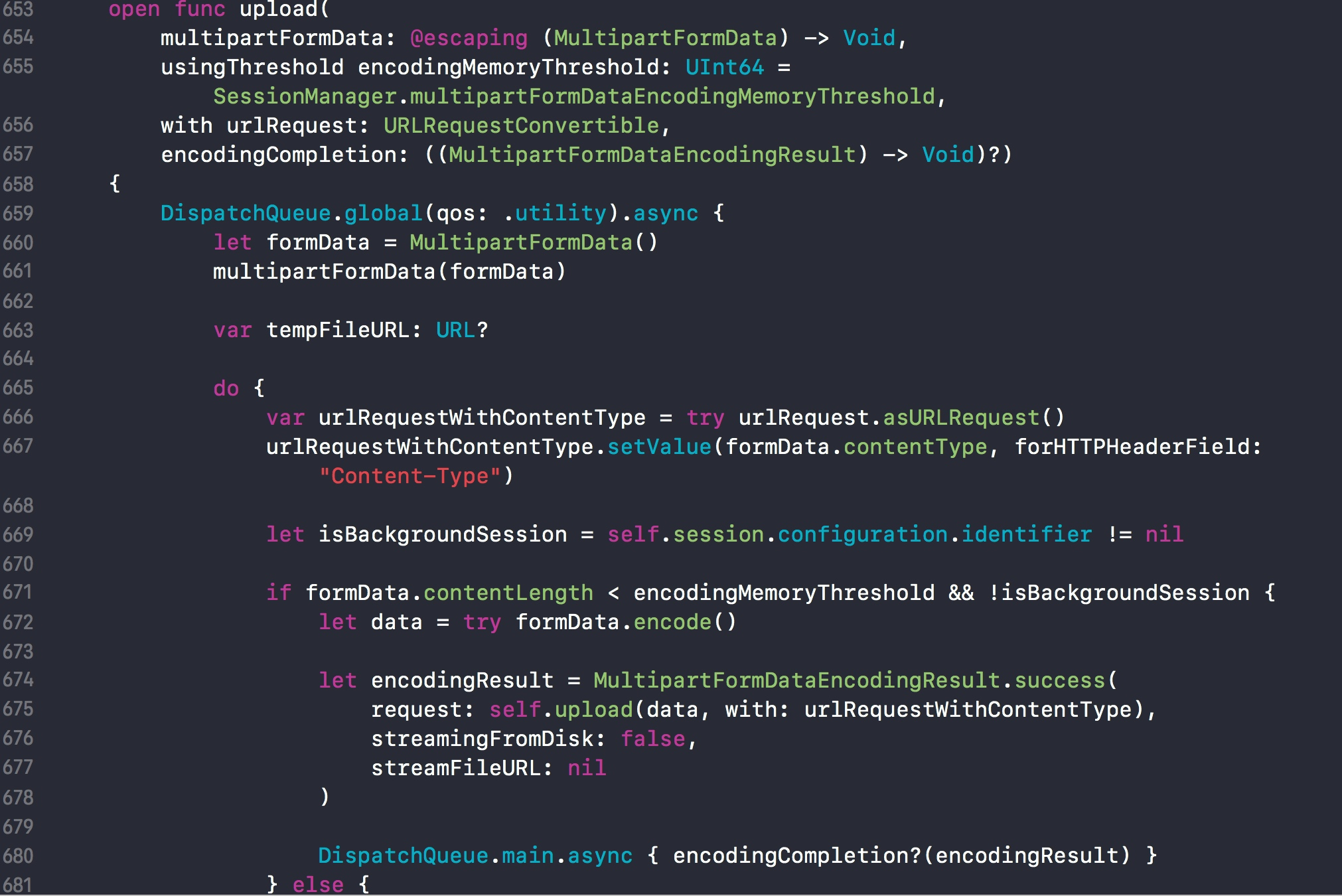
首先因为在读取数据时可能是一个耗时操作,所以
- 在异步线程中初始化一个
MultipartFormData对象。 - 再调用
multipartFormData闭包,拼接表单数据。 - 在发起网络请求之前,需要先设置
Content-Type,表明这是一个表单数据,以及boundary边界信息。 - 再调用
formData.encode()格式化数据。
1、添加表单
我们在向表单中添加数据时,会调用 append 函数添加数据。

