


前言
在前篇中已经讲了关于git的常用命令,这一篇我们就更进一步来讲讲git的存储原理,看看git葫芦里面究竟卖的什么药。
.git中究竟藏了些什么
当我们使用git init命令时,通常git会提示:Initialized empty Git repository in /xxxx/.git/。可以看到在初始化本地仓库时,git新建了一个.git的文件夹(.git是一个隐藏的文件夹),而git所有记录的版本控制的信息都藏在这个文件夹中。
先让我们看看.git中有什么:
▶ ls .git
HEAD config description hooks/ index info/ objects/ refs/
其中,config包含了项目的特有的配置信息;description包含了项目的描述信息,仅供GitWeb程序使用;info/文件夹中包含了一份执行文件,该文件用于指定不希望在.gitignore文件中管理的忽略模式;hooks文件包含了各个git生命周期的钩子。以上列出的这些文件大多都是一些配置文件。
git中最重要的四个文件是:HEAD,index,objects/,refs/。它们可以称之为git的核心内容。其中:
HEAD:存储HEAD指针当前的指向refs:存储所有branch,tag的信息index:存储暂存区的信息(在第一次git add后才会出现这个文件)objects:存储所有文件数据信息
git存储机制
git本质上就是一套内容寻址文件系统,它使用简单的key-value形式进行数据的存储和查找。其中的value指的是不仅仅是某一个文件本身内容,还有git的一些附件信息;key这是git对value进行SHA-1后得到的长度为40的字符串(还记得之前的commit-id,没错,它就是现在所说的key)。
现在我们新建一个空的仓库,并且新建一个readme.txt文件,可以使用git hash-object <file-name>命令查看该文件将会生成的key。
▶ git hash-object readme.txt
# 不信你数一数,真的是40位长
e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
git使用这种机制的好处在于:对于相同的value,总是能够得到相同的key。
blob & tree & commit
git内部包含了3个和存储机制相关的对象(或者说是数据结构):blob,tree,commit。
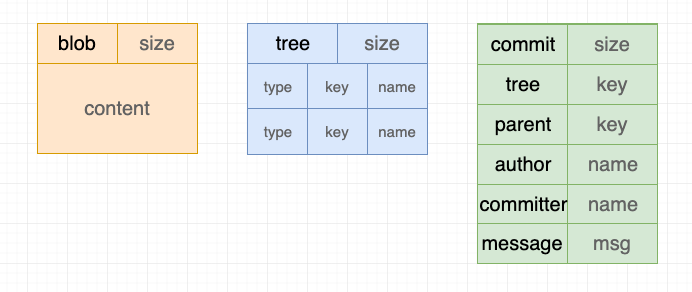
上图显示的是blob,tree以及commit三个对象的结构。
blob对象是用于储存每个文件的内容,所以它的内容就是文件的内容tree对象用于存储文件的结构以及文件名,所以它包含多个条目,每个条目包含类型,key,名字等信息commit对象用于存储每个提交的信息,tree是指本次提交的结构,parent是上一次提交的key,auther和commmitter两个信息可能有点混淆,简单解释一下:auther是指最早提交的人,由于git拥有修改历史的功能,所有后续可能还要其他的人对这个历史作修改,所以committer是指本次修改该提交的人
我们现在通过一些实际操作来看看三者之间的关系,以及git的存储机制。
在进行实际操作之前,我们先来看看objects/里面的内容:
# 现在objects中什么文件都没有
▶ find .git/objects -type f
我们先新建两个文件:readme.txt和.gitignore并且提交,在来看看objects/中的内容:
▶ git log --oneline
9dc03b3 (HEAD -> master) add readme.txt & .gitignore
