

redis三大功能
redis除了我们常用的5中基本数据类型,在此基础上,还提供了一些特殊的功能模块。这里介绍以下三种:bitmaps,hyperloglog,geo。
bitmaps
-
概述
redis中的bitmaps(位图)不是实际的数据类型,而是在String类型上定义的一组面向位的操作。由于字符串是二进制安全blob,并且它们的最大长度为512 MB,因此它们适合设置最多2^32个不同的位。位图的最大优势之一是它们在存储信息时通常可以节省大量空间。例如,在通过增量用户ID表示不同用户的系统中,可以使用仅512MB的存储器记住40亿用户的单个位信息

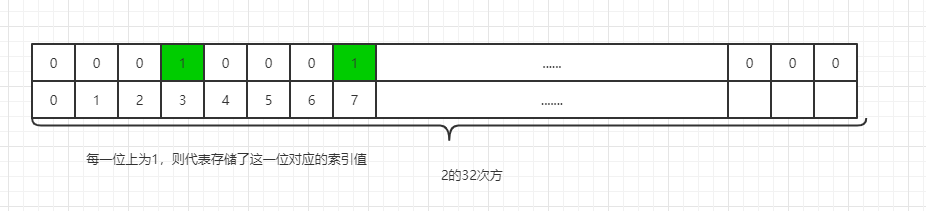
-
使用场景
活跃用户数统计:假设一个系统每天有100万独立用户登录。
需求1:统计每周的活跃用户数。
需求2:统计一周每天都登录了用户数。
分析,需要存储每个用户的每一天的登录信息
-
常用命令
setbit key offset value bitop 在不同的字符串之间执行逐位操作。提供的操作是AND,OR,XOR和NOT。 bitcount 执行填充计数,报告设置为1的位数。 bitpos 查找具有指定值0或1的第一个位。 -
代码
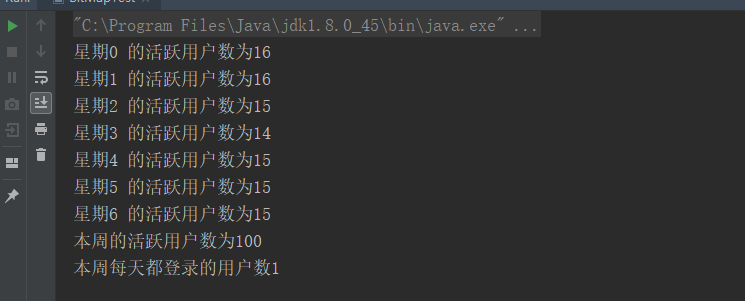
//TODO public class BitMapTest { public static void main(String[] args) { //连接本地的 Redis 服务 Jedis jedis = new Jedis("localhost"); //初始化id为0-99的签到情况 IntStream.range(0, 100).forEach((id) -> { jedis.setbit("星期" + id % 7, id, true); } ); //id的为10的用户,每天都登录了的。 for (int i = 0; i < 7; i++) { jedis.setbit("星期" + i , 10, true); } for (int i = 0; i < 7; i++) { System.out.println(String.format("星期%s 的活跃用户数为%s",i, jedis.bitcount("星期" + i))); } jedis.bitop(BitOP.OR, "week","星期0", "星期1", "星期2", "星期3", "星期4", "星期5", "星期6"); System.out.println(String.format("本周的活跃用户数为%s",jedis.bitcount("week"))); jedis.bitop(BitOP.AND, "week1","星期0", "星期1", "星期2", "星期3", "星期4", "星期5", "星期6"); System.out.println(String.format("本周每天都登录的用户数%s",jedis.bitcount("week1"))); } }
-
总结
学习bitmap,我们知道bitmap通过一个bit数组来存储特定数据的一种数据结构,每一个bit位都能独立包含信息,bit是数据的最小存储单位,因此能大量节省空间。bitmap有一个很明显的优势是可以轻松合并多个统计结果,只需要对多个结果求与,或,异或等操作就可以。也可以大大减少存储内存,可以做个简单的计算,如果要统计1亿个数据的基数值,大约需要内存。
数据类型 占用空间 储存的用户量 内存量 set 32位 100000000 32*100000000/8/1024/1024≈ 381M bitMap 1位 100000000 100000000/8/1024/1024 ≈ 12M
hyperloglog
-
概述
什么是基数? 假设有个集合为(1,4,2,7,8,7)那么这个集合的基数为去重之后的元素个数,即为5。
bitmap对于内存的节约量是显而易见的,但还是不够。统计一个对象的基数值需要12M,如果统计10000个对象,就需要将近120G了,同样不能广泛用于大数据场景。
redis中实现的HyperLogLog,只需要12K内存,在标准误差0.81%的前提下,能够统计2^{64}个数据。HyperLogLog是一种概率算法,概率算法不直接存储数据集合本身,通过一定的概率统计方法预估基数值,这种方法可以大大节省内存,同时保证误差控制在一定范围内。
-
常用命令
pfadd key val1 val2 ... pfcount key 统计基数 -
使用场景
统计页面独立的UV,UV即对于某个页面,每天独立访问的用户数量,如果同一个用户多次访问,只能算一次。
-
