

当你知道的越多,你就越发觉得自己无知。
我们在编写C语言源代码时,总是会不忘的加上#include <stdio.h>,不管它有没有用,但它能让我们代码少些报错。久而久之,就养成就了一种好习惯,只要用到了某个.h文件里面定义的函数就会把这个.h文件包含进来。
我们也许从来没有想过,这个头文件是必须的吗?我们会根据我们以往的经验来做出判断:肯定必须!因为我每次少写了#include <xxx.h>或#include "xxx.h"程序都会报错!
现在我告诉你,头文件不是必须的,你是否不会相信并觉得我在瞎扯?光说你肯定不信,让我们来实践一下。
实践检验真理
首先编写两个C源程序(一个有#include<stdio.h>,一个没有#include<stdio.h>)进行实验比较。
// helloworld.c
#include<stdio.h>
int main()
{
printf("hello world\n");
return 0;
}
// helloworld2.c
int main()
{
printf("hello world\n");
return 0;
}
显然对于helloworld.c肯定没有问题,我们来看看在Linux下helloworld2.c编译执行。
使用gcc对helloworld2.c进行编译。
gcc helloworld2.c -o helloworld2.out
输入命令后,终端输入了很多warning信息(注意没有error信息):
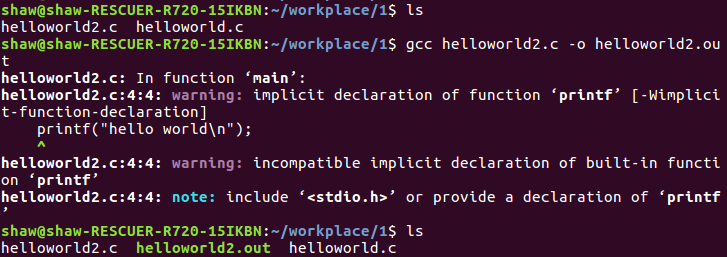
信息的大概意思告诉你一些警告信息,printf函数为隐式声明,对内建函数printf不兼容隐式声明等,并且提示你包含<stdio.h>或提供一个printf的函数声明。
补充:gcc在处理未知类型的函数时,会为其创建一个隐式声明,并假设该函数返回值类型为int
先不管,我们可以看到目录下还是生成了helloworld2.out,我们执行看看。

程序正确输出了!没想到把!
探索因果
这里的编译都是狭义的,不包括链接。
你是否还是不信,并且得自己用自己的电脑亲眼见证才肯相信?没关系,你去试吧,结果会跟我一样的。如果你已经信服,让我们一起来探索因果。
我们知道gcc编译C源程序时会经过四个步骤:
预处理 -》编译 -》汇编 -》链接
预处理就是把#include这条语句包含的文件内容直接插入到待编译的文件中。
我们用gcc -E命令来获取预处理后的文件。
预处理后部分内容如图:
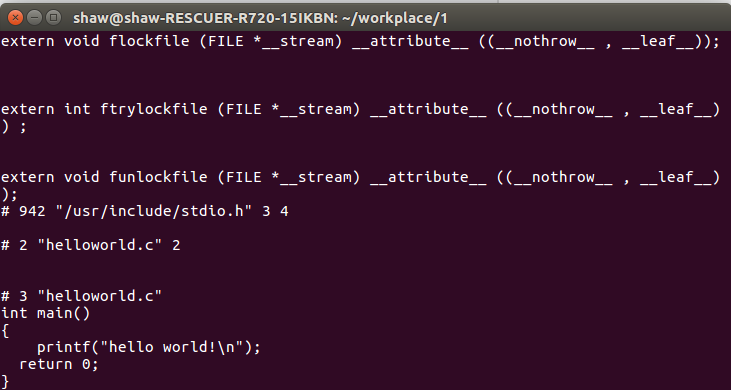
#include<stdio.h>不见了,取而代之的是一堆的extern的函数声明。翻来翻去才发现了printf的函数声明。(注意:预处理过程其实就是把文件内容完全复制到另一个文件中,因此不管你的.h文件中有什么都会拷贝到另一个文件)
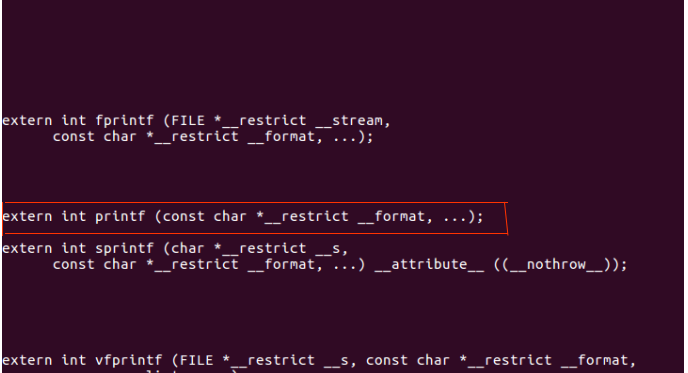
虽然看到了声明,但并没有给出函数实现啊?由此产生两个问题:
- 编译为什么能通过?
