

一、Spark Shell on Client
scala> var rdd =sc.parallelize(1 to 100 ,3)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd.count
res0: Long = 100
scala> val rdd2=rdd.map(_ + 1)
rdd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at map at <console>:26
scala> rdd2.take(3)
res1: Array[Int] = Array(2, 3, 4)
scala> val rdd1=sc.textFile("file://home/hadoop/apps/sparkwc")
rdd1: org.apache.spark.rdd.RDD[String] = file://home/hadoop/apps/sparkwc MapPartitionsRDD[3] at textFile at <console>:24
cala> val rdd1=sc.textFile("file:///home/hadoop/apps/sparkwc")
rdd1: org.apache.spark.rdd.RDD[String] = file:///home/hadoop/apps/sparkwc MapPartitionsRDD[9] at textFile at <console>:24
scala> val rdd2=rdd
rdd rdd1 rdd2 rdd3 rddToDatasetHolder
scala> val rdd2=rdd1.flatMap(_.split("\t"))
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[10] at flatMap at <console>:26
scala> val rdd3=rdd2.map((_,1))
rdd3: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[11] at map at <console>:28
scala> val rdd4=rdd3.reduceByKey(_ + _)
rdd4: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[12] at reduceByKey at <console>:30
scala> rdd4.collect
res2: Array[(String, Int)] = Array((spark,1), (hadoop,1), (hello,3), (world,1))
scala> rdd4.collect
res2: Array[(String, Int)] = Array((spark,1), (hadoop,1), (hello,3), (world,1))
scala> rdd4.saveAsTextFile("file:///home/hadoop/apps/out1")
[hadoop@hadoop01 apps]$ cd out1/
[hadoop@hadoop01 out1]$ ls
part-00000 _SUCCESS
[hadoop@hadoop01 out1]$ cat part-00000
(spark,1)
(hadoop,1)
(hello,3)
(world,1)
[hadoop@hadoop01 out1]$ pwd
/home/hadoop/apps/out1
WebUI 地址:http://192.168.43.20:4040/jobs/
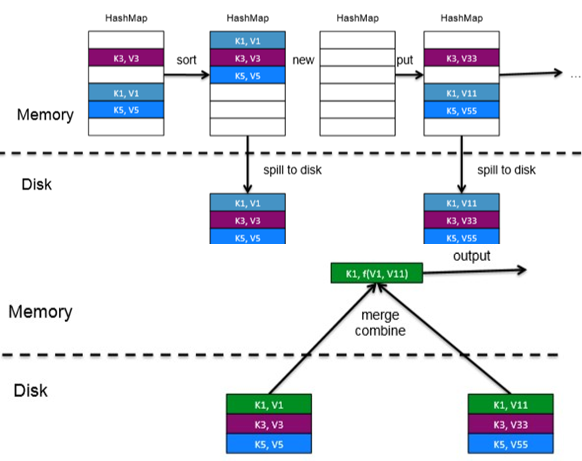
二、Spark Shuffle
- Shuffle Write:将Task中间结果数据写入到本地磁盘
- Shuffle Read:从Shuffle Write阶段拉取数据到内存中并行计算
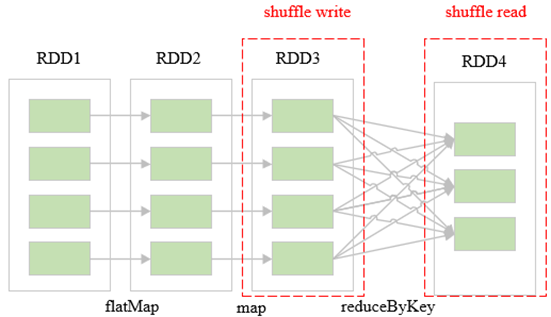
