

Master节点进程解析
Master进程的重要性已经不需要过多的描述,一个Spark集群(Standalone部署模式)必须有至少一个Master进程来协调整个集群的资源。
Master中的main函数
main函数十分简短,如下所示:
def main(argStrings: Array[String]) {
Thread.setDefaultUncaughtExceptionHandler(new SparkUncaughtExceptionHandler(
exitOnUncaughtException = false))
Utils.initDaemon(log)
val conf = new SparkConf
val args = new MasterArguments(argStrings, conf)
val (rpcEnv, _, _) = startRpcEnvAndEndpoint(args.host, args.port, args.webUiPort, conf)
rpcEnv.awaitTermination()
}
简单来说,
- 设置SparkConf
- 看函数名是开启了一个RPC环境,然后设置了一个Endpoint,就没了
SparkConf还比较好理解,就把它当作是一个键值对的配置集合。 那么,什么是RPC环境呢?Endpoint又是个什么鬼呢? RPC的概念请参考这里
本文接下来将尽最大的努力,用通俗易懂的方式讲解清楚。
基础对象概念
首先来看EndPoint,在Spark中用更具体的RpcEndPoint来替代抽象的endpoint这一概念。
RpcEndPoint
源码中对RpcEndPoint的定义是:
private[spark] trait RpcEndpoint
可以看出,RpcEndpoint是一个接口 其内部方法有如下:

An end point for the RPC that defines what functions to trigger given a message.
翻译一下就是:一个Rpc中的endpoint用于定义在给定消息时触发的函数。
RpcEndPoint是一个抽象的概念,表示在rpc环境中的实体。一个EndPoint的实例endpoint对应Actor模型中的一个特定的actor实体,endpoint能针对接收的消息进行响应、回复等操作。
一个endpoint的生命周期为: 构造函数-> onStart() -> receive* -> onStop() 一个endpoint启动之后,主要的工作就是调用receive对收到的消息进行处理。
RpcEndPoint只是最抽象的概念,ThreadSafeRpcEndpoint继承了RpcEndpoint,且用的更 多。
ThreadSafeRpcEndpoint的实现类有
RpcEnv概念
RpcEnv顾名思义,是rpc的环境,Spark通过一个RpcEnv的概念来屏蔽掉RPC通讯的具体细节。如何屏蔽的呢?若要对远程的节点发送、回复消息,都可以简单的通过rpcenv.send来进行发送,当然,这个send方法背后做了很多的事情,当对于调用者而言,都不用关心,这就实现了屏蔽的目的。
源码中的RpcEnv的定义为:
private[spark] abstract class RpcEnv(conf: SparkConf)
是一个抽象类,为什么是抽象类而不是接口呢,是因为源码中还有一个伴生的RpcEnv单例。在实现中,最终是用的NettyRpcEnv这个具体类。
进程启动过程详解
如下图所示
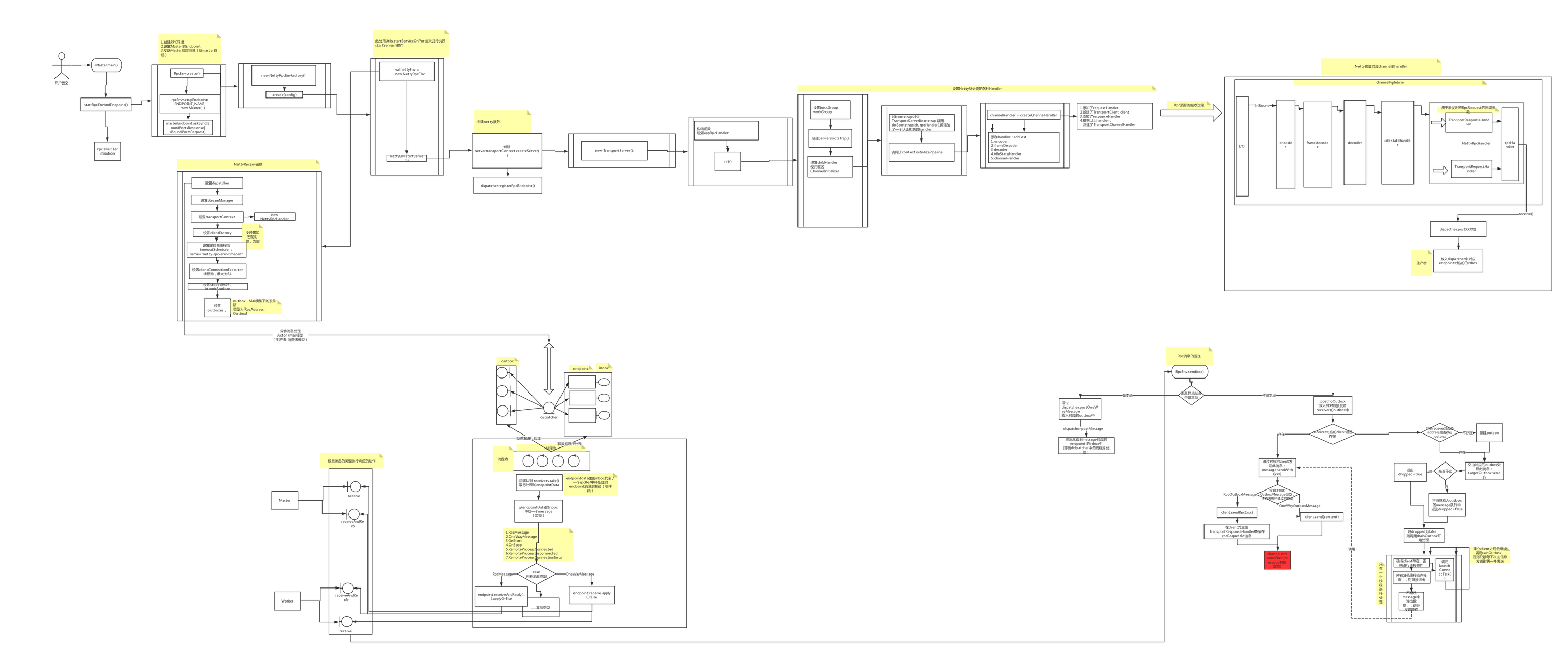