在 append 函数中,参数 name 会被先传入 contentHeaders 函数中进行处理。
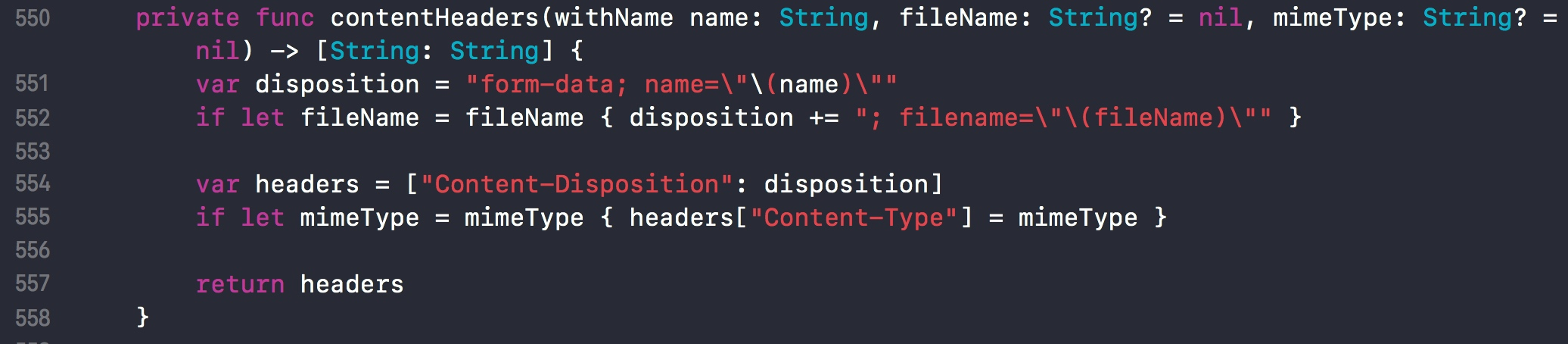
经过处理后会成为我们所需要的格式。
然后再将格式化后的 headers 和 data 封装成 BodyPart 对象。

最后添加到 bodyParts 数组中保存起来。
2、encode表单
需要格式化表单时,会调用 encode 函数。
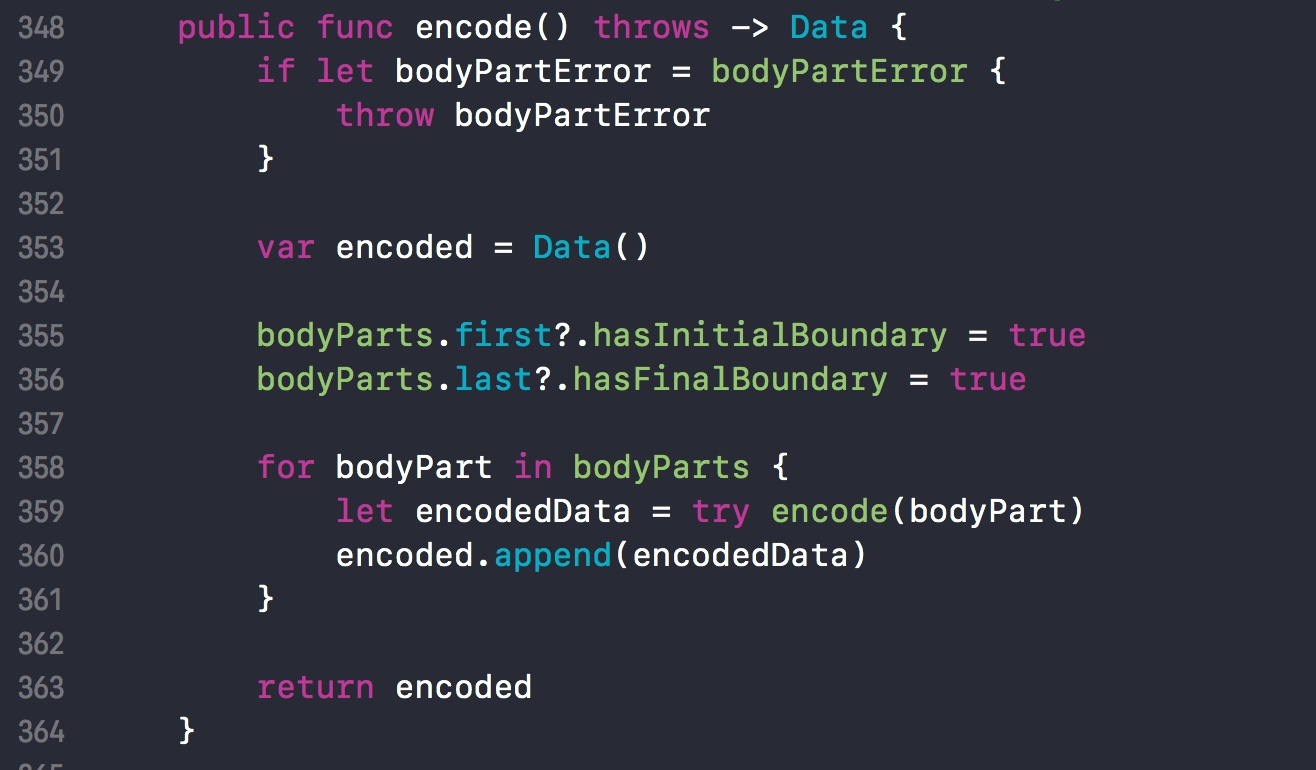