# 一下子多了这么多内容
▶ find .git/objects -type f
.git/objects/9d/c03b327b7f7898d64a21a80d5ec7aea34930f5
.git/objects/9c/b6bc282361e81f326d93cc0007be1d5424d8a7
.git/objects/62/c893550adb53d3a8fc29a1584ff831cb829062
.git/objects/63/c3cc5127ce2c42f670e07c597428716a62cb7d
看到类似于9d/c03b327b7f7898d64a21a80d5ec7aea34930f5这个文件,其实就是以40位的key命名的,key的前两位作为文件夹名,后38位作为文件名,如果此时我们直接打开这些文件看,只能看到一些乱码,这是因为git对这些文件进行了压缩储存,以节约空间。
可以使用一下命令查看这些文件的信息:
git cat-file -t <key>:查看该文件类型git cat-file -p <key>:查看该文件内容git cat-file -s <key>:查看该文件大小
# 我们先看看上一次提交的信息
▶ git cat-file -t head
commit
▶ git cat-file -s head
188
▶ git cat-file -p head
tree 9cb6bc282361e81f326d93cc0007be1d5424d8a7
author wenjun <wjxu@thoughtworks.com> 1570514009 +0800
committer wenjun <wjxu@thoughtworks.com> 1570525472 +0800
add readme.txt & .gitignore
# 再看看上一次提交所指向的tree
▶ git cat-file -p 9cb6bc2
100644 blob 62c893550adb53d3a8fc29a1584ff831cb829062 .gitignore
100644 blob 63c3cc5127ce2c42f670e07c597428716a62cb7d readme.txt
# .gitignore内容
▶ git cat-file -p 62c893
.idea/%
# readme.txt内容
▶ git cat-file -p 63c3c
this is readme.txt%
所以它们之间的关系如图所示:
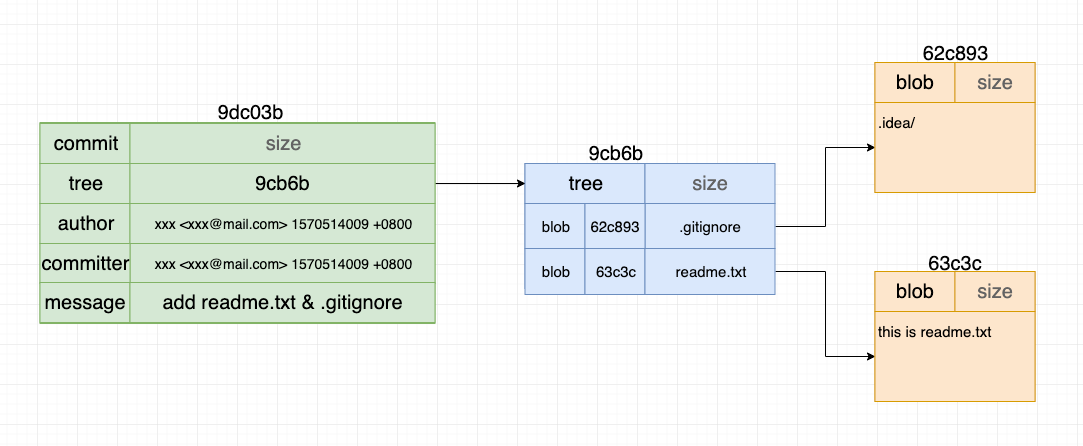
由于当前提交是一个提交,所有commit没有parent信息。相信你也主要到了在author一栏中其实包含了user name,user email以及提交时间,这也是为什么每次生成的git commit id不一样的原因,因为即使其他所有的信息都相同,但是只要提交的时间不同,就会产生不同的key(还记得之前我们所说的相同的value产生相同的key这个结论吗)
如果此时我们新建一个文件夹dir,并在其中新建一个reamde.copy.txt文件复制readme.txt文件的内容。并且将这些改动提交。此时的结构将会变成:
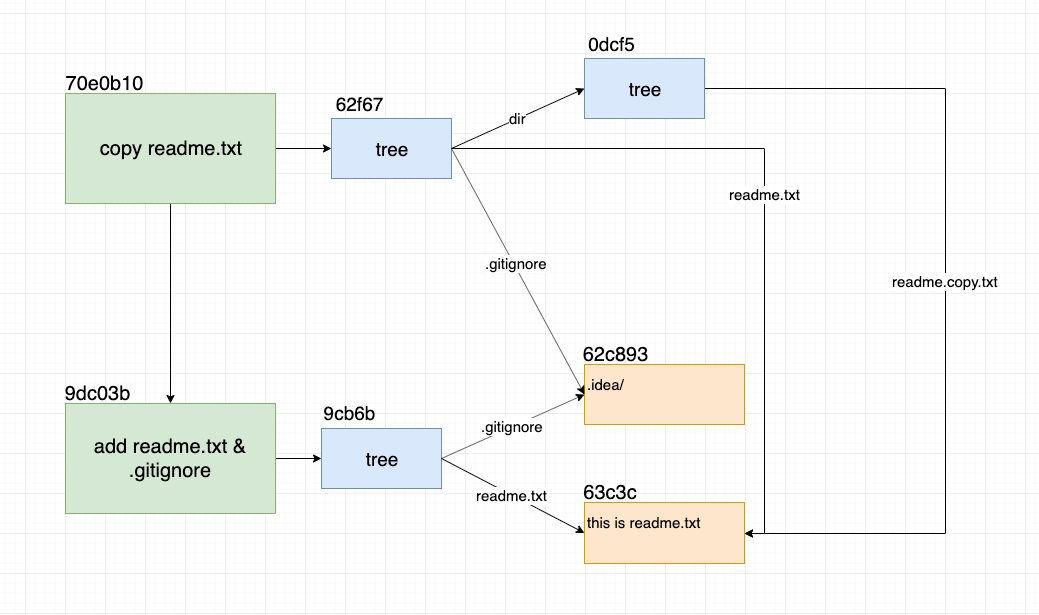
readme.txt以及.gitignore文件,但是这个最新的提交依旧包含了这些没有改变的内容,这和普遍的认识好像是有出入的。所以其实每一个commit都包含了当前项目的所有文件,只是有些文件指向了之前的key,有些指向了新的key。当时不管怎么样,每一个文件都是指向提交时最新的状态。