在main函数中,startRpcEnvAndEndpoint函数以及其调用的子函数做了以下事情:
- RpcEnv.create创建了rpcenv环境(层层调用 最终调用了下面函数)
- nettyEnv = new NettyRpcEnv(xxxx)
- nettyEnv.startServer()//rpc环境创建完毕,就开启服务
- 在rpcenv环境中设置了Master这一endpoint
- 向上一步设置的master这一endpoint发送BoundPortsRequest消息
接下来一步一步详细说明。
具体的组件及其功能
NettyRpcEnv
NettyRpcEnv类是RpcEnv的一个具体实现类,也是目前唯一的实现类,因为当前版本的Spark是基于Netty实现。 NettyRpcEnv有内部有几个十分重要的变量
- dispatcher // 用于路由通过网络收到的消息
- clientFactory // 用于创建远程实例的映像client
- transportContext // 利用netty做底层通讯的桥梁
- NettyRpcHandler // netty回调函数与Spark封装的的Actor模型的桥梁
- outbox // 用于向逻辑的远程写入数据消息 其中,dispatcher和outbox以及另一个稍后会提及的概念EndPointData的inbox,一起实现了异步数据的生产者消费模型:Mail模型
dispatcher
十分重要的一个组件,用于对接收到对消息进行处理
内部有以下组件
- 内部类: EndpointData,代表了一个待处理的endpoint,这个内部类内部只有一个变量:
- inbox :Inbox,内部有一个message队列,保存了待处理的消息
- endpoints: ConcurrentMap[String, EndpointData]:用于记录Endpointdata
- endpointRefs: ConcurrentMap[RpcEndpoint, RpcEndpointRef] :用于记录Endpoint与EndpointRef的映射关系
- receivers:LinkedBlockingQueue[EndpointData]:保存那些inbox可能有消息的接收者(EndpointData)
- threadpool: ThreadPoolExecutor;内部的线程池
- MessageLoop:Runnable;在线程池中运行的实际任务,用于处理receivers中的消息
- 除了以上方法之外,还提供了RpcEndpoint的注册/解除、路由消息的postXXXMessage方法
看到以上这些变量、方法,就可以清楚的知道dispatcher的作用:路由消息。此外,通过dispatcher内部的线程池,将消息的接收和处理分隔开来,实现了某种意义上的生产者、消费者模型。 后面的文章会通过实际的数据交互流程,来说明dispatcher的作用,以及如何运转的。
clientFactory
看名字就可以看出来,这是一个工厂类,用于产生client。
而client的含义(具体来说,是TransportClient),简单来说就是在TCP连接中所建立的socket。不过在Netty中,这一概念变成了Channel。
client中最重要的就是它的成员变量Channel,通过channel可以对外发送数据。总之,把cliet看作是channel的一个包装即可。
transportContext
传输上下文,提供了创建TransportServer、创建ClientFactory、创建channel所需要的handler以及初始化Channel的pipeline的方法。
