

缓存
缓存粒度控制
三个角度
1)通用性:全量属性更好。
2)占用空间:部分属性更好。
3)代码维护:表面上全量属性更好。
缓存穿透
定义:大量请求不命中。
原因
1)业务代码自身问题。
2)恶意攻击、爬虫等等。
如何发现
1)业务的相应时间。
2)业务本身问题。
3)相关指标:总调用数、缓存层命中数、存储层命中数。
解决问题
1)缓存空对象。
1、需要更多的键。
2、缓存层和存储层数据“短期”不一致。

2)布隆过滤器拦截。
所谓的布隆过滤器是一个很长的二进制向量,存放0或者1。经过几次hash计算,得到5,9,2三个数字,那么存放结果如下图所示:

仅仅从布隆过滤器本身而言,根本没有存放完整的数据,只是运用一系列随机映射函数计算出位置,然后填充二进制向量。因此,可以使用固定的计算方式 ,来判断一个数据是否存在。但是由于类似哈希冲突的原因存在误判的可能性,也就是说,布隆过滤器只能判断数据不存在,而不能判断数据一定存在。
- 优点:由于存放的不是完整的数据,所以占用的内存很少,而且新增,查询速度够快;
- 缺点: 随着数据的增加,误判率随之增加;无法做到删除数据;只能判断数据不存在,而不能判断数据一定存在。
代码
public class RedisTest {
static final int expectedInsertions = 100;//要插入多少数据
static final double fpp = 0.01;//期望的误判率
//bit数组长度
private static long numBits;
//hash函数数量
private static int numHashFunctions;
static {
numBits = optimalNumOfBits(expectedInsertions, fpp);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
}
public static void main(String[] args) {
Jedis jedis = new Jedis("你的ip", 6379);
for (int i = 0; i < 100; i++) {
long[] indexs = getIndexs(String.valueOf(i));
for (long index : indexs) {
jedis.setbit("codebear:bloom", index, true);
}
}
for (int i = 0; i < 100; i++) {
long[] indexs = getIndexs(String.valueOf(i));
for (long index : indexs) {
Boolean isContain = jedis.getbit("codebear:bloom", index);
if (!isContain) {
System.out.println(i + "肯定没有重复");
}
}
System.out.println(i + "可能重复");
}
}
/**
* 根据key获取bitmap下标
*/
private static long[] getIndexs(String key) {
