

[TOC]
一、Zookeeper简介
ZooKeeper致力于提供一个高性能、高可用,且具备严格的顺序访问控制能力的分布式协调服务,是雅虎公司创建,是Google的Chubby一个开源的实现,也是Hadoop和Hbase的重要组件.

设计目标:
- 简单的数据结构:共享的树形结构,类似文件系统,存储于内存
- 可以构建集群:避免单点故障,3-5台机器就可以组成集群,超过半数正常工作就能对外提供服务;
- 顺序访问:对于每个读请求,zk会分配一个全局唯一的递增编号,利用这个特性可以实现高级协调服务
- 高性能:基于内存操作,服务于非事务请求,适用于读操作为主的业务场景。3台zk集群能达到13w QPS
二、分布式系统协调“方法论”
1.CAP理论
- C 一致性:数据在分布式环境下的多个副本之间能否保持一致性,这里的一致性更多是指强一致性;
- A 可用性:分布式系统一直处于可用状态,对于请求总是能在有限的时间 内返回结果致性;
- P 分区容错性:除非整个网络故障,分布式系统在任何网络或者单点故障时,仍能对外提供满足一致性和可用性的服务;
CAP理论:一个分布式系统不可能同时满足一致性、可用性和分区容错性这三个 基本需求,最多只能同时满足其中的两项;

TIPS:架构师的精力往往就花在怎么样根据业务场景在A和C直接寻求平衡;
2.BASE理论
- Basically Avaliable 基本可用:当分布式系统出现不可预见的故障时,允许损失部分可用性,保障系统的“基本可用”;体现在“时间上的损失”和“功能上的损失”;e.g:部分用户双十一高峰期淘宝页面卡顿或 降级处理;
- Soft state 软状态:允许系统中的数据存在中间状态,既系统的不同节点的数据副本之间的数据同步过程存在延时,并认为这种延时不会影响系统可用性;e.g:12306网站卖火车票,请求会进入排队队列;
- Eventually consistent 最终一致性:所有的数据在经过一段时间的数据同步后,最终能够达到一个一致的状态;e.g:理财产品首页充值总金额 短时不一致;
BASE理论:即使无法做到强一致性,但分布式系统可以根据自己的业务特点,采 用适当的方式来使系统达到最终的一致性;
三、分布式环境协调通信应用场景
Zookeeper常应用以下场景:
- 数据发布订阅
- 负载均衡
- 命名服务
- Master选举
- 集群管理
- 配置管理
- 分布式队列
- 分布式锁
四、Zookeeper配置文件详解
| 序号 | 参数名 | 说明 |
|---|---|---|
| 1 | clientPort | 客户端连接server的端口,即对外服务端口,一般设置为2181 |
| 2 | dataDir | 存储快照文件snapshot的目录。默认情况下,事务日志也会存储在这里。建议同时配置参数dataLogDir, 事务日志的写性能直接影响zk性能。 |
| 3 | tickTime | ZK中的一个时间单元。ZK中所有时间都是以这个时间单元为基础,进行整数倍配置的。例如,session的最小超时时间是2*tickTime |
| 4 | dataLogDir | 事务日志输出目录。尽量给事务日志的输出配置单独的磁盘或是挂载点,这将极大的提升ZK性能 |
| 5 | globalOutstandingLimit | 最大请求堆积数。默认是1000。ZK运行的时候, 尽管server已经 没有空闲来处理更多的客户端请求了,但是还是允许客户端将请求提交到服务器上来,以提高吞吐性能。当然,为了防止Server内存 溢出,这个请求堆积数还是需要限制下的。(Java system property: zookeeper.globalOutstandingLimit.) |
| 6 | preAllocSize | 预先开辟磁盘空间,用于后续写入事务日志。默认是64M,每个事务日志大小就是64M。如果ZK的快照频率较大的话,建议适当减小 这个参数。(Java system property: zookeeper.preAllocSize) |
| 7 | snapCount | 每进行snapCount次事务日志输出后,触发一次快照(snapshot),此时,ZK会生成一个snapshot.文件,同时创建一个新的事务日志文件log.。 默认是100000.(真正的代码实现中,会进行一定的随机数处理,以避 免 所 有 服 务 器 在 同 一 时 间 进 行 快 照 而 影 响 性 能 )(Java system property: zookeeper.snapCount) |
| 8 | traceFile | 用于记录所有请求的log,一般调试过程中可以使用,但是生产环境不建 议使用,会严重影响性能。(Java system property:? requestTraceFile) |
| 9 | maxClientCnxns | 单个客户端与单台服务器之间的连接数的限制,是ip级别的,默认是60如果设置为0,那么表明不作任何限制。请注意这个限制的使用范围,仅仅是单台客户端机器与单台ZK服务器之间的连接数限制,不是针对指定客户端IP,也不是ZK集群的连接数限制,也不是单台ZK对所有客户端的 连接数限制。 |
