近年来最新的一系列实例分割模型,例如 Mask R-CNN 等,其高准确度很大程度上依赖于大量的训练数据(COCO 数据集包含 20 余万张训练图片)。但是获取像素级别的标注是一项成本高昂且复杂精细的工作。为此,上海交通大学 MVIG 实验室(卢策吾团队)提出了 InstaBoost——一种基于 crop-paste 的实例分割数据增强方法。实验表明,在 Mask R-CNN 和 Cascade R-CNN 等框架中应用 InstaBoost,可以在 COCO 实例分割数据集上达到 2.2 mAP 的提升。同时,该方法还能够将物体检测的精度在 COCO 数据集上最高提升 4mAP。该论文已被ICCV 2019接收。
该方法的操作非常简单,目前已发布为 pip 包,只需 python 中加一行代码,import instaboost,换一个 dataloader 函数就可以在 COCO 实例分割数据集上实现显著的性能提升。
然而实例分割这种像素级的分类要比目标检测难很多,对应的数据增强也要困难很多,这主要体现在它并不能随意把目标切割并移到另外的背景上,因为它们对分割结果也有很大的影响。
来自上海交通大学 MVIG 实验室的研究人员在实例分割应用中对其进行改进优化,成功的将模型的实例分割精度大幅提升,同时也能实现目标检测的提升。

论文地址:https://arxiv.org/abs/1908.07801
代码地址:https://github.com/GothicAi/InstaBoost
演示地址:https://youtu.be/iFsmmHUGy0g
实例分割任务中的数据增强
早期一些方法使用 domain adaptation 等思路,将其他领域的数据作为信息来源辅助数据增强,但是这些方法没有充分利用训练集的 mask 标注信息。
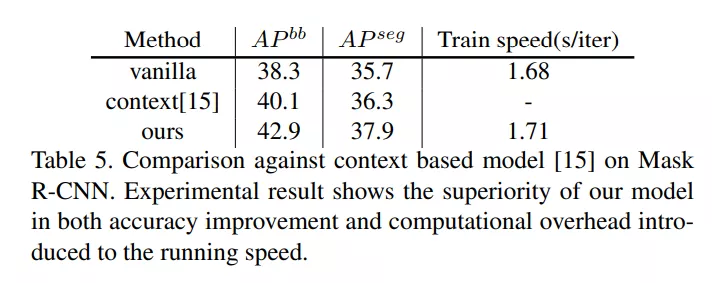
近期一些研究使用基于 crop-paste 的方法在目标检测任务中取得了不错的效果。简单来说,这些方法将物体按照 mask 标注的信息从原图片中剪下来,然后粘贴到一个随机的背景图片上。但是研究者发现这种方法在分割任务中,由于实例和背景契合程度较差,在实验中表现比 baseline 要差。为了解决这一问题,一些论文提出了使用 context model 去为二者一致性打分,但是这种该方法计算成本过高,难以在实际场景中应用。
研究者在这篇论文中提出了两种递进的实例层面的数据增强算法:Random InstaBoost 和 Map-guided InstaBoost。这类算法极大地提高了检测和分割精度。
Matting 和 Inpainting
在将图片前景和背景按照标注进行分离的过程中,如果完全按照标注去切割前景,前景的边界处会呈不自然的多边形锯齿状,这与 COCO 数据标注方式有关。为了解决这一问题,研究者使用《A global sampling method for alpha matting》一文中提出的方法对前景轮廓做 matting 处理,以得到与物体轮廓契合的边界。
在前景背景分离后,背景上会存在若干个空白区域,这些区域可以使用 inpainting 算法进行填补。论文中使用了《Navier-stokes, fluid dynamics, and image and videoinpainting》文章中提出的 inpainting 算法。

Random InstaBoost
为了尽可能保证粘贴后前景和背景融合的契合程度,直觉上来说将前景粘贴到原位置的附近是最可靠的。Random InstaBoost 方法即是在上述先验的判断下提出的。研究者通过定义一个四元数 (tx, ty, s, r) 来映射前景在数据增强前后的变换。四个参数从左至右分别表示了水平位移,垂直位移,放缩程度和旋转角度。将这四个参数在 (0, 0, 1, 0) 附近进行独立的随机扰动,即可生成一系列符合外观一致性的增强图片。

Map-guided InstaBoost
外观描述符 D(•)
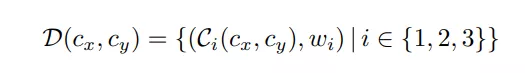

外观距离定义为,外观描述符之间局部外观一致性的度量。由于我们已经定义了具有三个轮廓区域和相应权重关联描述符,D1=D(c1x, c1y) 和 D2=D(c2x, c2y) 之间的外观距离被定义为:
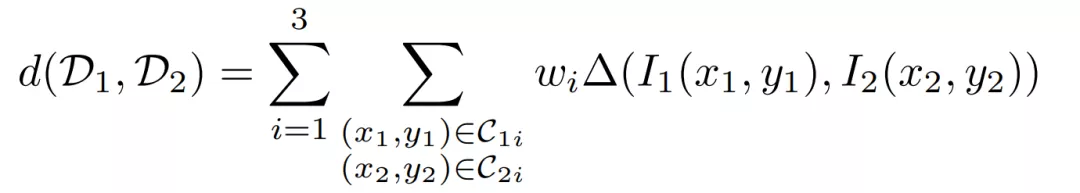
热度图生成与引导平移
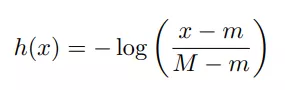