三、Shuffle Write(hash-based)
- Shuffle Write阶段产生的总文件数=MapTaskNum * ReduceTaskNum
- TotalBufferSize=CoreNum * ReducceTaskNum*FileBufferSize
- 产生大量小文件,占用更多的内存缓冲区,造成不必要的内存开销,增加 了磁盘IO和网络开销
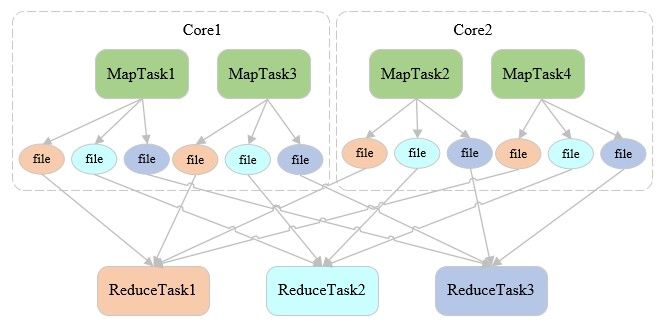
四、Shuffle Write(hash-based优化)
- Shuffle Write阶段产生的总文件数=CoreNum * ReduceTaskNum
- TotalBufferSize=CoreNum * ReducceTaskNum*FileBufferSize 减少了小文件产生的个数,但是占用内存缓冲区的大小没变
- 设置方法
- conf.set("spark.shuffle.manager", "hash")
- 在conf/spark-default.conf 配置文件中添加spark.shuffle.manager=hash
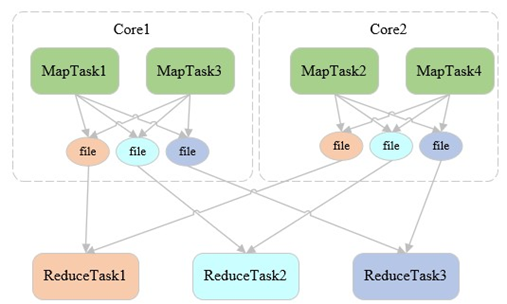
五、Shuffle Write(hash-based优化)Shuffle Write(sort-based)
- Shuffle Write阶段产生的总文件数= MapTaskNum * 2
- 优点: 顺序读写能够大幅提高磁盘IO性能,不会产生过多小文件,降低文件缓存占用内存空间大小,提高内存使用率。
- 缺点:多了一次粗粒度的排序。
- 设置方法
- 代码中设置:conf.set("spark.shuffle.manager", "sort")
- 在conf/spark-default.conf 配置文件中添加spark.shuffle.manager=sort
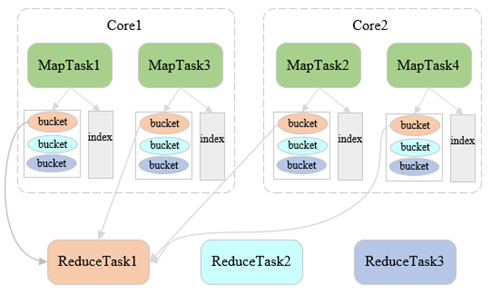
六、Shuffle Read
- hase-based和sort-based使用相同的shuffle read实现
七、Spark History Server配置
- spark history server查看运行完成的作业信息和日志
- 配置Hadoop的yarn-site.xml文件,所有节点配置文件同步,重启yarn
<property>
<name>yarn.log.server.url</name>
<value>http://node02:19888/jobhistory/logs</value>
<description> Yarn JobHistoryServer访问地址 </description>
</property>
- 修改spark安装包conf目录下的spark-defaults.conf(如果没有该文件, 通过spark-defaults.conf.template模板复制一个),spark history server 在192.168.183.100节点启动,spark_logs这个目录需要在HDFS上提前创建
spark.yarn.historyServer.address=192.168.183.100:18080 spark.history.ui.port=18080
spark.eventLog.enabled=true spark.eventLog.dir=hdfs:///spark_logs
spark.history.fs.logDirectory=hdfs:///spark_logs
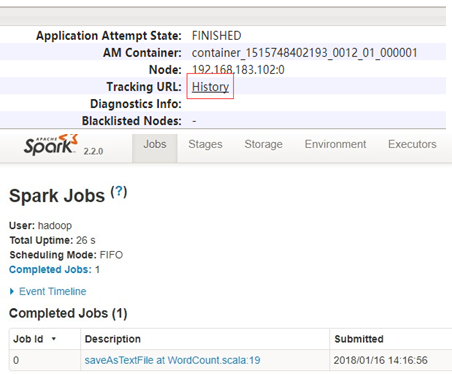
1.Spark History Server启动
- 启动Spark History Server
sbin/start-history-server.sh
- Spark History Server访问地址
httpL://192.168.183.100:18080
七、Spark运行环境优化
- 将spark系统jar包上传到HDFS上,直接使用HDFS上的文件
- 在spark安装目录下运行:jar cv0f spark-libs.jar -C jars/ .