通过设置RpcHandler,可以起到沟通netty和Spark的作用。
后续文章会讲解此类的作用
outbox
类型为ConcurrentHashMap[RpcAddress, Outbox],代表了要发送给远程某一个rpc地址的邮箱。同样也是Mail模型。 与Inbox不同的是,,此处的outbox里面的数据是通过rpcenv调用对应的client发送的,而不是通过线程池异步发送的
Master
Master的作用就像它的名字一样,是Spark集群的master,起到管理资源、调度任务的作用。
作为一个master,必定要保存十分繁杂的被管理的节点的资源信息,所以,在Master中,有许多的Map、Set,用于保存各种各样的信息。
要想梳理Master的动作,首先需要关注的是它的receive*()方法,可以从这里入手,阅读其对不同的消息的不同处理动作。
Master底层Netty通讯链路的建立
在创建了nettyEnv之后,则是建立监听Worker节点、Client节点的请求连接的server端服务,即调用NettyRpcEnv.startServer(),设置handler,bind端口,开启服务。具体分析如下:
- 调用transportContext的createServer来建立服务。
- 调用dispatcher的registerRpcEndpoint来设置一个endpoint-verifier验证器。
transportContext的createServer方法中,创建了TransportServer对象,而这个TransportServer对象,在构造函数中,调用它自身的init(hostToBind,portToBind)函数后,就已经按照netty的套路,将一个server建立绑定完成了,可以监听端口了。
下面详细看看init方法:
//位于package org.apache.spark.network.server;
private void init(String hostToBind, int portToBind) {
IOMode ioMode = IOMode.valueOf(conf.ioMode());
//设置了netty必须的bossGroup和workGroup
EventLoopGroup bossGroup =
NettyUtils.createEventLoop(ioMode, conf.serverThreads(), conf.getModuleName() + "-server");
EventLoopGroup workerGroup = bossGroup;
PooledByteBufAllocator allocator = NettyUtils.createPooledByteBufAllocator(
conf.preferDirectBufs(), true /* allowCache */, conf.serverThreads());
// 因为是监听的server,所以使用ServerBootstrap
bootstrap = new ServerBootstrap()
.group(bossGroup, workerGroup)
.channel(NettyUtils.getServerChannelClass(ioMode))
.option(ChannelOption.ALLOCATOR, allocator)
.childOption(ChannelOption.ALLOCATOR, allocator);
...