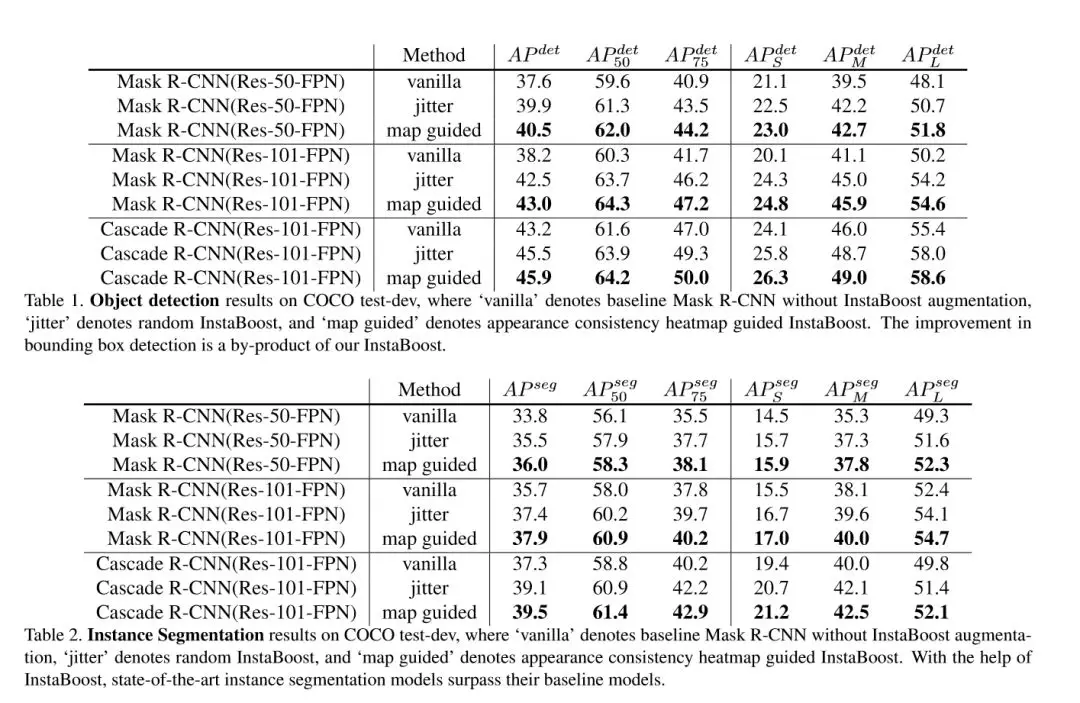
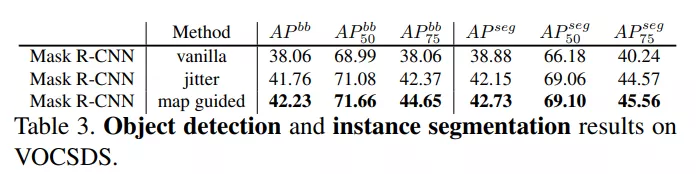
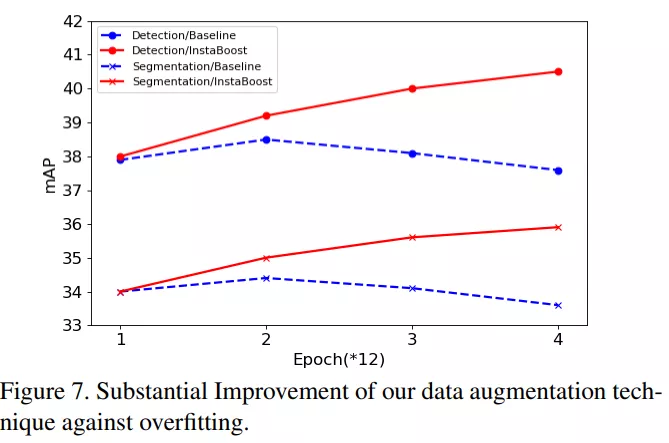
在实验过程中,作者使用 Mask R-CNN 和 Cascade R-CNN 两个框架在 COCO 数据集上分别进行了测试,测试结果如下图所示。结果显示,在目标检测和实例分割任务上,InstaBoost 在 mAP 标准下最高带来 4mAP 和 2.2mAP 的提升。