- 将spark安装目录下生成的spark-libs.jar上传到HDFS上的 /system/spark(需要手动创建)目录下
hadoop fs -put spark-libs.jar /system/spark
修改spark安装包conf目录下spark-defaults.conf配置文件添加spark- libs.jar在HDFS上的路径
spark.yarn.archive=hdfs:///system/spark/spark-libs.jar
八、Spark编程模型
- 创建SparkContext
- 封装了spark执行环境信息
- 创建RDD
- 可以用scala集合或hadoop数据文件创建
- 在RDD上进行transformation和action
- spark提供了丰富的transformation和action算子
- 返回结果
- 保存到hdfs、其他外部存储、直接打印
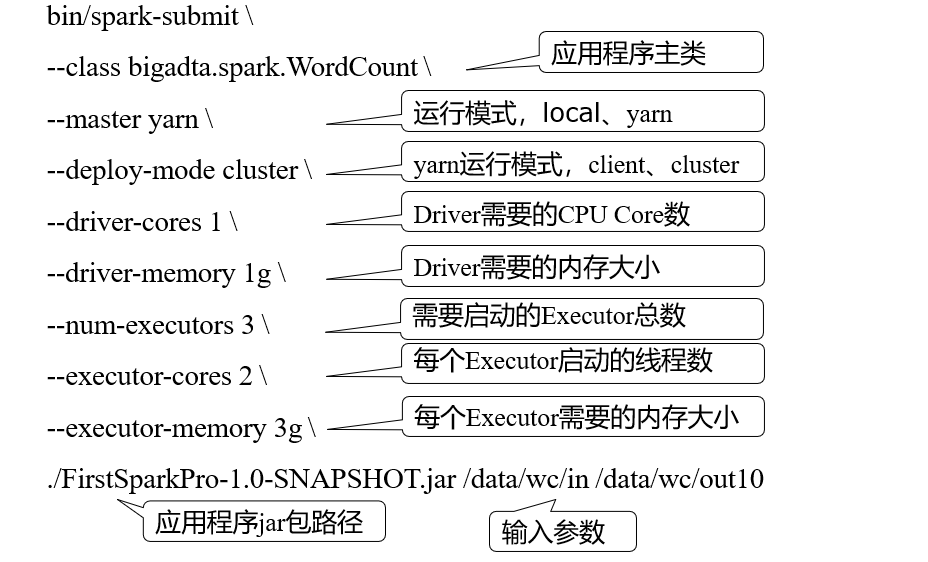
1.提交Spark程序到Yarn上
2.Spark RDD算子分类
- Transformation转换操作,惰性执行,不触发app执行
- 针对Value数据类型,如map、filter
- 针对Key-Value数据类型,如groupByKey、reduceByKey
- Action执行操作,触发app执行
3.创建RDD
- parallelize从集合创建RDD
- 参数1:Seq集合,必须
- 参数2:分区数
- 创建RDD:val rdd = sc. parallelize(List(1,2,3,4,5,6,7),3)
- 查看RDD分区数:rdd.partitions.size
- textFile从外部数据源(本地文件或者HDFS数据集)创建RDD
- 参数1:外部数据源路径,必须
- 参数2:最小分区数
- 从本地文件创建RDD:val rdd = sc.textFile("file:///home/hadoop/apps/in")
- 从HDFS数据集创建RDD:val rdd = sc.textFile("hdfs:///data/wc/in",1)
4.Value数据类型Transformation
- map
- 输入是一个RDD,将一个RDD中的每个数据项,通过map中的函数映射输出一个新的RDD,输入分区与输出分区一一对应
- flatMap
- 与map算子功能类似,可以将嵌套类型数据拆开展平
- distinct
- 对RDD元素进行去重
- coalesce
