

前几天看没事看了眼GLUE榜单就发现了ALBERT这个模型,去arxiv搜了下没搜到,还在想什么时候放出来,没想到在Openreview上。。
ALBERT原文openreview.netGoogle一出手就是不一样,不再是BERT+的模式,而是做了个大改动。
先来感受一下刷榜的乐趣,GLUE:


RACE可能没找对,没看到。
1. 模型简介
ALBERT主要对BERT做了3点改进,缩小了整体的参数量,加快了训练速度,增加了模型效果。
接下来介绍这三点改进。
1.1 Factorized embedding parameterization
在BERT、XLNet、RoBERTa中,词表的embedding size(E)和transformer层的hidden size(H)都是相等的,这个选择有两方面缺点:
- 从建模角度来讲,wordpiece向量应该是不依赖于当前内容的(context-independent),而transformer所学习到的表示应该是依赖内容的。所以把E和H分开可以更高效地利用参数,因为理论上存储了context信息的H要远大于E。
- 从实践角度来讲,NLP任务中的vocab size本来就很大,如果E=H的话,模型参数量就容易很大,而且embedding在实际的训练中更新地也比较稀疏。
因此作者使用了小一些的E(64、128、256、768),训练一个独立于上下文的embedding(VxE),之后计算时再投影到隐层的空间(乘上一个ExH的矩阵),相当于做了一个因式分解。
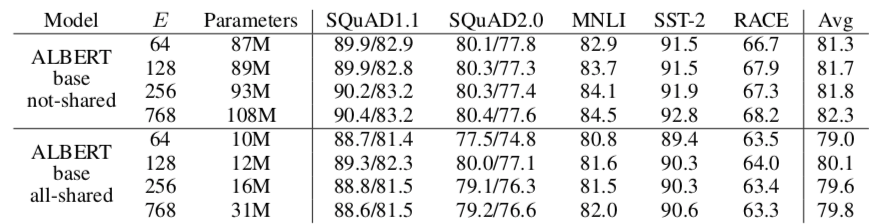
从后续的实验中来看,E的大小与实验效果也不是完全正相关,因此其他实验中E都取的128。
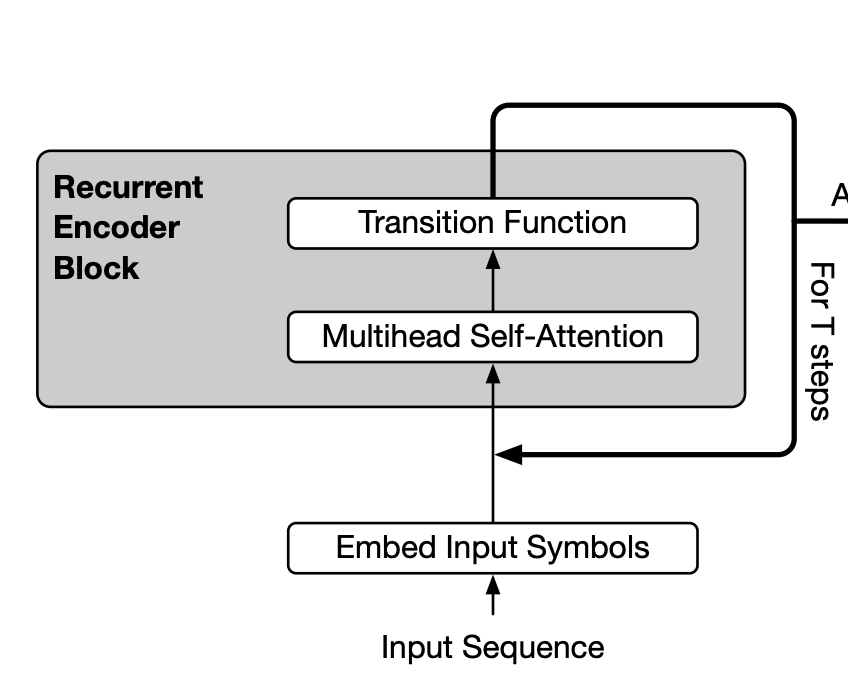
1.2 Cross-layer parameter sharing
跨层参数共享,就是不管12层还是24层都只用一个transformer。这在之前读过Universal Transformer就有了,但是以为会火,因为做语言模型的效果比标准Transformer好。结果没什么人用,这次被提起来了。
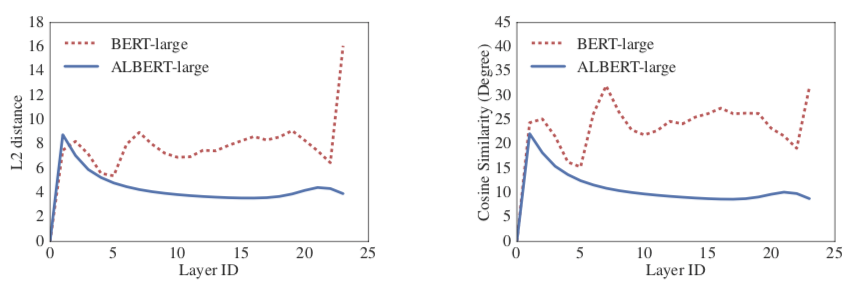
作者对比了每层输入输出的L2距离和相似度,发现了BERT的结果比较震荡,而ALBERT就很稳定,可见ALBERT有稳定网络参数的作用。
1.3 Inter-sentence coherence loss
后BERT时代很多研究(XLNet、RoBERTa)都发现next sentence prediction没什么用处,所以作者也审视了一下这个问题,认为NSP之所以没用是因为这个任务不仅包含了句间关系预测,也包含了主题预测,而主题预测显然更简单些(比如一句话来自新闻财经,一句话来自文学小说),模型会倾向于通过主题的关联去预测。因此换成了SOP(sentence order prediction),预测两句话有没有被交换过顺序。实验显示新增的任务有1个点的提升:

2. 总结
刚开始看这篇文章是很惊喜的,因为它直接把同等量级的BERT缩小了10倍+,让普通用户有了运行GPT2、威震天的可能。但是仔细看了实验后才发现体量的减小是需要付出代价的:

可以仔细看一下model的量级,并且注意一下这个speedup是训练时间而不是inference时间(因为数据少了,分布式训练时吞吐上去了,所以ALBERT训练更快),但inference还是需要和BERT一样的transformer计算。
可以得出的结论是:
- 在相同的训练时间下,ALBERT得到的效果确实比BERT好
- 在相同的Inference时间下,ALBERT base和large的效果都是没有BERT好的,而且差了2-3个点,作者在最后也提到了会继续寻找提高速度的方法(sparse attention和block attention)
鱼与熊掌不可兼得,尤其是对于工程落地而言,需要在速度与效果之间寻找一个trade-off。
另外,结合Universal Transformer可以想到的是,在训练和inference阶段可以动态地调整transformer层数(告别12、24、48的配置吧)。同时可以想办法去避免纯参数共享带来的效果下降,毕竟越深的transformer层所学到的任务相关信息越多,可以改进transformer模块,加入记忆单元、每层的个性化embedding。
