

编译器
说起编译原理,可能我们脑海中首先浮现的就是 “编译器” 这个词汇。维基百科上对编译器的定义是:编译器是一种计算机程序,它会将某种编程语言写成的源代码(原始语言)转换成另一种编程语言(目标语言)。 通常一个编译器的编译过程会经过词法分析、语法分析、语义分析、生成中间代码、优化、生成目标代码这几个阶段。如果将其简要概括,则只包含 解析 ( parse ) 、转换 ( transform ) 、生成 ( generate ) 这三个阶段。
- 解析 ( parse ) 是将原始代码转换为更为抽象的表达形式,在这个阶段编译器会对原始代码进行词法分析、语法分析、语义分析并最终生成抽象语法树 ( AST ) 。例如,ESTree 就是 JavaScript 的 AST 规范。
- 转换 ( transform ) 让我们可以在同一种语言下操纵 AST ,也可以将它翻译为另一种语言的 AST 。
- 生成 ( generate ) 阶段则是将转换后的 AST 翻译为目标代码的过程。
如果想要了解一个简单的编译器是如何实现的,可以看看 The Super Tiny Compiler 。
转译器
既然讲到了编译器 ( compiler ) ,就不得不提与它概念十分相近的转译器 ( transpiler ) 。转译器其实是一种特殊的编译器,它用于将一种语言编写的源代码转换为另一种具有相同抽象层次的语言。 例如,能够将 TypeScript 转换为 JavaScript 的 tsc 转译器以及能够将 ES6+ 转换为 ES5 的 Babel 转译器。从这里我们也可以看出编译器与转译器最大的区别就在于编译器是将高级语言转换为低级语言(例如汇编语言、机器语言),转译器则是相同抽象层次间的语言转换。
领域特定语言
Ruby 之父松本行弘在《代码的未来》一书中对领域特定语言 ( Domain Specific Language ) 有着这样的解释:
所谓 DSL ,是指利用为特定领域 ( Domain ) 所专门设计的词汇和语法,简化程序设计过程,提高生产效率的技术,同时也让非编程领域专家的人直接描述逻辑成为可能。DSL 的优点是,可以直接使用其对象领域中的概念,集中描述 “想要做到什么” ( What ) 的部分,而不必对 “如何做到” ( How ) 进行描述。
DSL 这个概念最早其实是由 Martin Fowler 提出,他把 DSL 分为内部 DSL 和外部 DSL ,而实现外部 DSL 的理论基础就是编译原理。我们知道如果将计算机编程语言按抽象层次划分可以分为高级语言、汇编语言以及机器语言。DSL 则是基于高级语言之上的抽象层次。上文提到的 TypeScript ,ES6+ 以及 React 中的 JSX 、Vue 中的 Template 、基于 Node.js 的模版引擎 ejs / jade / nunjucks 等等,从某种层面上来讲,它们都可以被叫做 DSL 。
如果想要具体了解 DSL 是什么,可以看看这篇文章。
理解 Babel 插件机制
在讲了这么多概念之后,相信读者很容易就可以理解什么是 Babel 插件。从上文中我们可以知道 Babel 其实就是一个转译器,它会将 ES6+ 语法的代码解析为 AST ,通过对 AST 中节点的增加、删除和更改将其转换为符合 ES5 规范的 AST ,最终再将转换后的 AST 翻译为 ES5 代码。下图展示了这个过程:
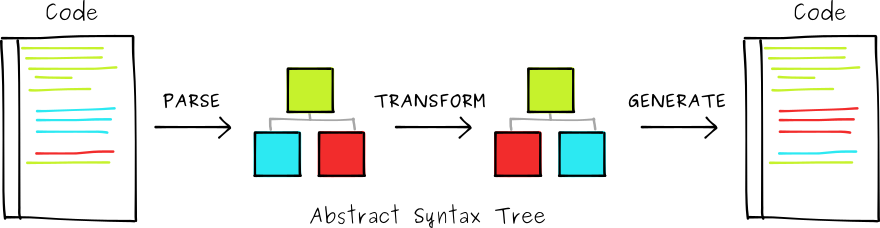
Babel 的主要作用是 ES6+ 转 ES5 ,但若只有这一个功能,肯定不能够满足开发者的需求。而 Babel 插件机制则能够让开发者涉足转换 ( transform ) 阶段,通过 Babel 提供的相关 API 操纵 AST ,并将原始代码转换为我们想要的目标代码。
编写 Babel 插件的前提
想要编写一个可用的 Babel 插件,是需要很多前置知识的。首先我们得理解基于 ESTree 的 AST 语法规范,通过 AST Explorer 我们可以实时查看某段代码生成的 AST ,对不同类型的节点对象有更加深刻的认识。在理解 AST 其实就是用来描述代码的一种抽象形式后,我们还需要学习如何对 Babel 生成的 AST 进行增加、删除和更改。在这里推荐 Babel Plugin Handbook ,里面完整地讲解了如何去写一个 Babel 插件,细读两遍之后写一个简单的 Babel 插件基本不在话下。在编写 Babel 插件时,我们常常会用到以下几个 npm 包:
- @babel/parser
- 将原始代码转换为能够让 Babel 操纵的 AST 。
- @babel/traverse
- 能够遍历 AST ,维护着整棵树的状态,并且负责替换、移除和添加节点。
- @babel/types