- 对RDD进行重分区
- 第一个参数为重分区的数目
- 第二个为是否进行shuffle,默认为false,如果重分区之后分区数目大于 原RDD的分区数,则必须设置为true
- repartition
- 对RDD进行重分区, 等价于coalesce第二个参数设置为true
- union
- 将两个RDD进行合并,不去重
- mapPartitions
- 针对RDD的每个分区进行操作,接收一个能够处理迭代器的函数作为参数
- 如果RDD处理的过程中,需要频繁的创建额外对象,使用mapPartitions要比使用map的性能高很多,如:创建数据库连接
- mapPartitionsWithIndex
- 与mapPartitions功能类似,接收一个第一个参数是分区索引,第二个参数是分区迭代器的函数
- zip
- 拉链操作,将两个RDD组合成Key-Value形式的RDD,保证两个RDD的partition数量和元素个数要相同,否则会抛出异常
- mapValues
- 针对[K,V]中的V值进行map操作
- groupByKdy
- 将RDD[K,V]中每个K对应的V值,合并到一个集合Iterable[V]中
- reduceByKey
- 将RDD[K,V]中每个K对应的V值根据传入的映射函数计算
- join -返回两个RDD根据K可以关联上的结果,join只能用于两个RDD之间的关联,如果要多个RDD关联,需要关联多次
5.RDD Action
- collect
- 将一个RDD转换成数组,常用于调试
- saveAsTextFile
- 用于将RDD以文本文件的格式存储到文件系统中
- take
- 根据传入参数返回RDD的指定个数元素
- count
- 返回RDD中元素数量
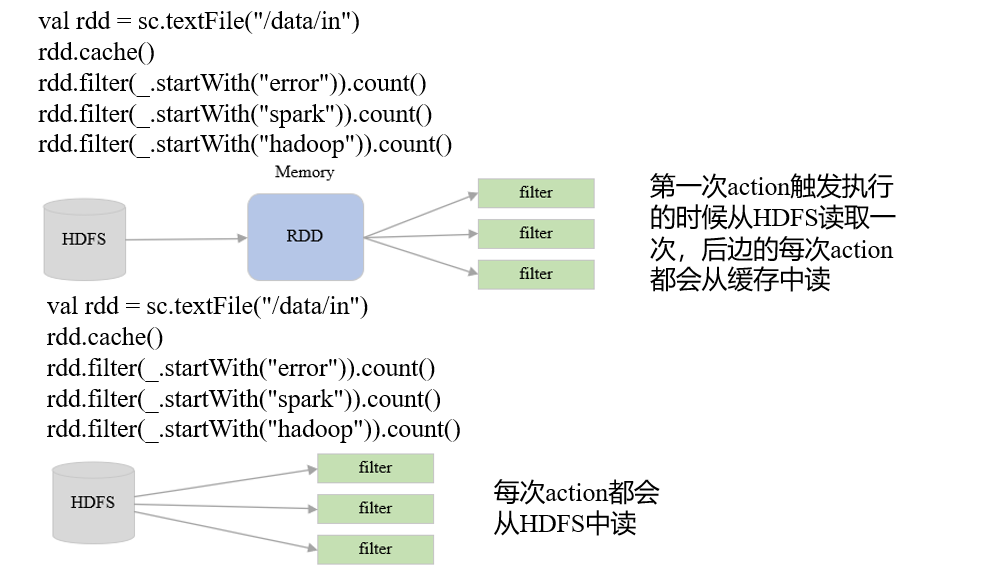
6.Spark优化-Cache应用
7.Accumulator计数器
- accumulator累加器,计数器
- accumulator累加器,计数器
- 通常用于监控,调试,记录关键数据处理的数目等
- 分布式计数器,在Driver端汇总
val total_counter = sc.accumulator(0L,"total_counter")
val resultRdd = rowRdd.flatMap(_.split("\t")).map(x=>{ total_counter += 1
(x,1)
}).reduceByKey(_ + _)
通过Spark Web UI查看