long hash1 = hash(key);
long hash2 = hash1 >>> 16;
long[] result = new long[numHashFunctions];
for (int i = 0; i < numHashFunctions; i++) {
long combinedHash = hash1 + i * hash2;
if (combinedHash < 0) {
combinedHash = -combinedHash;
}
result[i] = combinedHash % numBits;
}
return result;
}
private static long hash(String key) {
Charset charset = Charset.forName("UTF-8");
return Hashing.murmur3_128().hashObject(key, Funnels.stringFunnel(charset)).asLong();
}
//计算hash函数个数
private static int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
//计算bit数组长度
private static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
}
缓存雪崩
定义:某一个时间段,缓存集中过期失效。
原因
1)集中设置统一的过期时间,到了一定时间时,便全部怼到数据库上了。
2)服务器某个结点宕机或断网。
解决
1)使用随机因子尽可能分散过期时间。
2)使用集群高可用化。
无底洞问题优化
问题描述:2010年,Facebook有了3000个Memcache节点,发现增加机器性能没能提升,反而下降。
问题关键点
1)更多的机器!=更高的性能。
2)批量接口需求(mget, mset等)。
3)数据增长与水平扩展等。
优化IO的几种方法
1)命令本身优化:例如慢查询keys、hgetall bigkey。
2)减少网络通信次数。
3)降低接入成本:例如客户端长连接/连接池、NIO等。
热点key重建
问题描述:热点key+较长的重建时间
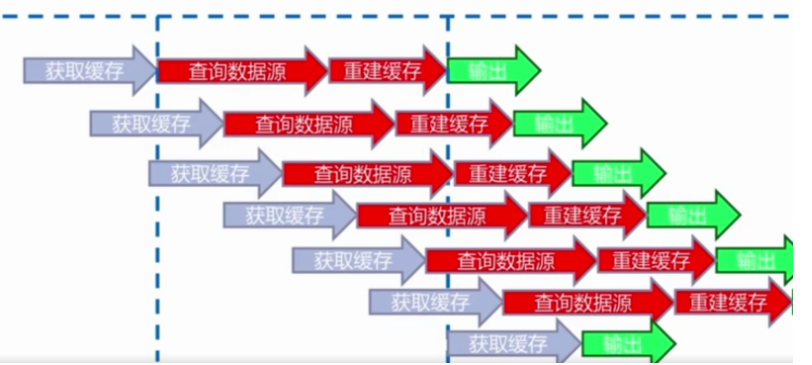
可能会存在多个线程共同执行查询数据源与重建缓存的操作。
目标
1)减少重建缓存的次数。
2)数据尽可能一致。
3)减少潜在风险。
解决
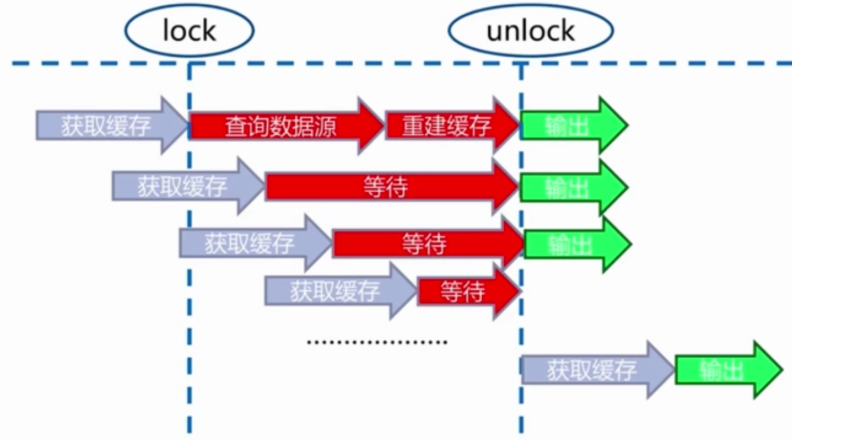
互斥锁(mutex key)
在重建时开始加锁,完成重建后进行解锁。
代码:
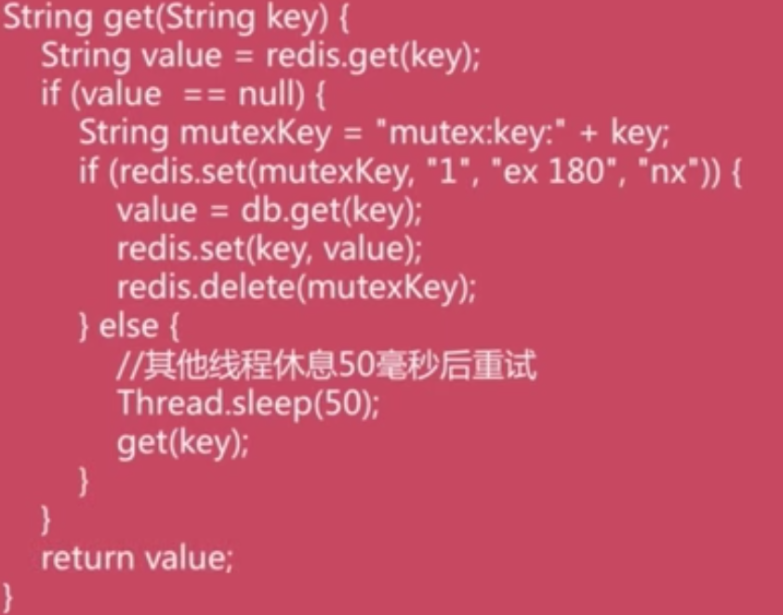
优点:
1)思路简单。
2)保证一致性。
缺点:
1)代码复杂度增加。
2)存在死锁的风险。
永远不过期
1)缓存层面:没有设置过期时间。
2)功能层面:为每个value添加逻辑过期时间,但发现超过逻辑过期后,会使用单独的线程去构建缓存。
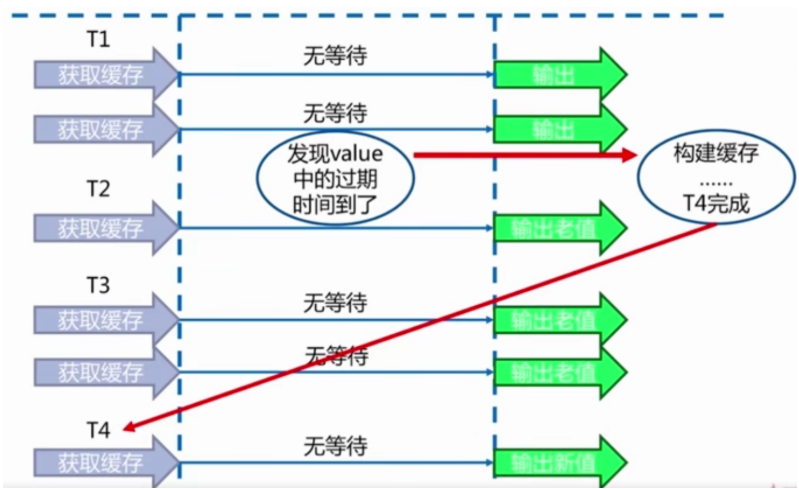
代码:

优点:
基本杜绝热点key重建问题。
缺点:
1)不保证一致性。
2)逻辑过期时间增加维护成本和内存成本。