| 10 | clientPortAddress | 对于多网卡的机器,可以为每个IP指定不同的监听端口。默认情况是所 有IP都监听 clientPort指定的端口。 New in 3.3.0 |
| 11 | minSessionTimeou tmaxSessionTimeout | Session超时时间限制,如果客户端设置的超时时间不在这个范围,那么会被强制设置为最大或最小时间。默认的Session超时时间是在2* tickTime ~ 20 * tickTime 这 个 范 围 New in 3.3.0 |
| 12 | fsync.warningthresholdms | 事务日志输出时,如果调用fsync方法超过指定的超时时间,那么会在日志中输出警告信息,默认是1000ms |
| 13 | autopurge.purgeInterval | 清理任务的时间间隔,单位为hours |
| 14 | autopurge.snapRetainCount | zkserver启动时会开启一个org.apache.zookeeper.server.DatadirCleanupManager的线程,用于清理"过期"的snapshot文件和其相应的txn log file,此参数用于设定需要被retain保留的文件个数(从QuorumPeerMain跟踪代码) |
| 15 | electionAlg | 选举算法,默认为3,可以选择(0,1,2,3), 0表示使用原生的UDP(LeaderElection), 1表示使用费授权的UDP 2表示使用授权的UDP(AuthFastLeaderElection) 3基于TCP的快速选举(FastLeaderElection) |
| 16 | initLimit | Leader与learner建立连接中 socket通讯read所阻塞的时间(initLimit * tickTime) 如果是Leaner数量较多或者leader的数量很大, 可以增加此值 |
| 17 | SyncLimit | learner与leader建立连接中,socket通讯read阻塞的时间.其中包括数据同步/数据提交等 |
| 18 | peerType | zkserver 类型 observer 观察者, participant参与者 ,默认为参与者 |
| 19 | leaderServes | 系统属性 zookeeper.leaderServes leader是否接受client请求,默认为yes即leader可以接受client的连接,在zk cluster 环境中,当节点数为>3时,建议关闭 |
| 20 | cnxTimeout | 系统属性:zookeeper.cnxTimeout leader选举时socket连接打开的时长,只有在electionAlg=3有效 |
| 21 | skipACL | 系统属性:zookeeper.skipACL 默认为no,是否跳过ACL检查 |
| 22 | forceSync | 系统属性:zookeeper.forceSync 默认yes 在update执行之前,是否强制对操作立即持久写入txn log文件.关闭此选项,会造成服务器失效后,尚未持久化的数据丢失 |
| 23 | jute.maxbuffer | 每个节点最大数据量,是默认是1M。这个限制必须在server和client 端都进行设置才会生效。 |
五、Zookeeper特性
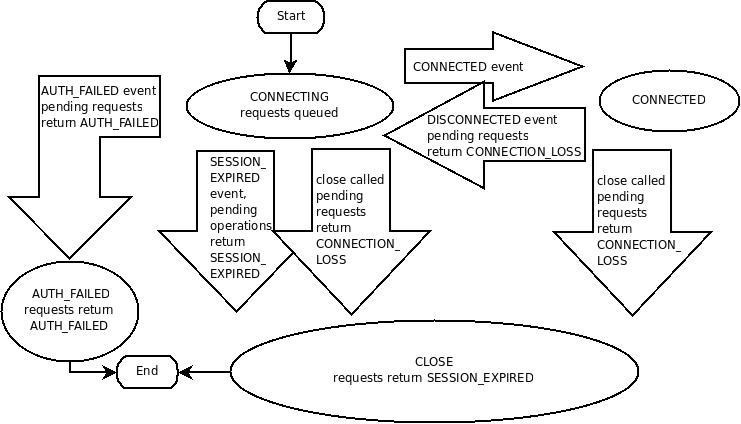
1.会话(Session)
客户端与服务端的一次会话连接,本质是TCP长连接,通过会话可以进行心跳检测和数据传输;
2.数据节点(znode)
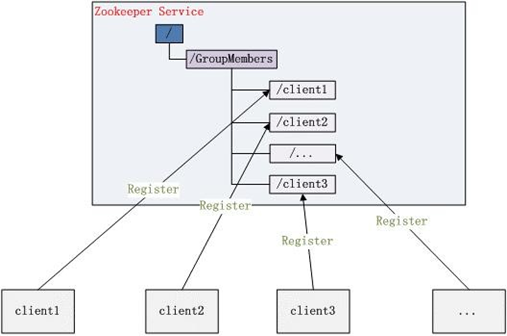
ZooKeeper的视图结构和标准的Unix文件系统类似,其中每个节点称为“数据节点”或ZNode,每个znode可以存储数据,还可以挂载子节点,因此可以称之为“树”
特性:
- 在Zookeeper中,znode是一个跟Unix文件系统路径相似的节点,可以往这个节点存储或获取数据。
- 通过客户端可对znode进行增删改 查的操作,还可以注册watcher监 控znode的变化。
Zookeeper节点类型
- 持久节点(Persistent)
- 持久顺序节点(Persistent_Sequential)
- 临时节点(Ephemeral)
- 临时顺序节点(Ephemeral_Sequential)
对于持久接地啊和临时节点,同一个Znode下,节点的名称是唯一的 -实现分布式锁的基础
Zookeeper节点状态属性
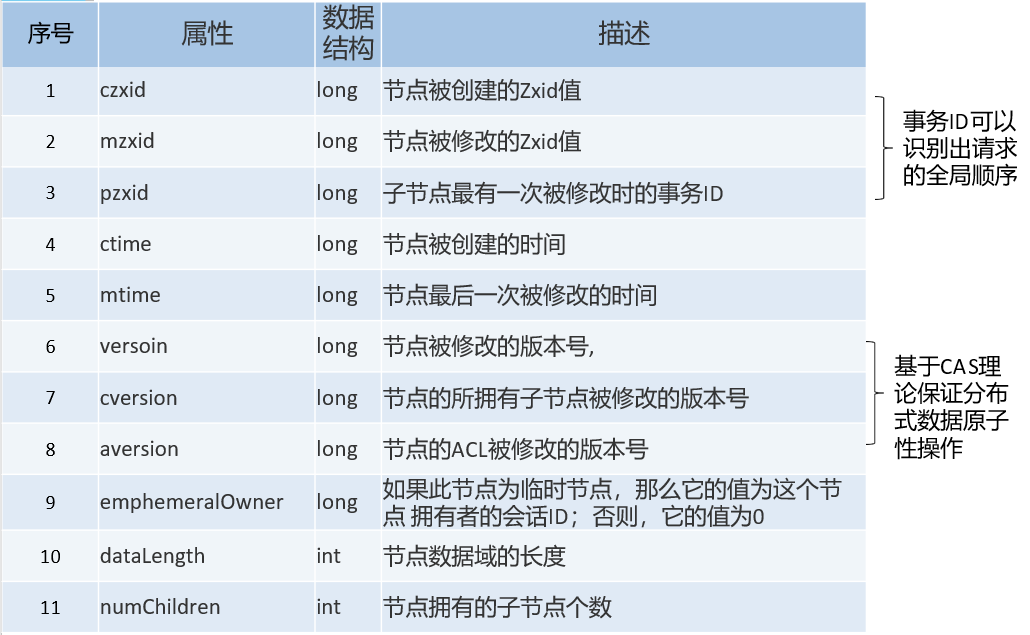
3.版本
4.Watcher
事件监听器,客户端可以在节点上注册监听器,当特定的事件发生后,zk会通知到感兴趣的客户 端;eventType: NodeCreated、NodeDeleted、NodeDataChanged、NodeChildrenChange