encode 函数会将 bodyParts 中的首尾两个元素分别设置 hasInitialBoundary = true 和 hasFinalBoundary = true,标识出其是首尾元素。
再遍历 bodyParts 数组中的元素,对每一个元素分别进行 encode。
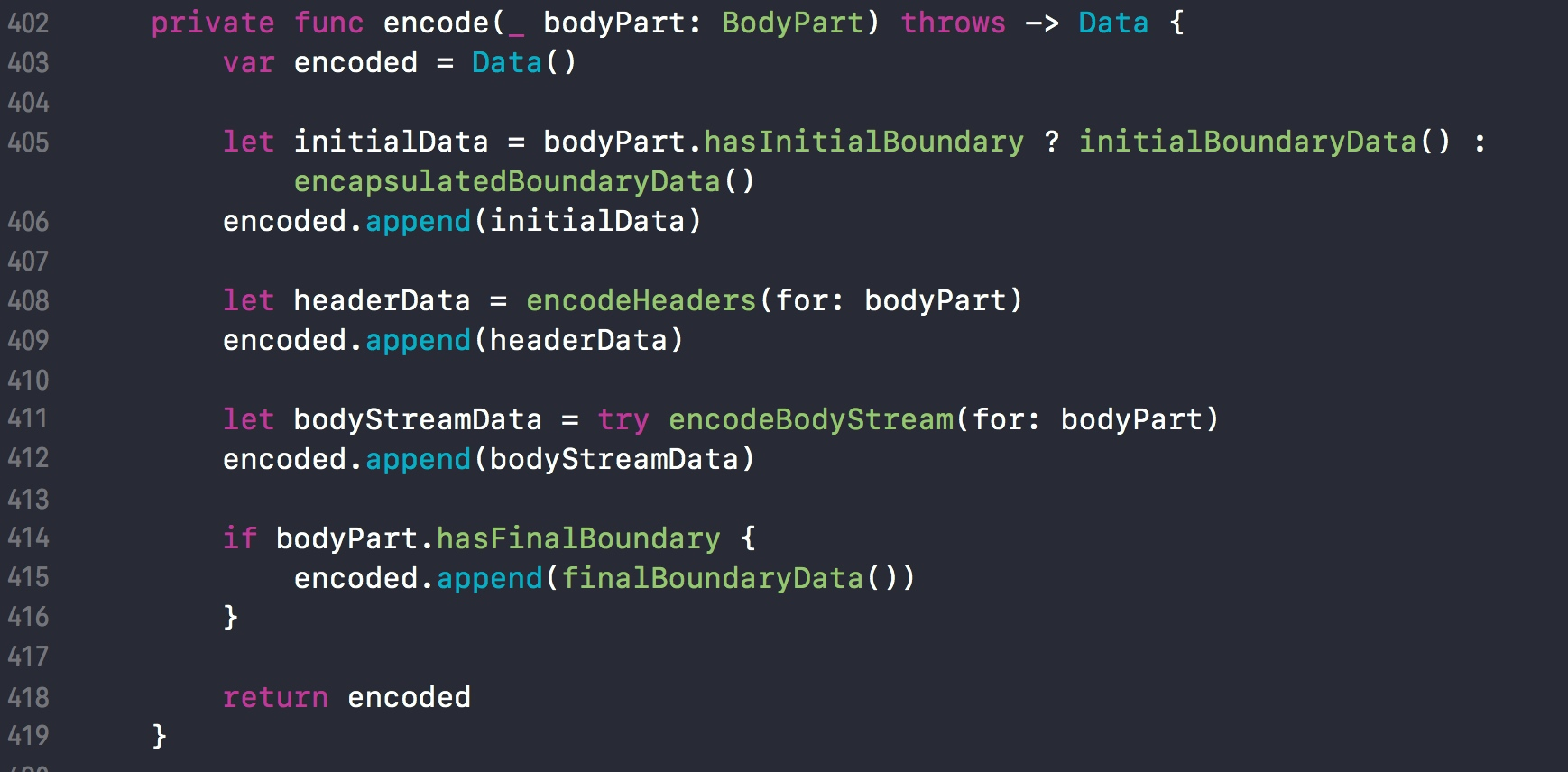
1、格式化边界
首先通过 hasInitialBoundary 判断是首元素还是中间元素。
- 如果是首元素,则调用
initialBoundaryData()函数。 - 如果是中间元素,则调用
encapsulatedBoundaryData()函数。 - 如果是尾元素,则调用