- 是一个用于 AST 节点的 Lodash 式工具库,它包含了构造、验证以及变换 AST 节点的方法,对编写处理 AST 逻辑非常有用。
- @babel/generator
- 将转换后的 AST 翻译为目标代码。
开始编写 Babel 插件
在这里我们以实现一个简单的函数性能分析工具为例,最终完成一个能够收集函数名、函数耗时以及函数对应行列号的 Babel 插件。它的基本原理其实就是在 Babel 遍历 AST 时,通过对 AST 节点的增加、删除和更改,在每个有效函数的首尾插入我们的打点代码,之后我们还会收集函数名和函数对应的行列号,最后当代码运行时再收集函数耗时的相关数据。下图展示了与实现该 Babel 插件相关的整个流程:
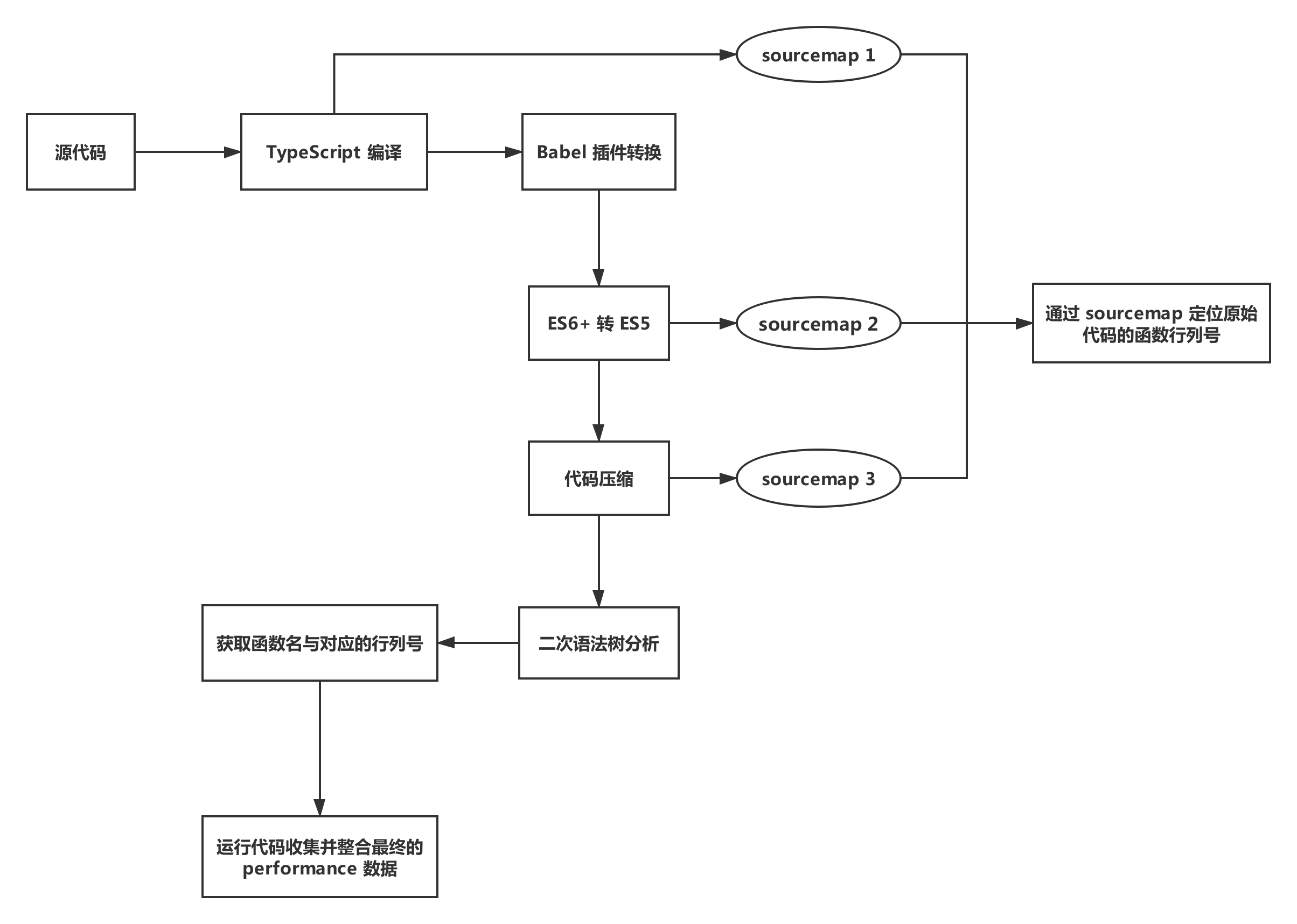
可以看到想要实现整个功能其实是有以下几个难点的:
- 如何定义相关的数据格式使得最终收集到的函数数据正确。
- 如何插入打点代码,对于异步函数 ( async / await 、generator ) 又该怎样处理。
- 原始代码在经过一系列的转换后,每一步都会生成相应的 sourcemap ,如何根据最终文件生成的 sourcemap 找到原始代码并进行调试。
- 如何减少 Babel 对 AST 的遍历以及操作次数,从而减少 Babel 插件的运行时间。
在开始讲解该 Babel 插件的实现之前,请读者确保已经对 Babel 下的 AST 规范十分熟悉,并且已经通读过 Babel Plugin Handbook 。完成这两个步骤后,就让我们来直接看代码吧。
module.exports = ({ types: t }) => {
return {
visitor: {
Function(path) {
if (isEmptyFunction(path) || isTraversalFunction(path)) {
return
}
var _tid = path.scope.generateUidIdentifier('tid')
var uid = getUid()
// 以查询取代变量
var query = { t, uid, _tid }
isAsyncFunction(path) ? asyncTransform(path, query) : syncTransform(path, query)
path.traverse(returnStatementVisitor, { path, query })
}
}
}
}
从上面的代码不难看出,编写 Babel 插件的入口其实就是一个返回访问者对象的函数,该函数为我们提供了 @babel/types 中的 types 对象,这对操纵 AST 十分有用。通过访问器模式和迭代器模式,Babel 能够遍历每个特定类型的 AST 节点以及相应的路径,开发者只需在 Babel 暴露的函数中编写操纵特定 AST 节点的代码即可。
因此,这段代码的大概意思就是每当遇到一个函数,首先判断这个函数是否为空或者是像 map 、forEach 、reduce 这样的遍历函数,如果满足以上条件就直接跳过,不插入打点代码。然后我们会创建 _tid 变量(后文会讲到)以及 uid 作为该函数的唯一标识符。之后我们会判断该函数是同步函数还是异步函数,进而执行不同的转换 ( transform ) 操作。最后就是处理函数中特有的 return 语句,在这里我们通过 returnStatementVisitor 来访问该函数下的所有 return 语句,但只会对相同函数作用域下的 return 语句进行转换操作。
在深入讲解函数的转换操作之前,我们先来看看插入的打点代码是如何实现的:
var data = {}
var time = {
start(uid) {
var startTime = performance.now()
data[startTime] = { uid, startTime }
return startTime
},
end(uid, tid) {
if (data[tid]) {
var endTime = performance.now()
data[tid] = { ...data[tid], endTime }
}
}
}
可以看到,我们以时间戳作为整个数据对象的 key ,每当调用 time.start() 就会记录当前函数开始执行的时间点,之后我们将这个时间戳返回,并在函数内部新建一个变量来接收它,在函数执行结束时我们会调用 time.end() ,此时再将该变量传回对象内部,这样就能通过 startTime 这个 key 将结束时的时间戳放到正确的位置。值得注意的是,由于一般时间戳的精度不足以计算同步函数执行的时间差,所以我们使用的是精确到毫秒的 performance.now() Web API 。打点函数中的 uid 指的是原始代码中每个函数的唯一标识符,它是在 Babel 遍历每个有效函数时由我们生成的,在上文代码中也有提到。