5.ACL
Zk采用ACL(access control lists)策略来控制权限,5种权限:create、read,write,delete,admin。
ACL机制,表示为scheme:id:permissions,第一个字段表示采用哪一种机制,第二个id表示用户,permissions表示相关权限(如只读,读写,管理等)。zookeeper提供了如下几种机制( scheme):
-
world: 它下面只有一个id, 叫anyone, world:anyone代表任何人,zookeeper中对所有人有权限的结点就是属于world:anyone的
-
auth: 它不需要id, 只要是通过authentication的user都有权限(zookeeper支持通过kerberos来进行authencation, 也支持username/password形式的authentication)
-
digest: 它对应的id为username:BASE64(SHA1(password)),它需要先通过username:password形式的authentication
-
ip: 它对应的id为客户机的IP地址,设置的时候可以设置一个ip段,比如ip:192.168.1. 0/16, 表示匹配前16个bit的IP段
-
super: 在这种scheme情况下,对应的id拥有超级权限,可以做任何事情(cdrwa)
6.集群角色
六、常用客户端命令
1.服务端常用命令
在准备好相应的配置之后可以直接通过zkServer.sh 这个脚本进行服务的相关操作:
- 启动ZK服务: sh bin/zkServer.sh start
- 查看ZK服务状态: sh bin/zkServer.sh status
- 停止Zk服务: sh bin/zkServer.sh stop
- 重启ZK服务: sh bin/zkServer.sh restart
2.客户端常用命令
使用zkCli.sh -server 127.0.0.1:2181 连接到Zookeeper服务
- 显示根目录下文件、文件
ls/
- 显示根目录下、文件
ls2 /
查看当前节点数据并能看到更新次数等数据
- 创建文件并设置初始内容
create /zk "test"
创建一个新的znode节点“zk" 以及与它关联的字符串
- 获取文件
get /zk
确认znode是否包含创建的字符串
- 修改文件内容
set /zk "zkbak"
对zk所关联的字符串进行设置和修改
- 删除文件
delete /zk
将创建的znode节点进行删除,如果存在子节点则删除会失败
- 递归删除
rmr /zk
将刚才创建的znode删除,同时删除子节点
- 退出客户端
quit
- 帮助命令
help
七、ACL 常用命令
1. getAcl
获取指定节点的ACL信息
2.setACL
设置指定节点的ACL信息
3.addauth
注册会话授权信息
八、Zookeeper常用命令
- 查看哪个节点被选择作为follower或者leader
echo stat|nc 127.0.0.1 2181
- 测试是否启动了该Server,若回复imok表示已经启动
echo ruok|nc 127.0.0.1 2181
- 列出未经处理的会话和临时节点
echo kill | nc 127.0.0.1 2181
- 输出相关服务配置的详细信息
echo conf | nc 127.0.0.1 2181
- 列出所有连接到服务器的客户端的完全的连接 / 会话的详细信息
echo cons | nc 127.0.0.1 2181
- 输出关于服务环境的详细信息(区别于 conf 命令)
echo envi |nc 127.0.0.1 2181
- 列出未经处理的请求
echo reqs | nc 127.0.0.1 2181
- 列出服务器 watch 的详细信息
echo wchs | nc 127.0.0.1 2181
- 通过 session 列出服务器 watch 的详细信息,它的输出是一个与 watch相关的会话的列表
echo wchc | nc 127.0.0.1 2181
- 通过路径列出服务器 watch 的详细信息。它输出一个与 session 相关的路 径
echo wchp | nc 127.0.0.1 2181
九、Zookeeper 日志可视化
- 事务日志可视化(LogFormatter)
java -cp ../../zookeeper-3.4.6.jar;../../lib/slf4j-api-1.6.1.jar org.apache.zookeeper.server.LogFormatter log.xxxx
- 数据快照可视化( SnapshotFormatter)
java -cp ../../zookeeper-3.4.6.jar;../../lib/slf4j-api-1.6.1.jar org.apache.zookeeper.server.SnapshotFormatter snapshot.xxxx
十、Zookeeper客户端简介