finalBoundaryData()函数。

这三个函数调用的都是 boundaryData 函数,仅参数不同。
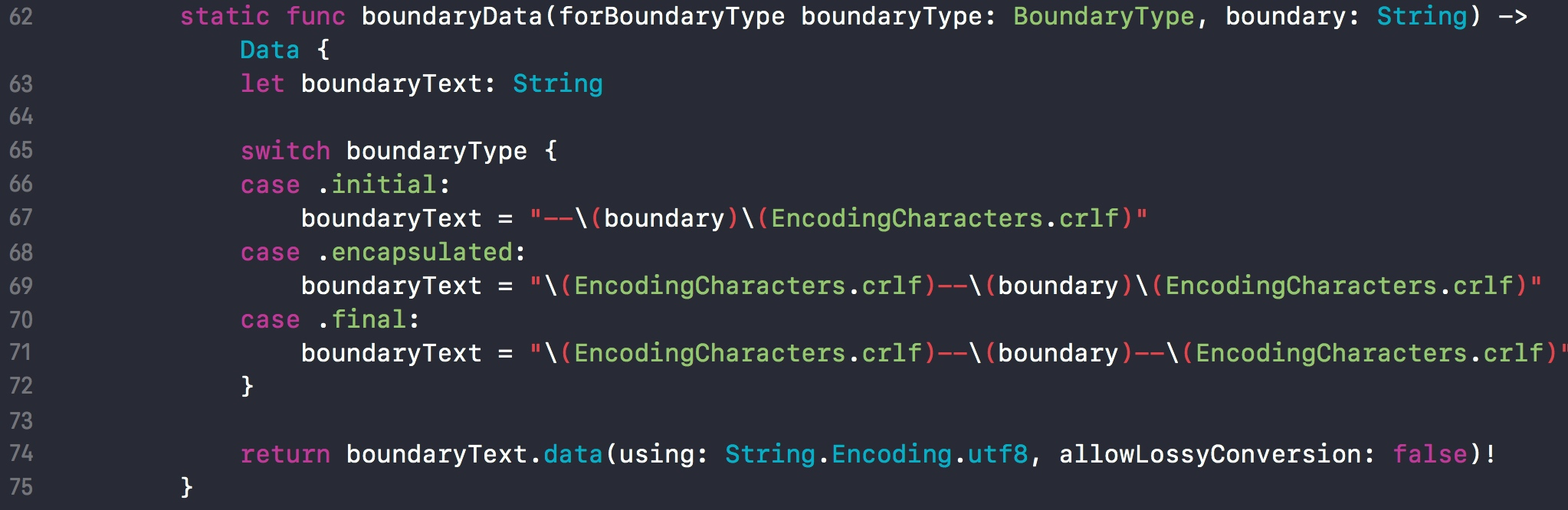
所以,最后生成的边界格式会有所不同。如: 首元素:--alamofire.boundary.xxx 中间元素:--alamofire.boundary.xxx 尾元素:--alamofire.boundary.xxx--
2、格式化name
对每个元素调用 encodeHeaders 函数。