接下来就让我们开始讲解函数的转换操作,对于普通函数,我们会对 AST 进行如下转换:
function syncTransform(path, query) {
path.get('body').unshiftContainer('body', startExpression(query))
if (!hasReturnStatement(path)) {
path.get('body').pushContainer('body', endExpression(query))
}
}
不难理解,这段代码会在同步函数的头部插入开始计时的打点函数,如果函数中没有 return 语句,则会在函数结尾插入结束计时的打点函数。
然后让我们来看看该如何处理异步函数:
function asyncTransform(path, query) {
path.get('body').unshiftContainer('body', startExpression(query))
if (path.node.async) {
path.traverse(awaitExpressionVisitor, { path, query })
}
if (path.node.generator) {
path.traverse(yieldExpressionVisitor, { path, query })
}
if (!hasReturnStatement(path)) {
path.get('body').pushContainer('body', endExpression(query))
}
}
可以看到,它和同步函数的处理方式其实是差不多的,只不过多了两处判断语句。如果函数为 async 类型则会通过 awaitExpressionVisitor 访问该函数下的 await 表达式并对其进行转换,awaitExpressionVisitor 的实现如下:
function isInjectedBefore(path) {
return (path.node.start === undefined || path.node.end === undefined)
}
function isUnmatchedContext(path, funcPath) {
return path.getFunctionParent().node !== funcPath.node
}
function shouldVisit(path, funcPath) {
return !(isInjectedBefore(path) || isUnmatchedContext(path, funcPath))
}
var awaitExpressionVisitor = {
AwaitExpression(path) {
if (shouldVisit(path, this.path)) {
awaitExpressionTransform(path, this.path, this.query)
}
}
}
在这里我们限制了 await 表达式能够进行转换的条件,只有当该表达式之前没有被转换过并且与函数位于同一作用域时,才能进行转换。那什么叫同一作用域呢?我们来举个例子:
async function foo() {
async function bar() {
await baz()
}
await baz()
}
Babel 在遍历 AST 时其实是以深度优先的,因此在访问 foo 函数中的 await 表达式时,会首先遍历到 bar 函数中的 await 表达式,如果此时对它进行转换其实是不符合我们的预期的,因为我们的打点代码只应该计算当前函数的执行耗时,所以对于这种情况我们会直接返回。
在找到正确的 await 表达式后,我们该如何插入打点代码来获得正确的函数耗时数据呢?我们知道在 async 函数中,当遇到 await 表达式时会立刻暂停当前函数的执行,然后去执行 await 表达式后面紧跟的函数,而恢复函数执行的条件则是等待 await 表达式后面的函数执行完毕或者返回的 Promise 决议完成。从这里我们也可以看出,在 async 函数遇到 await 表达式停止执行到恢复执行的时间段并不属于当前函数的耗时。因此我们的打点代码其实可以这样插入:
async function foo() {
var _tid5
var _tid4
var _tid3 = time.start("3")
console.log(2333)
(await (time.end("3", _tid3), bar()), _tid4 = time.start("3"))
console.log(2333)