- 为什么后续运行不会出问题呢?
问题1
编译过程就是把预处理完的文件进行一系列词法分析、语法分析、语义分析及优化后生成相应的汇编代码文件。汇编代码文件中所有的函数调用都会用函数名作为符号代替地址。
其实编译的时候,程序并不会去找printf函数的实现。编译和汇编后得到的目标文件(.o文件)将程序中的所有变量和函数都视作一个个符号,是一个可重定位文件。编译器并不知道printf的地址,而是将它的地址用一个假地址暂时代替。等到链接时才去处理它,将它重定位到正确的地址。
使用gcc -S和objdump来分析一下
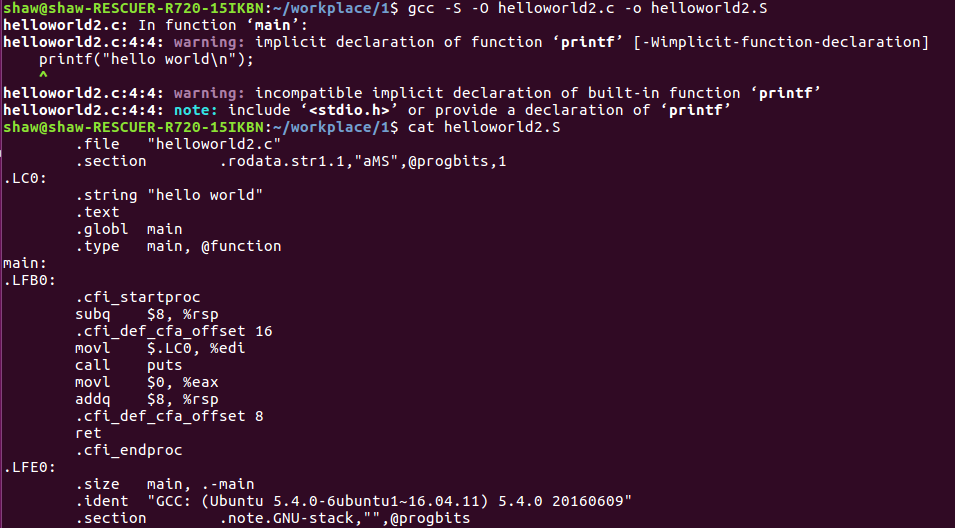
本应该是call printf,但被编译器被优化成了call puts。对于参数如果是以\n结尾的纯字符串printf函数都会被优化成puts。不过这不影响我们继续分析,我们将汇编文件进行汇编得到二进制文件,然后用objdump对二进制数据进行反汇编。
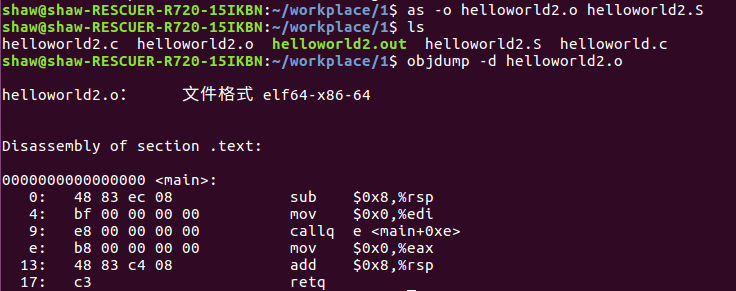
可以看到这里callq e <main+0xe>所用的地址0x00000000并不是puts的地址,可以把它当成一个占位符。因此,到后面这个地址会被修正成正确的地址。
用ls -l查看这个文件的执行权限,可以看到是不可执行的,这很容易解释,因为它是不完整的,并且地址也是无效的。

我们先看看来链接,以静态链接为例,链接过程分两步:
- 第一步 空间与地址分配。扫描所有的输入目标文件(.o文件)获得它们各个段的长度、属性和位置,并且将输入文件中的符号表中所有符号定义和符号引用收集起来,统一放到一个全局符号表。这一步中,链接器将能够获得的所有输入目标文件的段长度,并且将它们合并,计算出输出文件中各个段合并后的长度与位置,并建立映射。
- 第二步 符号解析与重定位。使用上面收集到的所有信息,读取输入文件中段的数据、重定位信息,并且进行符号解析与重定位、调整代码中的地址等。
到了gcc命令的最后一步也就是链接,会去寻找printf的实现,并将该实现合并到目标文件中形成可执行文件(静态链接),此时将printf的地址替换成正确地址,程序可以执行了。
使用gcc -print-search-dirs可以查看gcc搜索路径
install: /usr/lib/gcc/x86_64-linux-gnu/5/
programs: =/usr/lib/gcc/x86_64-linux-gnu/5/:/usr/lib/gcc/x86_64-linux-gnu/5/:/usr/lib/gcc/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/5/:/usr/lib/gcc/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/5/../../../../x86_64-linux-gnu/bin/x86_64-linux-gnu/5/:/usr/lib/gcc/x86_64-linux-gnu/5/../../../../x86_64-linux-gnu/bin/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/5/../../../../x86_64-linux-gnu/bin/
