

前言
使用TABAnimated集成骨架屏的开发者,大概都知道其原理是基于原视图映射生成骨架层,在细节上不满意的地方可以通过预处理回调进行异步调整。
- 本文内容:TABAnimated的缓存策略
- 使用TABAnimated的开发者,此文档建议阅读
TABAnimated缓存的是什么?
缓存的是通过映射机制生成的骨架屏单元管理对象TABComponentManager,
对该对象使用一个plist文件来解释。同时,通过计数的方式,逐渐筛选出该用户经常加载的骨架屏,提高缓存命中率。
TABAnimated缓存功能有什么作用?
- 相同版本的代码,避开了重复使用映射机制
- 避开了映射采用的递归操作,降低了CPU峰值,提高系统性能
- 省去部分场景的视图预填充成本及其他耗时操作,稳定性得到有效提升
- 预处理回调需要重新调整CALayer的部分值,有效降低GPU绘制成本
性能评测
- 评测工具:Instruments
- 评测环境:单线程
- 评测机型:iPhone 6s
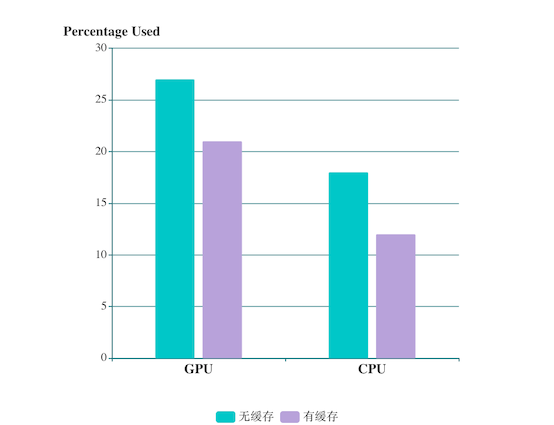
分析
其实,从峰值数据来看,GPU、CPU的数值本身并不高,缓存功能也并没有将他们的峰值降低很多,但是我为什么还要引入缓存策略呢?
答:
- 缓存策略更多地是优化了映射机制的耗时。对于CPU性能不高的设备,在极端的情况下,不能在下一次Vsyc信号来临时,将骨架屏的数据计算好并交给GPU处理,此时造成掉帧情况。
当然,掉帧是非常极端的情况。 例如:iPhone6 + 自适应高度 + 不规范的页面布局
- 映射机制,是基于当前开发好的视图。如果我的App打包上线了(除了热更新),那么此时骨架屏的映射结果也已经确定了,那么我还有必要每次都去映射一遍吗?
答案显然是不需要的。
TABAnimated采取的是:把映射结果存储在本地plist文件(大小约4kb)。唯一注意的是,TABAnimated会读取你的App版本,当你的App版本发生了变动,会重新映射一次。
正文目录
- 集成注意
- 缓存流程
- 存储结构
- 线程处理
- 特殊场景
一、集成注意
考虑到有些用户主要关注对后续使用会有什么影响,所以该点放到第一位。
集成只强调一点!!!也是最重要的一点,反复强调!!!
TABAnimated新增closeCache属性。
- debug 环境下,默认关闭缓存功能(为了方便通过预处理回调调试)
- release 环境下,默认开启缓存功能
- 如果你想在 debug 环境下测试缓存功能,可以强制置为NO。但是这个时候请注意,预处理回调再做修改,无效!
- 如果你始终都不想使用缓存功能,可以强制置为YES
二、缓存流程
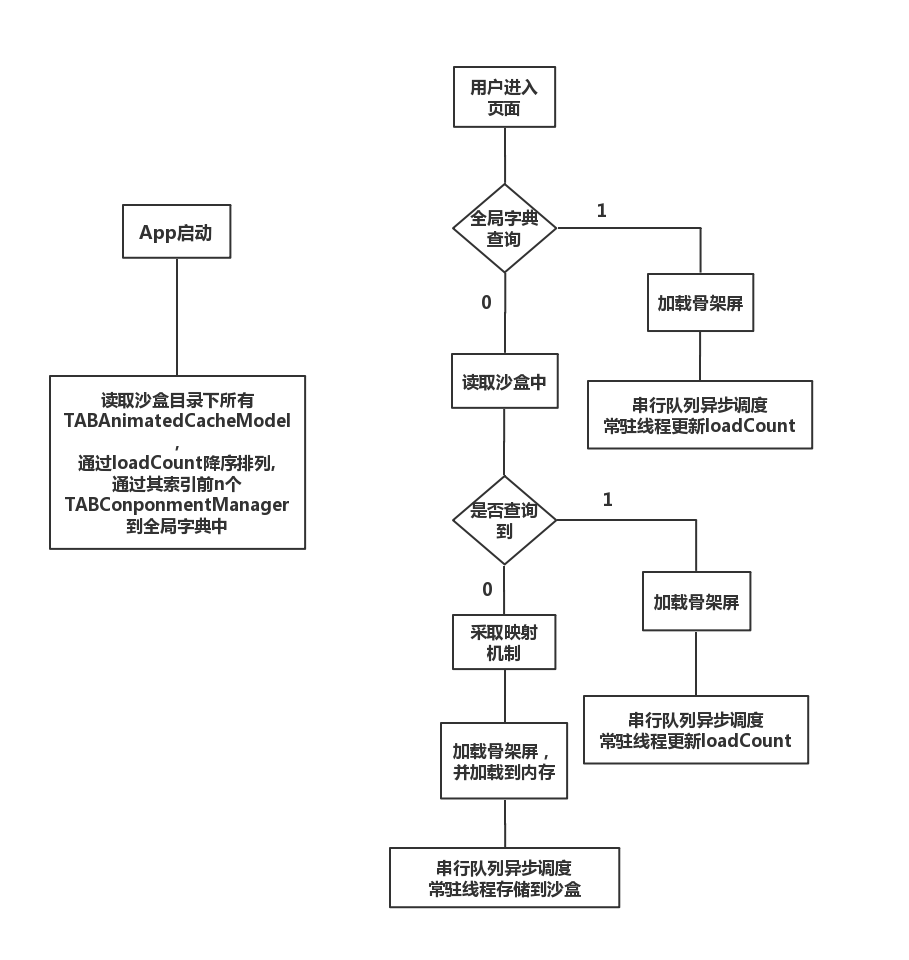
下面是流程图中相关说明:
1. 全局字典
App在启动时(图左侧),会预读取对于该用户来说加载次数最多的一部分数据到全局字典。
全局字典内容:key为plist文件名,value为解释TABAnimatedManager对象的plist文件内容
2. plist文件名
plist文件名用于唯一标识骨架屏管理对象。
-
起初,仅根据className唯一标识。但是有些class会在多个地方,不同
adjustBlock中出现,即这种方式无法唯一定位某个骨架屏视图。 -
最好的方式是将原视图的className+预处理回调字符串化(学过java的应该都用过toString()吧),但是如果回调处理的东西过多,会浪费大量资源。
-
于是,采取的方案是:在启动动画后,获取当前控制视图(control view)的
UIViewController的className, 将其合并。