还是一个更新就是,明明我们复制了一份新的readme.txt文件。当时git中新的提交readme.copy.txt文件内容依旧指向的是readme.txt的blob。这就是之前提到了对于相同的value,总是生成相同的key。而对于相同的key,git只会保存一份,这是git的优化机制,用于减少储存的开销。
如果此时,我们改动readme.copy.txt文件内容并提交,此时的结构将会变成:
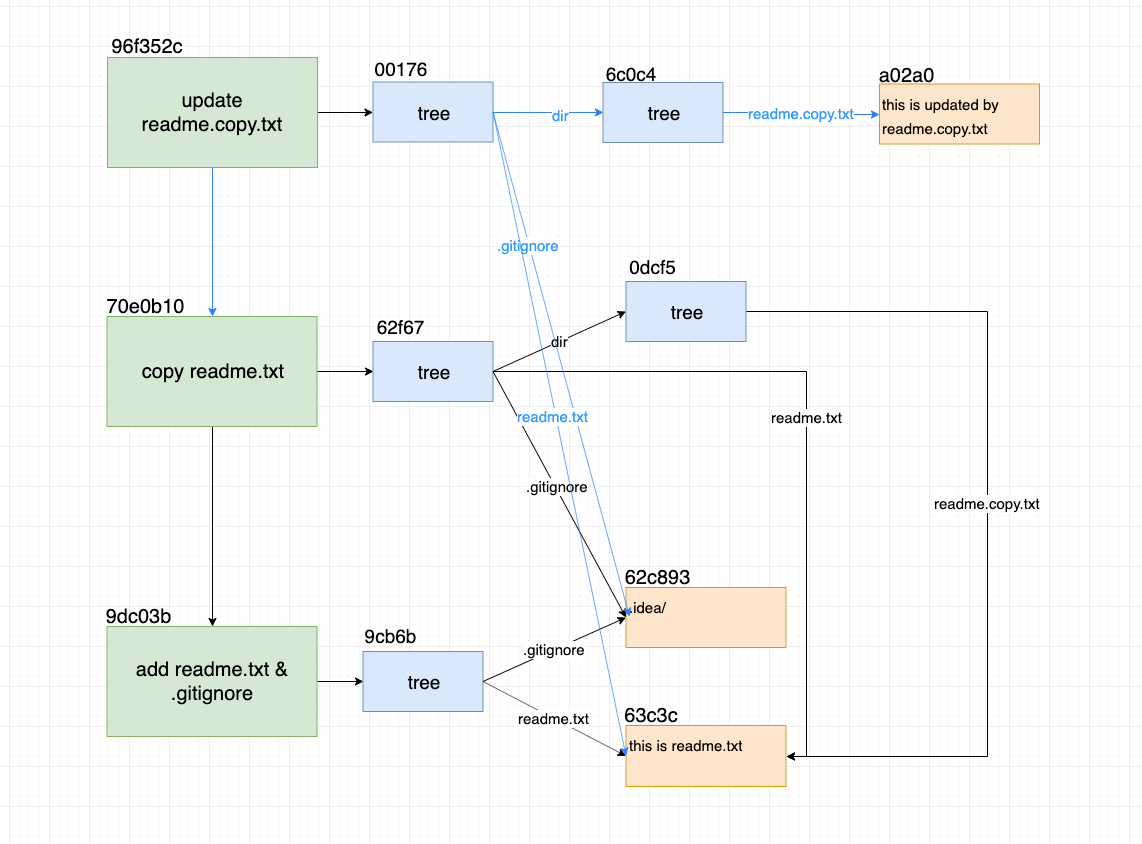
由于readme.copy.txt已经更新了,所以生成了一个新的blob。从这里也能看出其实每一个blob都是保存的文件的当前状态的所有内容。
Packfiles
通过上面的内容,其实也能看出每一个blob都是保存的全部的数据内容,虽然git本身会对内容进行压缩以减少存储体积。但是设想这样一个场景:有个大文件,它一个有2M,我们将它提交到仓库;后面需要在这个文件结尾加入一行数据,然后再提交,此时因为数据有改动,会保存一份新的blob,而这个blob有2M的内容和之前是一模一样的。这其实就造成了很多的浪费。而git可以通通过packfile只存储一份完整的内容,而随后的提交只需要保存两者之间的差异。
我们之前所提的git默认的存储方式使用的是松散对象格式。git会时不时的将这个文件打包到packfile中。当仓库有太多松散对象,或者手动调用git gc,或者push代码时;git都会进行这样的操作。
由于packfile也是被压缩的二进制文件,无法直接查看,可以通过git verify-pack查看打包内容。
# 手动调用gc命令
▶ git gc
Enumerating objects: 20, done.
Counting objects: 100% (20/20), done.
Delta compression using up to 8 threads.
Compressing objects: 100% (12/12), done.
Writing objects: 100% (20/20), done.
Total 20 (delta 2), reused 12 (delta 1)
# 此时的objects中多了pack,info文件夹
▶ find .git/objects -type f
.git/objects/pack/pack-891394b403ab48f1b2264486397661f55895a867.idx
.git/objects/pack/pack-891394b403ab48f1b2264486397661f55895a867.pack
.git/objects/info/packs
.git/objects/e6/9de29bb2d1d6434b8b29ae775ad8c2e48c5391
# 在这次提交中,readme.copy.txt文件加入大量数据,看看此时的大小
▶ git cat-file -s db53d
203632
# 只在之前的基础上在末尾加入一行新数据
▶ git cat-file -s 2d0077
203642
▶ git verify-pack -v ▶ git verify-pack -v .git/objects/pack/pack-891394b403ab48f1b2264486397661f55895a867.pack
d453ecc64baf5775532f5c42b8bbc082a9e1ed14 commit 250 175 12
dd6cdadafdf3fcf1278e5ab85c3d3c3694cccf9f commit 249 170 187
96f352cdde7dd887f219a3724139d9f4c5405e88 commit 231 158 357
70e0b10e339780007f27454b48b87ad534222f22 commit 224 155 515