1.Zookeeper 客户端
zookeeper官方提供的java客户端API;
核心API
- 创建会话
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher, long sessionId, byte[] sessionPasswd, boolean canBeReadOnly)
- 创建节点
public String void create(final String path, byte data[], List<ACL> acl, CreateMode createMode, StringCallback cb, Object ctx)
- 读取数据
public List<String> void getChildren(final String path, Watcher watcher, Stat stat, Children2Callback cb, Object ctx)
public List<String> void getData(final String path, Watcher watcher, Stat stat, DataCallback cb, Object ctx)
- 更新数据
public Static void setData(final String path, byte data[], int version, StatCallback cb, Object ctx)
- 检测节点是否存在
public Static void exists(final String path, Watcher watcher, StatCallback cb, Object ctx)
- 权限控制
public void addAuthInfo(String scheme, byte auth[])
- Watch
org.apache.zookeeper.Watcher(KeeperState、EventType)
(1)没有专门的API去注册watcher,依附于增删改查API;
(2)watch是一次性产品
(3)watch的process方法中,可对不同事件进行处理;
原生客户端开发弊端
- 会话的链接是异步的
- 序列化支持不透明
- Watch需要重复注册
- Session 重连机制
- 开发复杂性较高
2.ZkClient
开源的zk客户端,在原生API基础上封装,是一个更易于使用的zookeeper客户端; 引入Maven依赖
<!-- zkclient依赖 -->
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.10</version>
</dependency>
核心API
- 创建会话(同步,重试)
public ZkClient(final String zkServers, final int sessionTimeout,final int connectionTimeout, final ZkSerializer zkSerializer, final long operationRetryTimeout)
- 创建节点(同步、递归创建)
String create(final String path, Object data, final CreateMode mode)
public void createPersistent(String path,boolean createParents,List<ACL> acl)
public void createPersistent(String path, Object data, List<ACL> acl)
public String createPersistentSequential(String path,Object data,List<ACL> acl)
public String createPersistentSequential(String path,Object data,List<ACL> acl
public String createEphemeralSequential(String path,Object data,List<ACL> acl)
- 删除节点(同步,递归调用)
public boolean delete(String path,int version)
public boolean deleteRecursive(String path)
- 获取节点(同步,避免不存在异常)
public List<String> getChildren(String path)
public <T> T readData(String path, boolean returnNullIfPathNotExists)
public <T> T readData(String path, Stat stat)
- 更新节点(同步、实现CAS、状态返回)
public void writeData(String path, Object datat, int expectedVersion)