libraries: =/usr/lib/gcc/x86_64-linux-gnu/5/:/usr/lib/gcc/x86_64-linux-gnu/5/../../../../x86_64-linux-gnu/lib/x86_64-linux-gnu/5/:/usr/lib/gcc/x86_64-linux-gnu/5/../../../../x86_64-linux-gnu/lib/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/5/../../../../x86_64-linux-gnu/lib/../lib/:/usr/lib/gcc/x86_64-linux-gnu/5/../../../x86_64-linux-gnu/5/:/usr/lib/gcc/x86_64-linux-gnu/5/../../../x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/5/../../../../lib/:/lib/x86_64-linux-gnu/5/:/lib/x86_64-linux-gnu/:/lib/../lib/:/usr/lib/x86_64-linux-gnu/5/:/usr/lib/x86_64-linux-gnu/:/usr/lib/../lib/:/usr/lib/gcc/x86_64-linux-gnu/5/../../../../x86_64-linux-gnu/lib/:/usr/lib/gcc/x86_64-linux-gnu/5/../../../:/lib/:/usr/lib/
其中install为gcc的安装目录,programs为gcc查找本身工具的目录,libraries为gcc的库查找路径
我们再对这个可执行文件进行反汇编:
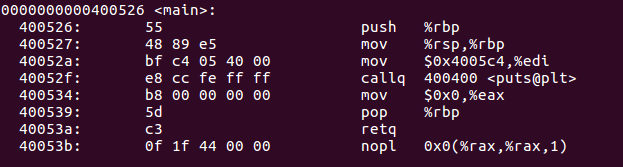
地址变成了0xccfeffff,这个就是链接后的重定位地址。
头文件有啥用?
方便编译器做类型检查
如果我们给出了头文件,头文件里一般包含函数的声明,这时如果我们调用函数时参数个数不对或者参数类型不对时编译器会报错,提示我们参数类型不匹配。否则程序将不会提示报错。
头文件作为描述性文件
库是已经被编译好的二进制文件集合,不再是文本文件,即使反汇编也看不出库函数的参数个数类型与返回值。
如果你写了一个功能强大的库(静态库or动态库),完全没有头文件,函数是你自己写的,你十分清楚每个函数的参数个数类型及返回值,清楚每个函数的功能,所以可以不需要头文件。但是如果另外一个人想要用你的库,它没法知道你的库中函数的参数个数及返回值,他就没法正确使用你的库,最终导致你的库得不到很好的利用。有了头文件,头文件里包括函数、变量声明,其他人使用时可以查看头文件,并且它仅仅知道头文件无法修改你的源代码,既安全又能使别人能很好的利用你的库。
总结
头文件只是为了编译能够通过,让编译器做类型检查,预处理过程头文件被原封不动的插入包含它的源文件中。链接过程再将调用的外部模块拼接起来。形成可执行文件。
写这篇文章的时候,发现越来越多不懂。后期再更新细节!!就是开头那句话一样
参考资料
《程序员的自我修养——链接、装载与库》
