


6-1 dict的abc继承关系
from collections import Mapping,MutableMapping
#dict属于mapping类型
a={}
print (isinstance(a,MutableMapping))
6-2 dict的常用方法
a=dict()
a={"bobby1":{"company":"imooc"},"bobby1":{"company":"imooc"}}
#clear
#a.clear()
#pass
#copy,返回浅拷贝
new_dict = a.copy()
new_dict["bobby1"]["company"]="imooc3"
#copy,返回深拷贝
import copy
new_dict=copy.deepcopy(a)
new_dict["bobby1"]["company"]="imooc3"
#formkeys
new_list=["bobby1","bobby2"]
new_dict=dict.fromkeys(new_list,{"company":imooc})
value=new_dict.get("bobby",{})
6-3 dict的子类
#不建议继承set和dict
class Mydict(dict):
def __setitem__(self,key,value):
super().__setitem__(key,value*2)
my_dict=Mydict(one=1)
my_dict["one"] =1
print(my_dict)
from collections import UserDict
class Mydict(UserDict):
def __setitem__(self,key,value):
super().__setitem__(key,value*2)
my_dict=Mydict(one=1)
#my_dict["one"] =1
print(my_dict)
from collections import defaultdict
my_dict=defaultdict(dict)
my_value=my_dict["bobby"]
pass
6-4 set和frozenset
#set 集合 fronzenset(不可变集合)无序,不重复
s = set('abcde')
s = set(['a','b','c','d','e'])
s={'a','b'}
print(type(s))
s = fornzenset('abcde') #fronzenset 可以作为dict的key
#向set添加数据
s.add()
another_set=set("def")
s.update(another_set)
re_set=s.defference(another_set)
re_set = s-another_set
# / & - #集合运算
#set性能很高
print (s.issubset(re_set))
if "c" in re_set:
print("i am in set")
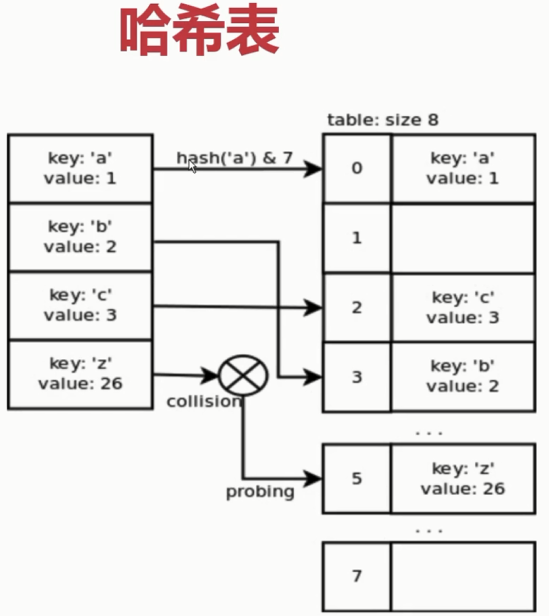
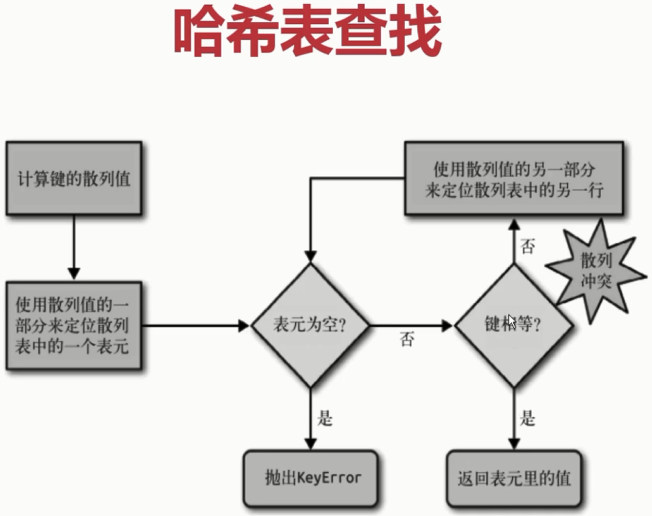
6-5 dict和set的实现原理
from random import randint
def load_list_data(total_nums, target_nums):
"""
从文件中读取数据,以list的方式返回
:param total_nums: 读取的数量
:param target_nums: 需要查询的数据的数量
"""
all_data = []
target_data = []
file_name = "G:/慕课网课程/AdvancePython/fbobject_idnew.txt"
with open(file_name, encoding="utf8", mode="r") as f_open:
for count, line in enumerate(f_open):
if count < total_nums:
all_data.append(line)
else:
break
for x in range(target_nums):
random_index = randint(0, total_nums)
if all_data[random_index] not in target_data:
target_data.append(all_data[random_index])
if len(target_data) == target_nums:
break
return all_data, target_data
def load_dict_data(total_nums, target_nums):
"""
从文件中读取数据,以dict的方式返回
:param total_nums: 读取的数量
:param target_nums: 需要查询的数据的数量
"""
all_data = {}
target_data = []
file_name = "G:/慕课网课程/AdvancePython/fbobject_idnew.txt"
with open(file_name, encoding="utf8", mode="r") as f_open:
for count, line in enumerate(f_open):
if count < total_nums:
all_data[line] = 0
else:
break
all_data_list = list(all_data)
for x in range(target_nums):
random_index = randint(0, total_nums-1)
if all_data_list[random_index] not in target_data:
target_data.append(all_data_list[random_index])
if len(target_data) == target_nums:
break
return all_data, target_data
def find_test(all_data, target_data):
#测试运行时间
test_times = 100
total_times = 0
import time
for i in range(test_times):
find = 0
start_time = time.time()
for data in target_data:
if data in all_data:
find += 1
last_time = time.time() - start_time
total_times += last_time
return total_times/test_times
if __name__ == "__main__":
all_data, target_data = load_list_data(10000, 1000)
# all_data, target_data = load_list_data(100000, 1000)
# all_data, target_data = load_list_data(1000000, 1000)
# all_data, target_data = load_dict_data(10000, 1000)
# all_data, target_data = load_dict_data(100000, 1000)
# all_data, target_data = load_dict_data(1000000, 1000)
last_time = find_test(all_data, target_data)
#dict查找的性能远远大于list
#在list中随着list数据的增大,查找时间会增大
#在dict中随着dict的增大,查找时间不会增大
print(last_time)
#dict 的key或者set的值,都必须是可以hash的
#不可变对象 都是可哈希的,str,fronzenset,tuple,自己实现的类,可以实现__hash__方法
#2.dict的内存花销大,但是查询速度快自己定义的对象或者python内部的对象都是用dict包装的
#3.dict的存储顺序和元素的添加顺序有关
#4.添加数据有可能改变已有数据的顺序
6-6 本章小结
python基于协议编程的,dict常用的用法,dict的子类,set和fronzenset,dict背后的哈希表与特性.