最后生成格式如下: Content-Disposition: form-data; name="name"
3、格式化data
对每个元素调用 encodeBodyStream 函数。
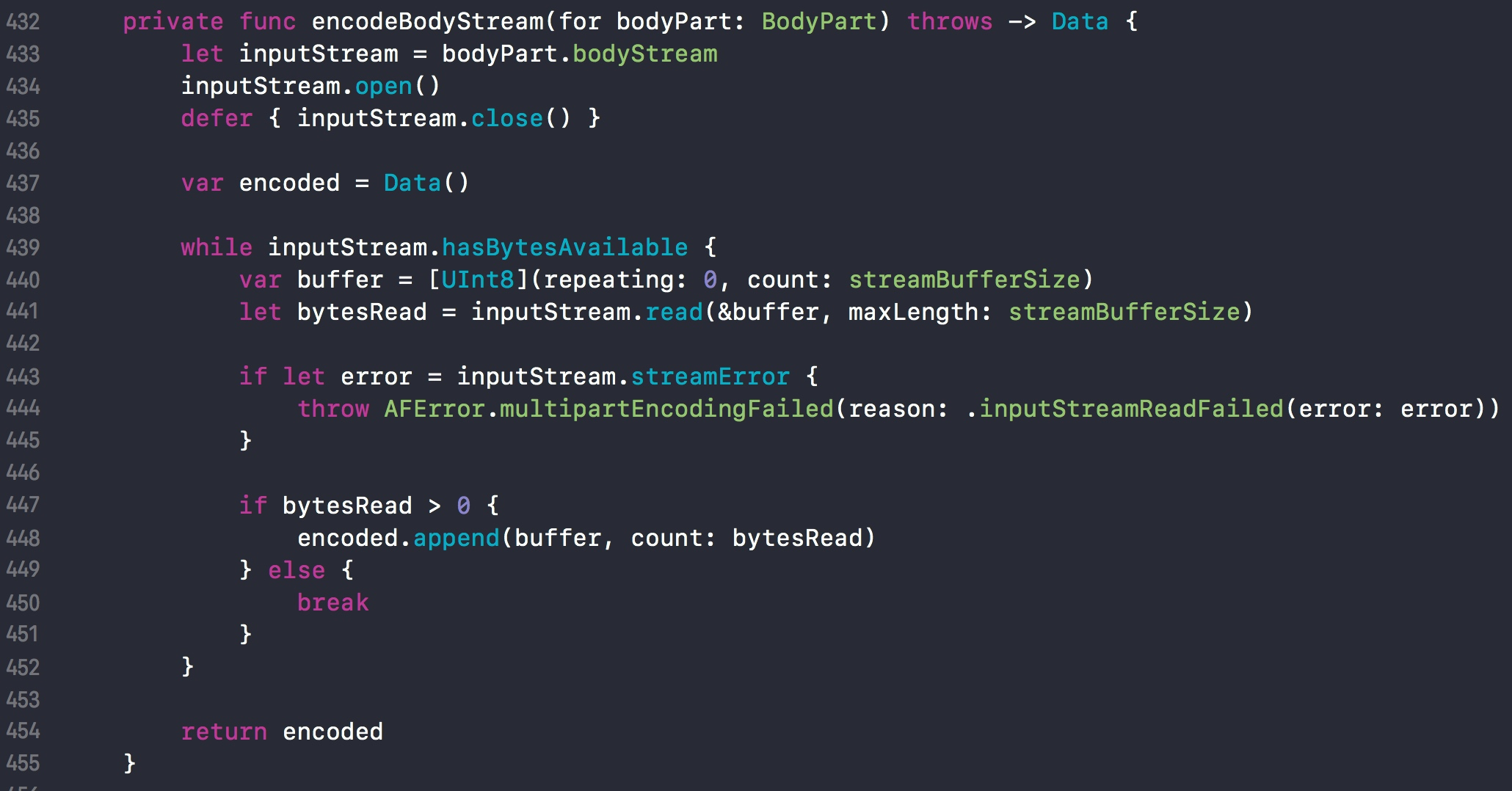
因为表单数据可能是一个很大的文件,如果要将文件整个读取到内存中,将会消耗掉很大的内存空间,造成资源紧张。所以使用 数据流stream 的方式读取数据。生成格式如:BO。
最后将生成的所有数据拼接为一个data数据,完成表单数据的封装。
以上,则是多表单上传中,表单数据的格式化解析。