(await (time.end("3", _tid4), bar()), _tid5 = time.start("3"))
time.end("3", _tid5)
}
从上面的代码可以看出在 await 表达式后面的函数执行之前,我们会先结束前一段同步代码的计时,并在函数恢复执行之后开始下一段同步代码的计时,在这里我们巧妙地运用了 JavaScript 中的逗号操作符来实现该功能。对于 generator 函数,其实它和 async 函数的处理方式是一样的,只需要在函数中访问正确的 yield 表达式并进行转换即可。
下面是对两种异步函数转换的代码:
function asyncExpressionTransform(path, funcPath, query, expression) {
var _tid2 = funcPath.scope.generateUidIdentifier('tid')
query['_tid2'] = _tid2
funcPath.get('body').unshiftContainer('body', variableExpression(query))
path.replaceWith(expression(path, query))
query['_tid'] = _tid2
}
function yieldExpressionTransform(path, funcPath, query) {
asyncExpressionTransform(path, funcPath, query, yieldExpression)
}
function awaitExpressionTransform(path, funcPath, query) {
asyncExpressionTransform(path, funcPath, query, awaitExpression)
}
接下来让我们看看该如何对 return 语句进行转换:
var returnStatementVisitor = {
ReturnStatement(path) {
if (shouldVisit(path, this.path)) {
returnStatementTransform(path, this.query)
}
}
}
function returnStatementTransform(path, query) {
var { t } = query
var end = endExpression(query)
var return_uid = path.scope.generateUidIdentifier('uid')
var returnVar = t.variableDeclaration('var', [t.variableDeclarator(return_uid, path.node.argument)])
var _return = t.returnStatement(return_uid)
if (path.parentPath.type === 'BlockStatement') {
path.insertBefore(returnVar)
path.insertBefore(end)
path.insertBefore(_return)
path.remove()
}
}
这里的转换十分简单,最终的效果大致是这个样子:
// 转换前
function foo() {
console.log(2333)
return 'xxx'
}
// 转换后
function foo() {
var _tid = time.start("1")
console.log(2333)
var _uid = 'xxx'
time.end("1", _tid)
return _uid
}
到此为止,整个 Babel 插件的主要实现差不多就讲完了,现在让我们把关注点转移到实现函数的性能分析工具上。只收集函数的耗时是远远不够的,我们还需要收集函数名以及函数对应的行列号,因为只要转换后的代码带有 sourcemap ,结合 chrome 的 performance 面板,其实是可以通过函数行列号直接定位到原始代码对应函数的位置的。但通常我们的 sourcemap 只能映射到上一次转换前的代码,而我们的代码往往会经过编译、ES6+ 转 ES5、压缩等一系列步骤,每一步都会生成不同的 sourcemap ,那我们该如何通过最终文件的 sourcemap 找到原始代码并进行调试呢?其实社区中已经有大神写出了这样的库,它的名字叫做 sorcery ,翻译过来就是魔法的意思,下面是这个库的简介:
Resolve a chain of sourcemaps back to the original source, like magic.
