

作者:陈晓强
一、基础
为什么要了解抽象语法树
日常工作中,我们会碰到js代码解析的场景,比如分析代码中require了哪些包,有些什么关键API调用,大部分情况使用正则表达式来处理,可一旦场景复杂,或者依赖于代码上下文时,正则就很难处理了,这时候就要用到抽象语法树。常见的uglify、eslint、babel、webpack等等都是基于抽象语法树来处理的,如此强大,有必要好好了解一下。
什么是抽象语法树
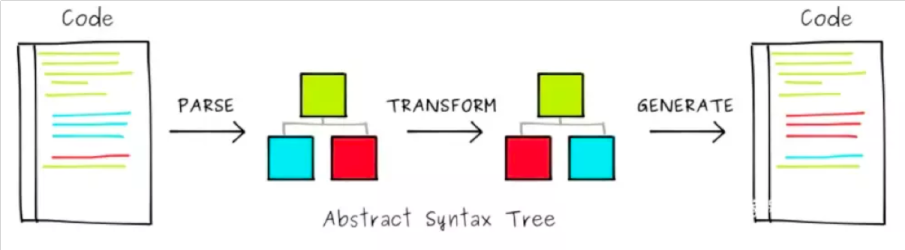
抽象语法树即:Abstract Syntax Tree。简称AST,见下图。
- 图中code先经过parse转换成一个树状数据结构
- 接着对树中节点进行转换,图中将叶子节点对换位置
- 将树状结构通过generate再生成code
图中树状数据结构即AST,从这个过程可以看到将代码转成AST后,通过操作节点来改变代码。
如何获得抽象语法树
获得抽象语法树的过程为:代码 => 词法分析 => 语法分析 => AST
词法分析:把字符串形式的代码转换为令牌(tokens)流。
语法分析:把一个令牌流转换成 AST 的形式。这个阶段会使用令牌中的信息把它们转换成一个 AST 的表述结构,这样更易于后续的操作。
如下图,代码为一个简单的函数声明。词法分析阶段,将代码作为字符串输入获得关键词,图中function、square、(、)、{、}等都被识别为关键词(稍微回忆下编译原理,字符挨个入栈,符合一定规则即出栈)。语法分析阶段,对关键词的组合形成一个个节点,如n*n这3个关键词组合成二元表达式,关键词return与二元表达式组合成return语句。最后组合成一个函数声明语句。

二、规范
如何获得AST已经简单介绍了,那AST最终应该以什么样的数据结构存在呢,先看看上述函数声明的AST结构

那解析的依据是什么,为什么要以上图的结构出现,业界已经有了一套成熟的规范。
规范起源
在v8引擎之前,最早js引擎是SpiderMonkey,第一个版本由js作者Brendan Eich设计,后交给Mozilla组织维护。js引擎在执行js文件时,都会先将js代码转换成抽象语法树(AST)。有一天,一位Mozilla工程师在FireFox中公开了这个将代码转成AST的解析器Api,也就是Parser_API[1],后来被人整理到github项目estree[2],慢慢的成了业界的规范。
规范解读
上面提到的Parser_API是规范的原文,中文版:Parser_API[3],但读起来并不太友好,推荐直接读整理后的git项目estree,打开项目地址,如下图

其中最下面的
es5.md为ES5规范,仅列出ES5的内容,es2015.md为ES6规范,但只列出了针对ES5新增的内容,依次类推,最后的es2019.md即ES10是对ES9的补充,仅有一条规则。
打开最基础的es5.md,可以看到所有语法基础,这里跟大家一起读一下大类,细分类别就略过了。读规范时可以使用https://astexplorer.net/ 辅助阅读,可以实时输出AST。
Node objects
interface Node {
type: string;
loc: SourceLocation | null;
}
定义AST中节点基本类型,其他所有具体节点都需要实现以上接口,即每个节点都必须包含type、loc两个字段
type字段表示不同的节点类型,下边会再讲一下各个类型的情况,分别对应了 JavaScript 中的什么语法。你可以从这个字段看出这个节点实现了哪个接口
loc字段表示源码的位置信息,如果没有相关信息的话为 null,否则是一个对象,包含了开始和结束的位置。接口如下
interface SourceLocation {
source: string | null;
start: Position;
end: Position;
}
每个 Position 对象包含了行(从1开始)和列(从0开始)信息,接口如下
interface Position {
line: number; // >= 1
column: number; // >= 0
}
Programs
interface Program <: Node {
type: "Program";
body: [ Directive | Statement ];
}
一棵完整的程序代码树,一般作为根节点
Identifier
interface Identifier <: Expression, Pattern {
type: "Identifier";
name: string;
}
标识符,我们写代码时自定义的名称,如变量名、函数名、属性名。
Literal
interface Literal <: Expression {
type: "Literal";
value: string | boolean | null | number | RegExp;
}
字面量,如“hello”、true、null、100、/\d/这些,注意字面量本身也是一个表达式语句(ExpressionStatement)
Functions
interface Function <: Node {
id: Identifier | null;
params: [ Pattern ];
body: FunctionBody;
}
一个函数声明或者表达式,id是函数名,params是标识符数组,body是函数体,也是一个语句块。
Statements
interface Statement <: Node { }
语句,子类有很多,块语句、if/switch语句、return语句、for/while语句、with语句等等
Declarations
interface Declaration <: Statement { }
声明,子类主要有变量申明、函数声明。
Expressions
interface Expression <: Node { }
表达式,子类很多,有二元表达式(n*n)、函数表达式(var fun = function(){})、数组表达式(var arr = [])、对象表达式(var obj = {})、赋值表达式(a = 1)等等
Patterns
interface Pattern <: Node { }
模式,主要在 ES6 的解构赋值中有意义(let {name} = user,其中{name}部分为ObjectPattern),在 ES5 中,可以理解为和Identifier 差不多的东西。
三、现状
通过以上规范解读,知道了最终要生成的AST以什么样的结构存在,对于javascript的解析,业界已经有很多成熟的解析器,可以将js代码转换成符合规范的AST
- Esprima,比较经典,出现的比较早
- Acorn,fork自Esprima,代码更精简。webpack使用acorn进行模块解析
- UglifyJS2,主要用于代码压缩
- babylon,babel解析器,fork自Acorn,目前最新版本是babylon7,对应npm包@babel/parser
- Espree,eslint默认的解析器,由于遵循同一套规范,也可以使用babel的解析器替代
- flow、shift等等
AST基础篇介绍完毕,下篇将从实践的角度继续介绍
References
[1] Parser_API
[2] estree
[3] Parser_API(中文)
如果你觉得这篇内容对你有价值,请点赞,并关注我们的官网和我们的微信公众号(WecTeam):