// 给监听到的连接设置handler
bootstrap.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) {
RpcHandler rpcHandler = appRpcHandler;
for (TransportServerBootstrap bootstrap : bootstraps) {
rpcHandler = bootstrap.doBootstrap(ch, rpcHandler);
}
// 使用transportContext的方法给pipeline添加各种handler
context.initializePipeline(ch, rpcHandler);
}
});
InetSocketAddress address = hostToBind == null ?
new InetSocketAddress(portToBind): new InetSocketAddress(hostToBind, portToBind);
// 绑定到对应的地址上。
channelFuture = bootstrap.bind(address);
channelFuture.syncUninterruptibly();
// 至此,,server已经建立完成,等待监听其他节点的连接请求。
// 提交spark时需要填写的Spark master地址即这个server的地址(如:spark://localhost:7077)
port = ((InetSocketAddress)channelFuture.channel().localAddress()).getPort();
logger.debug("Shuffle server started on port: {}", port);
}
而transportContext的initializePipeline方法如下:
//位于package org.apache.spark.network;
public TransportChannelHandler initializePipeline(
SocketChannel channel,
RpcHandler channelRpcHandler) {
try {
TransportChannelHandler channelHandler = createChannelHandler(channel, channelRpcHandler);
channel.pipeline()
.addLast("encoder", ENCODER)
.addLast(TransportFrameDecoder.HANDLER_NAME, NettyUtils.createFrameDecoder())
.addLast("decoder", DECODER)
.addLast("idleStateHandler", new IdleStateHandler(0, 0, conf.connectionTimeoutMs() / 1000))
// NOTE: Chunks are currently guaranteed to be returned in the order of request, but this
// would require more logic to guarantee if this were not part of the same event loop.
.addLast("handler", channelHandler);
return channelHandler;
} catch (RuntimeException e) {
logger.error("Error while initializing Netty pipeline", e);
throw e;
}
}
代码中很清楚从可以看到,为连接channel添加了encoder编码器、frameDecoder帧解码器、decoder解码器、idleStateHandler空闲状态检测器、自定义的handler。
重点在于这个最后的这个自定义的handler。这个handler内部封装了代表channel的TransportClient、用于处理回调函数的responseHandler、处理netty接收到的后封装过的请求的requestHandler这三个子handler。 这三个handler共同作用,实现了消息编解码、事件触发的操作,为上层的Spark逻辑提供了支持。
网络流消息的处理流程
在设置完netty的TransportServer之后,就可以监听其他节点的连接请求事件,在连接建立之后,数据的发送、接收过程。
在数据到达Master的netty连接之后,会依次经过解码、帧重组、消息封装,最后数据由ByteBuf类型转变为Spark中的Message,经由transportChannelHandler处理,若为request消息,则交由经由transportChannelHandler处理中的requestHandler进行处理,若是response消息,则交由responseHandler处理。
若交由requestHandler处理,则调用requestHandler中的handle方法,继续交由消息类型对应的具体处理方法。因为本文着重分析RPC消息,则进考虑rpc消息。对于RPC消息,则交由requestHandler中的rpcHandler进行处理,调用rpcHandler的receive方法,这个方法先做一个internalRecive,然后调用dispatcher的postRemoteMessage,将消息投递到对用endpoint到inbox中,至此,一个完整到网络消息就算接收完毕了,之后是dispatcher中到线程池不断到消费各个endpoint中到inbox,进行处理。
化简一下上述的流程:
IO数据 -> 解码、帧重组、消息类型识别封装 -> transportChannelHandelr处理 -> rpcHandler处理
-> rpcHandler的receive方法 -> 通过dispatcher将消息"投递"到对应发送者的收件箱inbox中
-> dispatcher中的线程池轮询,取出消息进行处理。
总结上述的网络数据操作,可以看到,rpcHandler作为netty中的一个handler, 是连接netty通讯底层和Spark Rpc框架的桥梁,数据经过rpcHandler被传到dispatcher中进行处理。
小结:
Master进程的分析,从RPC角度来说,主要就是netty中的server的创建、启动,以及通过给建立的连接所对应的channel添加合适的hadnler,来使消息被传递到Spark RPC框架中。
至于Master作为一个EndPoint,是如何响应消息、作出反映的,通过查看Master的receive*函数即可获得消息的处理入口,对此后续文章将继续进行分析。
以上内容尚未定稿,仍有待完善。