代码
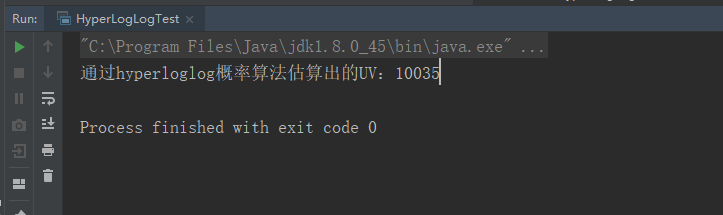
public class HyperLogLogTest { public static void main(String[] args) { //连接本地的 Redis 服务 Jedis jedis = new Jedis("localhost"); //初始化id为0-99的签到情况 IntStream.range(0, 10000).forEach((id) -> { String userId = UUID.randomUUID().toString(); jedis.pfadd("datetime:page1",userId); } ); System.out.println("通过hyperloglog概率算法估算出的UV:"+jedis.pfcount("datetime:page1")); } }
-
总结
hyperloglog是一种概率算法,是通过局部推算整体的一种算法,在不存储元素的情况下,用计算集合的基数,但是有一定的误差。如果误差在业务容忍的范围内。那么这一种非常节省内存的高效算法。
geo
-
概述
在redis3.2版本,增加了Geo地理空间位置的计算功能。通过GEO我们可以计算两个地理位置的距离,以及给定地理位置获取指定范围内的地理位置集合等
-
常用命令(使用redis3.2之后的版本才有geo功能)
1、GEOADD:增加某个地理位置的坐标 2、GEOPOS:获取某个地理位置的坐标 3、GEODIST:获取两个地理位置的距离 4、GEORADIUS:根据给定地理位置坐标获取指定范围内的地理位置集合 5、GEORADIUSBYMEMBER:根据给定地理位置获取指定范围内的地理位置集合 6、GEOHASH:获取某个地理位置的 geohash 值
-
使用场景
计算用户和商家的距离
-
代码
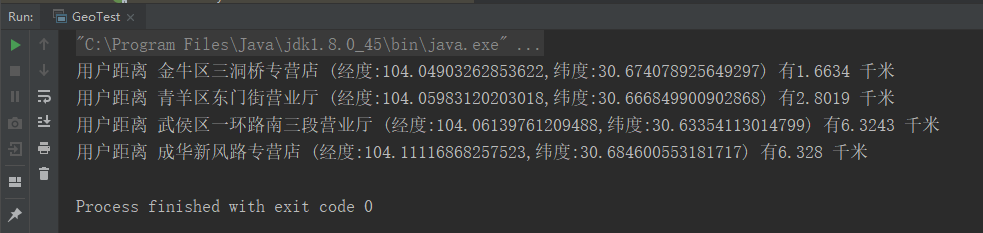
public class GeoTest { public static void main(String[] args) { //连接本地的 Redis 服务 Jedis jedis = new Jedis("localhost"); //初始化4个门店的位置 Map<String, GeoCoordinate> map=new HashMap<>(); map.put("成华新风路专营店",new GeoCoordinate(104.11117,30.6846)); map.put("青羊区东门街营业厅",new GeoCoordinate(104.05983,30.66685)); map.put("武侯区一环路南三段营业厅",new GeoCoordinate(104.0614,30.63354)); map.put("金牛区三洞桥专营店",new GeoCoordinate(104.04903,30.67408)); jedis.geoadd("shop",map); GeoRadiusParam param=GeoRadiusParam.geoRadiusParam() .withDist()//返回距离 .withCoord() //返回经纬度 .sortAscending();//根据距离升序排序; double userLongitude=104.045181;//用户的经度 double userLatitude=30.688663;//用户的纬度 //查询距离用户10公里范围内的营业点 List<GeoRadiusResponse> shop = jedis.georadius("shop", userLongitude, userLatitude, 10, GeoUnit.KM,param); for (GeoRadiusResponse geoRadiusResponse : shop) { System.out.println(String.format("用户距离 %s (经度:%s,纬度:%s) 有%s 千米 ", geoRadiusResponse.getMemberByString(), geoRadiusResponse.getCoordinate().getLongitude(), geoRadiusResponse.getCoordinate().getLatitude(), geoRadiusResponse.getDistance())); } } }
-
总结
redis的geo是通过 它只是假设地球是一个球体,因为使用的距离公式是Haversine公式。这个公式只是在应用于地球时的近似值,而地球不是一个完美的球体。在作为不是特别高的精度情况下,使用geo是一个不错的选择。