这个库的作者是 Rich-Harris ,他同时也是 Rollup.js 和 Svelte.js 的作者,确实是大神级别的人物。
通过 sorcery.js 我们可以 flatten 多个 sourcemap 并最终生成能够直接映射到原始代码的 sourcemap ,这为我们调试代码提供了极大的帮助。之后我们通过 @babel/traverse 对压缩后的最终文件进行二次语法树分析,此时收集到的函数名与函数行列号,在有了正确的 sourcemap 后便显得尤为重要。下面是进行二次语法树分析的代码实现:
var ast = parser.parse(code)
function isStartExpression(path) {
var result = path.node.object.name === 'time' &&
path.node.property.name === 'start' && path.parentPath.node.type === 'CallExpression'
return result
}
function getFunctionInfo(path) {
var funcPath = path.getFunctionParent()
var parentNode = funcPath.parentPath.node
var info = {}
function generateInfo(name, location) {
info = { name, location }
}
if (parentNode.type === 'AssignmentExpression') {
generateInfo(parentNode.left.property.name, parentNode.left.property.loc.start)
} else if (parentNode.type === 'VariableDeclarator') {
generateInfo(parentNode.id.name, parentNode.id.loc.start)
} else {
funcPath.node.id
? generateInfo(funcPath.node.id.name, funcPath.node.id.loc.start)
: generateInfo('anonymous', funcPath.node.loc.start)
}
return info
}
var data = {}
// 对代码进行二次语法树分析,收集函数名以及对应的行列号。
traverse(ast, {
MemberExpression(path) {
if (isStartExpression(path)) {
var uid = path.parentPath.node.arguments[0].value
data[uid] = getFunctionInfo(path)
}
}
})
最后让我们来看看在编写 Babel 插件时该如何避免不必要的遍历以及对 AST 的操作,进而减少插件的运行时间。
在遍历 AST 时,对于不满足要求的节点应该直接返回,这样既防止了我们生成错误代码也在一定程度上缩短了遍历时间。
// 正确
if (shouldVisit(path, this.path)) {
returnStatementTransform(path, this.query)
}
// 正确
if (isEmptyFunction(path) || isTraversalFunction(path)) {
return
}
应尽量避免遍历 AST,及时合并访问者对象。
// 错误
path.traverse({
Identifier(path) {
// ...
}
})
path.traverse({
BinaryExpression(path) {
// ...
}
})
// 正确
path.traverse({
Identifier(path) {
// ...
},
BinaryExpression(path) {
// ...
}
})
使用单例,优化嵌套的访问者对象。
// 错误
path.traverse({
ReturnStatement(path) {
if (shouldVisit(path, this.path)) {
returnStatementTransform(path, this.query)
}
}
}, { path, query })
// 正确
var returnStatementVisitor = {
ReturnStatement(path) {
if (shouldVisit(path, this.path)) {
returnStatementTransform(path, this.query)
}
}
}
path.traverse(returnStatementVisitor, { path, query })
结语
本文到此也就接近尾声了,与文章相关的代码全都在这个仓库,有兴趣的朋友可以翻阅下。文中如有错误,请读者指出,作者会立即改正。在最后结束时想要感谢 2019 年暑假在腾讯实习时的导师,正是他给作者布置的课题才有了现在这篇文章,当然期间也受到了许多帮助,故在此表达谢意。
参考内容