9dc03b327b7f7898d64a21a80d5ec7aea34930f5 commit 188 140 670
f4bd8c7bd40a2cb07611dd87cdc0b001c84d2186 commit 18 30 810 1 9dc03b327b7f7898d64a21a80d5ec7aea34930f5
62c893550adb53d3a8fc29a1584ff831cb829062 blob 6 15 840
2d0077acefe0c82f2b1751797930d61854ddedef blob 203642 1610 855
63c3cc5127ce2c42f670e07c597428716a62cb7d blob 18 26 2465
8abbb9d2066b01124935168578575bda84c611c4 tree 106 114 2491
90af1bd85bf9caefe7f2a896bde462e73197fe8a tree 43 54 2605
f4e13c3ae0262786fe5e6d6732364e8fb0a3c479 tree 106 114 2659
adc38899d876c80633deeb231f61c1680577edfb tree 43 54 2773
db53d7cf02340f626f717030979f2d8d1cd03dec blob 15 26 2827 1 2d0077acefe0c82f2b1751797930d61854ddedef
00176f1c402309625b9757f54c228e19c53f6705 tree 106 113 2853
6c0c493d71b5fa1052bb92835fd0a24e54540db7 tree 43 53 2966
a02a0d302c13ed72406a60cac8dc0b927c1f0a47 blob 34 42 3019
62f678e1e758528a7b5450cf7c225c684be08390 tree 106 113 3061
0dcf59da0270a619704a7fd02e64f624efc8d954 tree 43 53 3174
9cb6bc282361e81f326d93cc0007be1d5424d8a7 tree 76 84 3227
non delta: 18 objects
chain length = 1: 2 objects
.git/objects/pack/pack-891394b403ab48f1b2264486397661f55895a867.pack: ok
其中每一个数据代表什么可以查看git-verify。我们需要关注的是:此时,2d0077的大小是203642,而db53d的大小只有15。同时git会在最新版本保存完成的数据内容,而在之前的版本只保留差异。这也是因为大部分情况下,最新版本需要被快速的访问。
index
index文件保存了所有暂存区的信息,它也是一个二进制文件,可以通过git ls-files -s查看暂存区的状态。
▶ git ls-files -s
100644 62c893550adb53d3a8fc29a1584ff831cb829062 0 .gitignore
100644 2d0077acefe0c82f2b1751797930d61854ddedef 0 dir/readme.copy.txt
100644 63c3cc5127ce2c42f670e07c597428716a62cb7d 0 readme.txt
如果此时我更改一下readme.txt文件的内容,并且提交到暂存区:
▶ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: readme.txt
▶ git ls-files -s
100644 62c893550adb53d3a8fc29a1584ff831cb829062 0 .gitignore
100644 2d0077acefe0c82f2b1751797930d61854ddedef 0 dir/readme.copy.txt
100644 fc1e0c2ac5dca872def36e9a5ca0c9a30cb27ad9 0 readme.txt
可以看到readme.txt的文件key已经改变了,此时如果commit改动,暂存区依旧是保留这样的信息,这其实也是和通常的认知有些不同的地方(通常,我们认为当commit后,暂存区就会被情况)。其实暂存区保存的信息和commit对象保存的内容,都是保存每一个文件最新的状态。git根据这些文件信息才能分辨出每个区域不同的状态。
refs/ & HEAD
在git中,除了需要保存版本信息外,还需要保存分支,tag,当前HEAD的信息。 其实refs/用于保存分支和tag的信息;HEAD保存当前HEAD指针信息。
在git中新建一个分支second,并查看分支信息
▶ git branch second
▶ cd .git/refs/heads
# 有几个分支就会有几个同名的文件
▶ ls
master second
# 每个文件包含了当前分支所指向的commit id
▶ cat master
ef059bba1983be625c6cb619af7b7bd26966181d
▶ cat second
ef059bba1983be625c6cb619af7b7bd26966181d
# 如果HEAD和某一个分支指向的key相同
▶ cat HEAD
ref: refs/heads/master
# 如果HEAD指向历史的某一个commit
▶ cat HEAD
d453ecc64baf5775532f5c42b8bbc082a9e1ed14
此时在新建两个tag,并查看tag信息:
# 分别使用不同的命令新建tag
▶ git tag v1.0
▶ git tag -a v2.0 -m "this is v2.0"
# 有几个tag就会有几个同名的文件
▶ cd .git/refs/tags
▶ ls
v1.0 v2.0
▶ cat v1.0
ef059bba1983be625c6cb619af7b7bd26966181d
# 不使用-a参数的tag直接保存commit id
▶ git cat-file -t ef059
commit
# 使用-a参数的tag直接保存tag对象
▶ cat v2.0
5b6990bc6916f95f757090a411faa02b0b332178
▶ git cat-file -t 5b699
tag
# 可以看到tag对象所包含的信息
▶ git cat-file -p 5b699
object ef059bba1983be625c6cb619af7b7bd26966181d
type commit
tag v2.0
tagger wenjun <wjxu@thoughtworks.com> 1570547502 +0800
this is v2.0
其实从这里就可以看到,在git中不管是分支,HEAD,还是tag,本质是都是指向某一次提交的指针。
结语
其实,通过上面的这些关键点,我们就能大概搞清楚git是如何存储的。可以这样打一个比方:git会将所有的更改以类似单链表的方式连接起来,串成一条或者多条路线;而分支和tag等指针就像是这些路上的地标;而HEAD则是表明在这些路中,当前你在哪个位置。
当然,git内部的原理还远不止此,如果大家有兴趣也可以继续探索,欢迎交流。