3. 描述"加载次数最多"、loadCount?
为了描述加载次数最多,引入了TABAnimatedCacheModel,
TABAnimatedCacheModel同样是用一个plist文件解释。与TABAnimatedManager同名
- 一个描述
TABAnimatedCacheModel的plist文件,大小约为300bytes - 一个描述
TABAnimatedManager的plist文件,大小约为3kb
loadCount字段作用:
App启动后,读取沙盒中所有的TABCacheModel文件,根据loadCount降序排列TABCacheModel数组,并加载数组中前n个TABComponentManager到内存中,存储方式是全局字典。(n默认为20)
loadCount更新机制: 启动动画后,在下一次runloop执行时,放到串行队列中。
4. 为什么要通过TABAnimatedCacheModel计数,而不是TABAnimatedManager自计数?
一个用于解释TABAnimatedManager的plist文件大概是4kb,如果仅仅为了更新一个字段频繁写入,很明显浪费资源。
而TABAnimatedCacheModel仅需要300bytes。
5. 版本控制
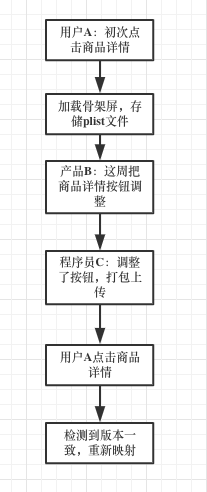
如果开发者在待发布的版本,对某个已经在沙盒中存在的plist文件,其对应视图和预处理回调做了修改,此时需要重新写入。所以在读取缓存对象前,需要进行版本校对,如果不一致,需要重新使用映射机制。
太长不看😶😶???
三、存储结构

- 默认生成文件夹
TABAnimated - 默认在
TABAnimated文件夹里生成2个文件夹cacheModel和cacheManager cacheModel用于存储TABAnimatedCacheModel对象,该对象只有2个字段,一个用于索引cacheManager,一个用于描述cacheManager的加载次数,即loadCountcacheManager存储的就是能够解释骨架屏的骨架管理对象
存储路径:沙盒根目录/Document/TABAnimated/
四、线程处理
- 默认创建一个串行队列,调度plist文件写入、更新任务。
- 默认开辟一个常驻的子线程。该线程主要负责执行plist文件写入、更新任务。通过添加
NSMachPort端口保证该线程的runLoop不会退出。 - 当加载了新的(沙盒中没有的)骨架对象,该骨架对象会立即写入全局字典(即内存中),但是并不急着写入沙盒,会将该任务交由已经创建好的串行队列调度。
五、特殊场景
如果你的列表数据,需要针对每一个row做特殊处理。
框架内部重写了getter方法,检测到这种情况后,每次都会强制使用映射机制。
当然后续会继续探索更好的处理方式,目前先这样处理,不会存在太大的问题~
