

前言
一两年前由于工作需要重点研究过自然语言处理与人机对话系统,本文将会列出的它们的知识点以及自己的思考。
nlp与人机对话
对于普通企业,人机对话目前主要的应用是任务型人机对话系统。不管是nlp亦或是chatbot,学术上和工程上都有不同的实现手段。学术界上人机对话系统的研究成果以及最新的研究趋势在工程上应用的较少,而工程上又有自己的方式来实现人机对话。人机对话在实现过程中会使用很多nlp技术,所以可以说nlp是chatbot的基础。
涉及nlp
词:语法、语义、语用。
短语(句子):语法、语义、语用。
篇章:语法、语义、语用。
词和短语的研究已经比较成熟了,主要的研究集中在2000年后。篇章的研究不成熟,主要研究是在2010年以后。
语法树:
DG
CFG
PCFG
LPCFG
常用算法:
搜索S
动态规划D
分类算法C
序列标注S
优化算法O
人机对话主流框架
NLU:理解用户输入,将自然语言转换成结构化表示。
DM:系统决策。
NLG:自然语言生成,将结构化表示转换成自然语言。

所以根据主流框架分成了三个主要模块,分别为NLU、DM和NLG。
自然语言理解
自然语言理解包括三块:
领域识别,主要就是判断任务种类,比如会议室预定、火车票购买、订餐等等类别。
意图识别,识别用于意图,比如用户确定、拒绝。
槽填充,抽取任务相关的重要信息,比如会议预定,槽就可以定义为开会地点、开会时间。
用户输入“我明天在公司开会”,经过自然语言理解处理(句子分类、序列标注)后结果为,
Domain:会议室预定Intent:提供信息Slots:{Time:明天;Location:公司}自然语言理解研究现状:
基于规则的方法,正则表达,比较耗人力、灵活性差、可移植性差。
基于统计的方法,单独建模和联合建模。单独建模将领域识别、意图识别、槽填充分开研究,分别使用支持向量机、卷积神经网络、决策树、条件随机场、循环神经网络实现,存在误差累积。
研发步骤:
根据任务需求定义标签。
准备数据,如果用基于规则的方法则要观察数据规律,提取模板。如果使用基于统计方法则要标注数据,分为训练集、验证集、测试集。一般数据量要几十万。
写正则表达式或建立模型训练模型。
完成NLU研发。
迭代优化。
对话管理
对话管理模块主要框架如下图,
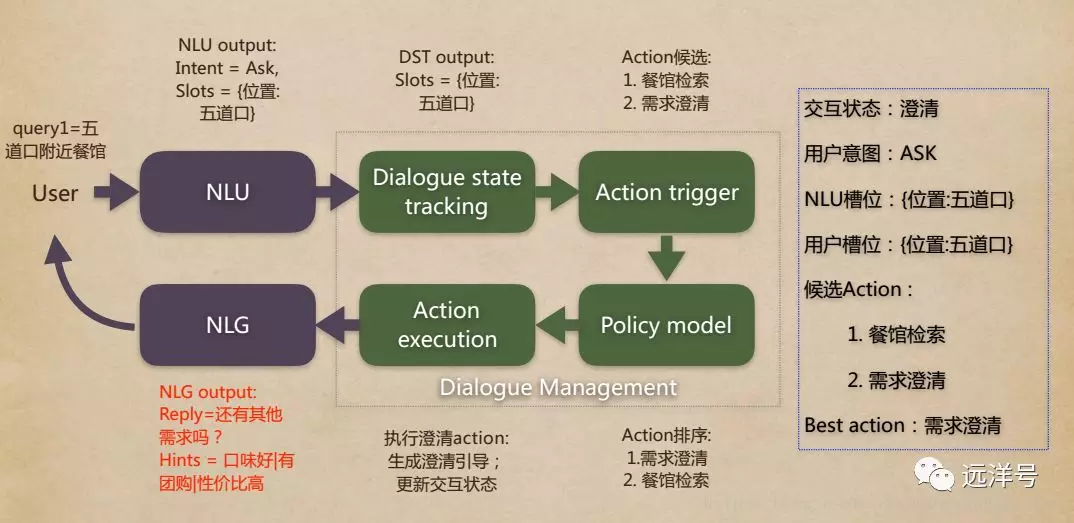
用户输入“五道口附近餐馆”,经过 NLU 处理后得到intent = ask,slots={位置:五道口}。
对话状态跟踪模块输出 slots={位置:五道口}。
Action候选为餐馆检索和需求澄清。
Policy将候选Action排序。
Action执行根据Action排序执行action更新交互状态
由NLG生产回复,“还有其他需求吗?”
用户继续输入。
自然语言生成
关于自然语言生成模块NLG,典型的概念到文本生成包含三部分,
内容选择,从输入中选择合适的内容并决定输出文本的结构。
句子规划,决定个别句子的词汇内容。
内容表达,渲染选定句子到输出。
传统做法涉及到:
概率上下文无关文法
n元语法
属性检测
阈值过滤
文本筛选
基于深度学习的方式:
RNN
LSTM
seq2seq
encoder-decoder
训练样本需要几十万条。
问题及思考
人机对话目前只有在很小的某个领域能做出效果,不大可能实现一个大范围的通用的聊天机器人。
目前主流对话系统的主体框架都大同小异,主要还是要能出效果。要做出效果就只有将领域限定得很小才可行,可以把业务领域限定的很小,只是某块小业务。
涉及到用机器学习或深度学习的对话系统都需要大量的训练样本,没有办法跳过人力标注这步。
NLU、DM、NLG三个模块在工程上的调用形式主要以库的形式调用,如果以服务的形式调用会比较重,而且涉及到升级的话会比较麻烦,涉及到多项目组。
数据才是最重要的,没有数据寸步难行,而且数据要能不断更新,与在线系统实现闭环。
目前工程上效果较好的的主要都还是用传统的基于规则,会在某些环节引入机器学习或深度学习,不会直接end-to-end做法。
人工智能也好深度学习也罢,其实回归到问题本质才能真正地利用人工智能,而不是一味吹捧什么高大上的人工智能。
样本标注方面,需要搞用户便捷的标注系统,方便业务人员或标注人员使用。
本公众号专注于人工智能、读书与感想、聊聊数学、计算机科学、分布式、机器学习、深度学习、自然语言处理、算法与数据结构、Java深度、Tomcat内核等。