public Stat writeDataReturnStat(String path,Object datat,int expectedVersion)
- 检测节点存在(同步)
public boolean exists(String path)
- 权限控制(同步)
public void addAuthInfo(String scheme, final byte[] auth);
public void setAcl(final String path, final List<ACL> acl);
- 监听器

3.Cuator
开源的zk客户端,在原生API基础上封装,apache顶级项目;
- Curator采用Fluent风格API
<!-- curator依赖 -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>
序列化支持不好
Curator 核心API
- 创建会话(同步、重试)
CuratorFrameworkFactory.newClient(String connectString, int sessionTimeoutM int connectionTimeoutMs, RetryPolicy retryPolicy)
CuratorFrameworkFactory.builder().connectString("192.168.11.56:2180")
.sessionTimeoutMs(30000).connectionTimeoutMs(30000)
.canBeReadOnly(false)
.retryPolicy(new ExponentialBackoffRetry(1000, Integer.MAX_VALUE))
.build();
retryPolicy 连接策略:
RetryOneTime: 只重连一次.
RetryNTime: 指定重连的次数N.
RetryUtilElapsed: 指定最大重连超时时间和重连时间间隔,间歇性重连直到超时或者链接成功.
ExponentialBackoffRetry: 基于"backoff"方式重连,和RetryUtilElapsed的区别是重连的时间间隔是动态
BoundedExponentialBackoffRetry: 同ExponentialBackoffRetry,增加了最大重试次数的控制.
- 创建节点
client.create().creatingParentIfNeeded()
.withMode(CreateMode.PERSISTENT)
.withACL(aclList)
.forPath(path, "hello, zk".getBytes());
- 删除节点
client.delete().guaranteed().deletingChildrenIfNeeded()
.withVersion(version).forPath(path)
- 获取节点
client.getData().storingStatIn(stat).forPath(path);
client.getChildren().forPath(path);
- 更新节点
client.setData().withVersion(version).forPath(path, data)
- 判断节点是否存在
client.checkExists().forPath(path);
- 设置权限
Build.authorization(String scheme, byte[] auth)
client.setACL().withVersion(version)
.withACL(ZooDefs.Ids.CREATOR_ALL_ACL)
.forPath(path);
- 监听器(避免重复监听)
Cache是curator中对事件监听的包装,对事件的监听可以近似看做是本地缓存视图和远程zk视图的对比过程
- NodeCache 节点缓存用于处理节点本身的变化 ,回调接口NodeCacheListener
- PathChildrenCache 子节点缓存用于处理节点的子节点变化,回调接口 PathChildrenCacheListener
- TreeCache NodeCache和PathChildrenCache的结合体,回调接口TreeCacheListener
- 事务支持(保证一组操作的原子性)
Collection<CuratorTransactionResult> results = client.transaction().forOperations(operations);
- 异步支持 引入BackgroundCallback接口,用于处理异步接口调用之后服务端返回的结果信息
public void processResult(CuratorFramework client, CuratorEvent event)
CuratorEventType 事件类型
org.apache.zookeeper.KeeperException.Code
