

从 SF 慢慢把文章搬过来。。。
TL.DR
软件是一个巨大的有限状态机。
工程师日常做的 bug 修复、性能调优,本质上就是尽可能保证代码处于有序状态下。尽可能多地将状态固定在编码时,就就减少了运行期的状态,使得软件的状态总数减少了。
状态总数少了,错误就少了,性能也提升了。
减少错误
以矩阵相乘为例。
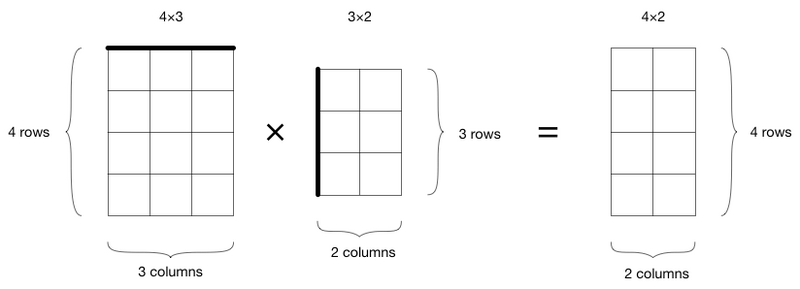
如图所示,要保证第一个矩阵中的列数必须与第二个矩阵中的行数相同。简单的做法是做运行时检查
struct Matrix {
let rows: Int
let columns: Int
}
func multiply(m1: Matrix, _ m2: Matrix) -> Matrix? {
// do the matrices have the correct sizes?
precondition(m1.columns == m2.rows)
// bunch of math...
}
更好的做法是在编码时,就不允许出现行列不等的情况
protocol Dimension {
static var size: Int { get set }
}
func multiply<U: Dimension, V: Dimension, W: Dimension>
(m1: Matrix<U,V>, _ m2: Matrix<V,W>) -> Matrix<U,W> {
// bunch of math...
return Matrix<U,W>()
}
运行结果
struct NumExamples: Dimension { static var size = 20 }
struct NumFeatures: Dimension { static var size = 10 }
struct OneDimensional: Dimension { static var size = 1 }
let A = Matrix<NumExamples, NumFeatures>()
let B = Matrix<NumFeatures, OneDimensional>()
let C = multiply(A, B) // yay!
let D = multiply(B, A) // compiler error
完整的优化过程不在本文的讨论范围内,感兴趣的可以看这里。
提升性能
以 OC Runtime 的 Non fragile ivars 为例。 与 C、C++以来对象的内存结构不同,为了实现 ABI 兼容,OC 的对象并不直接存储成员变量的指针,每个成员变量都需要两次寻址才能访问到。比如要获取 obj 的第 n 个变量的偏移地址,就要
*((&obj->isa.cls->data()->ro->ivars->first)[N]->offset);
看起来慢爆了。
在实现上,LLVM 为每个类的每个成员变量都分配了一个全局变量,用于存储该成员变量的偏移值。这样,访问每个变量需要两次寻址,先获取全局变量,再取全局变量的值作为地址找到真正的变量。
编译后的
obj->myInt = 42;
对应于如下 C 代码
int32_t g_ivar_MyClass_myInt = 40; // 全局变量
*(int32_t *)((uint8_t *)obj + g_ivar_MyClass_myInt) = 42;
这就是为什么 ivar_t.offset 用 int 指针来存储偏移值,而不是直接放一个 int 的原因。
struct ivar_t {
int32_t *offset; // 注意,这里是指针
const char *name;
const char *type;
//...
}
真正存放偏移值的地址是固定不变的,在编译时就确定了下来。因此才能用区区 2 条指令搞定动态布局的成员变量。
参考链接
objc explain: Non-fragile ivars Dynamic ivars: solving a fragile base class problem 编程世界的熵增原理
